 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeMix: How to Better Utilize Data Augmentation
Oct 03, 2020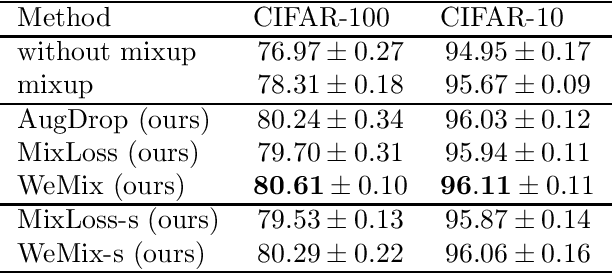


Data augmentation is a widely used training trick in deep learning to improve the network generalization ability. Despite many encouraging results, several recent studies did point out limitations of the conventional data augmentation scheme in certain scenarios, calling for a better theoretical understanding of data augmentation. In this work, we develop a comprehensive analysis that reveals pros and cons of data augmentation. The main limitation of data augmentation arises from the data bias, i.e. the augmented data distribution can be quite different from the original one. This data bias leads to a suboptimal performance of existing data augmentation methods. To this end, we develop two novel algorithms, termed "AugDrop" and "MixLoss", to correct the data bias in the data augmentation. Our theoretical analysis shows that both algorithms are guaranteed to improve the effect of data augmentation through the bias correction, which is further validated by our empirical studies. Finally, we propose a generic algorithm "WeMix" by combining AugDrop and MixLoss, whose effectiveness is observed from extensive empirical evaluations.
Neural Architecture Design for GPU-Efficient Networks
Jul 12, 2020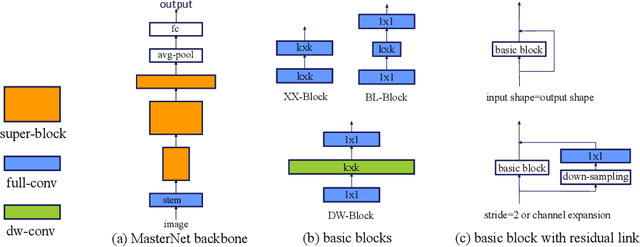
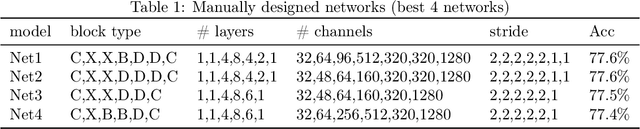
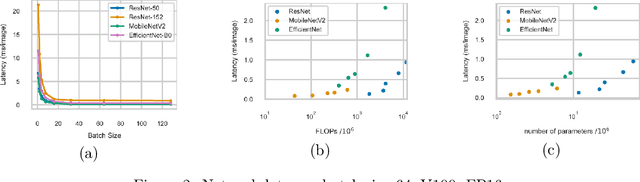
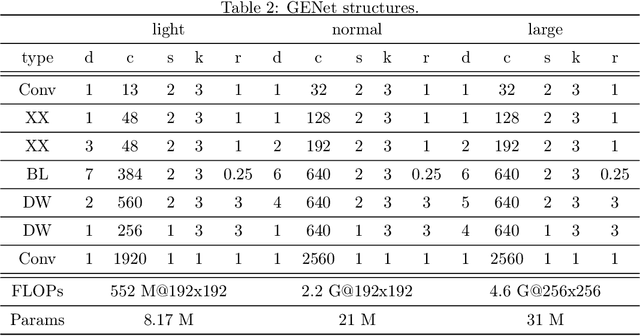
Many mission-critical systems are based on GPU for inference. It requires not only high recognition accuracy but also low latency in responding time. Although many studies are devoted to optimizing the structure of deep models for efficient inference, most of them do not leverage the architecture of \textbf{modern GPU} for fast inference, leading to suboptimal performance. To address this issue, we propose a general principle for designing GPU-efficient networks based on extensive empirical studies. This design principle enables us to search for GPU-efficient network structures effectively by a simple and lightweight method as opposed to most Neural Architecture Search (NAS) methods that are complicated and computationally expensive. Based on the proposed framework, we design a family of GPU-Efficient Networks, or GENets in short. We did extensive evaluations on multiple GPU platforms and inference engines. While achieving $\geq 81.3\%$ top-1 accuracy on ImageNet, GENet is up to $6.4$ times faster than EfficienNet on GPU. It also outperforms most state-of-the-art models that are more efficient than EfficientNet in high precision regimes. Our source code and pre-trained models are available from \url{https://github.com/idstcv/GPU-Efficient-Networks}.
