 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowdMove: Autonomous Mapless Navigation in Crowded Scenarios
Jul 25, 2018
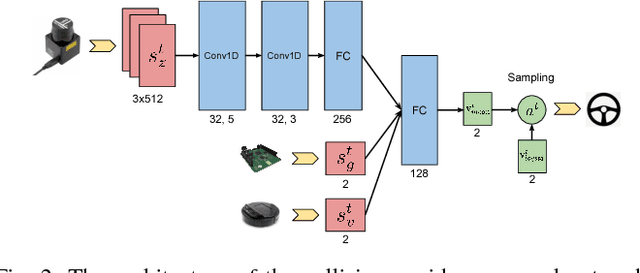
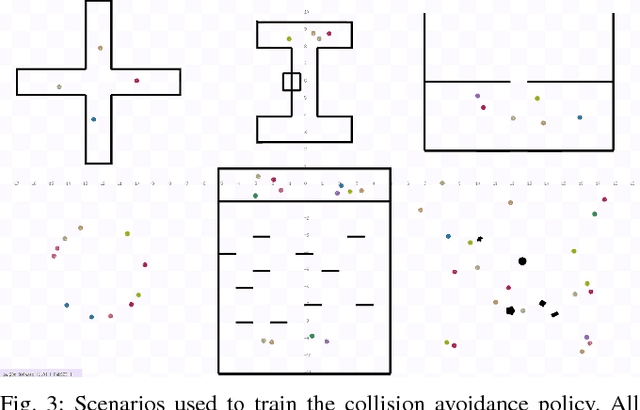
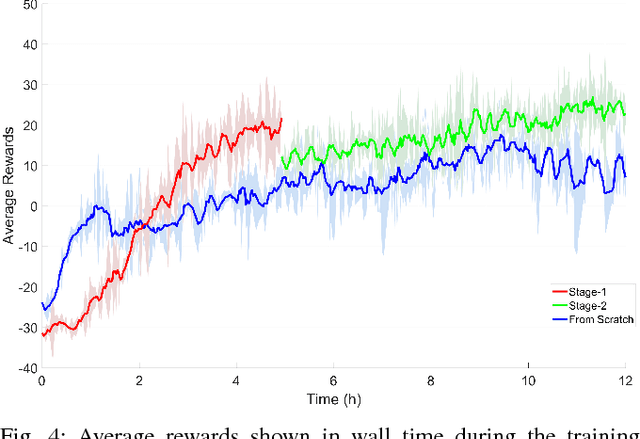
Navigation is an essential capability for mobile robots. In this paper, we propose a generalized yet effective 3M (i.e., multi-robot, multi-scenario, and multi-stage) training framework. We optimize a mapless navigation policy with a robust policy gradient algorithm. Our method enables different types of mobile platforms to navigate safely in complex and highly dynamic environments, such as pedestrian crowds. To demonstrate the superiority of our method, we test our methods with four kinds of mobile platforms in four scenarios. Videos are available at https://sites.google.com/view/crowdmove.
Identity Preserving Face Completion for Large Ocular Region Occlusion
Jul 23, 2018

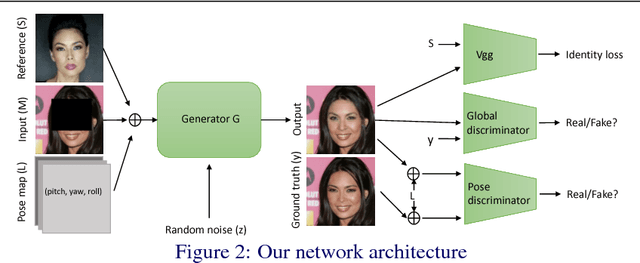

We present a novel deep learning approach to synthesize complete face images in the presence of large ocular region occlusions. This is motivated by recent surge of VR/AR displays that hinder face-to-face communications. Different from the state-of-the-art face inpainting methods that have no control over the synthesized content and can only handle frontal face pose, our approach can faithfully recover the missing content under various head poses while preserving the identity. At the core of our method is a novel generative network with dedicated constraints to regularize the synthesis process. To preserve the identity, our network takes an arbitrary occlusion-free image of the target identity to infer the missing content, and its high-level CNN features as an identity prior to regularize the searching space of generator. Since the input reference image may have a different pose, a pose map and a novel pose discriminator are further adopted to supervise the learning of implicit pose transformations. Our method is capable of generating coherent facial inpainting with consistent identity over videos with large variations of head motions. Experiments on both synthesized and real data demonstrate that our method greatly outperforms the state-of-the-art methods in terms of both synthesis quality and robustness.
