 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecentralized Multi-Robot Social Navigation in Constrained Environments via Game-Theoretic Control Barrier Functions
Aug 31, 2023



We present an approach to ensure safe and deadlock-free navigation for decentralized multi-robot systems operating in constrained environments, including doorways and intersections. Although many solutions have been proposed to ensure safety, preventing deadlocks in a decentralized fashion with global consensus remains an open problem. We first formalize the objective as a non-cooperative, non-communicative, partially observable multi-robot navigation problem in constrained spaces with multiple conflicting agents, which we term as \emph{social mini-games}. Our approach to ensuring liveness rests on two novel insights: $(i)$ there exists a mixed-strategy Nash equilibrium that allows decentralized robots to perturb their state onto \textit{liveness sets} i.e. states where robots are deadlock-free and $(ii)$ forward invariance of liveness sets can be achieved identical to how control barrier functions (CBFs) guarantee forward invariance of safety sets. We evaluate our approach in simulation as well on physical robots using F$1/10$ robots, a Clearpath Jackal, as well as a Boston Dynamics Spot in a doorway and corridor intersection scenario. Compared to both fully decentralized and centralized approaches with and without deadlock resolution capabilities, we demonstrate that our approach results in safer, more efficient, and smoother navigation, based on a comprehensive set of metrics including success rate, collision rate, stop time, change in velocity, path deviation, time-to-goal, and flow rate.
Principles and Guidelines for Evaluating Social Robot Navigation Algorithms
Jun 29, 2023



A major challenge to deploying robots widely is navigation in human-populated environments, commonly referred to as social robot navigation. While the field of social navigation has advanced tremendously in recent years, the fair evaluation of algorithms that tackle social navigation remains hard because it involves not just robotic agents moving in static environments but also dynamic human agents and their perceptions of the appropriateness of robot behavior. In contrast, clear, repeatable, and accessible benchmarks have accelerated progress in fields like computer vision, natural language processing and traditional robot navigation by enabling researchers to fairly compare algorithms, revealing limitations of existing solutions and illuminating promising new directions. We believe the same approach can benefit social navigation. In this paper, we pave the road towards common, widely accessible, and repeatable benchmarking criteria to evaluate social robot navigation. Our contributions include (a) a definition of a socially navigating robot as one that respects the principles of safety, comfort, legibility, politeness, social competency, agent understanding, proactivity, and responsiveness to context, (b) guidelines for the use of metrics, development of scenarios, benchmarks, datasets, and simulators to evaluate social navigation, and (c) a design of a social navigation metrics framework to make it easier to compare results from different simulators, robots and datasets.
Decentralized Social Navigation with Non-Cooperative Robots via Bi-Level Optimization
Jun 15, 2023



This paper presents a fully decentralized approach for realtime non-cooperative multi-robot navigation in social mini-games, such as navigating through a narrow doorway or negotiating right of way at a corridor intersection. Our contribution is a new realtime bi-level optimization algorithm, in which the top-level optimization consists of computing a fair and collision-free ordering followed by the bottom-level optimization which plans optimal trajectories conditioned on the ordering. We show that, given such a priority order, we can impose simple kinodynamic constraints on each robot that are sufficient for it to plan collision-free trajectories with minimal deviation from their preferred velocities, similar to how humans navigate in these scenarios. We successfully deploy the proposed algorithm in the real world using F$1/10$ robots, a Clearpath Jackal, and a Boston Dynamics Spot as well as in simulation using the SocialGym 2.0 multi-agent social navigation simulator, in the doorway and corridor intersection scenarios. We compare with state-of-the-art social navigation methods using multi-agent reinforcement learning, collision avoidance algorithms, and crowd simulation models. We show that $(i)$ classical navigation performs $44\%$ better than the state-of-the-art learning-based social navigation algorithms, $(ii)$ without a scheduling protocol, our approach results in collisions in social mini-games $(iii)$ our approach yields $2\times$ and $5\times$ fewer velocity changes than CADRL in doorways and intersections, and finally $(iv)$ bi-level navigation in doorways at a flow rate of $2.8 - 3.3$ (ms)$^{-1}$ is comparable to flow rate in human navigation at a flow rate of $4$ (ms)$^{-1}$.
