 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime in a Box: Advancing Knowledge Graph Completion with Temporal Scopes
Nov 12, 2021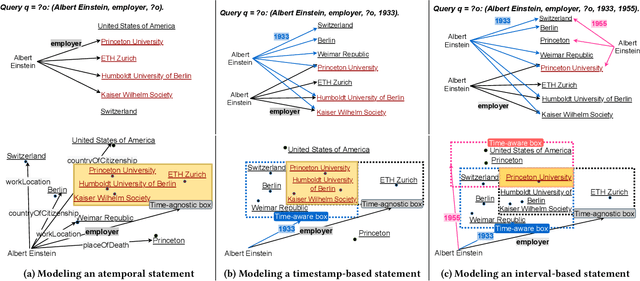
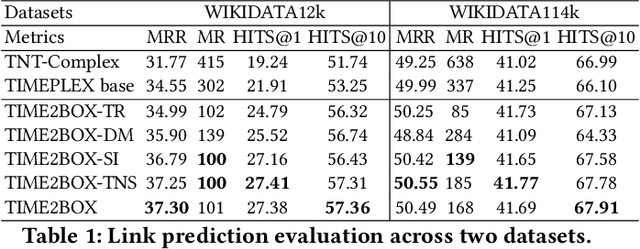
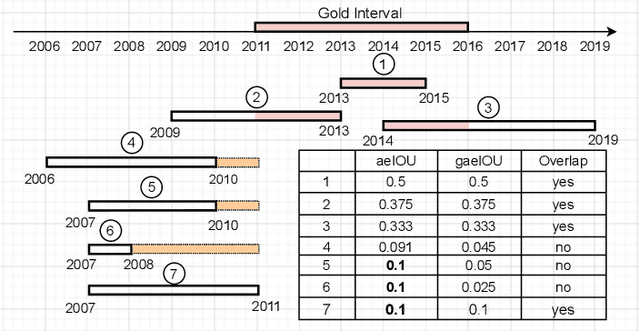
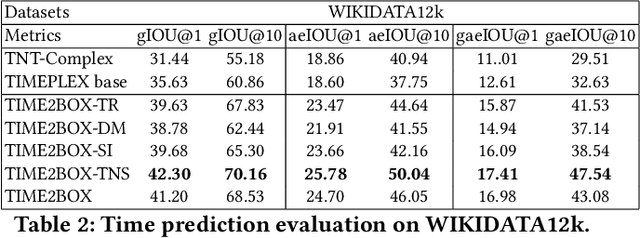
Almost all statements in knowledge bases have a temporal scope during which they are valid. Hence, knowledge base completion (KBC) on temporal knowledge bases (TKB), where each statement \textit{may} be associated with a temporal scope, has attracted growing attention. Prior works assume that each statement in a TKB \textit{must} be associated with a temporal scope. This ignores the fact that the scoping information is commonly missing in a KB. Thus prior work is typically incapable of handling generic use cases where a TKB is composed of temporal statements with/without a known temporal scope. In order to address this issue, we establish a new knowledge base embedding framework, called TIME2BOX, that can deal with atemporal and temporal statements of different types simultaneously. Our main insight is that answers to a temporal query always belong to a subset of answers to a time-agnostic counterpart. Put differently, time is a filter that helps pick out answers to be correct during certain periods. We introduce boxes to represent a set of answer entities to a time-agnostic query. The filtering functionality of time is modeled by intersections over these boxes. In addition, we generalize current evaluation protocols on time interval prediction. We describe experiments on two datasets and show that the proposed method outperforms state-of-the-art (SOTA) methods on both link prediction and time prediction.