* 12 pages,9 figures
DeLS-3D: Deep Localization and Segmentation with a 3D Semantic Map
May 13, 2018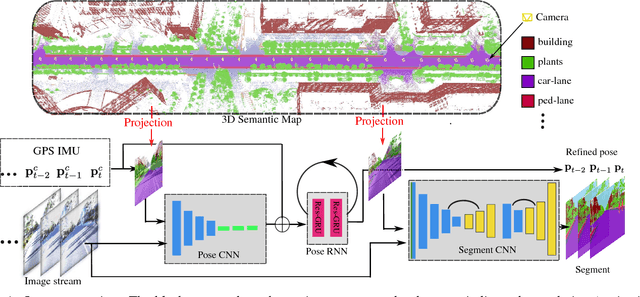

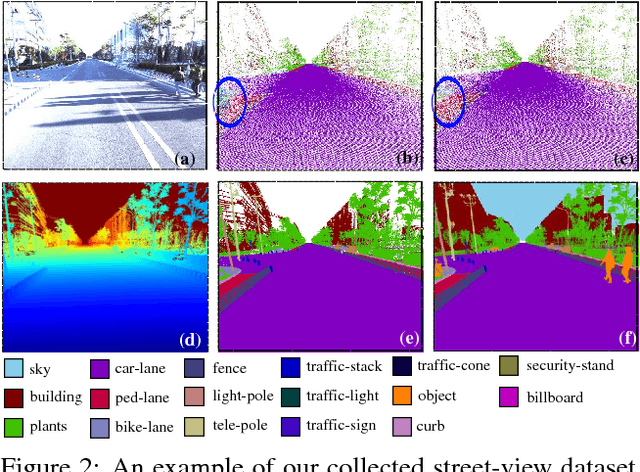
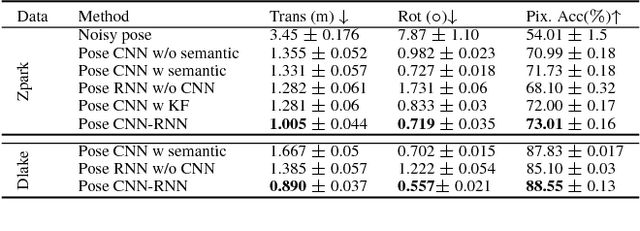
For applications such as autonomous driving, self-localization/camera pose estimation and scene parsing are crucial technologies. In this paper, we propose a unified framework to tackle these two problems simultaneously. The uniqueness of our design is a sensor fusion scheme which integrates camera videos, motion sensors (GPS/IMU), and a 3D semantic map in order to achieve robustness and efficiency of the system. Specifically, we first have an initial coarse camera pose obtained from consumer-grade GPS/IMU, based on which a label map can be rendered from the 3D semantic map. Then, the rendered label map and the RGB image are jointly fed into a pose CNN, yielding a corrected camera pose. In addition, to incorporate temporal information, a multi-layer recurrent neural network (RNN) is further deployed improve the pose accuracy. Finally, based on the pose from RNN, we render a new label map, which is fed together with the RGB image into a segment CNN which produces per-pixel semantic label. In order to validate our approach, we build a dataset with registered 3D point clouds and video camera images. Both the point clouds and the images are semantically-labeled. Each video frame has ground truth pose from highly accurate motion sensors. We show that practically, pose estimation solely relying on images like PoseNet may fail due to street view confusion, and it is important to fuse multiple sensors. Finally, various ablation studies are performed, which demonstrate the effectiveness of the proposed system. In particular, we show that scene parsing and pose estimation are mutually beneficial to achieve a more robust and accurate system.