iPLAN: Intent-Aware Planning in Heterogeneous Traffic via Distributed Multi-Agent Reinforcement Learning
Jun 09, 2023



Navigating safely and efficiently in dense and heterogeneous traffic scenarios is challenging for autonomous vehicles (AVs) due to their inability to infer the behaviors or intentions of nearby drivers. In this work, we propose a distributed multi-agent reinforcement learning (MARL) algorithm with trajectory and intent prediction in dense and heterogeneous traffic scenarios. Our approach for intent-aware planning, iPLAN, allows agents to infer nearby drivers' intents solely from their local observations. We model two distinct incentives for agents' strategies: Behavioral incentives for agents' long-term planning based on their driving behavior or personality; Instant incentives for agents' short-term planning for collision avoidance based on the current traffic state. We design a two-stream inference module that allows agents to infer their opponents' incentives and incorporate their inferred information into decision-making. We perform experiments on two simulation environments, Non-Cooperative Navigation and Heterogeneous Highway. In Heterogeneous Highway, results show that, compared with centralized MARL baselines such as QMIX and MAPPO, our method yields a 4.0% and 35.7% higher episodic reward in mild and chaotic traffic, with 48.1% higher success rate and 80.6% longer survival time in chaotic traffic. We also compare with a decentralized baseline IPPO and demonstrate a higher episodic reward of 9.2% and 10.3% in mild traffic and chaotic traffic, 25.3% higher success rate, and 13.7% longer survival time.
SOCIALGYM 2.0: Simulator for Multi-Agent Social Robot Navigation in Shared Human Spaces
Mar 09, 2023



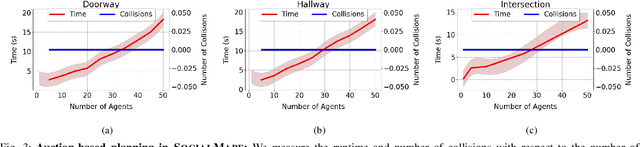
We present SocialGym 2, a multi-agent navigation simulator for social robot research. Our simulator models multiple autonomous agents, replicating real-world dynamics in complex environments, including doorways, hallways, intersections, and roundabouts. Unlike traditional simulators that concentrate on single robots with basic kinematic constraints in open spaces, SocialGym 2 employs multi-agent reinforcement learning (MARL) to develop optimal navigation policies for multiple robots with diverse, dynamic constraints in complex environments. Built on the PettingZoo MARL library and Stable Baselines3 API, SocialGym 2 offers an accessible python interface that integrates with a navigation stack through ROS messaging. SocialGym 2 can be easily installed and is packaged in a docker container, and it provides the capability to swap and evaluate different MARL algorithms, as well as customize observation and reward functions. We also provide scripts to allow users to create their own environments and have conducted benchmarks using various social navigation algorithms, reporting a broad range of social navigation metrics. Projected hosted at: https://amrl.cs.utexas.edu/social_gym/index.html
SOCIALMAPF: Optimal and Efficient Multi-Agent Path Finding with Strategic Agents for Social Navigation
Oct 15, 2022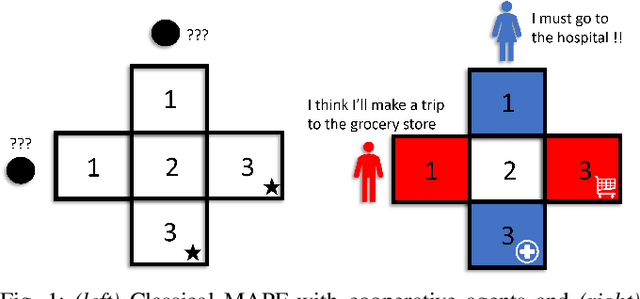


We propose an extension to the MAPF formulation, called SocialMAPF, to account for private incentives of agents in constrained environments such as doorways, narrow hallways, and corridor intersections. SocialMAPF is able to, for instance, accurately reason about the urgent incentive of an agent rushing to the hospital over another agent's less urgent incentive of going to a grocery store; MAPF ignores such agent-specific incentives. Our proposed formulation addresses the open problem of optimal and efficient path planning for agents with private incentives. To solve SocialMAPF, we propose a new class of algorithms that use mechanism design during conflict resolution to simultaneously optimize agents' private local utilities and the global system objective. We perform an extensive array of experiments that show that optimal search-based MAPF techniques lead to collisions and increased time-to-goal in SocialMAPF compared to our proposed method using mechanism design. Furthermore, we empirically demonstrate that mechanism design results in models that maximizes agent utility and minimizes the overall time-to-goal of the entire system. We further showcase the capabilities of mechanism design-based planning by successfully deploying it in environments with static obstacles. To conclude, we briefly list several research directions using the SocialMAPF formulation, such as exploring motion planning in the continuous domain for agents with private incentives.
