 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSONIC: Supersizing Motion Tracking for Natural Humanoid Whole-Body Control
Nov 11, 2025Despite the rise of billion-parameter foundation models trained across thousands of GPUs, similar scaling gains have not been shown for humanoid control. Current neural controllers for humanoids remain modest in size, target a limited behavior set, and are trained on a handful of GPUs over several days. We show that scaling up model capacity, data, and compute yields a generalist humanoid controller capable of creating natural and robust whole-body movements. Specifically, we posit motion tracking as a natural and scalable task for humanoid control, leverageing dense supervision from diverse motion-capture data to acquire human motion priors without manual reward engineering. We build a foundation model for motion tracking by scaling along three axes: network size (from 1.2M to 42M parameters), dataset volume (over 100M frames, 700 hours of high-quality motion data), and compute (9k GPU hours). Beyond demonstrating the benefits of scale, we show the practical utility of our model through two mechanisms: (1) a real-time universal kinematic planner that bridges motion tracking to downstream task execution, enabling natural and interactive control, and (2) a unified token space that supports various motion input interfaces, such as VR teleoperation devices, human videos, and vision-language-action (VLA) models, all using the same policy. Scaling motion tracking exhibits favorable properties: performance improves steadily with increased compute and data diversity, and learned representations generalize to unseen motions, establishing motion tracking at scale as a practical foundation for humanoid control.
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Mar 18, 2025General-purpose robots need a versatile body and an intelligent mind. Recent advancements in humanoid robots have shown great promise as a hardware platform for building generalist autonomy in the human world. A robot foundation model, trained on massive and diverse data sources, is essential for enabling the robots to reason about novel situations, robustly handle real-world variability, and rapidly learn new tasks. To this end, we introduce GR00T N1, an open foundation model for humanoid robots. GR00T N1 is a Vision-Language-Action (VLA) model with a dual-system architecture. The vision-language module (System 2) interprets the environment through vision and language instructions. The subsequent diffusion transformer module (System 1) generates fluid motor actions in real time. Both modules are tightly coupled and jointly trained end-to-end. We train GR00T N1 with a heterogeneous mixture of real-robot trajectories, human videos, and synthetically generated datasets. We show that our generalist robot model GR00T N1 outperforms the state-of-the-art imitation learning baselines on standard simulation benchmarks across multiple robot embodiments. Furthermore, we deploy our model on the Fourier GR-1 humanoid robot for language-conditioned bimanual manipulation tasks, achieving strong performance with high data efficiency.
ACE: A Cross-Platform Visual-Exoskeletons System for Low-Cost Dexterous Teleoperation
Aug 21, 2024



Learning from demonstrations has shown to be an effective approach to robotic manipulation, especially with the recently collected large-scale robot data with teleoperation systems. Building an efficient teleoperation system across diverse robot platforms has become more crucial than ever. However, there is a notable lack of cost-effective and user-friendly teleoperation systems for different end-effectors, e.g., anthropomorphic robot hands and grippers, that can operate across multiple platforms. To address this issue, we develop ACE, a cross-platform visual-exoskeleton system for low-cost dexterous teleoperation. Our system utilizes a hand-facing camera to capture 3D hand poses and an exoskeleton mounted on a portable base, enabling accurate real-time capture of both finger and wrist poses. Compared to previous systems, which often require hardware customization according to different robots, our single system can generalize to humanoid hands, arm-hands, arm-gripper, and quadruped-gripper systems with high-precision teleoperation. This enables imitation learning for complex manipulation tasks on diverse platforms.
Bunny-VisionPro: Real-Time Bimanual Dexterous Teleoperation for Imitation Learning
Jul 03, 2024Teleoperation is a crucial tool for collecting human demonstrations, but controlling robots with bimanual dexterous hands remains a challenge. Existing teleoperation systems struggle to handle the complexity of coordinating two hands for intricate manipulations. We introduce Bunny-VisionPro, a real-time bimanual dexterous teleoperation system that leverages a VR headset. Unlike previous vision-based teleoperation systems, we design novel low-cost devices to provide haptic feedback to the operator, enhancing immersion. Our system prioritizes safety by incorporating collision and singularity avoidance while maintaining real-time performance through innovative designs. Bunny-VisionPro outperforms prior systems on a standard task suite, achieving higher success rates and reduced task completion times. Moreover, the high-quality teleoperation demonstrations improve downstream imitation learning performance, leading to better generalizability. Notably, Bunny-VisionPro enables imitation learning with challenging multi-stage, long-horizon dexterous manipulation tasks, which have rarely been addressed in previous work. Our system's ability to handle bimanual manipulations while prioritizing safety and real-time performance makes it a powerful tool for advancing dexterous manipulation and imitation learning.
Can 3D Vision-Language Models Truly Understand Natural Language?
Mar 28, 2024