Learning Warped Guidance for Blind Face Restoration
Apr 16, 2018
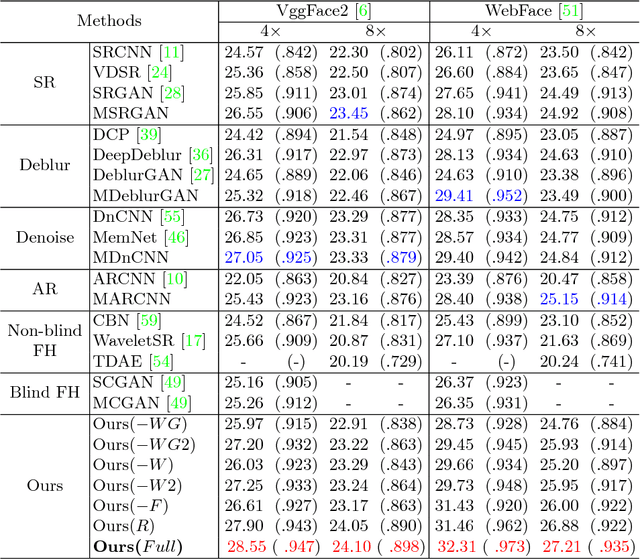
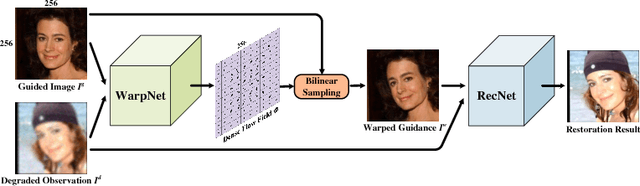
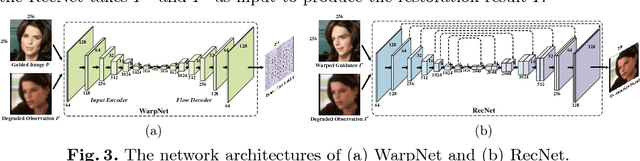
This paper studies the problem of blind face restoration from an unconstrained blurry, noisy, low-resolution, or compressed image (i.e., degraded observation). For better recovery of fine facial details, we modify the problem setting by taking both the degraded observation and a high-quality guided image of the same identity as input to our guided face restoration network (GFRNet). However, the degraded observation and guided image generally are different in pose, illumination and expression, thereby making plain CNNs (e.g., U-Net) fail to recover fine and identity-aware facial details. To tackle this issue, our GFRNet model includes both a warping subnetwork (WarpNet) and a reconstruction subnetwork (RecNet). The WarpNet is introduced to predict flow field for warping the guided image to correct pose and expression (i.e., warped guidance), while the RecNet takes the degraded observation and warped guidance as input to produce the restoration result. Due to that the ground-truth flow field is unavailable, landmark loss together with total variation regularization are incorporated to guide the learning of WarpNet. Furthermore, to make the model applicable to blind restoration, our GFRNet is trained on the synthetic data with versatile settings on blur kernel, noise level, downsampling scale factor, and JPEG quality factor. Experiments show that our GFRNet not only performs favorably against the state-of-the-art image and face restoration methods, but also generates visually photo-realistic results on real degraded facial images.
View Extrapolation of Human Body from a Single Image
Apr 11, 2018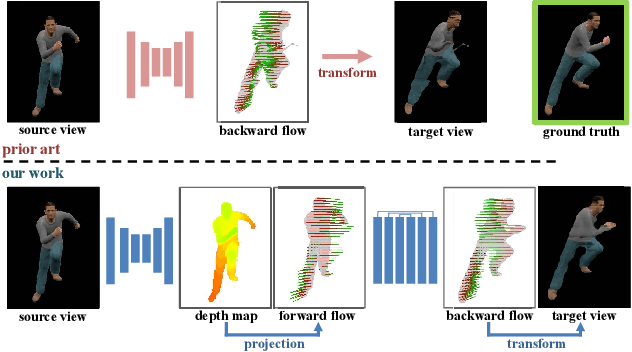
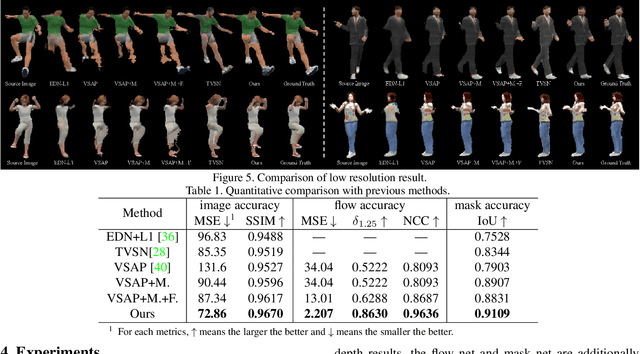
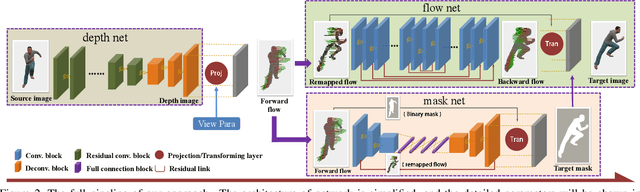
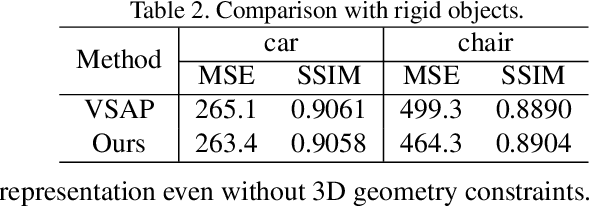
We study how to synthesize novel views of human body from a single image. Though recent deep learning based methods work well for rigid objects, they often fail on objects with large articulation, like human bodies. The core step of existing methods is to fit a map from the observable views to novel views by CNNs; however, the rich articulation modes of human body make it rather challenging for CNNs to memorize and interpolate the data well. To address the problem, we propose a novel deep learning based pipeline that explicitly estimates and leverages the geometry of the underlying human body. Our new pipeline is a composition of a shape estimation network and an image generation network, and at the interface a perspective transformation is applied to generate a forward flow for pixel value transportation. Our design is able to factor out the space of data variation and makes learning at each step much easier. Empirically, we show that the performance for pose-varying objects can be improved dramatically. Our method can also be applied on real data captured by 3D sensors, and the flow generated by our methods can be used for generating high quality results in higher resolution.
