 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Flan Collection: Designing Data and Methods for Effective Instruction Tuning
Feb 14, 2023



We study the design decisions of publicly available instruction tuning methods, and break down the development of Flan 2022 (Chung et al., 2022). Through careful ablation studies on the Flan Collection of tasks and methods, we tease apart the effect of design decisions which enable Flan-T5 to outperform prior work by 3-17%+ across evaluation settings. We find task balancing and enrichment techniques are overlooked but critical to effective instruction tuning, and in particular, training with mixed prompt settings (zero-shot, few-shot, and chain-of-thought) actually yields stronger (2%+) performance in all settings. In further experiments, we show Flan-T5 requires less finetuning to converge higher and faster than T5 on single downstream tasks, motivating instruction-tuned models as more computationally-efficient starting checkpoints for new tasks. Finally, to accelerate research on instruction tuning, we make the Flan 2022 collection of datasets, templates, and methods publicly available at https://github.com/google-research/FLAN/tree/main/flan/v2.
Unified Functional Hashing in Automatic Machine Learning
Feb 10, 2023



The field of Automatic Machine Learning (AutoML) has recently attained impressive results, including the discovery of state-of-the-art machine learning solutions, such as neural image classifiers. This is often done by applying an evolutionary search method, which samples multiple candidate solutions from a large space and evaluates the quality of each candidate through a long training process. As a result, the search tends to be slow. In this paper, we show that large efficiency gains can be obtained by employing a fast unified functional hash, especially through the functional equivalence caching technique, which we also present. The central idea is to detect by hashing when the search method produces equivalent candidates, which occurs very frequently, and this way avoid their costly re-evaluation. Our hash is "functional" in that it identifies equivalent candidates even if they were represented or coded differently, and it is "unified" in that the same algorithm can hash arbitrary representations; e.g. compute graphs, imperative code, or lambda functions. As evidence, we show dramatic improvements on multiple AutoML domains, including neural architecture search and algorithm discovery. Finally, we consider the effect of hash collisions, evaluation noise, and search distribution through empirical analysis. Altogether, we hope this paper may serve as a guide to hashing techniques in AutoML.
Noise2Music: Text-conditioned Music Generation with Diffusion Models
Feb 08, 2023



We introduce Noise2Music, where a series of diffusion models is trained to generate high-quality 30-second music clips from text prompts. Two types of diffusion models, a generator model, which generates an intermediate representation conditioned on text, and a cascader model, which generates high-fidelity audio conditioned on the intermediate representation and possibly the text, are trained and utilized in succession to generate high-fidelity music. We explore two options for the intermediate representation, one using a spectrogram and the other using audio with lower fidelity. We find that the generated audio is not only able to faithfully reflect key elements of the text prompt such as genre, tempo, instruments, mood, and era, but goes beyond to ground fine-grained semantics of the prompt. Pretrained large language models play a key role in this story -- they are used to generate paired text for the audio of the training set and to extract embeddings of the text prompts ingested by the diffusion models. Generated examples: https://google-research.github.io/noise2music
PyGlove: Efficiently Exchanging ML Ideas as Code
Feb 03, 2023



The increasing complexity and scale of machine learning (ML) has led to the need for more efficient collaboration among multiple teams. For example, when a research team invents a new architecture like "ResNet," it is desirable for multiple engineering teams to adopt it. However, the effort required for each team to study and understand the invention does not scale well with the number of teams or inventions. In this paper, we present an extension of our PyGlove library to easily and scalably share ML ideas. PyGlove represents ideas as symbolic rule-based patches, enabling researchers to write down the rules for models they have not seen. For example, an inventor can write rules that will "add skip-connections." This permits a network effect among teams: at once, any team can issue patches to all other teams. Such a network effect allows users to quickly surmount the cost of adopting PyGlove by writing less code quicker, providing a benefit that scales with time. We describe the new paradigm of organizing ML through symbolic patches and compare it to existing approaches. We also perform a case study of a large codebase where PyGlove led to an 80% reduction in the number of lines of code.