Rapid advancements in 3D vision-language (3D-VL) tasks have opened up new avenues for human interaction with embodied agents or robots using natural language. Despite this progress, we find a notable limitation: existing 3D-VL models exhibit sensitivity to the styles of language input, struggling to understand sentences with the same semantic meaning but written in different variants. This observation raises a critical question: Can 3D vision-language models truly understand natural language? To test the language understandability of 3D-VL models, we first propose a language robustness task for systematically assessing 3D-VL models across various tasks, benchmarking their performance when presented with different language style variants. Importantly, these variants are commonly encountered in applications requiring direct interaction with humans, such as embodied robotics, given the diversity and unpredictability of human language. We propose a 3D Language Robustness Dataset, designed based on the characteristics of human language, to facilitate the systematic study of robustness. Our comprehensive evaluation uncovers a significant drop in the performance of all existing models across various 3D-VL tasks. Even the state-of-the-art 3D-LLM fails to understand some variants of the same sentences. Further in-depth analysis suggests that the existing models have a fragile and biased fusion module, which stems from the low diversity of the existing dataset. Finally, we propose a training-free module driven by LLM, which improves language robustness. Datasets and code will be available at github.
V-IRL: Grounding Virtual Intelligence in Real Life
Feb 05, 2024



There is a sensory gulf between the Earth that humans inhabit and the digital realms in which modern AI agents are created. To develop AI agents that can sense, think, and act as flexibly as humans in real-world settings, it is imperative to bridge the realism gap between the digital and physical worlds. How can we embody agents in an environment as rich and diverse as the one we inhabit, without the constraints imposed by real hardware and control? Towards this end, we introduce V-IRL: a platform that enables agents to scalably interact with the real world in a virtual yet realistic environment. Our platform serves as a playground for developing agents that can accomplish various practical tasks and as a vast testbed for measuring progress in capabilities spanning perception, decision-making, and interaction with real-world data across the entire globe.
Lowis3D: Language-Driven Open-World Instance-Level 3D Scene Understanding
Aug 01, 2023



Open-world instance-level scene understanding aims to locate and recognize unseen object categories that are not present in the annotated dataset. This task is challenging because the model needs to both localize novel 3D objects and infer their semantic categories. A key factor for the recent progress in 2D open-world perception is the availability of large-scale image-text pairs from the Internet, which cover a wide range of vocabulary concepts. However, this success is hard to replicate in 3D scenarios due to the scarcity of 3D-text pairs. To address this challenge, we propose to harness pre-trained vision-language (VL) foundation models that encode extensive knowledge from image-text pairs to generate captions for multi-view images of 3D scenes. This allows us to establish explicit associations between 3D shapes and semantic-rich captions. Moreover, to enhance the fine-grained visual-semantic representation learning from captions for object-level categorization, we design hierarchical point-caption association methods to learn semantic-aware embeddings that exploit the 3D geometry between 3D points and multi-view images. In addition, to tackle the localization challenge for novel classes in the open-world setting, we develop debiased instance localization, which involves training object grouping modules on unlabeled data using instance-level pseudo supervision. This significantly improves the generalization capabilities of instance grouping and thus the ability to accurately locate novel objects. We conduct extensive experiments on 3D semantic, instance, and panoptic segmentation tasks, covering indoor and outdoor scenes across three datasets. Our method outperforms baseline methods by a significant margin in semantic segmentation (e.g. 34.5%$\sim$65.3%), instance segmentation (e.g. 21.8%$\sim$54.0%) and panoptic segmentation (e.g. 14.7%$\sim$43.3%). Code will be available.
RegionPLC: Regional Point-Language Contrastive Learning for Open-World 3D Scene Understanding
Apr 03, 2023



Existing 3D scene understanding tasks have achieved high performance on close-set benchmarks but fail to handle novel categories in real-world applications. To this end, we propose a Regional Point-Language Contrastive learning framework, namely RegionPLC, for open-world 3D scene understanding, which equips models trained on closed-set datasets with open-vocabulary recognition capabilities. We propose dense visual prompts to elicit region-level visual-language knowledge from 2D foundation models via captioning, which further allows us to build dense regional point-language associations. Then, we design a point-discriminative contrastive learning objective to enable point-independent learning from captions for dense scene understanding. We conduct extensive experiments on ScanNet, ScanNet200, and nuScenes datasets. Our RegionPLC significantly outperforms previous base-annotated 3D open-world scene understanding approaches by an average of 11.6\% and 6.6\% for semantic and instance segmentation, respectively. It also shows promising open-world results in absence of any human annotation with low training and inference costs. Code will be released.
Language-driven Open-Vocabulary 3D Scene Understanding
Nov 29, 2022



