 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrinsic Concept Extraction Based on Compositional Interpretability
Mar 12, 2026Unsupervised Concept Extraction aims to extract concepts from a single image; however, existing methods suffer from the inability to extract composable intrinsic concepts. To address this, this paper introduces a new task called Compositional and Interpretable Intrinsic Concept Extraction (CI-ICE). The CI-ICE task aims to leverage diffusion-based text-to-image models to extract composable object-level and attribute-level concepts from a single image, such that the original concept can be reconstructed through the combination of these concepts. To achieve this goal, we propose a method called HyperExpress, which addresses the CI-ICE task through two core aspects. Specifically, first, we propose a concept learning approach that leverages the inherent hierarchical modeling capability of hyperbolic space to achieve accurate concept disentanglement while preserving the hierarchical structure and relational dependencies among concepts; second, we introduce a concept-wise optimization method that maps the concept embedding space to maintain complex inter-concept relationships while ensuring concept composability. Our method demonstrates outstanding performance in extracting compositionally interpretable intrinsic concepts from a single image.
Weakly and Self-Supervised Class-Agnostic Motion Prediction for Autonomous Driving
Sep 16, 2025Understanding motion in dynamic environments is critical for autonomous driving, thereby motivating research on class-agnostic motion prediction. In this work, we investigate weakly and self-supervised class-agnostic motion prediction from LiDAR point clouds. Outdoor scenes typically consist of mobile foregrounds and static backgrounds, allowing motion understanding to be associated with scene parsing. Based on this observation, we propose a novel weakly supervised paradigm that replaces motion annotations with fully or partially annotated (1%, 0.1%) foreground/background masks for supervision. To this end, we develop a weakly supervised approach utilizing foreground/background cues to guide the self-supervised learning of motion prediction models. Since foreground motion generally occurs in non-ground regions, non-ground/ground masks can serve as an alternative to foreground/background masks, further reducing annotation effort. Leveraging non-ground/ground cues, we propose two additional approaches: a weakly supervised method requiring fewer (0.01%) foreground/background annotations, and a self-supervised method without annotations. Furthermore, we design a Robust Consistency-aware Chamfer Distance loss that incorporates multi-frame information and robust penalty functions to suppress outliers in self-supervised learning. Experiments show that our weakly and self-supervised models outperform existing self-supervised counterparts, and our weakly supervised models even rival some supervised ones. This demonstrates that our approaches effectively balance annotation effort and performance.
Lumen: A Machine Learning Framework to Expose Influence Cues in Text
Jul 12, 2021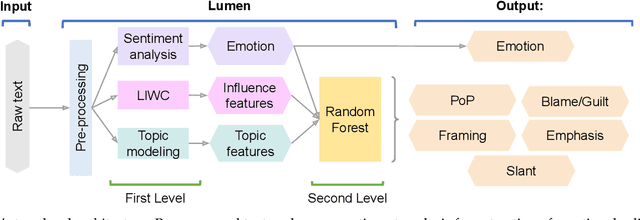
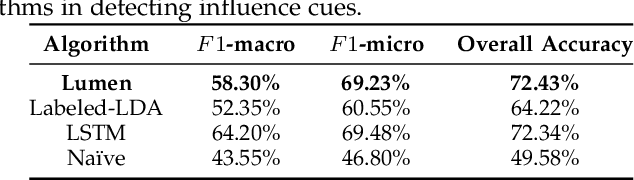
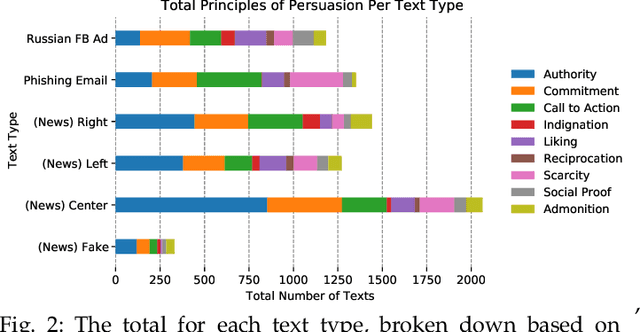
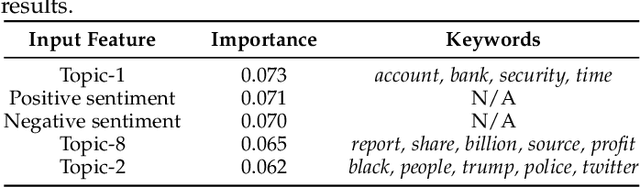
Phishing and disinformation are popular social engineering attacks with attackers invariably applying influence cues in texts to make them more appealing to users. We introduce Lumen, a learning-based framework that exposes influence cues in text: (i) persuasion, (ii) framing, (iii) emotion, (iv) objectivity/subjectivity, (v) guilt/blame, and (vi) use of emphasis. Lumen was trained with a newly developed dataset of 3K texts comprised of disinformation, phishing, hyperpartisan news, and mainstream news. Evaluation of Lumen in comparison to other learning models showed that Lumen and LSTM presented the best F1-micro score, but Lumen yielded better interpretability. Our results highlight the promise of ML to expose influence cues in text, towards the goal of application in automatic labeling tools to improve the accuracy of human-based detection and reduce the likelihood of users falling for deceptive online content.