A Review of Location Encoding for GeoAI: Methods and Applications
Nov 07, 2021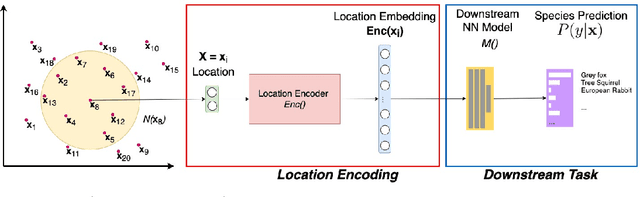
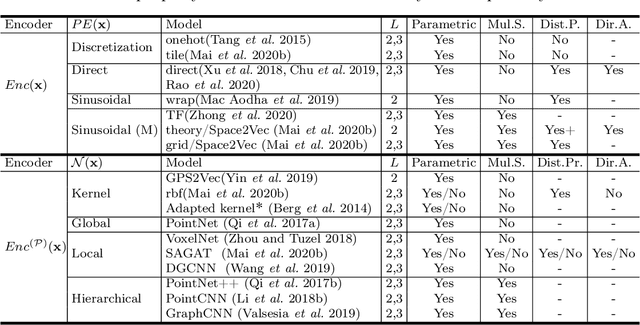
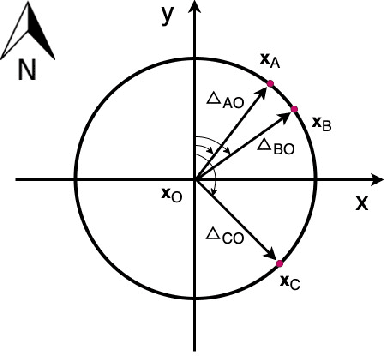
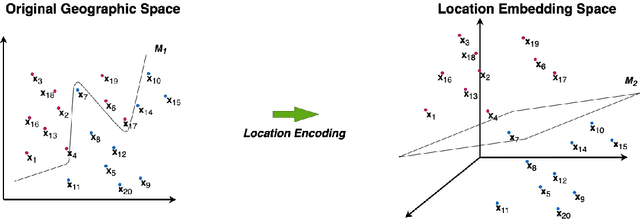
A common need for artificial intelligence models in the broader geoscience is to represent and encode various types of spatial data, such as points (e.g., points of interest), polylines (e.g., trajectories), polygons (e.g., administrative regions), graphs (e.g., transportation networks), or rasters (e.g., remote sensing images), in a hidden embedding space so that they can be readily incorporated into deep learning models. One fundamental step is to encode a single point location into an embedding space, such that this embedding is learning-friendly for downstream machine learning models such as support vector machines and neural networks. We call this process location encoding. However, there lacks a systematic review on the concept of location encoding, its potential applications, and key challenges that need to be addressed. This paper aims to fill this gap. We first provide a formal definition of location encoding, and discuss the necessity of location encoding for GeoAI research from a machine learning perspective. Next, we provide a comprehensive survey and discussion about the current landscape of location encoding research. We classify location encoding models into different categories based on their inputs and encoding methods, and compare them based on whether they are parametric, multi-scale, distance preserving, and direction aware. We demonstrate that existing location encoding models can be unified under a shared formulation framework. We also discuss the application of location encoding for different types of spatial data. Finally, we point out several challenges in location encoding research that need to be solved in the future.
