 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Does Stagewise Training Accelerate Convergence of Testing Error Over SGD?
Paper and Code
Dec 11, 2018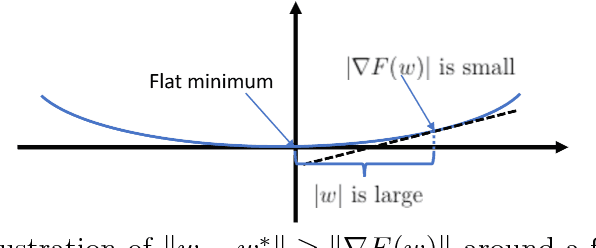
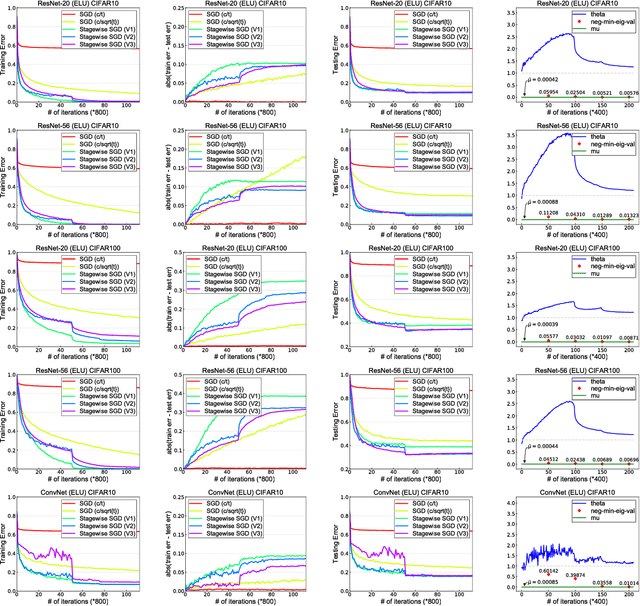
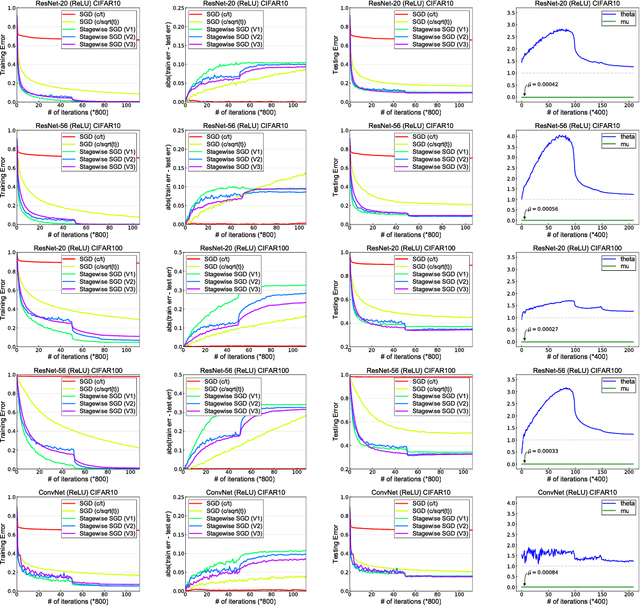
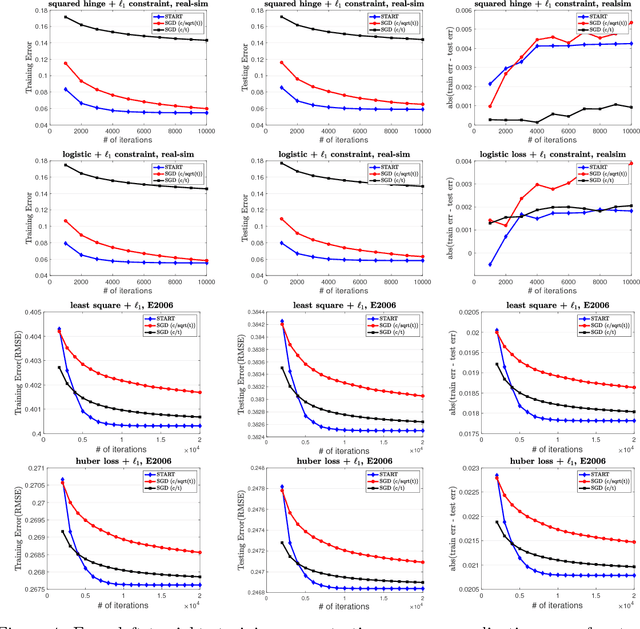
Stagewise training strategy is commonly used for learning neural networks, which uses a stochastic algorithm (e.g., SGD) starting with a relatively large step size (aka learning rate) and geometrically decreasing the step size after a number of iterations. It has been observed that the stagewise SGD has much faster convergence than the vanilla SGD with a polynomial decaying step size in terms of both training error and testing error. {\it But how to explain this phenomenon has been largely ignored by existing studies.} This paper provides some theoretical evidence for explaining this faster convergence. In particular, we consider the stagewise training strategy for minimizing empirical risk that satisfies the Polyak-\L ojasiewicz condition, which has been observed/proved for neural networks and also holds for a broad family of convex functions. For convex loss functions and "nice-behaviored" non-convex loss functions that are close to a convex function (namely weakly convex functions), we establish faster convergence of stagewise training than the vanilla SGD under the same condition on both training error and testing error. Indeed, the proposed algorithm has additional favorable features that come with theoretical guarantee for the considered non-convex optimization problems, including using explicit algorithmic regularization at each stage, using stagewise averaged solution for restarting, and returning the last stagewise averaged solution as the final solution. To differentiate from commonly used stagewise SGD, we refer to our algorithm as stagewise regularized training algorithm. Of independent interest, the proved testing error bounds for a family of non-convex loss functions are dimensionality and norm independent.