Inverse scaling can become U-shaped
Nov 14, 2022Although scaling language models improves performance on a range of tasks, there are apparently some scenarios where scaling hurts performance. For instance, the Inverse Scaling Prize Round 1 (McKensie et al., 2022) identified four "inverse scaling" tasks, for which performance gets worse for larger models. These tasks were evaluated on models of up to 280B parameters, trained up to 500 zettaFLOPs of compute. This paper takes a closer look at these four tasks. We evaluate models of up to 540B parameters, trained on five times more compute than those evaluated in the Inverse Scaling Prize. With this increased range of model sizes and training compute, two out of the four tasks exhibit what we call "U-shaped scaling" -- performance decreases up to a certain model size, and then increases again up to the largest model evaluated. One hypothesis is that U-shaped scaling occurs when a task comprises a "true task" and a "distractor task". Medium-size models can do the distractor task, which hurts performance, while only large-enough models can ignore the distractor task and do the true task. The existence of U-shaped scaling implies that inverse scaling may not hold for larger models. Second, we evaluate the inverse scaling tasks using chain-of-thought (CoT) prompting, in addition to basic prompting without CoT. With CoT prompting, all four tasks show either U-shaped scaling or positive scaling, achieving perfect solve rates on two tasks and several sub-tasks. This suggests that the term "inverse scaling task" is under-specified -- a given task may be inverse scaling for one prompt but positive or U-shaped scaling for a different prompt.
Scaling Instruction-Finetuned Language Models
Oct 20, 2022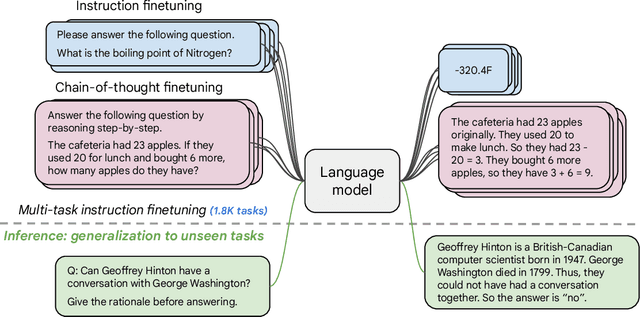

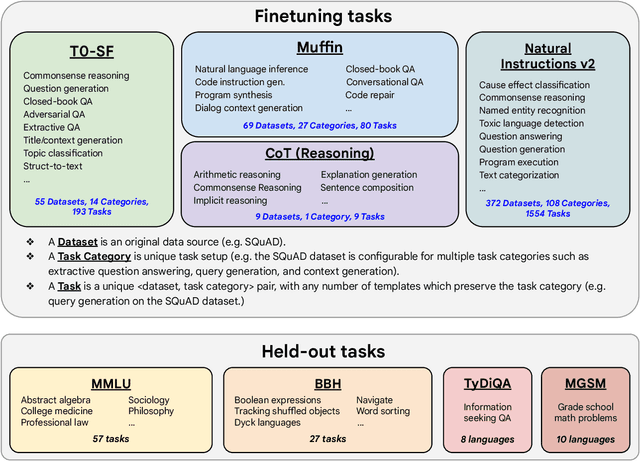

Finetuning language models on a collection of datasets phrased as instructions has been shown to improve model performance and generalization to unseen tasks. In this paper we explore instruction finetuning with a particular focus on (1) scaling the number of tasks, (2) scaling the model size, and (3) finetuning on chain-of-thought data. We find that instruction finetuning with the above aspects dramatically improves performance on a variety of model classes (PaLM, T5, U-PaLM), prompting setups (zero-shot, few-shot, CoT), and evaluation benchmarks (MMLU, BBH, TyDiQA, MGSM, open-ended generation). For instance, Flan-PaLM 540B instruction-finetuned on 1.8K tasks outperforms PALM 540B by a large margin (+9.4% on average). Flan-PaLM 540B achieves state-of-the-art performance on several benchmarks, such as 75.2% on five-shot MMLU. We also publicly release Flan-T5 checkpoints, which achieve strong few-shot performance even compared to much larger models, such as PaLM 62B. Overall, instruction finetuning is a general method for improving the performance and usability of pretrained language models.
