 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Pseudo-Labeling for Pre-Ranking with LLMs
Feb 24, 2026Pre-ranking is a critical stage in industrial recommendation systems, tasked with efficiently scoring thousands of recalled items for downstream ranking. A key challenge is the train-serving discrepancy: pre-ranking models are trained only on exposed interactions, yet must score all recalled candidates -- including unexposed items -- during online serving. This mismatch not only induces severe sample selection bias but also degrades generalization, especially for long-tail content. Existing debiasing approaches typically rely on heuristics (e.g., negative sampling) or distillation from biased rankers, which either mislabel plausible unexposed items as negatives or propagate exposure bias into pseudo-labels. In this work, we propose Generative Pseudo-Labeling (GPL), a framework that leverages large language models (LLMs) to generate unbiased, content-aware pseudo-labels for unexposed items, explicitly aligning the training distribution with the online serving space. By offline generating user-specific interest anchors and matching them with candidates in a frozen semantic space, GPL provides high-quality supervision without adding online latency. Deployed in a large-scale production system, GPL improves click-through rate by 3.07%, while significantly enhancing recommendation diversity and long-tail item discovery.
HiSAC: Hierarchical Sparse Activation Compression for Ultra-long Sequence Modeling in Recommenders
Feb 24, 2026Modern recommender systems leverage ultra-long user behavior sequences to capture dynamic preferences, but end-to-end modeling is infeasible in production due to latency and memory constraints. While summarizing history via interest centers offers a practical alternative, existing methods struggle to (1) identify user-specific centers at appropriate granularity and (2) accurately assign behaviors, leading to quantization errors and loss of long-tail preferences. To alleviate these issues, we propose Hierarchical Sparse Activation Compression (HiSAC), an efficient framework for personalized sequence modeling. HiSAC encodes interactions into multi-level semantic IDs and constructs a global hierarchical codebook. A hierarchical voting mechanism sparsely activates personalized interest-agents as fine-grained preference centers. Guided by these agents, Soft-Routing Attention aggregates historical signals in semantic space, weighting by similarity to minimize quantization error and retain long-tail behaviors. Deployed on Taobao's "Guess What You Like" homepage, HiSAC achieves significant compression and cost reduction, with online A/B tests showing a consistent 1.65% CTR uplift -- demonstrating its scalability and real-world effectiveness.
RankGR: Rank-Enhanced Generative Retrieval with Listwise Direct Preference Optimization in Recommendation
Feb 09, 2026Generative retrieval (GR) has emerged as a promising paradigm in recommendation systems by autoregressively decoding identifiers of target items. Despite its potential, current approaches typically rely on the next-token prediction schema, which treats each token of the next interacted items as the sole target. This narrow focus 1) limits their ability to capture the nuanced structure of user preferences, and 2) overlooks the deep interaction between decoded identifiers and user behavior sequences. In response to these challenges, we propose RankGR, a Rank-enhanced Generative Retrieval method that incorporates listwise direct preference optimization for recommendation. RankGR decomposes the retrieval process into two complementary stages: the Initial Assessment Phase (IAP) and the Refined Scoring Phase (RSP). In IAP, we incorporate a novel listwise direct preference optimization strategy into GR, thus facilitating a more comprehensive understanding of the hierarchical user preferences and more effective partial-order modeling. The RSP then refines the top-λ candidates generated by IAP with interactions towards input sequences using a lightweight scoring module, leading to more precise candidate evaluation. Both phases are jointly optimized under a unified GR model, ensuring consistency and efficiency. Additionally, we implement several practical improvements in training and deployment, ultimately achieving a real-time system capable of handling nearly ten thousand requests per second. Extensive offline performance on both research and industrial datasets, as well as the online gains on the "Guess You Like" section of Taobao, validate the effectiveness and scalability of RankGR.
ReaSeq: Unleashing World Knowledge via Reasoning for Sequential Modeling
Dec 24, 2025Industrial recommender systems face two fundamental limitations under the log-driven paradigm: (1) knowledge poverty in ID-based item representations that causes brittle interest modeling under data sparsity, and (2) systemic blindness to beyond-log user interests that constrains model performance within platform boundaries. These limitations stem from an over-reliance on shallow interaction statistics and close-looped feedback while neglecting the rich world knowledge about product semantics and cross-domain behavioral patterns that Large Language Models have learned from vast corpora. To address these challenges, we introduce ReaSeq, a reasoning-enhanced framework that leverages world knowledge in Large Language Models to address both limitations through explicit and implicit reasoning. Specifically, ReaSeq employs explicit Chain-of-Thought reasoning via multi-agent collaboration to distill structured product knowledge into semantically enriched item representations, and latent reasoning via Diffusion Large Language Models to infer plausible beyond-log behaviors. Deployed on Taobao's ranking system serving hundreds of millions of users, ReaSeq achieves substantial gains: >6.0% in IPV and CTR, >2.9% in Orders, and >2.5% in GMV, validating the effectiveness of world-knowledge-enhanced reasoning over purely log-driven approaches.