A new evaluation framework for topic modeling algorithms based on synthetic corpora
Jan 28, 2019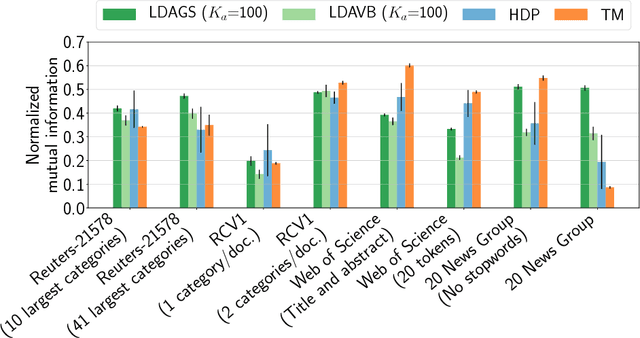
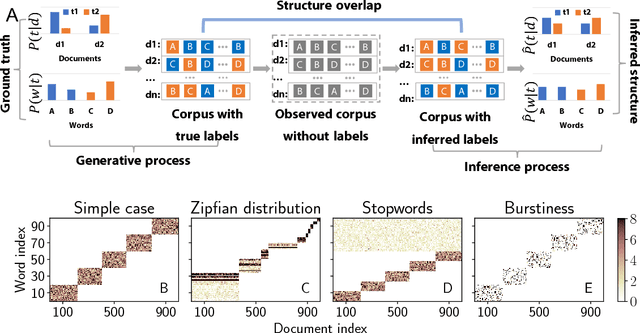
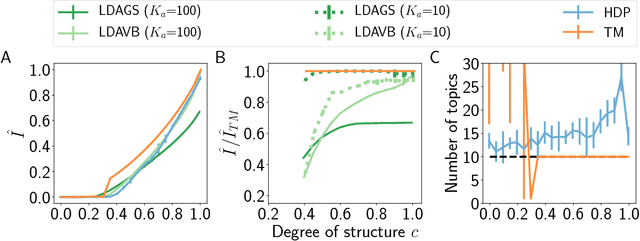
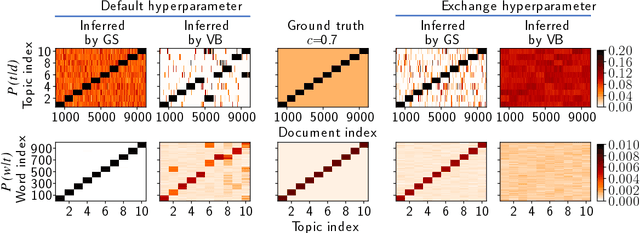
Topic models are in widespread use in natural language processing and beyond. Here, we propose a new framework for the evaluation of probabilistic topic modeling algorithms based on synthetic corpora containing an unambiguously defined ground truth topic structure. The major innovation of our approach is the ability to quantify the agreement between the planted and inferred topic structures by comparing the assigned topic labels at the level of the tokens. In experiments, our approach yields novel insights about the relative strengths of topic models as corpus characteristics vary, and the first evidence of an "undetectable phase" for topic models when the planted structure is weak. We also establish the practical relevance of the insights gained for synthetic corpora by predicting the performance of topic modeling algorithms in classification tasks in real-world corpora.