Towards Understanding Label Smoothing
Jun 20, 2020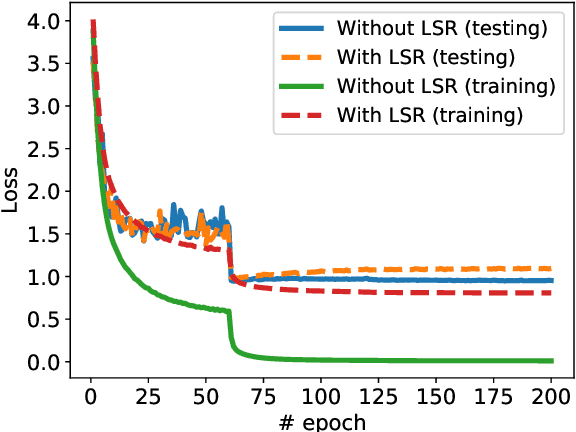

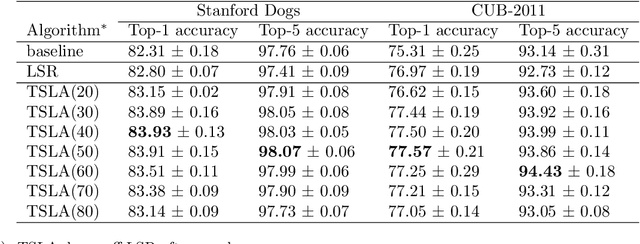
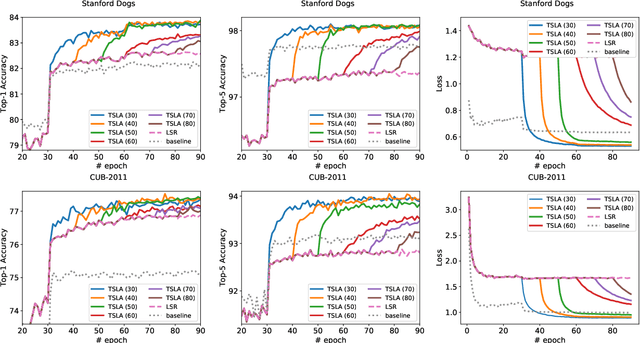
Label smoothing regularization (LSR) has a great success in training deep neural networks by stochastic algorithms such as stochastic gradient descent and its variants. However, the theoretical understanding of its power from the view of optimization is still rare. This study opens the door to a deep understanding of LSR by initiating the analysis. In this paper, we analyze the convergence behaviors of stochastic gradient descent with LSR for solving non-convex problems and show that an appropriate LSR can help to speed up the convergence by reducing the variance of labels. More interestingly, we proposed a simple and efficient strategy, namely Two-Stage LAbel smoothing algorithm (TSLA), that uses LSR in the early training epochs and drops it off in the later training epochs. We observe from the improved convergence result of TSLA that it benefits from LSR in the first stage and essentially converges faster in the second stage. To the best of our knowledge, this is the first work for understanding the power of LSR via establishing convergence complexity of stochastic methods with LSR in non-convex optimization. We empirically demonstrate the effectiveness of the proposed method in comparison with baselines on training ResNet models over public data sets.