RecGPT-V2 Technical Report
Dec 16, 2025



Large language models (LLMs) have demonstrated remarkable potential in transforming recommender systems from implicit behavioral pattern matching to explicit intent reasoning. While RecGPT-V1 successfully pioneered this paradigm by integrating LLM-based reasoning into user interest mining and item tag prediction, it suffers from four fundamental limitations: (1) computational inefficiency and cognitive redundancy across multiple reasoning routes; (2) insufficient explanation diversity in fixed-template generation; (3) limited generalization under supervised learning paradigms; and (4) simplistic outcome-focused evaluation that fails to match human standards. To address these challenges, we present RecGPT-V2 with four key innovations. First, a Hierarchical Multi-Agent System restructures intent reasoning through coordinated collaboration, eliminating cognitive duplication while enabling diverse intent coverage. Combined with Hybrid Representation Inference that compresses user-behavior contexts, our framework reduces GPU consumption by 60% and improves exclusive recall from 9.39% to 10.99%. Second, a Meta-Prompting framework dynamically generates contextually adaptive prompts, improving explanation diversity by +7.3%. Third, constrained reinforcement learning mitigates multi-reward conflicts, achieving +24.1% improvement in tag prediction and +13.0% in explanation acceptance. Fourth, an Agent-as-a-Judge framework decomposes assessment into multi-step reasoning, improving human preference alignment. Online A/B tests on Taobao demonstrate significant improvements: +2.98% CTR, +3.71% IPV, +2.19% TV, and +11.46% NER. RecGPT-V2 establishes both the technical feasibility and commercial viability of deploying LLM-powered intent reasoning at scale, bridging the gap between cognitive exploration and industrial utility.
DeLS-3D: Deep Localization and Segmentation with a 3D Semantic Map
May 13, 2018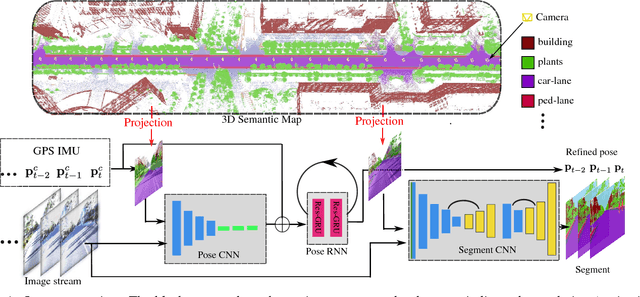

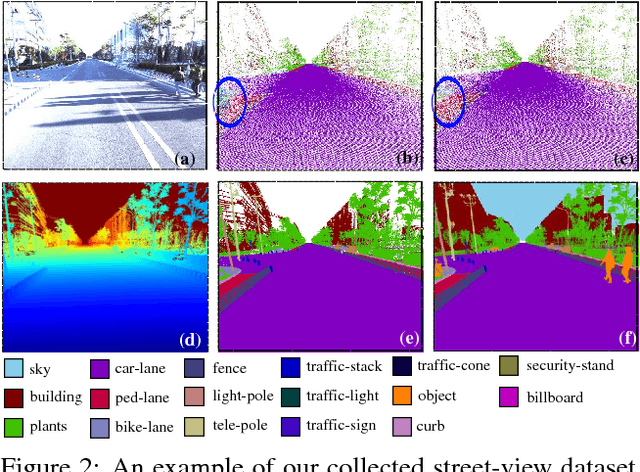
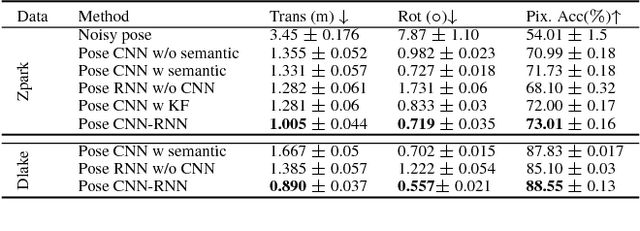
For applications such as autonomous driving, self-localization/camera pose estimation and scene parsing are crucial technologies. In this paper, we propose a unified framework to tackle these two problems simultaneously. The uniqueness of our design is a sensor fusion scheme which integrates camera videos, motion sensors (GPS/IMU), and a 3D semantic map in order to achieve robustness and efficiency of the system. Specifically, we first have an initial coarse camera pose obtained from consumer-grade GPS/IMU, based on which a label map can be rendered from the 3D semantic map. Then, the rendered label map and the RGB image are jointly fed into a pose CNN, yielding a corrected camera pose. In addition, to incorporate temporal information, a multi-layer recurrent neural network (RNN) is further deployed improve the pose accuracy. Finally, based on the pose from RNN, we render a new label map, which is fed together with the RGB image into a segment CNN which produces per-pixel semantic label. In order to validate our approach, we build a dataset with registered 3D point clouds and video camera images. Both the point clouds and the images are semantically-labeled. Each video frame has ground truth pose from highly accurate motion sensors. We show that practically, pose estimation solely relying on images like PoseNet may fail due to street view confusion, and it is important to fuse multiple sensors. Finally, various ablation studies are performed, which demonstrate the effectiveness of the proposed system. In particular, we show that scene parsing and pose estimation are mutually beneficial to achieve a more robust and accurate system.