Transcending Scaling Laws with 0.1% Extra Compute
Oct 20, 2022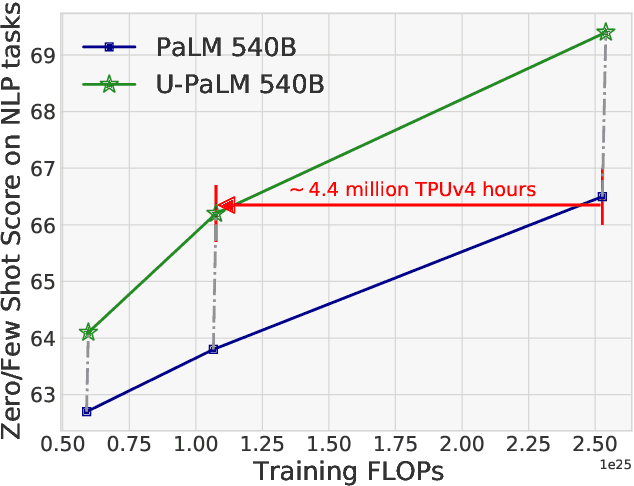
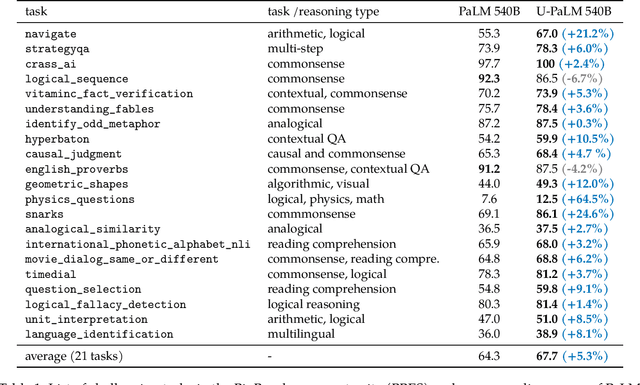
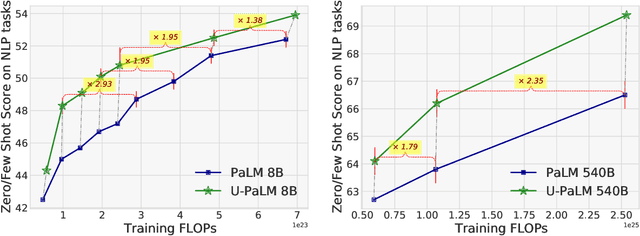
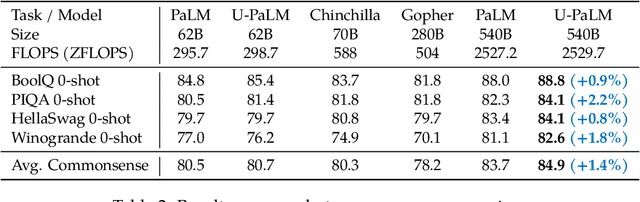
Scaling language models improves performance but comes with significant computational costs. This paper proposes UL2R, a method that substantially improves existing language models and their scaling curves with a relatively tiny amount of extra compute. The key idea is to continue training a state-of-the-art large language model (e.g., PaLM) on a few more steps with UL2's mixture-of-denoiser objective. We show that, with almost negligible extra computational costs and no new sources of data, we are able to substantially improve the scaling properties of large language models on downstream metrics. In this paper, we continue training PaLM with UL2R, introducing a new set of models at 8B, 62B, and 540B scale which we call U-PaLM. Impressively, at 540B scale, we show an approximately 2x computational savings rate where U-PaLM achieves the same performance as the final PaLM 540B model at around half its computational budget (i.e., saving $\sim$4.4 million TPUv4 hours). We further show that this improved scaling curve leads to 'emergent abilities' on challenging BIG-Bench tasks -- for instance, U-PaLM does much better than PaLM on some tasks or demonstrates better quality at much smaller scale (62B as opposed to 540B). Overall, we show that U-PaLM outperforms PaLM on many few-shot setups, i.e., English NLP tasks (e.g., commonsense reasoning, question answering), reasoning tasks with chain-of-thought (e.g., GSM8K), multilingual tasks (MGSM, TydiQA), MMLU and challenging BIG-Bench tasks. Finally, we provide qualitative examples showing the new capabilities of U-PaLM for single and multi-span infilling.