A Practical Online Method for Distributionally Deep Robust Optimization
Jun 17, 2020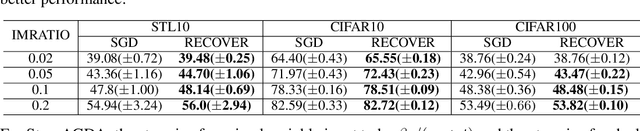
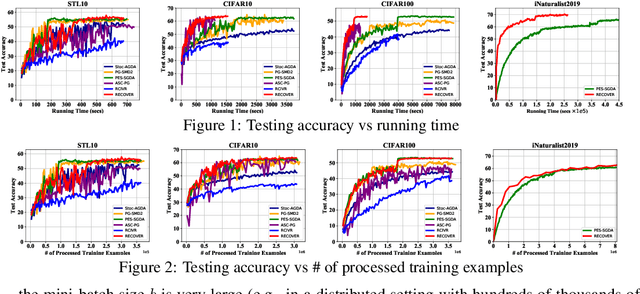
In this paper, we propose a practical online method for solving a distributionally robust optimization (DRO) for deep learning, which has important applications in machine learning for improving the robustness of neural networks. In the literature, most methods for solving DRO are based on stochastic primal-dual methods. However, primal-dual methods for deep DRO suffer from several drawbacks: (1) manipulating a high-dimensional dual variable corresponding to the size of data is time expensive; (2) they are not friendly to online learning where data is coming sequentially. To address these issues, we transform the min-max formulation into a minimization formulation and propose a practical duality-free online stochastic method for solving deep DRO with KL divergence regularization. The proposed online stochastic method resembles the practical stochastic Nesterov's method in several perspectives that are widely used for learning deep neural networks. Under a Polyak-Lojasiewicz (PL) condition, we prove that the proposed method can enjoy an optimal sample complexity and a better round complexity (the number of gradient evaluations divided by a fixed mini-batch size) with a moderate mini-batch size than existing algorithms for solving the min-max or min formulation of DRO. Of independent interest, the proposed method can be also used for solving a family of stochastic compositional problems.
Representation Learning with Fine-grained Patterns
May 19, 2020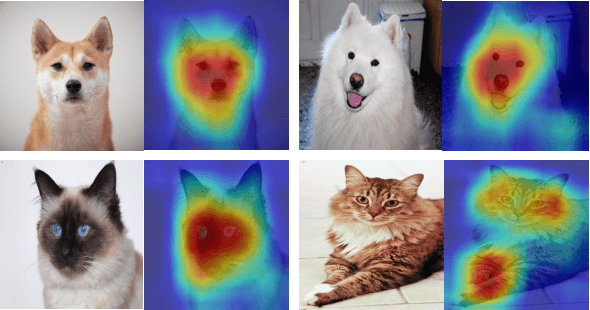
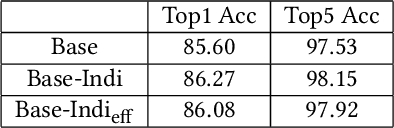
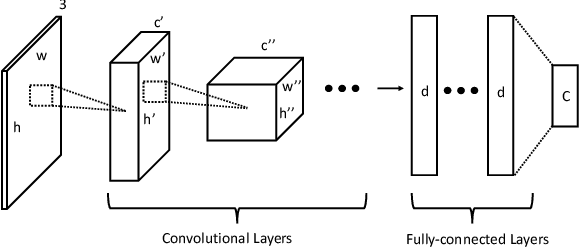
With the development of computational power and techniques for data collection, deep learning demonstrates a superior performance over many existing algorithms on benchmark data sets. Many efforts have been devoted to studying the mechanism of deep learning. One of important observations is that deep learning can learn the discriminative patterns from raw materials directly in a task-dependent manner. It makes the patterns obtained by deep learning outperform hand-crafted features significantly. However, those patterns can be misled by the training task when the target task is different. In this work, we investigate a prevalent problem in real-world applications, where the training set only accesses to the supervised information from superclasses but the target task is defined on fine-grained classes. Each superclass can contain multiple fine-grained classes. In this scenario, fine-grained patterns are essential to classify examples from fine-grained classes while they can be neglected when training only with labels from superclasses. To mitigate the challenge, we propose the algorithm to explore the fine-grained patterns sufficiently without additional supervised information. Besides, our analysis indicates that the performance of learned patterns on the fine-grained classes can be theoretically guaranteed. Finally, an efficient algorithm is developed to reduce the cost of optimization. The experiments on real-world data sets verify that the propose algorithm can significantly improve the performance on the fine-grained classes with information from superclasses only.
