 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster Perturbed Stochastic Gradient Methods for Finding Local Minima
Oct 25, 2021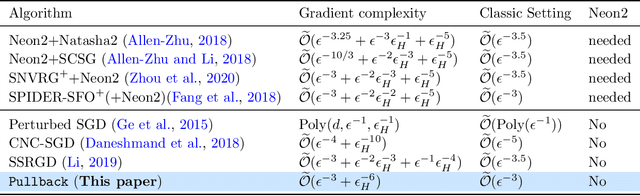
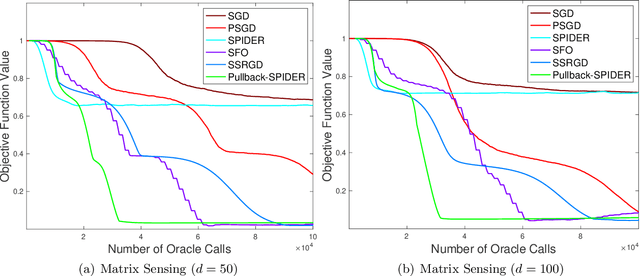
Escaping from saddle points and finding local minima is a central problem in nonconvex optimization. Perturbed gradient methods are perhaps the simplest approach for this problem. However, to find $(\epsilon, \sqrt{\epsilon})$-approximate local minima, the existing best stochastic gradient complexity for this type of algorithms is $\tilde O(\epsilon^{-3.5})$, which is not optimal. In this paper, we propose \texttt{Pullback}, a faster perturbed stochastic gradient framework for finding local minima. We show that Pullback with stochastic gradient estimators such as SARAH/SPIDER and STORM can find $(\epsilon, \epsilon_{H})$-approximate local minima within $\tilde O(\epsilon^{-3} + \epsilon_{H}^{-6})$ stochastic gradient evaluations (or $\tilde O(\epsilon^{-3})$ when $\epsilon_H = \sqrt{\epsilon}$). The core idea of our framework is a step-size ``pullback'' scheme to control the average movement of the iterates, which leads to faster convergence to the local minima. Experiments on matrix factorization problems corroborate our theory.
Linear Contextual Bandits with Adversarial Corruptions
Oct 25, 2021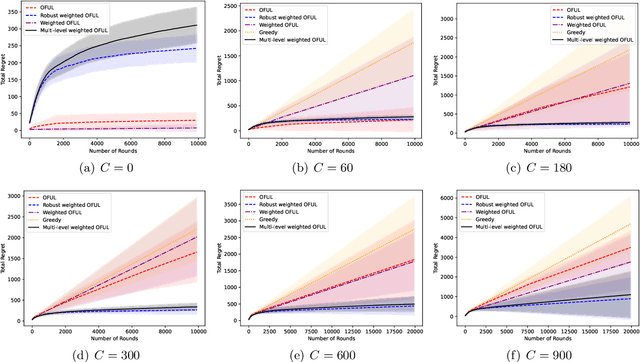
We study the linear contextual bandit problem in the presence of adversarial corruption, where the interaction between the player and a possibly infinite decision set is contaminated by an adversary that can corrupt the reward up to a corruption level $C$ measured by the sum of the largest alteration on rewards in each round. We present a variance-aware algorithm that is adaptive to the level of adversarial contamination $C$. The key algorithmic design includes (1) a multi-level partition scheme of the observed data, (2) a cascade of confidence sets that are adaptive to the level of the corruption, and (3) a variance-aware confidence set construction that can take advantage of low-variance reward. We further prove that the regret of the proposed algorithm is $\tilde{O}(C^2d\sqrt{\sum_{t = 1}^T \sigma_t^2} + C^2R\sqrt{dT})$, where $d$ is the dimension of context vectors, $T$ is the number of rounds, $R$ is the range of noise and $\sigma_t^2,t=1\ldots,T$ are the variances of instantaneous reward. We also prove a gap-dependent regret bound for the proposed algorithm, which is instance-dependent and thus leads to better performance on good practical instances. To the best of our knowledge, this is the first variance-aware corruption-robust algorithm for contextual bandits. Experiments on synthetic data corroborate our theory.