G-Augment: Searching For The Meta-Structure Of Data Augmentation Policies For ASR
Oct 19, 2022
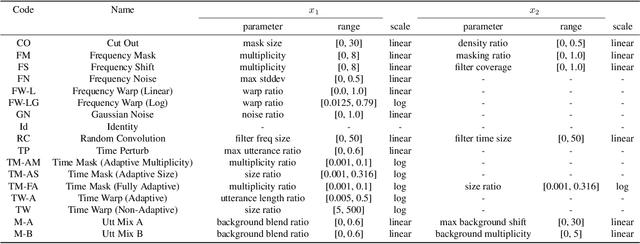
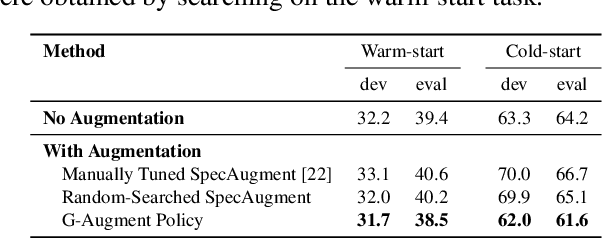
Data augmentation is a ubiquitous technique used to provide robustness to automatic speech recognition (ASR) training. However, even as so much of the ASR training process has become automated and more "end-to-end", the data augmentation policy (what augmentation functions to use, and how to apply them) remains hand-crafted. We present Graph-Augment, a technique to define the augmentation space as directed acyclic graphs (DAGs) and search over this space to optimize the augmentation policy itself. We show that given the same computational budget, policies produced by G-Augment are able to perform better than SpecAugment policies obtained by random search on fine-tuning tasks on CHiME-6 and AMI. G-Augment is also able to establish a new state-of-the-art ASR performance on the CHiME-6 evaluation set (30.7% WER). We further demonstrate that G-Augment policies show better transfer properties across warm-start to cold-start training and model size compared to random-searched SpecAugment policies.
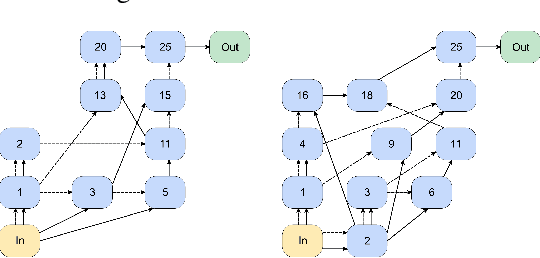
Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them
Oct 17, 2022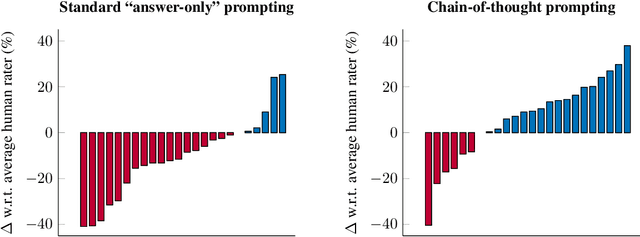

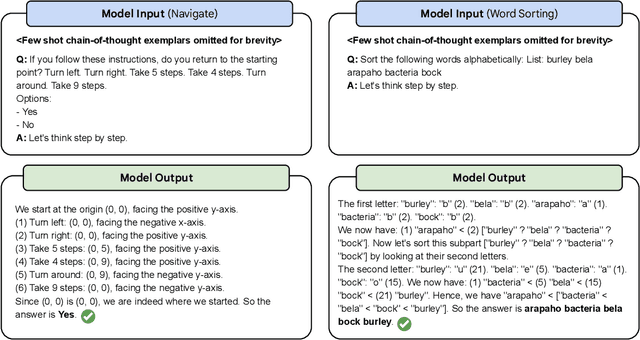
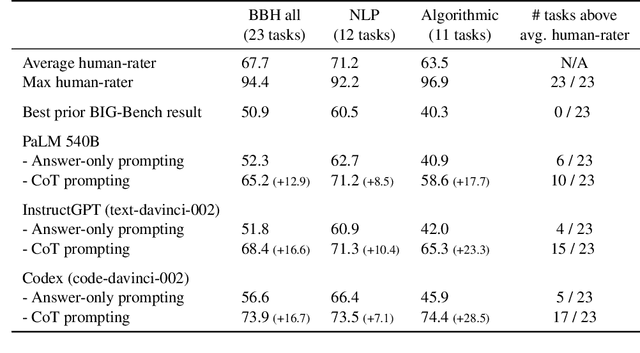
BIG-Bench (Srivastava et al., 2022) is a diverse evaluation suite that focuses on tasks believed to be beyond the capabilities of current language models. Language models have already made good progress on this benchmark, with the best model in the BIG-Bench paper outperforming average reported human-rater results on 65% of the BIG-Bench tasks via few-shot prompting. But on what tasks do language models fall short of average human-rater performance, and are those tasks actually unsolvable by current language models? In this work, we focus on a suite of 23 challenging BIG-Bench tasks which we call BIG-Bench Hard (BBH). These are the task for which prior language model evaluations did not outperform the average human-rater. We find that applying chain-of-thought (CoT) prompting to BBH tasks enables PaLM to surpass the average human-rater performance on 10 of the 23 tasks, and Codex (code-davinci-002) to surpass the average human-rater performance on 17 of the 23 tasks. Since many tasks in BBH require multi-step reasoning, few-shot prompting without CoT, as done in the BIG-Bench evaluations (Srivastava et al., 2022), substantially underestimates the best performance and capabilities of language models, which is better captured via CoT prompting. As further analysis, we explore the interaction between CoT and model scale on BBH, finding that CoT enables emergent task performance on several BBH tasks with otherwise flat scaling curves.