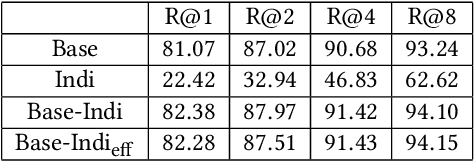
SoftTriple Loss: Deep Metric Learning Without Triplet Sampling
Sep 11, 2019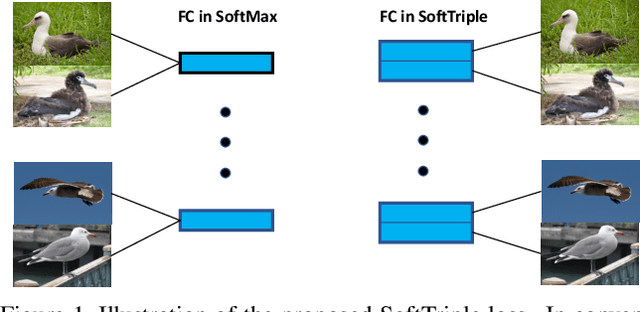
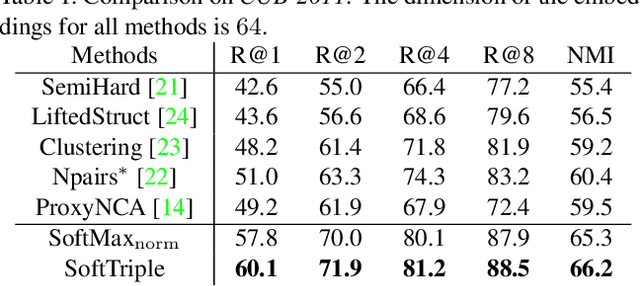
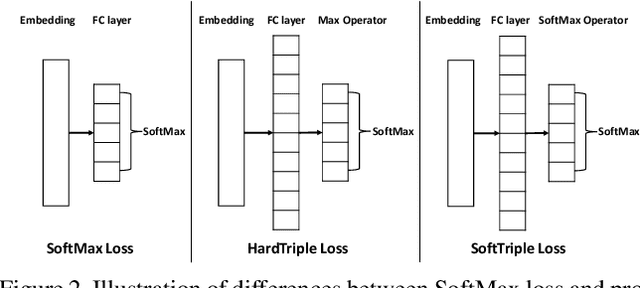
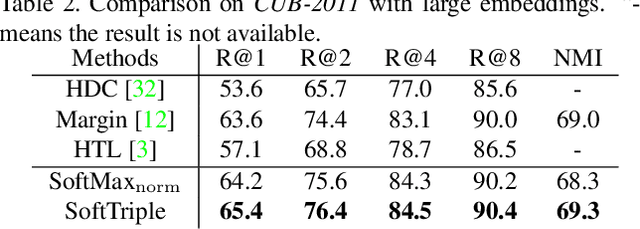
Distance metric learning (DML) is to learn the embeddings where examples from the same class are closer than examples from different classes. It can be cast as an optimization problem with triplet constraints. Due to the vast number of triplet constraints, a sampling strategy is essential for DML. With the tremendous success of deep learning in classifications, it has been applied for DML. When learning embeddings with deep neural networks (DNNs), only a mini-batch of data is available at each iteration. The set of triplet constraints has to be sampled within the mini-batch. Since a mini-batch cannot capture the neighbors in the original set well, it makes the learned embeddings sub-optimal. On the contrary, optimizing SoftMax loss, which is a classification loss, with DNN shows a superior performance in certain DML tasks. It inspires us to investigate the formulation of SoftMax. Our analysis shows that SoftMax loss is equivalent to a smoothed triplet loss where each class has a single center. In real-world data, one class can contain several local clusters rather than a single one, e.g., birds of different poses. Therefore, we propose the SoftTriple loss to extend the SoftMax loss with multiple centers for each class. Compared with conventional deep metric learning algorithms, optimizing SoftTriple loss can learn the embeddings without the sampling phase by mildly increasing the size of the last fully connected layer. Experiments on the benchmark fine-grained data sets demonstrate the effectiveness of the proposed loss function.
