 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Pre-training and Self-training
Jun 11, 2020
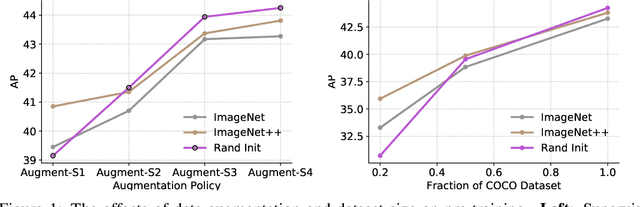

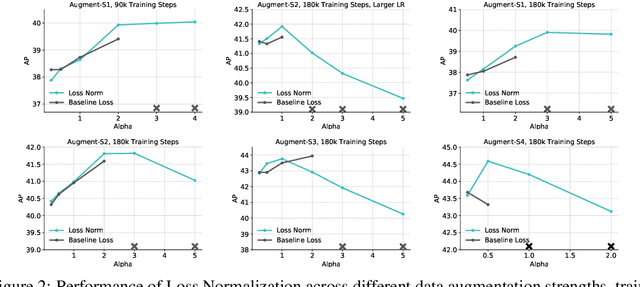
Pre-training is a dominant paradigm in computer vision. For example, supervised ImageNet pre-training is commonly used to initialize the backbones of object detection and segmentation models. He et al., however, show a surprising result that ImageNet pre-training has limited impact on COCO object detection. Here we investigate self-training as another method to utilize additional data on the same setup and contrast it against ImageNet pre-training. Our study reveals the generality and flexibility of self-training with three additional insights: 1) stronger data augmentation and more labeled data further diminish the value of pre-training, 2) unlike pre-training, self-training is always helpful when using stronger data augmentation, in both low-data and high-data regimes, and 3) in the case that pre-training is helpful, self-training improves upon pre-training. For example, on the COCO object detection dataset, pre-training benefits when we use one fifth of the labeled data, and hurts accuracy when we use all labeled data. Self-training, on the other hand, shows positive improvements from +1.3 to +3.4AP across all dataset sizes. In other words, self-training works well exactly on the same setup that pre-training does not work (using ImageNet to help COCO). On the PASCAL segmentation dataset, which is a much smaller dataset than COCO, though pre-training does help significantly, self-training improves upon the pre-trained model. On COCO object detection, we achieve 54.3AP, an improvement of +1.5AP over the strongest SpineNet model. On PASCAL segmentation, we achieve 90.5 mIOU, an improvement of +1.5% mIOU over the previous state-of-the-art result by DeepLabv3+.
AutoHAS: Differentiable Hyper-parameter and Architecture Search
Jun 05, 2020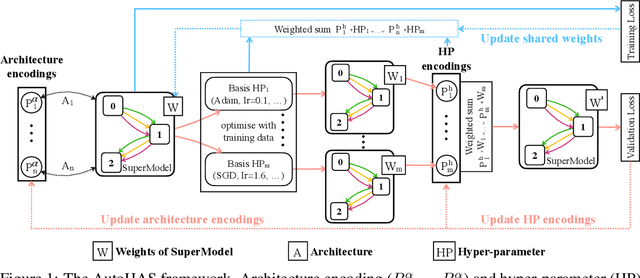
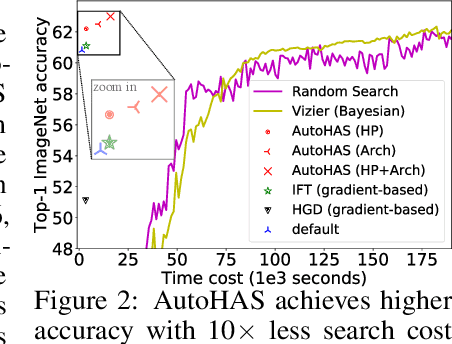
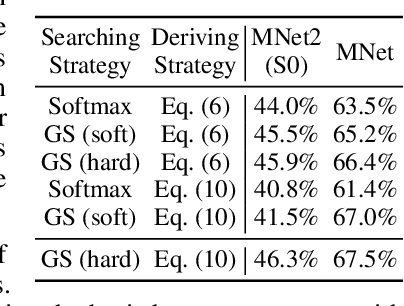
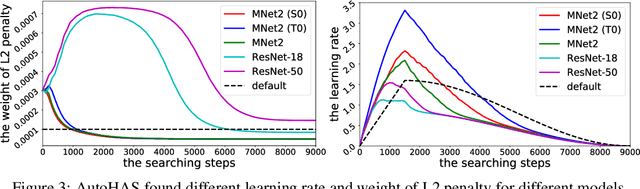