* 32 Pages, 5 Figures, Accepted to International Journal of Geographical Information Science, 2021
Improving Contrastive Learning by Visualizing Feature Transformation
Aug 06, 2021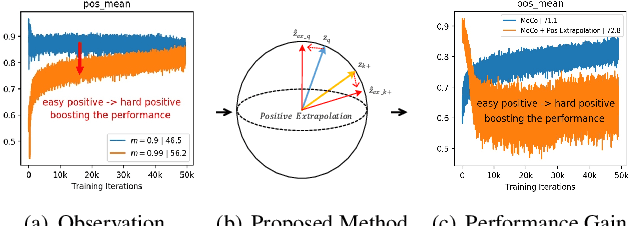

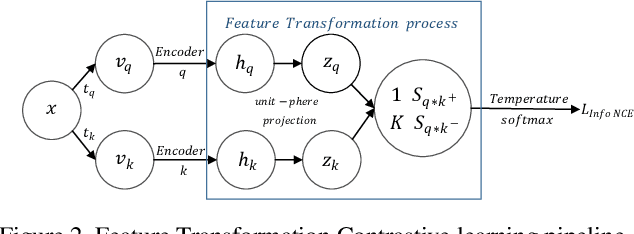

Contrastive learning, which aims at minimizing the distance between positive pairs while maximizing that of negative ones, has been widely and successfully applied in unsupervised feature learning, where the design of positive and negative (pos/neg) pairs is one of its keys. In this paper, we attempt to devise a feature-level data manipulation, differing from data augmentation, to enhance the generic contrastive self-supervised learning. To this end, we first design a visualization scheme for pos/neg score (Pos/neg score indicates cosine similarity of pos/neg pair.) distribution, which enables us to analyze, interpret and understand the learning process. To our knowledge, this is the first attempt of its kind. More importantly, leveraging this tool, we gain some significant observations, which inspire our novel Feature Transformation proposals including the extrapolation of positives. This operation creates harder positives to boost the learning because hard positives enable the model to be more view-invariant. Besides, we propose the interpolation among negatives, which provides diversified negatives and makes the model more discriminative. It is the first attempt to deal with both challenges simultaneously. Experiment results show that our proposed Feature Transformation can improve at least 6.0% accuracy on ImageNet-100 over MoCo baseline, and about 2.0% accuracy on ImageNet-1K over the MoCoV2 baseline. Transferring to the downstream tasks successfully demonstrate our model is less task-bias. Visualization tools and codes https://github.com/DTennant/CL-Visualizing-Feature-Transformation .
Geographic Question Answering: Challenges, Uniqueness, Classification, and Future Directions
May 19, 2021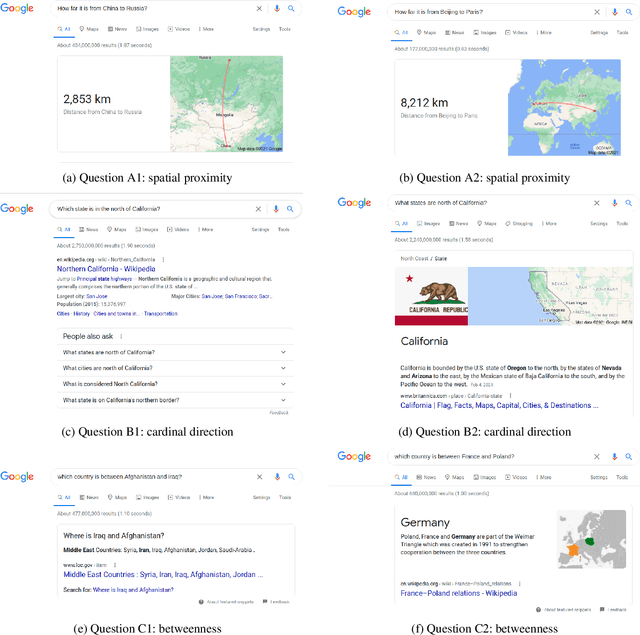
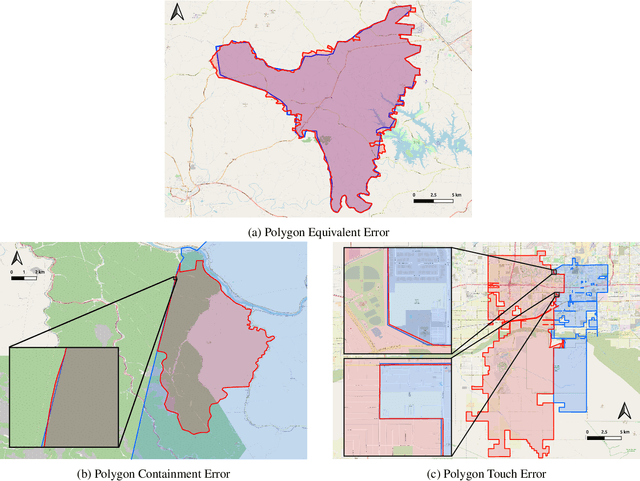
As an important part of Artificial Intelligence (AI), Question Answering (QA) aims at generating answers to questions phrased in natural language. While there has been substantial progress in open-domain question answering, QA systems are still struggling to answer questions which involve geographic entities or concepts and that require spatial operations. In this paper, we discuss the problem of geographic question answering (GeoQA). We first investigate the reasons why geographic questions are difficult to answer by analyzing challenges of geographic questions. We discuss the uniqueness of geographic questions compared to general QA. Then we review existing work on GeoQA and classify them by the types of questions they can address. Based on this survey, we provide a generic classification framework for geographic questions. Finally, we conclude our work by pointing out unique future research directions for GeoQA.