DR Loss: Improving Object Detection by Distributional Ranking
Jul 23, 2019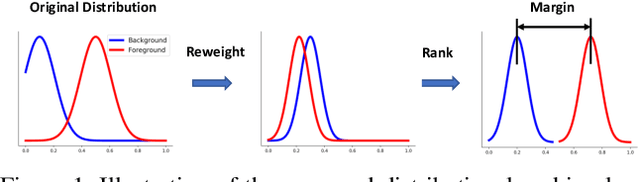
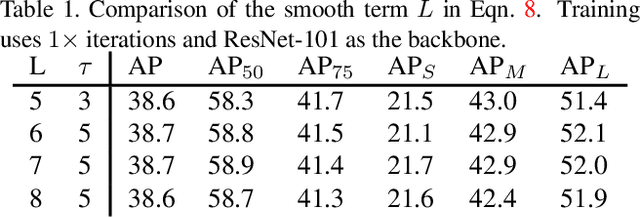
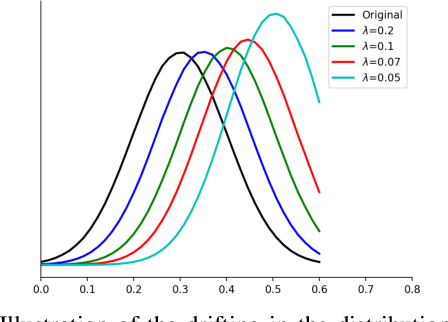

Most of object detection algorithms can be categorized into two classes: two-stage detectors and one-stage detectors. For two-stage detectors, a region proposal phase can filter massive background candidates in the first stage and it masks the classification task more balanced in the second stage. Recently, one-stage detectors have attracted much attention due to its simple yet effective architecture. Different from two-stage detectors, one-stage detectors have to identify foreground objects from all candidates in a single stage. This architecture is efficient but can suffer from the imbalance issue with respect to two aspects: the imbalance between classes and that in the distribution of background, where only a few candidates are hard to be identified. In this work, we propose to address the challenge by developing the distributional ranking (DR) loss. First, we convert the classification problem to a ranking problem to alleviate the class-imbalance problem. Then, we propose to rank the distribution of foreground candidates above that of background ones in the constrained worst-case scenario. This strategy not only handles the imbalance in background candidates but also improves the efficiency for the ranking algorithm. Besides the classification task, we also improve the regression loss by gradually approaching the $L_1$ loss as suggested in interior-point methods. To evaluate the proposed losses, we replace the corresponding losses in RetinaNet that reports the state-of-the-art performance as a one-stage detector. With the ResNet-101 as the backbone, our method can improve mAP on COCO data set from $39.1\%$ to $41.1\%$ by only changing the loss functions and it verifies the effectiveness of the proposed losses.