Neural Architecture Search (NAS) has achieved significant progress in pushing state-of-the-art performance. While previous NAS methods search for different network architectures with the same hyper-parameters, we argue that such search would lead to sub-optimal results. We empirically observe that different architectures tend to favor their own hyper-parameters. In this work, we extend NAS to a broader and more practical space by combining hyper-parameter and architecture search. As architecture choices are often categorical whereas hyper-parameter choices are often continuous, a critical challenge here is how to handle these two types of values in a joint search space. To tackle this challenge, we propose AutoHAS, a differentiable hyper-parameter and architecture search approach, with the idea of discretizing the continuous space into a linear combination of multiple categorical basis. A key element of AutoHAS is the use of weight sharing across all architectures and hyper-parameters which enables efficient search over the large joint search space. Experimental results on MobileNet/ResNet/EfficientNet/BERT show that AutoHAS significantly improves accuracy up to 2% on ImageNet and F1 score up to 0.4 on SQuAD 1.1, with search cost comparable to training a single model. Compared to other AutoML methods, such as random search or Bayesian methods, AutoHAS can achieve better accuracy with 10x less compute cost.
Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing
Jun 05, 2020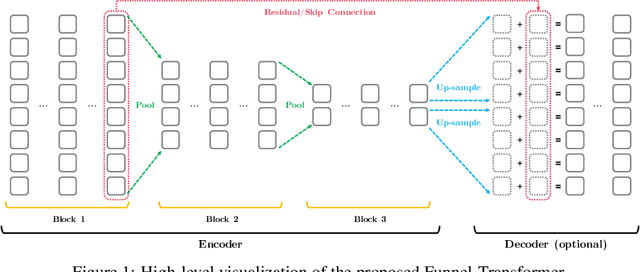
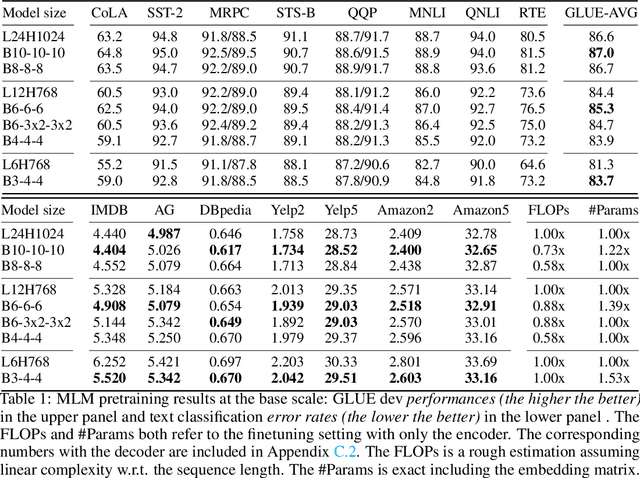
With the success of language pretraining, it is highly desirable to develop more efficient architectures of good scalability that can exploit the abundant unlabeled data at a lower cost. To improve the efficiency, we examine the much-overlooked redundancy in maintaining a full-length token-level presentation, especially for tasks that only require a single-vector presentation of the sequence. With this intuition, we propose Funnel-Transformer which gradually compresses the sequence of hidden states to a shorter one and hence reduces the computation cost. More importantly, by re-investing the saved FLOPs from length reduction in constructing a deeper or wider model, we further improve the model capacity. In addition, to perform token-level predictions as required by common pretraining objectives, Funnel-Transformer is able to recover a deep representation for each token from the reduced hidden sequence via a decoder. Empirically, with comparable or fewer FLOPs, Funnel-Transformer outperforms the standard Transformer on a wide variety of sequence-level prediction tasks, including text classification, language understanding, and reading comprehension. The code and pretrained checkpoints are available at https://github.com/laiguokun/Funnel-Transformer.