* 20 pages, 3 figure, Full paper accepted to AGILE 2021
Boosting Semi-Supervised Face Recognition with Noise Robustness
May 10, 2021
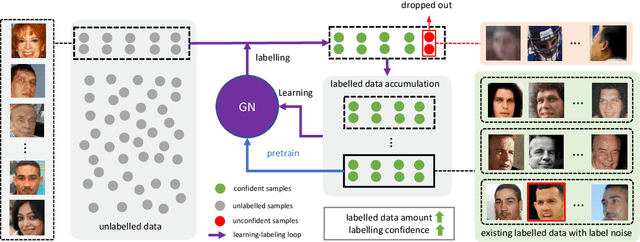


Although deep face recognition benefits significantly from large-scale training data, a current bottleneck is the labelling cost. A feasible solution to this problem is semi-supervised learning, exploiting a small portion of labelled data and large amounts of unlabelled data. The major challenge, however, is the accumulated label errors through auto-labelling, compromising the training. This paper presents an effective solution to semi-supervised face recognition that is robust to the label noise aroused by the auto-labelling. Specifically, we introduce a multi-agent method, named GroupNet (GN), to endow our solution with the ability to identify the wrongly labelled samples and preserve the clean samples. We show that GN alone achieves the leading accuracy in traditional supervised face recognition even when the noisy labels take over 50\% of the training data. Further, we develop a semi-supervised face recognition solution, named Noise Robust Learning-Labelling (NRoLL), which is based on the robust training ability empowered by GN. It starts with a small amount of labelled data and consequently conducts high-confidence labelling on a large amount of unlabelled data to boost further training. The more data is labelled by NRoLL, the higher confidence is with the label in the dataset. To evaluate