XNAS: Neural Architecture Search with Expert Advice
Jun 19, 2019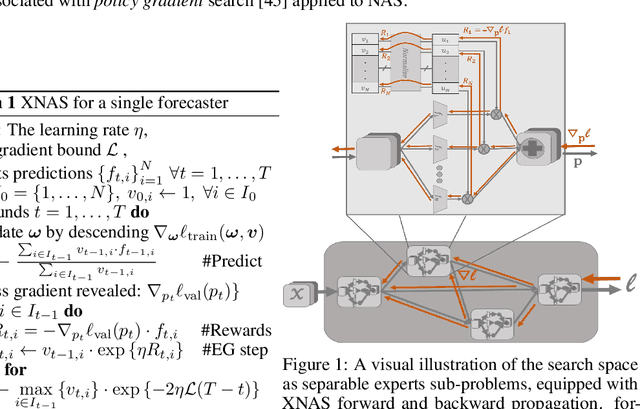
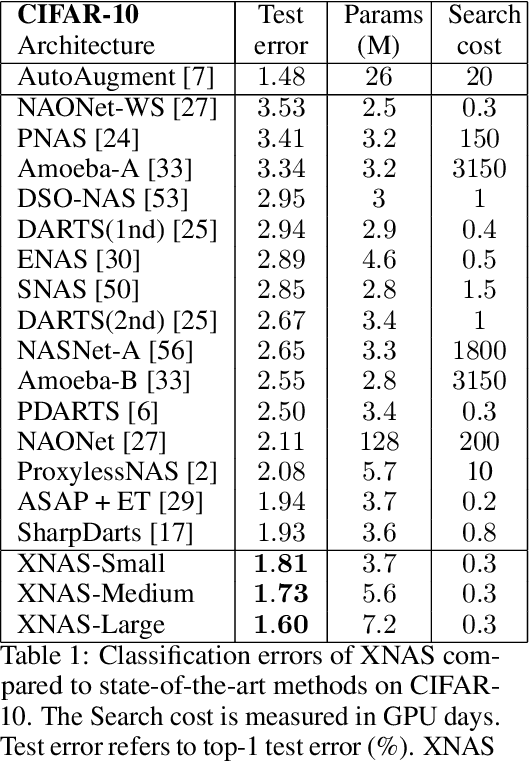
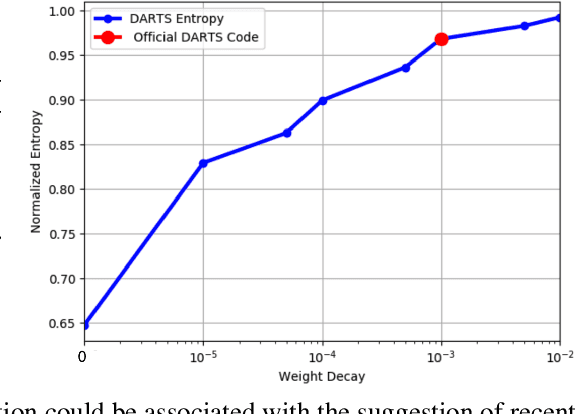
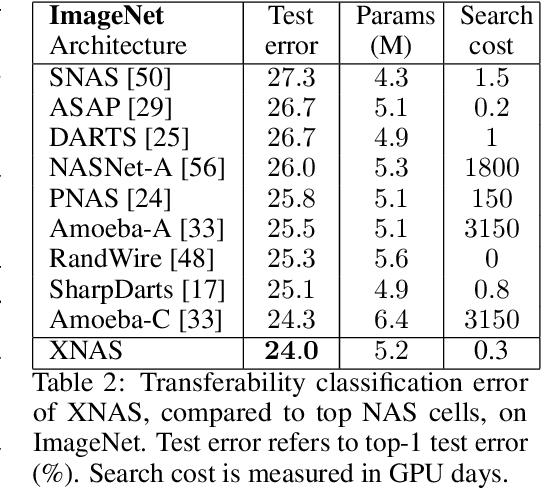
This paper introduces a novel optimization method for differential neural architecture search, based on the theory of prediction with expert advice. Its optimization criterion is well fitted for an architecture-selection, i.e., it minimizes the regret incurred by a sub-optimal selection of operations. Unlike previous search relaxations, that require hard pruning of architectures, our method is designed to dynamically wipe out inferior architectures and enhance superior ones. It achieves an optimal worst-case regret bound and suggests the use of multiple learning-rates, based on the amount of information carried by the backward gradients. Experiments show that our algorithm achieves a strong performance over several image classification datasets. Specifically, it obtains an error rate of 1.6% for CIFAR-10, 24% for ImageNet under mobile settings, and achieves state-of-the-art results on three additional datasets.