Game-Theoretic Planning for Autonomous Driving among Risk-Aware Human Drivers
May 01, 2022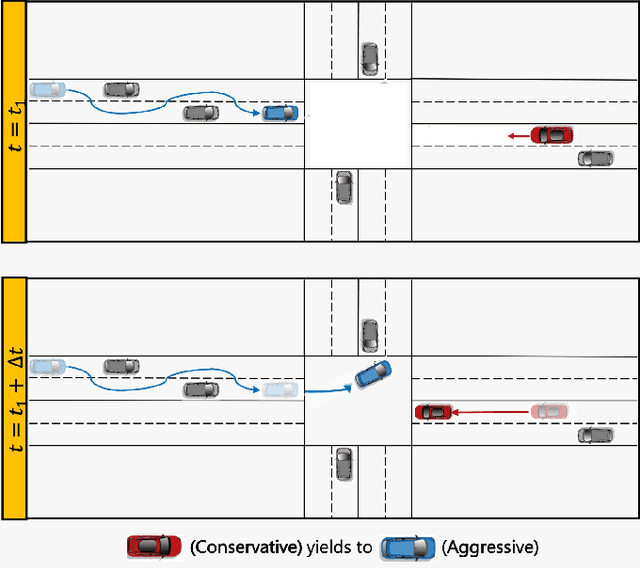
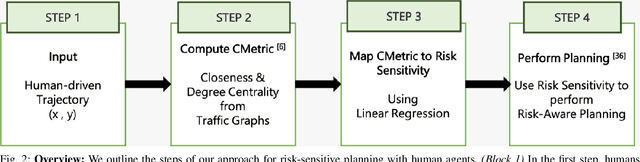
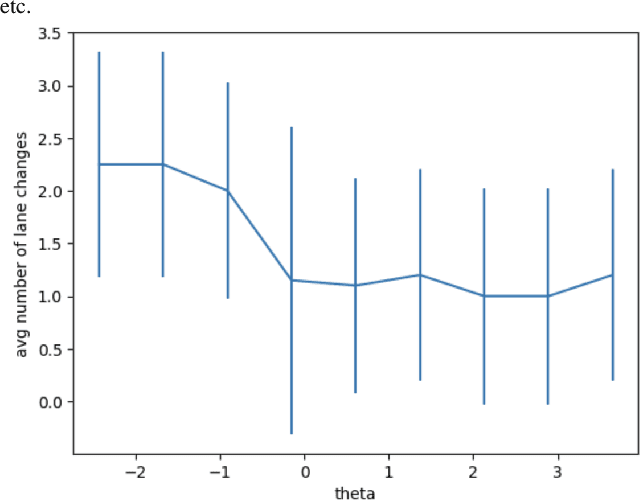
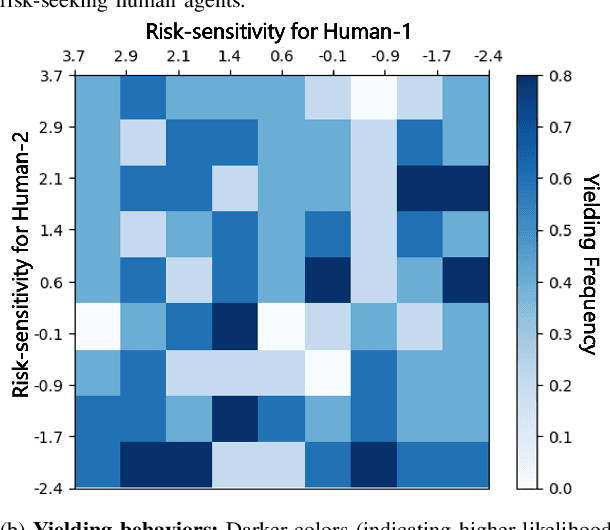
We present a novel approach for risk-aware planning with human agents in multi-agent traffic scenarios. Our approach takes into account the wide range of human driver behaviors on the road, from aggressive maneuvers like speeding and overtaking, to conservative traits like driving slowly and conforming to the right-most lane. In our approach, we learn a mapping from a data-driven human driver behavior model called the CMetric to a driver's entropic risk preference. We then use the derived risk preference within a game-theoretic risk-sensitive planner to model risk-aware interactions among human drivers and an autonomous vehicle in various traffic scenarios. We demonstrate our method in a merging scenario, where our results show that the final trajectories obtained from the risk-aware planner generate desirable emergent behaviors. Particularly, our planner recognizes aggressive human drivers and yields to them while maintaining a greater distance from them. In a user study, participants were able to distinguish between aggressive and conservative simulated drivers based on trajectories generated from our risk-sensitive planner. We also observe that aggressive human driving results in more frequent lane-changing in the planner. Finally, we compare the performance of our modified risk-aware planner with existing methods and show that modeling human driver behavior leads to safer navigation.