Improved Noisy Student Training for Automatic Speech Recognition
May 19, 2020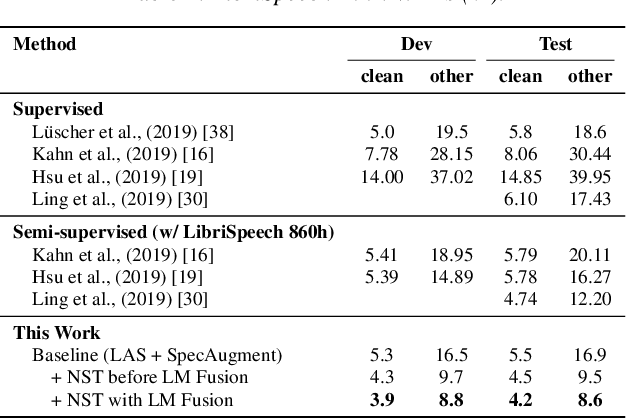
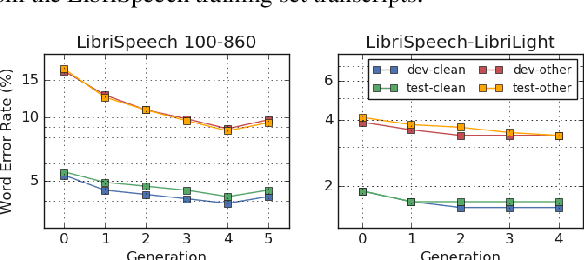
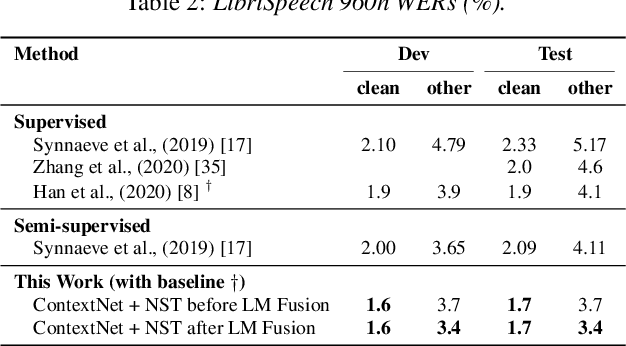
Recently, a semi-supervised learning method known as "noisy student training" has been shown to improve image classification performance of deep networks significantly. Noisy student training is an iterative self-training method that leverages augmentation to improve network performance. In this work, we adapt and improve noisy student training for automatic speech recognition, employing (adaptive) SpecAugment as the augmentation method. We find effective methods to filter, balance and augment the data generated in between self-training iterations. By doing so, we are able to obtain word error rates (WERs) 4.2%/8.6% on the clean/noisy LibriSpeech test sets by only using the clean 100h subset of LibriSpeech as the supervised set and the rest (860h) as the unlabeled set. Furthermore, we are able to achieve WERs 1.7%/3.4% on the clean/noisy LibriSpeech test sets by using the unlab-60k subset of LibriLight as the unlabeled set for LibriSpeech 960h. We are thus able to improve upon the previous state-of-the-art clean/noisy test WERs achieved on LibriSpeech 100h (4.74%/12.20%) and LibriSpeech (1.9%/4.1%).