Robust Gaussian Process Regression for Real-Time High Precision GPS Signal Enhancement
Jun 03, 2019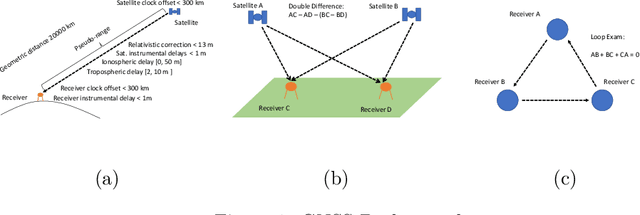
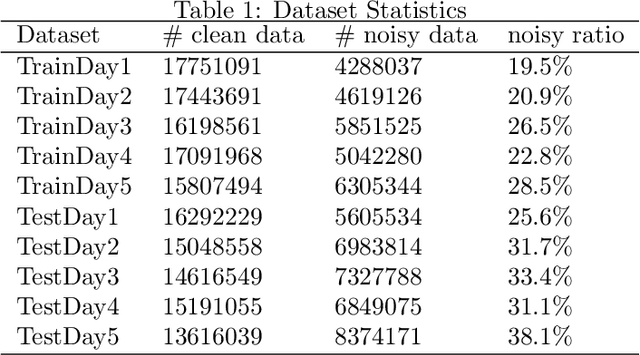
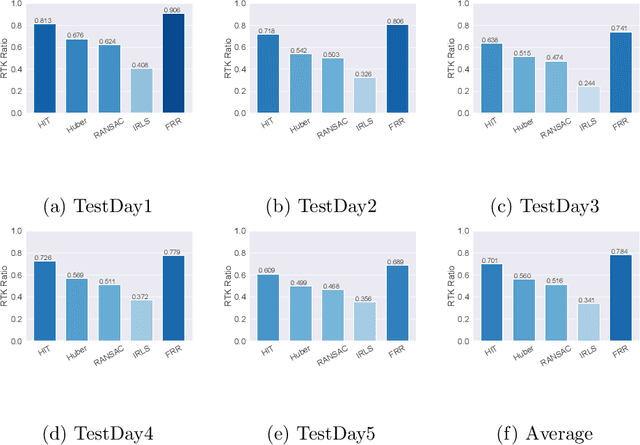
Satellite-based positioning system such as GPS often suffers from large amount of noise that degrades the positioning accuracy dramatically especially in real-time applications. In this work, we consider a data-mining approach to enhance the GPS signal. We build a large-scale high precision GPS receiver grid system to collect real-time GPS signals for training. The Gaussian Process (GP) regression is chosen to model the vertical Total Electron Content (vTEC) distribution of the ionosphere of the Earth. Our experiments show that the noise in the real-time GPS signals often exceeds the breakdown point of the conventional robust regression methods resulting in sub-optimal system performance. We propose a three-step approach to address this challenge. In the first step we perform a set of signal validity tests to separate the signals into clean and dirty groups. In the second step, we train an initial model on the clean signals and then reweigting the dirty signals based on the residual error. A final model is retrained on both the clean signals and the reweighted dirty signals. In the theoretical analysis, we prove that the proposed three-step approach is able to tolerate much higher noise level than the vanilla robust regression methods if two reweighting rules are followed. We validate the superiority of the proposed method in our real-time high precision positioning system against several popular state-of-the-art robust regression methods. Our method achieves centimeter positioning accuracy in the benchmark region with probability $78.4\%$ , outperforming the second best baseline method by a margin of $8.3\%$. The benchmark takes 6 hours on 20,000 CPU cores or 14 years on a single CPU.