Detailed Surface Geometry and Albedo Recovery from RGB-D Video Under Natural Illumination
Mar 22, 2017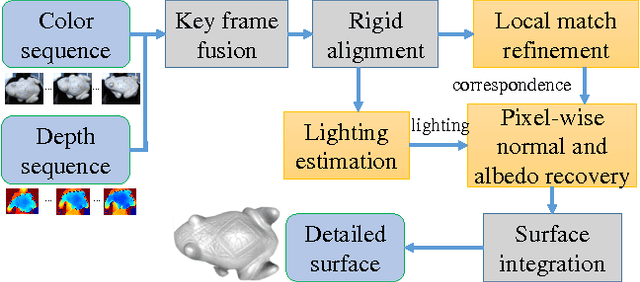

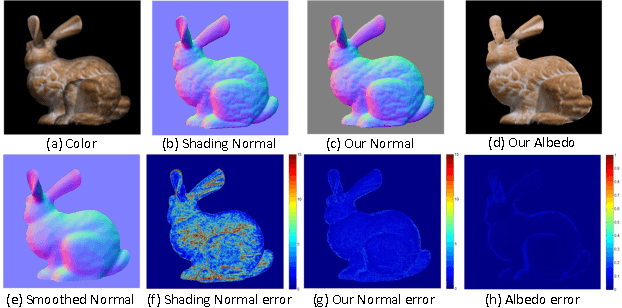
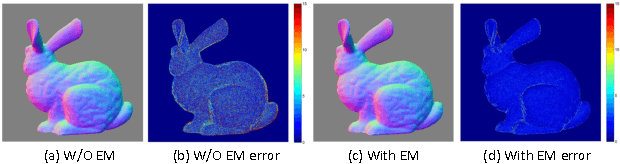
In this paper we present a novel approach for depth map enhancement from an RGB-D video sequence. The basic idea is to exploit the shading information in the color image. Instead of making assumption about surface albedo or controlled object motion and lighting, we use the lighting variations introduced by casual object movement. We are effectively calculating photometric stereo from a moving object under natural illuminations. The key technical challenge is to establish correspondences over the entire image set. We therefore develop a lighting insensitive robust pixel matching technique that out-performs optical flow method in presence of lighting variations. In addition we present an expectation-maximization framework to recover the surface normal and albedo simultaneously, without any regularization term. We have validated our method on both synthetic and real datasets to show its superior performance on both surface details recovery and intrinsic decomposition.
Mask-off: Synthesizing Face Images in the Presence of Head-mounted Displays
Oct 27, 2016

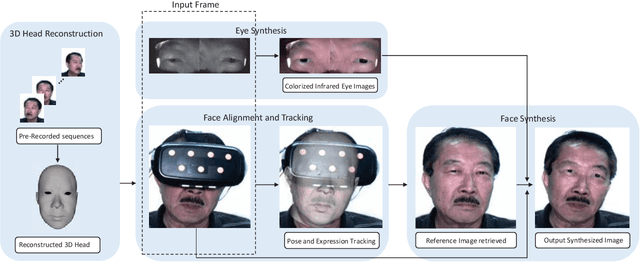

A head-mounted display (HMD) could be an important component of augmented reality system. However, as the upper face region is seriously occluded by the device, the user experience could be affected in applications such as telecommunication and multi-player video games. In this paper, we first present a novel experimental setup that consists of two near-infrared (NIR) cameras to point to the eye regions and one visible-light RGB camera to capture the visible face region. The main purpose of this paper is to synthesize realistic face images without occlusions based on the images captured by these cameras. To this end, we propose a novel synthesis framework that contains four modules: 3D head reconstruction, face alignment and tracking, face synthesis, and eye synthesis. In face synthesis, we propose a novel algorithm that can robustly align and track a personalized 3D head model given a face that is severely occluded by the HMD. In eye synthesis, in order to generate accurate eye movements and dynamic wrinkle variations around eye regions, we propose another novel algorithm to colorize the NIR eye images and further remove the "red eye" effects caused by the colorization. Results show that both hardware setup and system framework are robust to synthesize realistic face images in video sequences.