Evolving Normalization-Activation Layers
Apr 28, 2020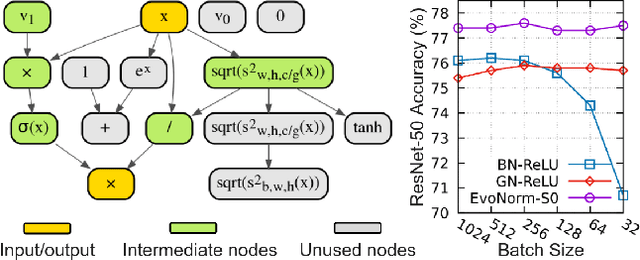

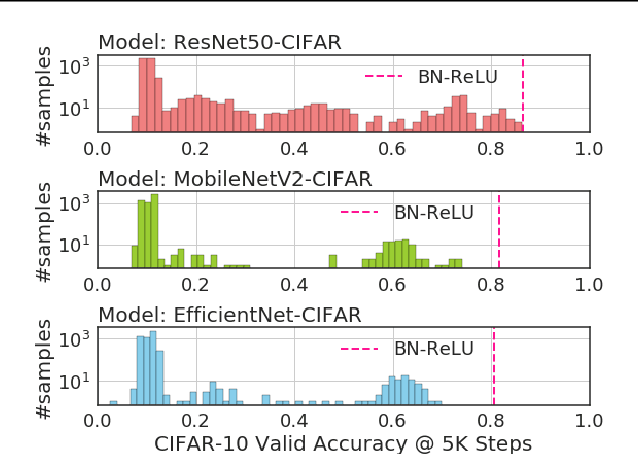
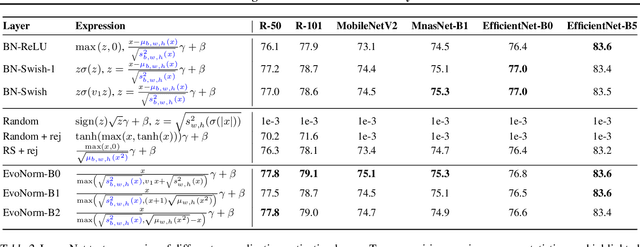
Normalization layers and activation functions are critical components in deep neural networks that frequently co-locate with each other. Instead of designing them separately, we unify them into a single computation graph, and evolve its structure starting from low-level primitives. Our layer search algorithm leads to the discovery of EvoNorms, a set of new normalization-activation layers that go beyond existing design patterns. Several of these layers enjoy the property of being independent from the batch statistics. Our experiments show that EvoNorms not only work well on a variety of image classification models including ResNets, MobileNets and EfficientNets but also transfer well to Mask R-CNN, SpineNet for instance segmentation and BigGAN for image synthesis, significantly outperforming BatchNorm and GroupNorm based layers in many cases.
Meta Pseudo Labels
Apr 23, 2020
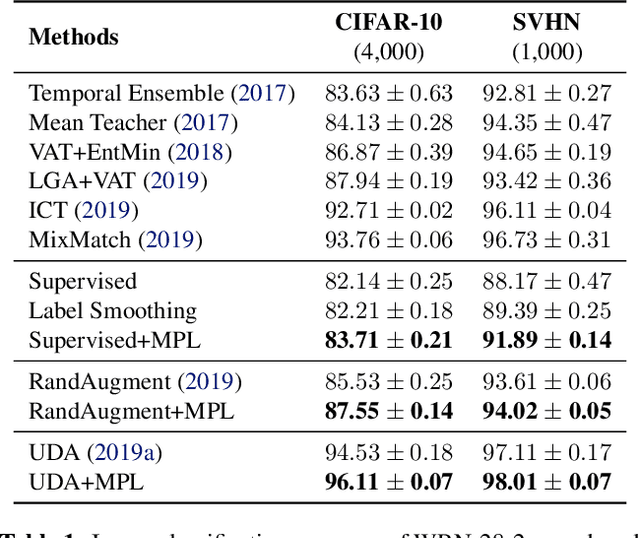

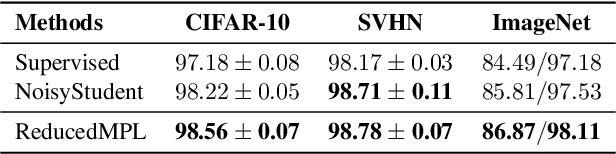
Many training algorithms of a deep neural network can be interpreted as minimizing the cross entropy loss between the prediction made by the network and a target distribution. In supervised learning, this target distribution is typically the ground-truth one-hot vector. In semi-supervised learning, this target distribution is typically generated by a pre-trained teacher model to train the main network. In this work, instead of using such predefined target distributions, we show that learning to adjust the target distribution based on the learning state of the main network can lead to better performances. In particular, we propose an efficient meta-learning algorithm, which encourages the teacher to adjust the target distributions of training examples in the manner that improves the learning of the main network. The teacher is updated by policy gradients computed by evaluating the main network on a held-out validation set. Our experiments demonstrate substantial improvements over strong baselines and establish state-ofthe-art performance on CIFAR-10, SVHN, and ImageNet. For instance, with ResNets on small datasets, we achieve 96.1% on CIFAR-10 with 4,000 labeled examples and 73.9% top-1 on ImageNet with 10% examples. Meanwhile, with EfficientNet on full datasets plus extra unlabeled data, we attain 98.6% accuracy on CIFAR-10 and 86.9% top-1 accuracy on ImageNet.