On the Computation and Communication Complexity of Parallel SGD with Dynamic Batch Sizes for Stochastic Non-Convex Optimization
May 10, 2019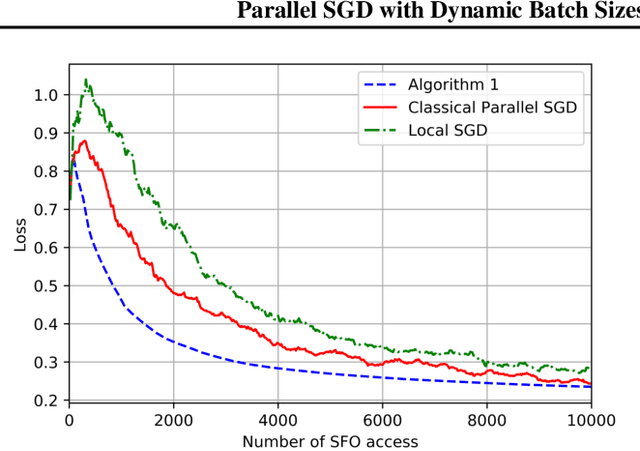
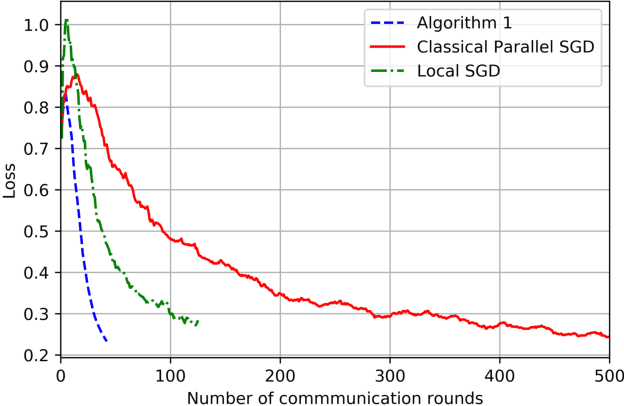
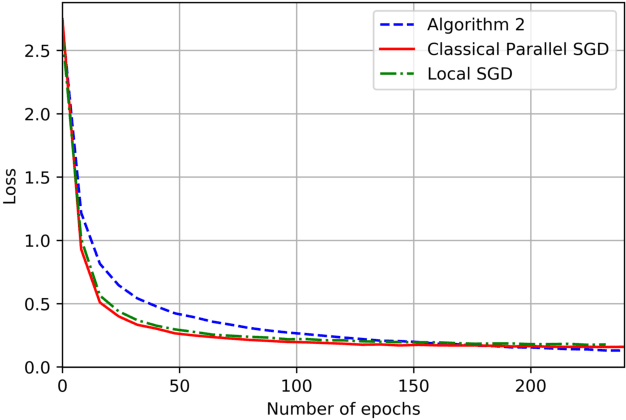
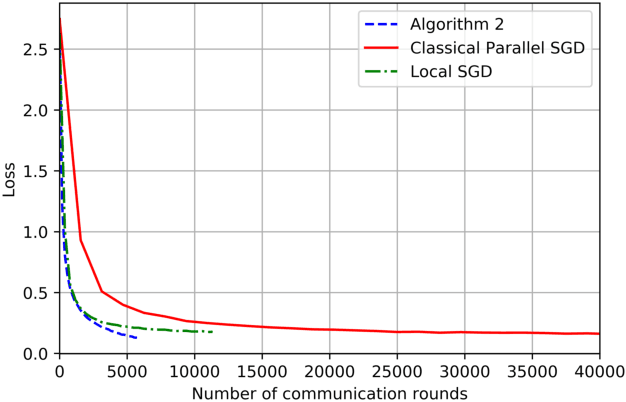
For SGD based distributed stochastic optimization, computation complexity, measured by the convergence rate in terms of the number of stochastic gradient calls, and communication complexity, measured by the number of inter-node communication rounds, are two most important performance metrics. The classical data-parallel implementation of SGD over $N$ workers can achieve linear speedup of its convergence rate but incurs an inter-node communication round at each batch. We study the benefit of using dynamically increasing batch sizes in parallel SGD for stochastic non-convex optimization by charactering the attained convergence rate and the required number of communication rounds. We show that for stochastic non-convex optimization under the P-L condition, the classical data-parallel SGD with exponentially increasing batch sizes can achieve the fastest known $O(1/(NT))$ convergence with linear speedup using only $\log(T)$ communication rounds. For general stochastic non-convex optimization, we propose a Catalyst-like algorithm to achieve the fastest known $O(1/\sqrt{NT})$ convergence with only $O(\sqrt{NT}\log(\frac{T}{N}))$ communication rounds.