the competitiveness of our method, we run NRoLL with a rough condition that only one-fifth of the labelled MSCeleb is available and the rest is used as unlabelled data. On a wide range of benchmarks, our method compares favorably against the state-of-the-art methods.
Robust Classification via Support Vector Machines
Apr 27, 2021
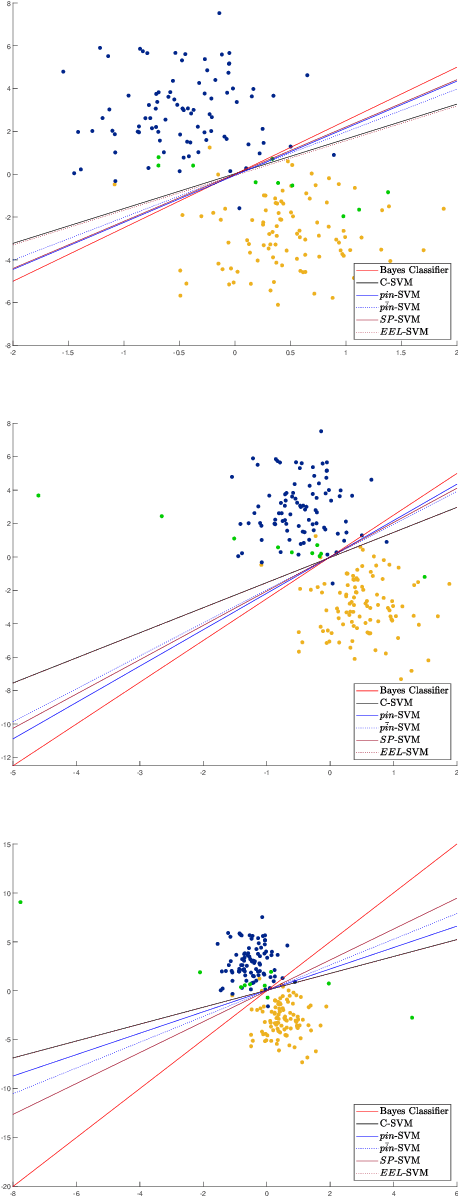
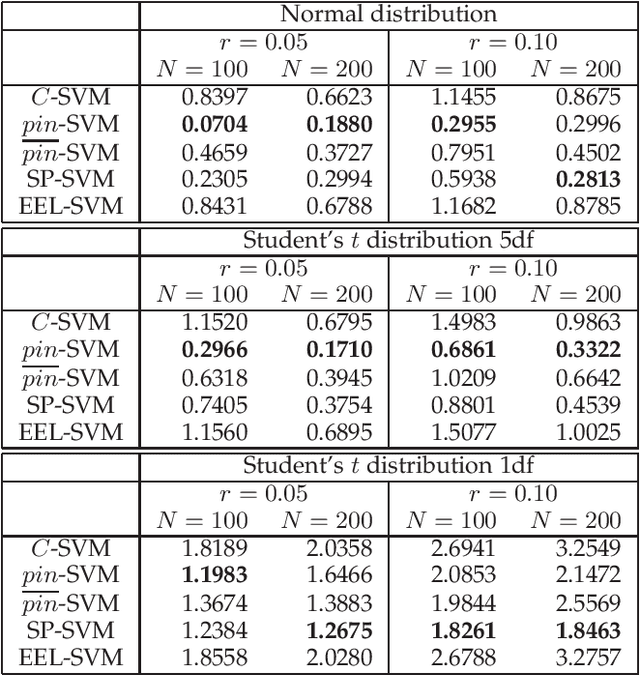
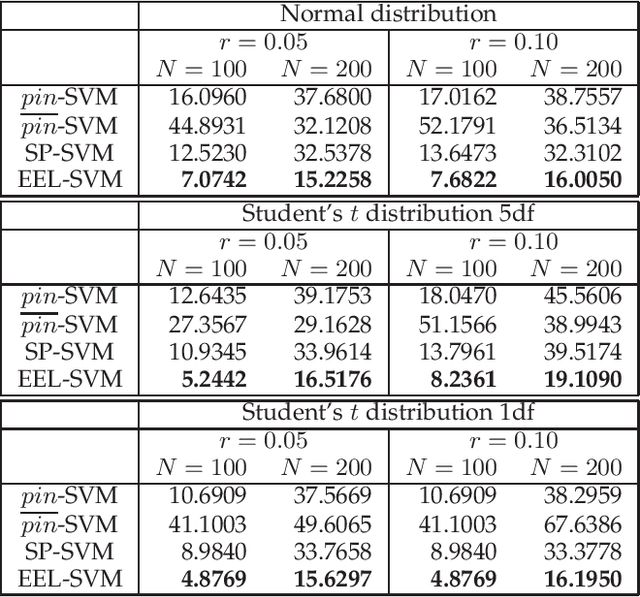
The loss function choice for any Support Vector Machine classifier has raised great interest in the literature due to the lack of robustness of the Hinge loss, which is the standard loss choice. In this paper, we plan to robustify the binary classifier by maintaining the overall advantages of the Hinge loss, rather than modifying this standard choice. We propose two robust classifiers under data uncertainty. The first is called Single Perturbation SVM (SP-SVM) and provides a constructive method by allowing a controlled perturbation to one feature of the data. The second method is called Extreme Empirical Loss SVM (EEL-SVM) and is based on a new empirical loss estimate, namely, the Extreme Empirical Loss (EEL), that puts more emphasis on extreme violations of the classification hyper-plane, rather than taking the usual sample average with equal importance for all hyper-plane violations. Extensive numerical investigation reveals the advantages of the two robust classifiers on simulated data and well-known real datasets.