Chip Placement with Deep Reinforcement Learning
Apr 22, 2020

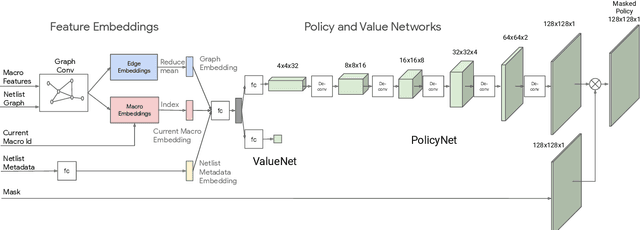
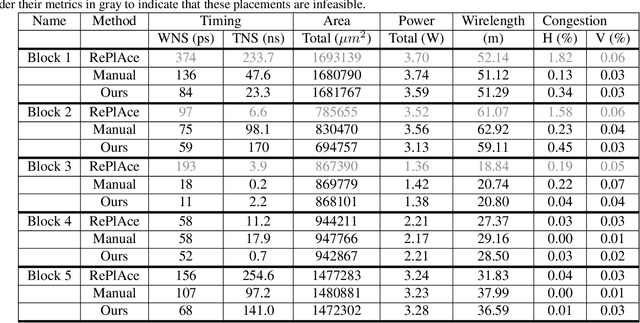
In this work, we present a learning-based approach to chip placement, one of the most complex and time-consuming stages of the chip design process. Unlike prior methods, our approach has the ability to learn from past experience and improve over time. In particular, as we train over a greater number of chip blocks, our method becomes better at rapidly generating optimized placements for previously unseen chip blocks. To achieve these results, we pose placement as a Reinforcement Learning (RL) problem and train an agent to place the nodes of a chip netlist onto a chip canvas. To enable our RL policy to generalize to unseen blocks, we ground representation learning in the supervised task of predicting placement quality. By designing a neural architecture that can accurately predict reward across a wide variety of netlists and their placements, we are able to generate rich feature embeddings of the input netlists. We then use this architecture as the encoder of our policy and value networks to enable transfer learning. Our objective is to minimize PPA (power, performance, and area), and we show that, in under 6 hours, our method can generate placements that are superhuman or comparable on modern accelerator netlists, whereas existing baselines require human experts in the loop and take several weeks.
Improving 3D Object Detection through Progressive Population Based Augmentation
Apr 02, 2020
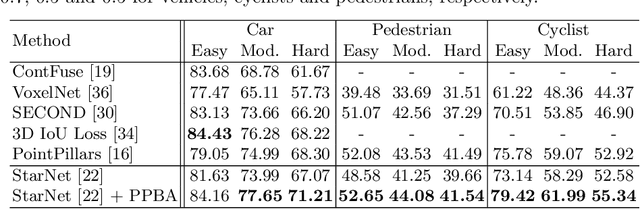

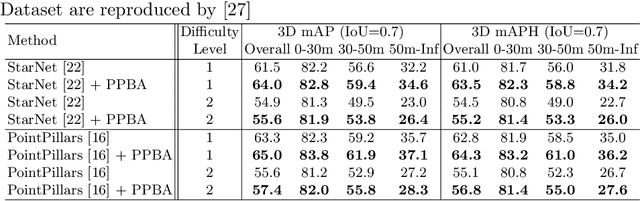
Data augmentation has been widely adopted for object detection in 3D point clouds. All previous efforts have focused on manually designing specific data augmentation methods for individual architectures, however no work has attempted to automate the design of data augmentation in 3D detection problems -- as is common in 2D image-based computer vision. In this work, we present the first attempt to automate the design of data augmentation policies for 3D object detection. We present an algorithm, termed Progressive Population Based Augmentation (PPBA). PPBA learns to optimize augmentation strategies by narrowing down the search space and adopting the best parameters discovered in previous iterations. On the KITTI test set, PPBA improves the StarNet detector by substantial margins on the moderate difficulty category of cars, pedestrians, and cyclists, outperforming all current state-of-the-art single-stage detection models. Additional experiments on the Waymo Open Dataset indicate that PPBA continues to effectively improve 3D object detection on a 20x larger dataset compared to KITTI. The magnitude of the improvements may be comparable to advances in 3D perception architectures and the gains come without an incurred cost at inference time. In subsequent experiments, we find that PPBA may be up to 10x more data efficient than baseline 3D detection models without augmentation, highlighting that 3D detection models may achieve competitive accuracy with far fewer labeled examples.