GAMEOPT: Optimal Real-time Multi-Agent Planning and Control for Dynamic Intersections
Mar 18, 2022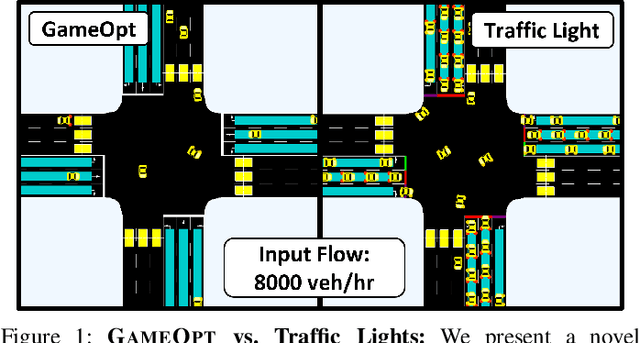
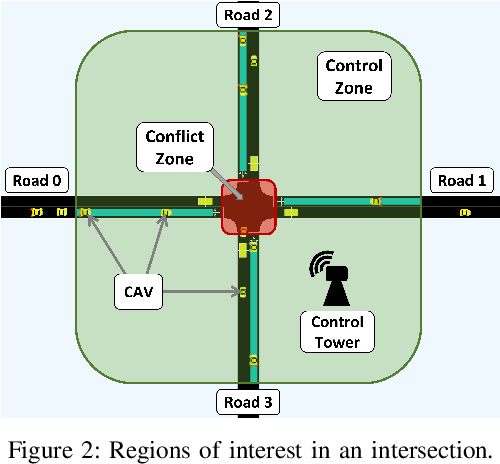
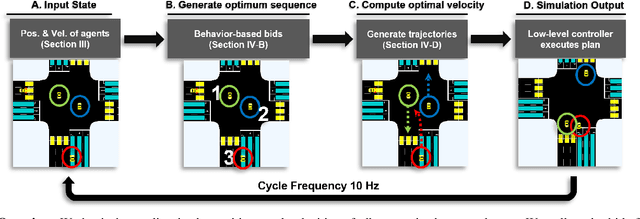
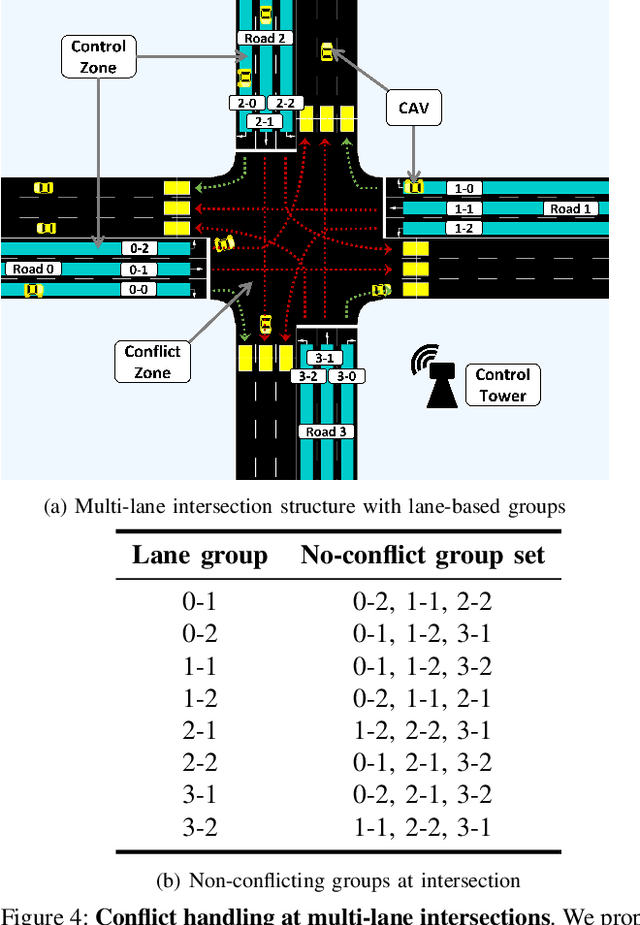
We propose GameOpt: a novel hybrid approach to cooperative intersection control for dynamic, multi-lane, unsignalized intersections. Safely navigating these complex and accident prone intersections requires simultaneous trajectory planning and negotiation among drivers. GameOpt is a hybrid formulation that first uses an auction mechanism to generate a priority entrance sequence for every agent, followed by an optimization-based trajectory planner that computes velocity controls that satisfy the priority sequence. This coupling operates at real-time speeds of less than 10 milliseconds in high density traffic of more than 10,000 vehicles/hr, 100 times faster than other fully optimization-based methods, while providing guarantees in terms of fairness, safety, and efficiency. Tested on the SUMO simulator, our algorithm improves throughput by at least 25%, time taken to reach the goal by 75%, and fuel consumption by 33% compared to auction-based approaches and signaled approaches using traffic-lights and stop signs.