Imitating Interactive Intelligence
Jan 21, 2021
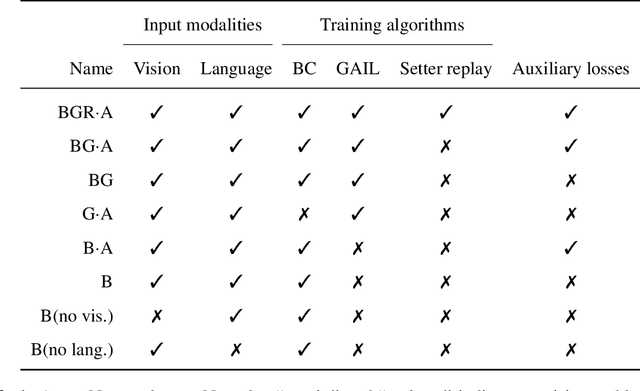
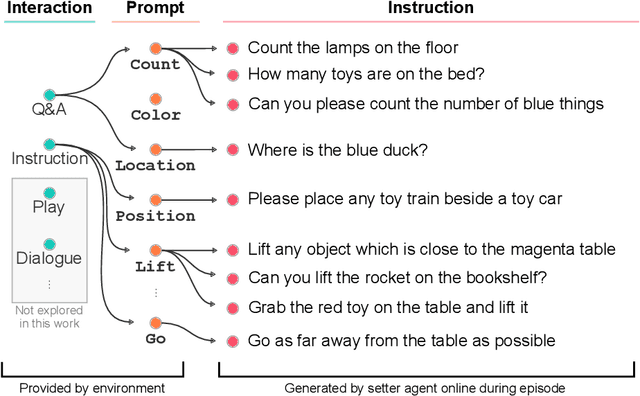
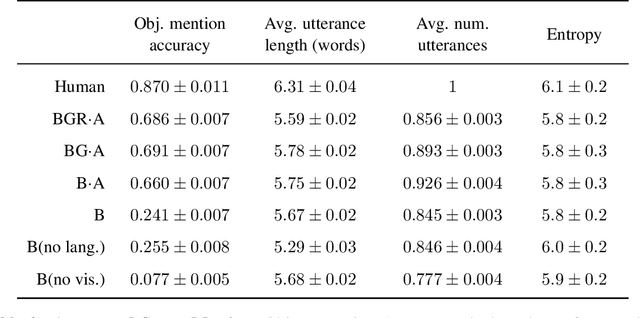
A common vision from science fiction is that robots will one day inhabit our physical spaces, sense the world as we do, assist our physical labours, and communicate with us through natural language. Here we study how to design artificial agents that can interact naturally with humans using the simplification of a virtual environment. This setting nevertheless integrates a number of the central challenges of artificial intelligence (AI) research: complex visual perception and goal-directed physical control, grounded language comprehension and production, and multi-agent social interaction. To build agents that can robustly interact with humans, we would ideally train them while they interact with humans. However, this is presently impractical. Therefore, we approximate the role of the human with another learned agent, and use ideas from inverse reinforcement learning to reduce the disparities between human-human and agent-agent interactive behaviour. Rigorously evaluating our agents poses a great challenge, so we develop a variety of behavioural tests, including evaluation by humans who watch videos of agents or interact directly with them. These evaluations convincingly demonstrate that interactive training and auxiliary losses improve agent behaviour beyond what is achieved by supervised learning of actions alone. Further, we demonstrate that agent capabilities generalise beyond literal experiences in the dataset. Finally, we train evaluation models whose ratings of agents agree well with human judgement, thus permitting the evaluation of new agent models without additional effort. Taken together, our results in this virtual environment provide evidence that large-scale human behavioural imitation is a promising tool to create intelligent, interactive agents, and the challenge of reliably evaluating such agents is possible to surmount.