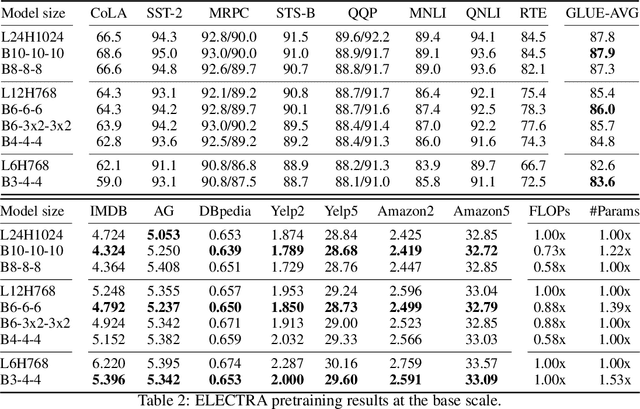
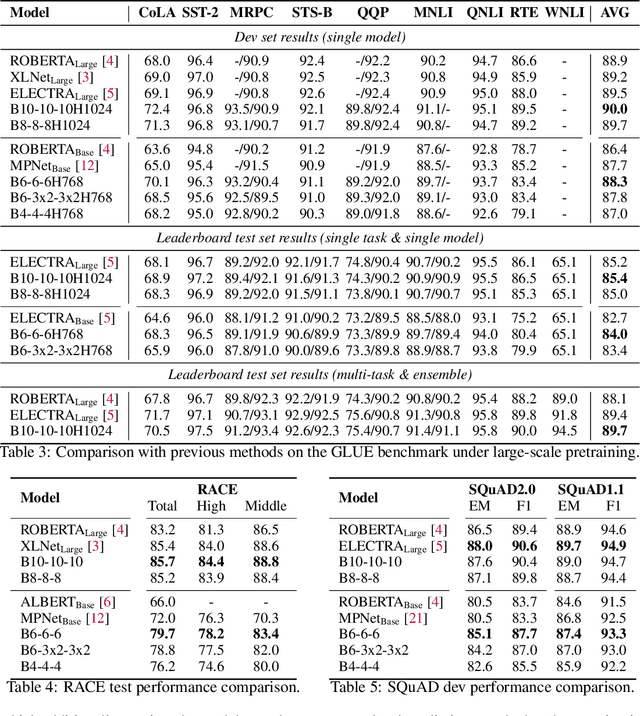
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
Mar 23, 2020Masked language modeling (MLM) pre-training methods such as BERT corrupt the input by replacing some tokens with [MASK] and then train a model to reconstruct the original tokens. While they produce good results when transferred to downstream NLP tasks, they generally require large amounts of compute to be effective. As an alternative, we propose a more sample-efficient pre-training task called replaced token detection. Instead of masking the input, our approach corrupts it by replacing some tokens with plausible alternatives sampled from a small generator network. Then, instead of training a model that predicts the original identities of the corrupted tokens, we train a discriminative model that predicts whether each token in the corrupted input was replaced by a generator sample or not. Thorough experiments demonstrate this new pre-training task is more efficient than MLM because the task is defined over all input tokens rather than just the small subset that was masked out. As a result, the contextual representations learned by our approach substantially outperform the ones learned by BERT given the same model size, data, and compute. The gains are particularly strong for small models; for example, we train a model on one GPU for 4 days that outperforms GPT (trained using 30x more compute) on the GLUE natural language understanding benchmark. Our approach also works well at scale, where it performs comparably to RoBERTa and XLNet while using less than 1/4 of their compute and outperforms them when using the same amount of compute.