Using Graph-Theoretic Machine Learning to Predict Human Driver Behavior
Nov 04, 2021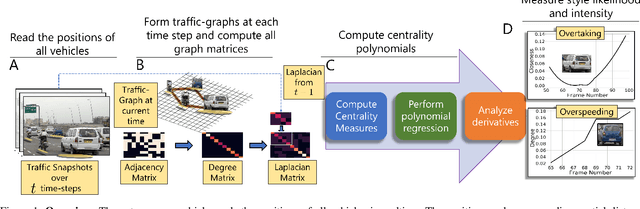
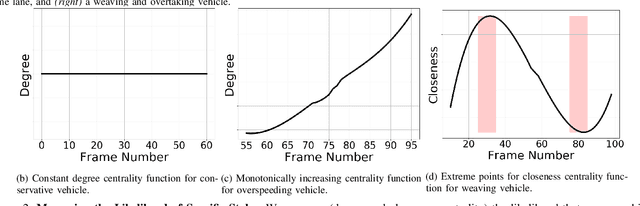

Studies have shown that autonomous vehicles (AVs) behave conservatively in a traffic environment composed of human drivers and do not adapt to local conditions and socio-cultural norms. It is known that socially aware AVs can be designed if there exists a mechanism to understand the behaviors of human drivers. We present an approach that leverages machine learning to predict, the behaviors of human drivers. This is similar to how humans implicitly interpret the behaviors of drivers on the road, by only observing the trajectories of their vehicles. We use graph-theoretic tools to extract driver behavior features from the trajectories and machine learning to obtain a computational mapping between the extracted trajectory of a vehicle in traffic and the driver behaviors. Compared to prior approaches in this domain, we prove that our method is robust, general, and extendable to broad-ranging applications such as autonomous navigation. We evaluate our approach on real-world traffic datasets captured in the U.S., India, China, and Singapore, as well as in simulation.
