 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLASH: Latent-Aware Semi-Autoregressive Speculative Decoding for Multimodal Tasks
May 19, 2025Large language and multimodal models (LLMs and LMMs) exhibit strong inference capabilities but are often limited by slow decoding speeds. This challenge is especially acute in LMMs, where visual inputs typically comprise more tokens with lower information density than text -- an issue exacerbated by recent trends toward finer-grained visual tokenizations to boost performance. Speculative decoding has been effective in accelerating LLM inference by using a smaller draft model to generate candidate tokens, which are then selectively verified by the target model, improving speed without sacrificing output quality. While this strategy has been extended to LMMs, existing methods largely overlook the unique properties of visual inputs and depend solely on text-based draft models. In this work, we propose \textbf{FLASH} (Fast Latent-Aware Semi-Autoregressive Heuristics), a speculative decoding framework designed specifically for LMMs, which leverages two key properties of multimodal data to design the draft model. First, to address redundancy in visual tokens, we propose a lightweight latent-aware token compression mechanism. Second, recognizing that visual objects often co-occur within a scene, we employ a semi-autoregressive decoding strategy to generate multiple tokens per forward pass. These innovations accelerate draft decoding while maintaining high acceptance rates, resulting in faster overall inference. Experiments show that FLASH significantly outperforms prior speculative decoding approaches in both unimodal and multimodal settings, achieving up to \textbf{2.68$\times$} speed-up on video captioning and \textbf{2.55$\times$} on visual instruction tuning tasks compared to the original LMM.
DPCN++: Differentiable Phase Correlation Network for Versatile Pose Registration
Jun 12, 2022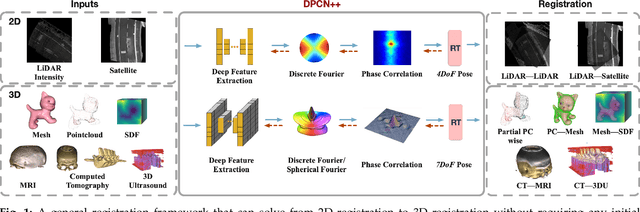
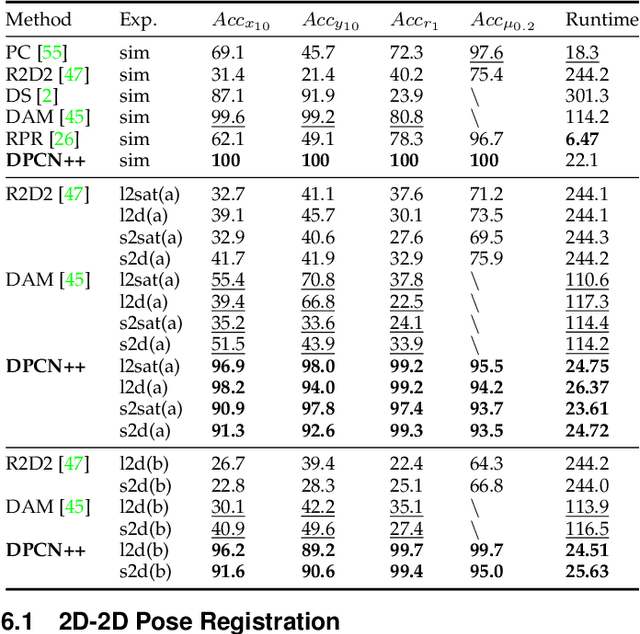
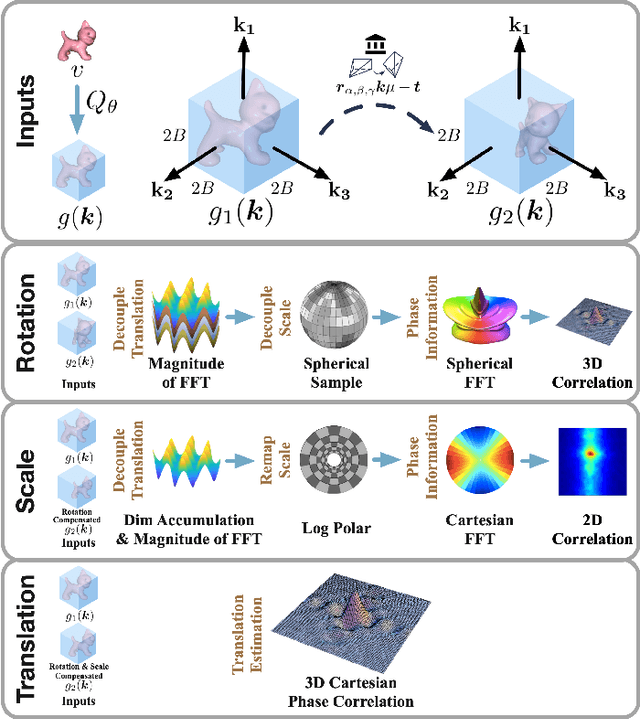

Pose registration is critical in vision and robotics. This paper focuses on the challenging task of initialization-free pose registration up to 7DoF for homogeneous and heterogeneous measurements. While recent learning-based methods show promise using differentiable solvers, they either rely on heuristically defined correspondences or are prone to local minima. We present a differentiable phase correlation (DPC) solver that is globally convergent and correspondence-free. When combined with simple feature extraction networks, our general framework DPCN++ allows for versatile pose registration with arbitrary initialization. Specifically, the feature extraction networks first learn dense feature grids from a pair of homogeneous/heterogeneous measurements. These feature grids are then transformed into a translation and scale invariant spectrum representation based on Fourier transform and spherical radial aggregation, decoupling translation and scale from rotation. Next, the rotation, scale, and translation are independently and efficiently estimated in the spectrum step-by-step using the DPC solver. The entire pipeline is differentiable and trained end-to-end. We evaluate DCPN++ on a wide range of registration tasks taking different input modalities, including 2D bird's-eye view images, 3D object and scene measurements, and medical images. Experimental results demonstrate that DCPN++ outperforms both classical and learning-based baselines, especially on partially observed and heterogeneous measurements.