Single View Metrology in the Wild
Aug 11, 2020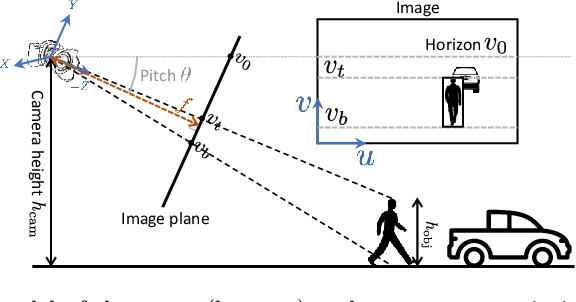

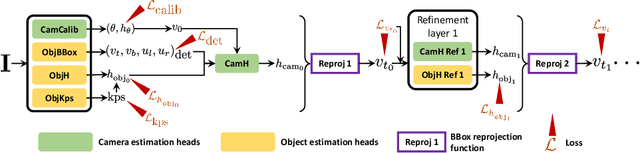
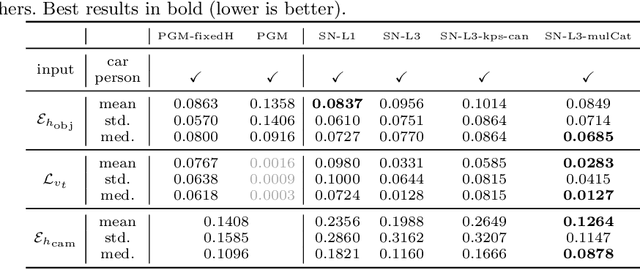
Most 3D reconstruction methods may only recover scene properties up to a global scale ambiguity. We present a novel approach to single view metrology that can recover the absolute scale of a scene represented by 3D heights of objects or camera height above the ground as well as camera parameters of orientation and field of view, using just a monocular image acquired in unconstrained condition. Our method relies on data-driven priors learned by a deep network specifically designed to imbibe weakly supervised constraints from the interplay of the unknown camera with 3D entities such as object heights, through estimation of bounding box projections. We leverage categorical priors for objects such as humans or cars that commonly occur in natural images, as references for scale estimation. We demonstrate state-of-the-art qualitative and quantitative results on several datasets as well as applications including virtual object insertion. Furthermore, the perceptual quality of our outputs is validated by a user study.
Deep Keypoint-Based Camera Pose Estimation with Geometric Constraints
Jul 29, 2020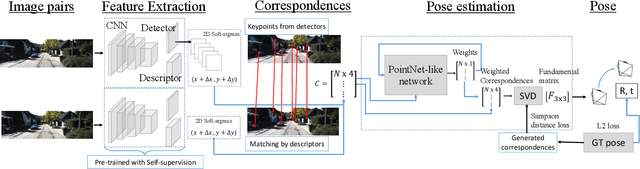
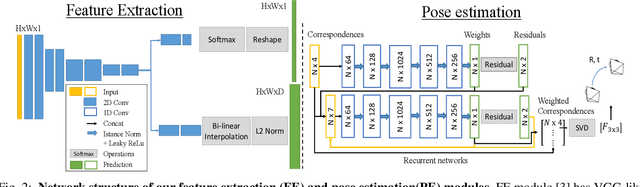


Estimating relative camera poses from consecutive frames is a fundamental problem in visual odometry (VO) and simultaneous localization and mapping (SLAM), where classic methods consisting of hand-crafted features and sampling-based outlier rejection have been a dominant choice for over a decade. Although multiple works propose to replace these modules with learning-based counterparts, most have not yet been as accurate, robust and generalizable as conventional methods. In this paper, we design an end-to-end trainable framework consisting of learnable modules for detection, feature extraction, matching and outlier rejection, while directly optimizing for the geometric pose objective. We show both quantitatively and qualitatively that pose estimation performance may be achieved on par with the classic pipeline. Moreover, we are able to show by end-to-end training, the key components of the pipeline could be significantly improved, which leads to better generalizability to unseen datasets compared to existing learning-based methods.