Adaptive Differentially Private Empirical Risk Minimization
Oct 25, 2021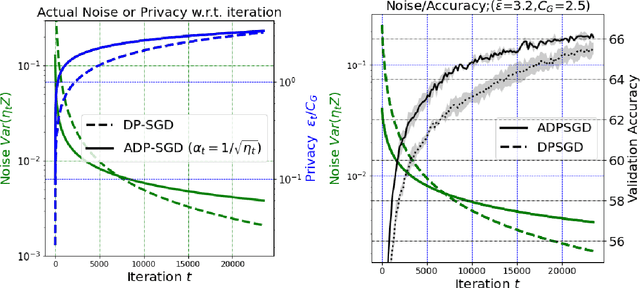
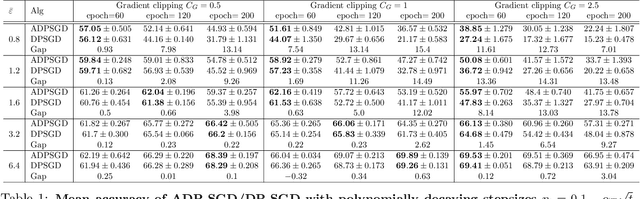
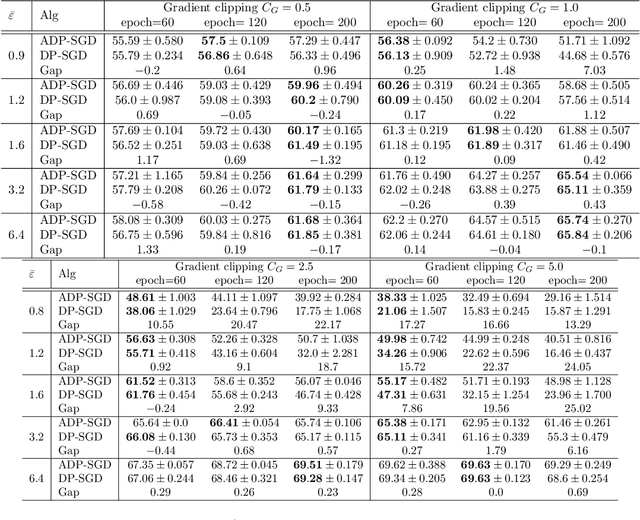
We propose an adaptive (stochastic) gradient perturbation method for differentially private empirical risk minimization. At each iteration, the random noise added to the gradient is optimally adapted to the stepsize; we name this process adaptive differentially private (ADP) learning. Given the same privacy budget, we prove that the ADP method considerably improves the utility guarantee compared to the standard differentially private method in which vanilla random noise is added. Our method is particularly useful for gradient-based algorithms with time-varying learning rates, including variants of AdaGrad (Duchi et al., 2011). We provide extensive numerical experiments to demonstrate the effectiveness of the proposed adaptive differentially private algorithm.