METEOR: A Massive Dense & Heterogeneous Behavior Dataset for Autonomous Driving
Sep 30, 2021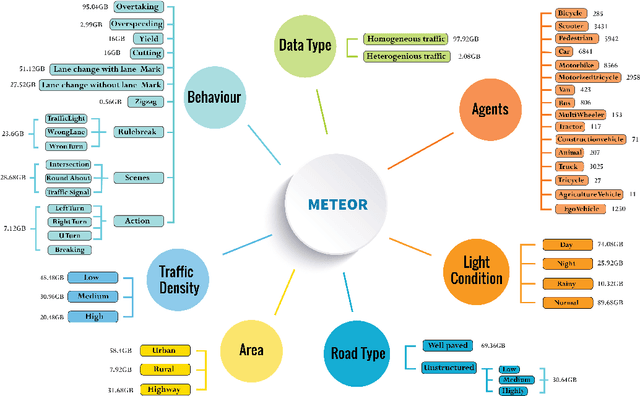

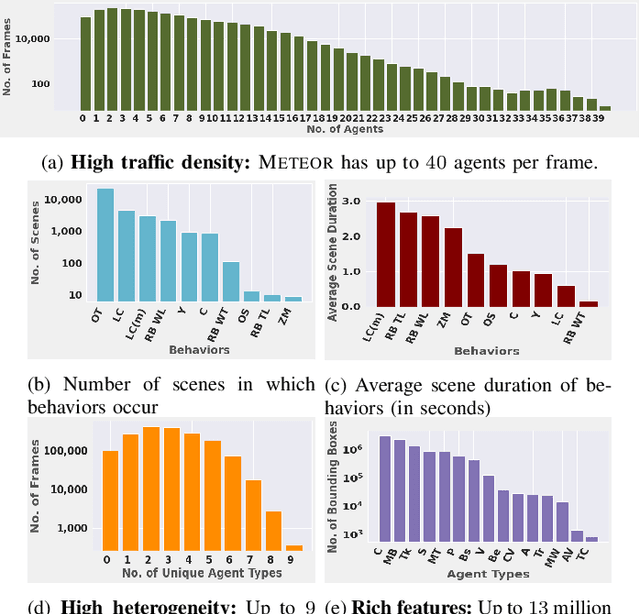
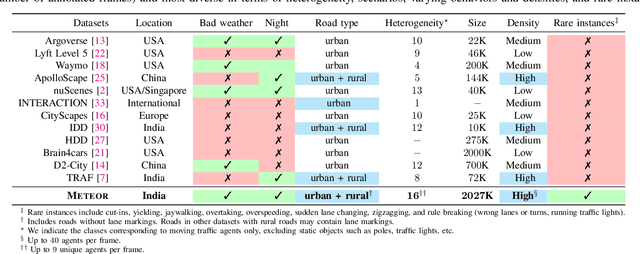
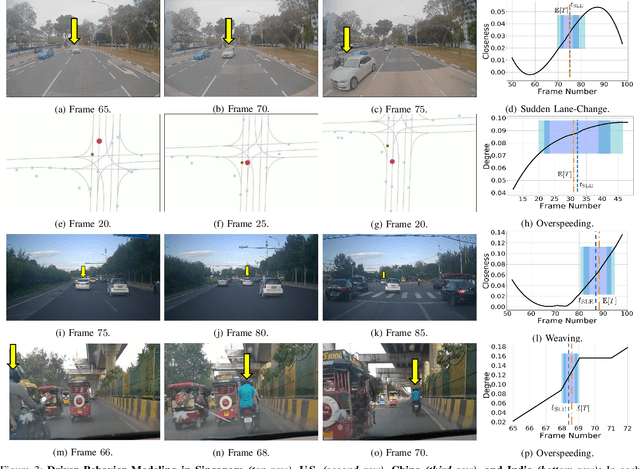
We present a new and complex traffic dataset, METEOR, which captures traffic patterns in unstructured scenarios in India. METEOR consists of more than 1000 one-minute video clips, over 2 million annotated frames with ego-vehicle trajectories, and more than 13 million bounding boxes for surrounding vehicles or traffic agents. METEOR is a unique dataset in terms of capturing the heterogeneity of microscopic and macroscopic traffic characteristics. Furthermore, we provide annotations for rare and interesting driving behaviors such as cut-ins, yielding, overtaking, overspeeding, zigzagging, sudden lane changing, running traffic signals, driving in the wrong lanes, taking wrong turns, lack of right-of-way rules at intersections, etc. We also present diverse traffic scenarios corresponding to rainy weather, nighttime driving, driving in rural areas with unmarked roads, and high-density traffic scenarios. We use our novel dataset to evaluate the performance of object detection and behavior prediction algorithms. We show that state-of-the-art object detectors fail in these challenging conditions and also propose a new benchmark test: action-behavior prediction with a baseline mAP score of 70.74.