Open-vocabulary scene understanding aims to localize and recognize unseen categories beyond the annotated label space. The recent breakthrough of 2D open-vocabulary perception is largely driven by Internet-scale paired image-text data with rich vocabulary concepts. However, this success cannot be directly transferred to 3D scenarios due to the inaccessibility of large-scale 3D-text pairs. To this end, we propose to distill knowledge encoded in pre-trained vision-language (VL) foundation models through captioning multi-view images from 3D, which allows explicitly associating 3D and semantic-rich captions. Further, to facilitate coarse-to-fine visual-semantic representation learning from captions, we design hierarchical 3D-caption pairs, leveraging geometric constraints between 3D scenes and multi-view images. Finally, by employing contrastive learning, the model learns language-aware embeddings that connect 3D and text for open-vocabulary tasks. Our method not only remarkably outperforms baseline methods by 25.8% $\sim$ 44.7% hIoU and 14.5% $\sim$ 50.4% hAP$_{50}$ on open-vocabulary semantic and instance segmentation, but also shows robust transferability on challenging zero-shot domain transfer tasks. Code will be available at https://github.com/CVMI-Lab/PLA.
Towards Efficient 3D Object Detection with Knowledge Distillation
May 30, 2022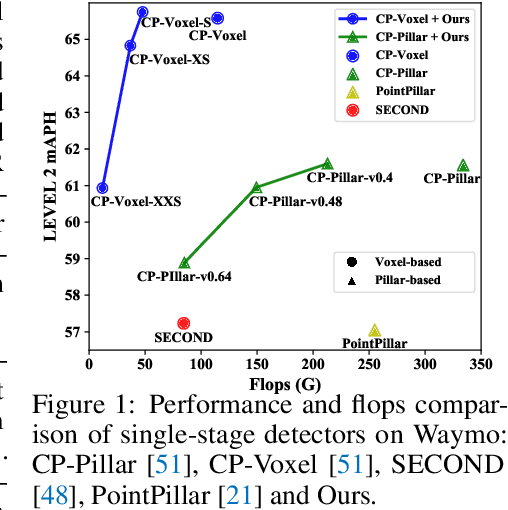
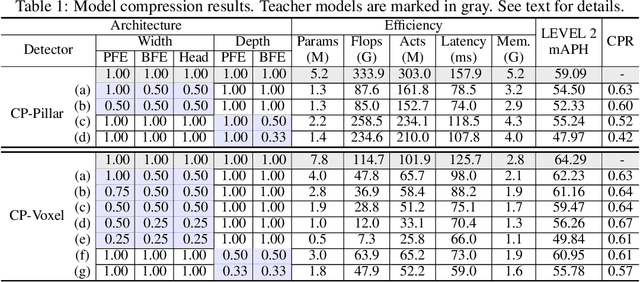

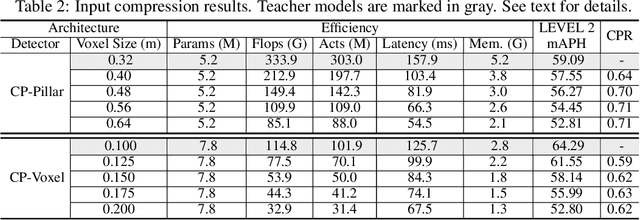
Despite substantial progress in 3D object detection, advanced 3D detectors often suffer from heavy computation overheads. To this end, we explore the potential of knowledge distillation (KD) for developing efficient 3D object detectors, focusing on popular pillar- and voxel-based detectors.Without well-developed teacher-student pairs, we first study how to obtain student models with good trade offs between accuracy and efficiency from the perspectives of model compression and input resolution reduction. Then, we build a benchmark to assess existing KD methods developed in the 2D domain for 3D object detection upon six well-constructed teacher-student pairs. Further, we propose an improved KD pipeline incorporating an enhanced logit KD method that performs KD on only a few pivotal positions determined by teacher classification response, and a teacher-guided student model initialization to facilitate transferring teacher model's feature extraction ability to students through weight inheritance. Finally, we conduct extensive experiments on the Waymo dataset. Our best performing model achieves $65.75\%$ LEVEL 2 mAPH, surpassing its teacher model and requiring only $44\%$ of teacher flops. Our most efficient model runs 51 FPS on an NVIDIA A100, which is $2.2\times$ faster than PointPillar with even higher accuracy. Code will be available.