Revisiting Multi-Scale Feature Fusion for Semantic Segmentation
Mar 23, 2022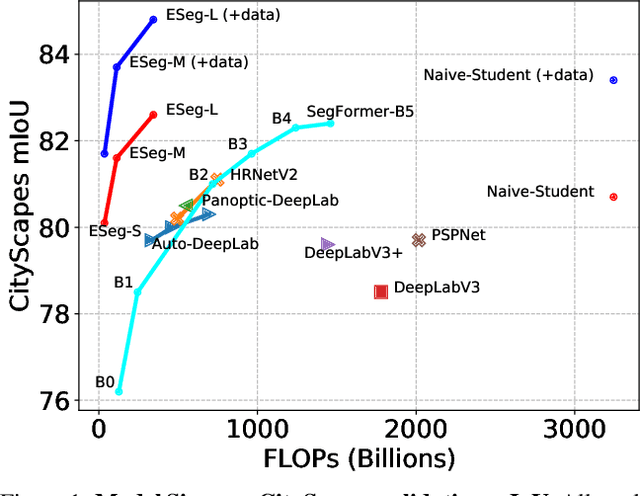

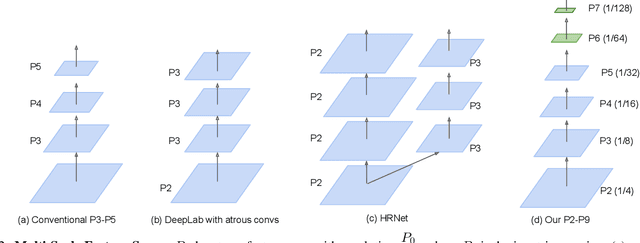
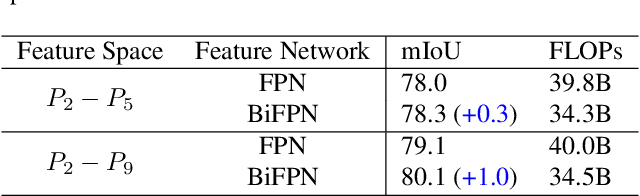
It is commonly believed that high internal resolution combined with expensive operations (e.g. atrous convolutions) are necessary for accurate semantic segmentation, resulting in slow speed and large memory usage. In this paper, we question this belief and demonstrate that neither high internal resolution nor atrous convolutions are necessary. Our intuition is that although segmentation is a dense per-pixel prediction task, the semantics of each pixel often depend on both nearby neighbors and far-away context; therefore, a more powerful multi-scale feature fusion network plays a critical role. Following this intuition, we revisit the conventional multi-scale feature space (typically capped at P5) and extend it to a much richer space, up to P9, where the smallest features are only 1/512 of the input size and thus have very large receptive fields. To process such a rich feature space, we leverage the recent BiFPN to fuse the multi-scale features. Based on these insights, we develop a simplified segmentation model, named ESeg, which has neither high internal resolution nor expensive atrous convolutions. Perhaps surprisingly, our simple method can achieve better accuracy with faster speed than prior art across multiple datasets. In real-time settings, ESeg-Lite-S achieves 76.0% mIoU on CityScapes [12] at 189 FPS, outperforming FasterSeg [9] (73.1% mIoU at 170 FPS). Our ESeg-Lite-L runs at 79 FPS and achieves 80.1% mIoU, largely closing the gap between real-time and high-performance segmentation models.