Exploring Architectural Ingredients of Adversarially Robust Deep Neural Networks
Oct 21, 2021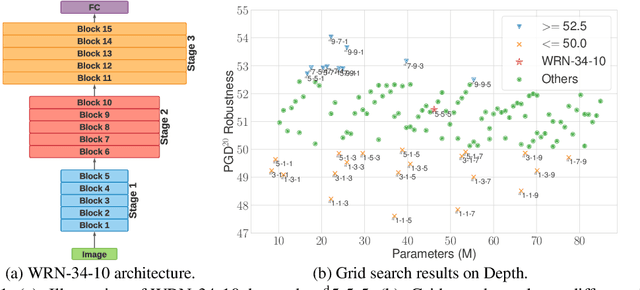
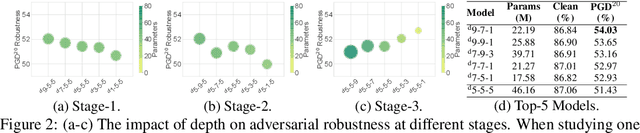
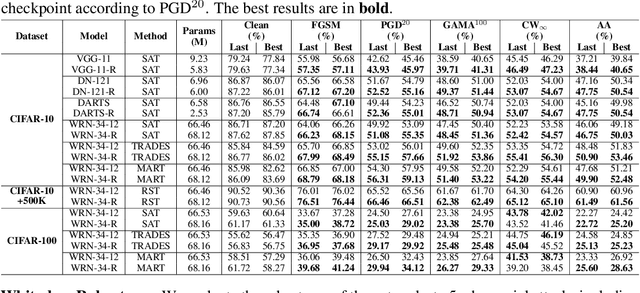
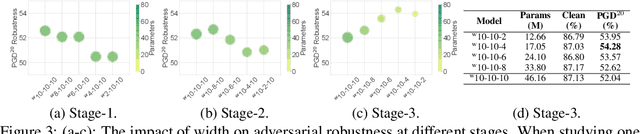
Deep neural networks (DNNs) are known to be vulnerable to adversarial attacks. A range of defense methods have been proposed to train adversarially robust DNNs, among which adversarial training has demonstrated promising results. However, despite preliminary understandings developed for adversarial training, it is still not clear, from the architectural perspective, what configurations can lead to more robust DNNs. In this paper, we address this gap via a comprehensive investigation on the impact of network width and depth on the robustness of adversarially trained DNNs. Specifically, we make the following key observations: 1) more parameters (higher model capacity) does not necessarily help adversarial robustness; 2) reducing capacity at the last stage (the last group of blocks) of the network can actually improve adversarial robustness; and 3) under the same parameter budget, there exists an optimal architectural configuration for adversarial robustness. We also provide a theoretical analysis explaning why such network configuration can help robustness. These architectural insights can help design adversarially robust DNNs. Code is available at \url{https://github.com/HanxunH/RobustWRN}.
Locally Differentially Private Reinforcement Learning for Linear Mixture Markov Decision Processes
Oct 19, 2021
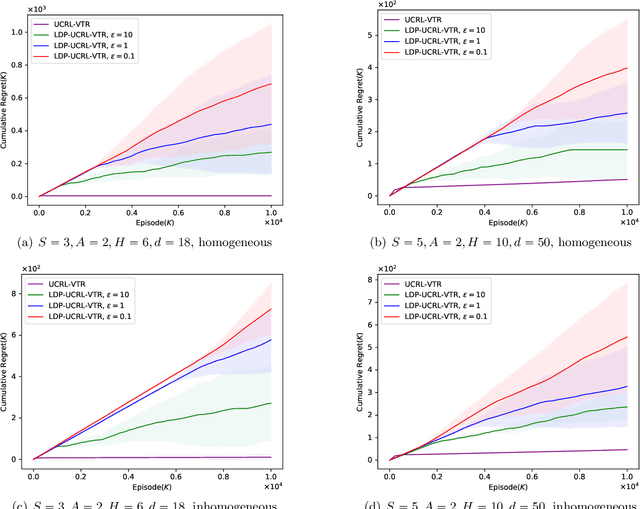
Reinforcement learning (RL) algorithms can be used to provide personalized services, which rely on users' private and sensitive data. To protect the users' privacy, privacy-preserving RL algorithms are in demand. In this paper, we study RL with linear function approximation and local differential privacy (LDP) guarantees. We propose a novel $(\varepsilon, \delta)$-LDP algorithm for learning a class of Markov decision processes (MDPs) dubbed linear mixture MDPs, and obtains an $\tilde{\mathcal{O}}( d^{5/4}H^{7/4}T^{3/4}\left(\log(1/\delta)\right)^{1/4}\sqrt{1/\varepsilon})$ regret, where $d$ is the dimension of feature mapping, $H$ is the length of the planning horizon, and $T$ is the number of interactions with the environment. We also prove a lower bound $\Omega(dH\sqrt{T}/\left(e^{\varepsilon}(e^{\varepsilon}-1)\right))$ for learning linear mixture MDPs under $\varepsilon$-LDP constraint. Experiments on synthetic datasets verify the effectiveness of our algorithm. To the best of our knowledge, this is the first provable privacy-preserving RL algorithm with linear function approximation.