AutoML-Zero: Evolving Machine Learning Algorithms From Scratch
Mar 06, 2020
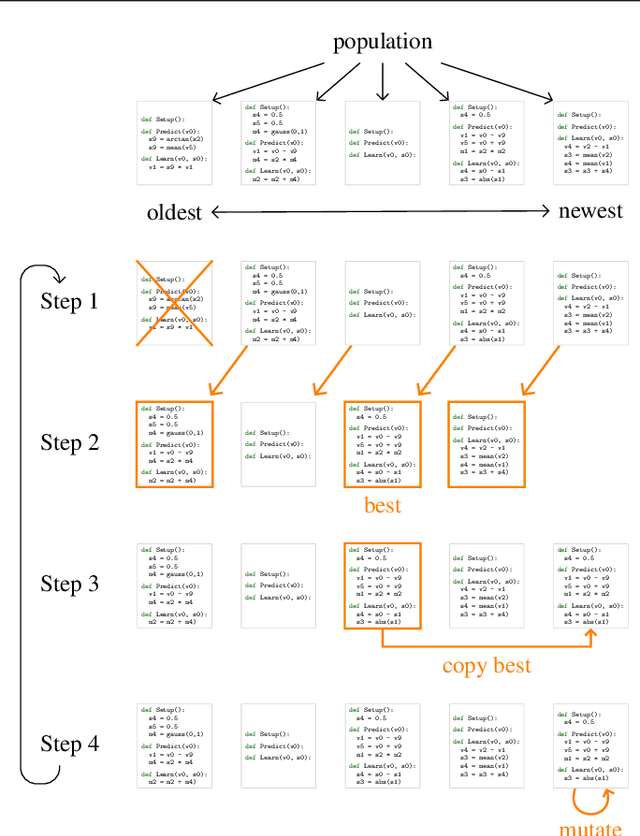

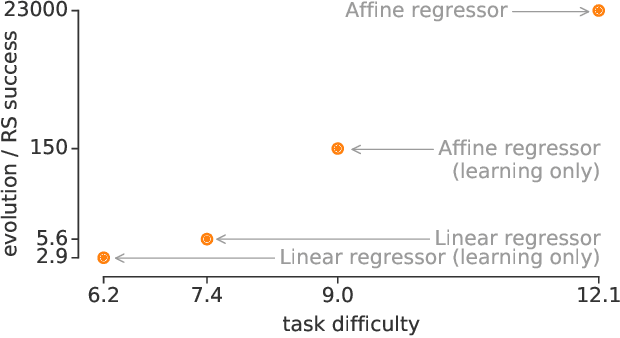
Machine learning research has advanced in multiple aspects, including model structures and learning methods. The effort to automate such research, known as AutoML, has also made significant progress. However, this progress has largely focused on the architecture of neural networks, where it has relied on sophisticated expert-designed layers as building blocks---or similarly restrictive search spaces. Our goal is to show that AutoML can go further: it is possible today to automatically discover complete machine learning algorithms just using basic mathematical operations as building blocks. We demonstrate this by introducing a novel framework that significantly reduces human bias through a generic search space. Despite the vastness of this space, evolutionary search can still discover two-layer neural networks trained by backpropagation. These simple neural networks can then be surpassed by evolving directly on tasks of interest, e.g. CIFAR-10 variants, where modern techniques emerge in the top algorithms, such as bilinear interactions, normalized gradients, and weight averaging. Moreover, evolution adapts algorithms to different task types: e.g., dropout-like techniques appear when little data is available. We believe these preliminary successes in discovering machine learning algorithms from scratch indicate a promising new direction for the field.