Fully Differentiable and Interpretable Model for VIO with 4 Trainable Parameters
Sep 25, 2021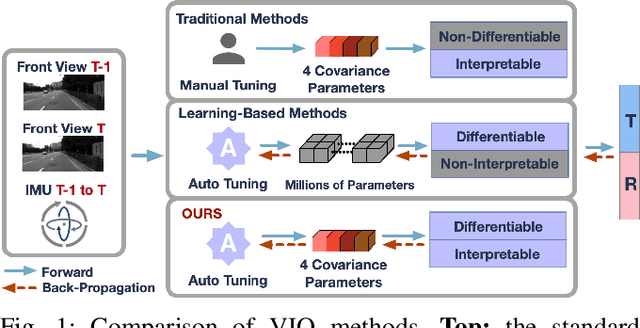
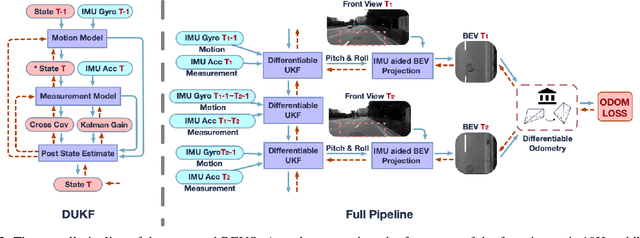
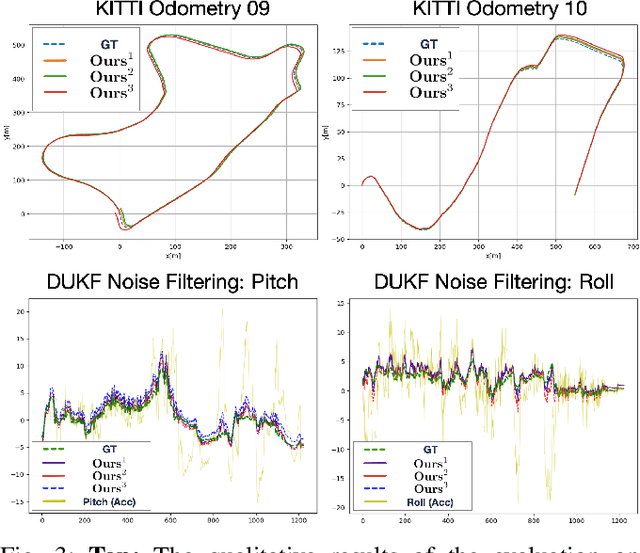
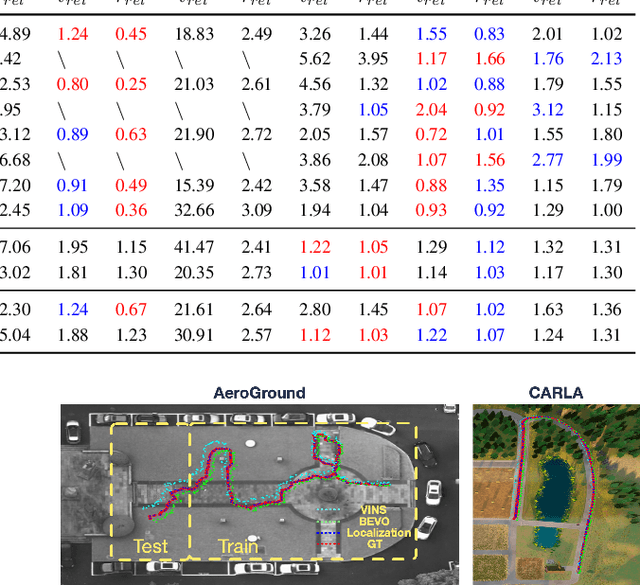
Monocular visual-inertial odometry (VIO) is a critical problem in robotics and autonomous driving. Traditional methods solve this problem based on filtering or optimization. While being fully interpretable, they rely on manual interference and empirical parameter tuning. On the other hand, learning-based approaches allow for end-to-end training but require a large number of training data to learn millions of parameters. However, the non-interpretable and heavy models hinder the generalization ability. In this paper, we propose a fully differentiable, interpretable, and lightweight monocular VIO model that contains only 4 trainable parameters. Specifically, we first adopt Unscented Kalman Filter as a differentiable layer to predict the pitch and roll, where the covariance matrices of noise are learned to filter out the noise of the IMU raw data. Second, the refined pitch and roll are adopted to retrieve a gravity-aligned BEV image of each frame using differentiable camera projection. Finally, a differentiable pose estimator is utilized to estimate the remaining 4 DoF poses between the BEV frames. Our method allows for learning the covariance matrices end-to-end supervised by the pose estimation loss, demonstrating superior performance to empirical baselines. Experimental results on synthetic and real-world datasets demonstrate that our simple approach is competitive with state-of-the-art methods and generalizes well on unseen scenes.