Bounding The Number of Linear Regions in Local Area for Neural Networks with ReLU Activations
Jul 14, 2020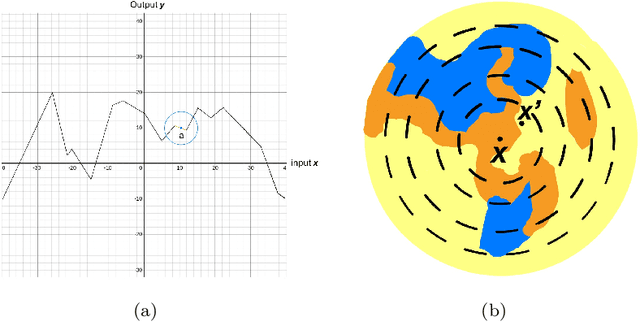
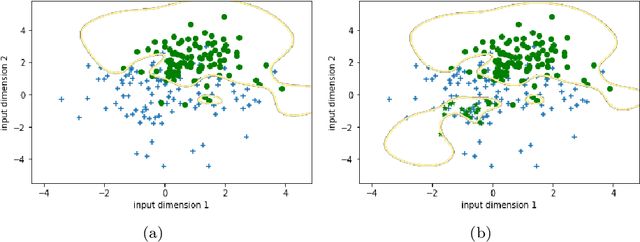
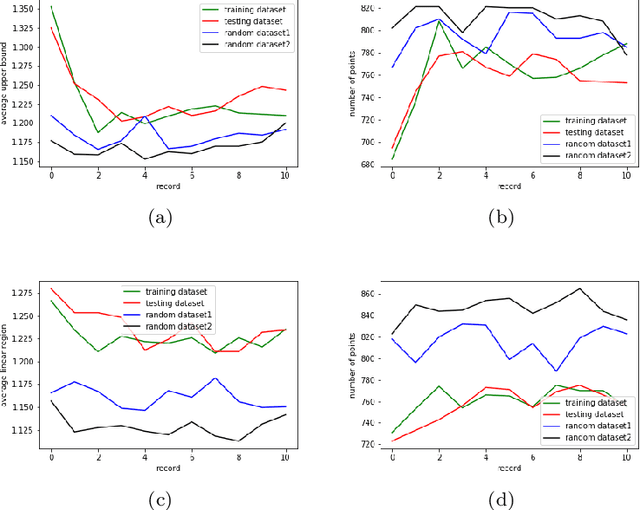
The number of linear regions is one of the distinct properties of the neural networks using piecewise linear activation functions such as ReLU, comparing with those conventional ones using other activation functions. Previous studies showed this property reflected the expressivity of a neural network family ([14]); as a result, it can be used to characterize how the structural complexity of a neural network model affects the function it aims to compute. Nonetheless, it is challenging to directly compute the number of linear regions; therefore, many researchers focus on estimating the bounds (in particular the upper bound) of the number of linear regions for deep neural networks using ReLU. These methods, however, attempted to estimate the upper bound in the entire input space. The theoretical methods are still lacking to estimate the number of linear regions within a specific area of the input space, e.g., a sphere centered at a training data point such as an adversarial example or a backdoor trigger. In this paper, we present the first method to estimate the upper bound of the number of linear regions in any sphere in the input space of a given ReLU neural network. We implemented the method, and computed the bounds in deep neural networks using the piece-wise linear active function. Our experiments showed that, while training a neural network, the boundaries of the linear regions tend to move away from the training data points. In addition, we observe that the spheres centered at the training data points tend to contain more linear regions than any arbitrary points in the input space. To the best of our knowledge, this is the first study of bounding linear regions around a specific data point. We consider our work as a first step toward the investigation of the structural complexity of deep neural networks in a specific input area.