Iterative Teacher-Aware Learning
Oct 17, 2021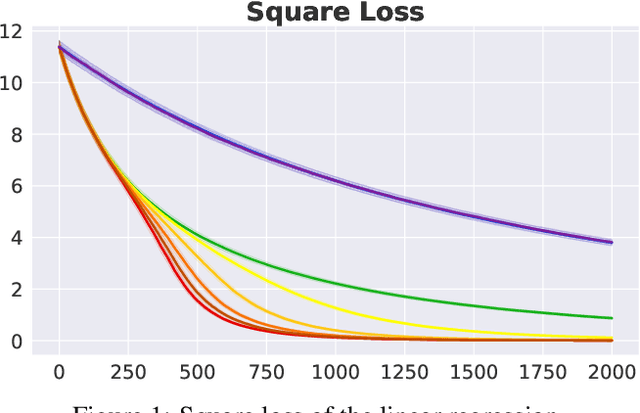
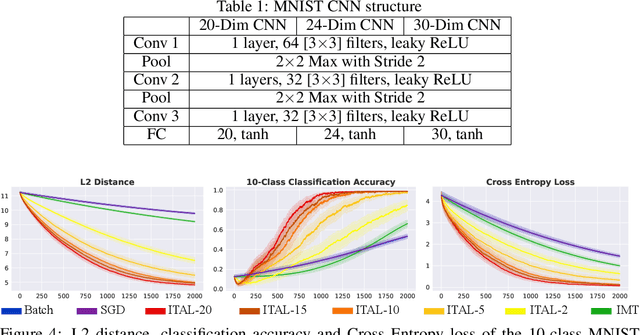
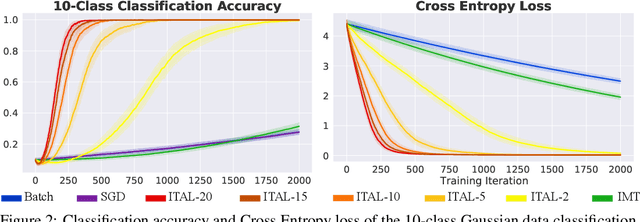

In human pedagogy, teachers and students can interact adaptively to maximize communication efficiency. The teacher adjusts her teaching method for different students, and the student, after getting familiar with the teacher's instruction mechanism, can infer the teacher's intention to learn faster. Recently, the benefits of integrating this cooperative pedagogy into machine concept learning in discrete spaces have been proved by multiple works. However, how cooperative pedagogy can facilitate machine parameter learning hasn't been thoroughly studied. In this paper, we propose a gradient optimization based teacher-aware learner who can incorporate teacher's cooperative intention into the likelihood function and learn provably faster compared with the naive learning algorithms used in previous machine teaching works. We give theoretical proof that the iterative teacher-aware learning (ITAL) process leads to local and global improvements. We then validate our algorithms with extensive experiments on various tasks including regression, classification, and inverse reinforcement learning using synthetic and real data. We also show the advantage of modeling teacher-awareness when agents are learning from human teachers.
Reward-Free Model-Based Reinforcement Learning with Linear Function Approximation
Oct 12, 2021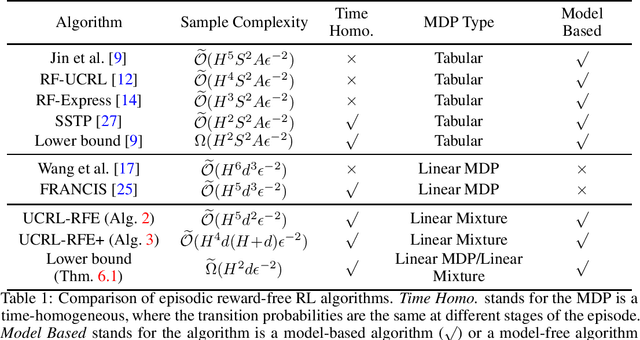
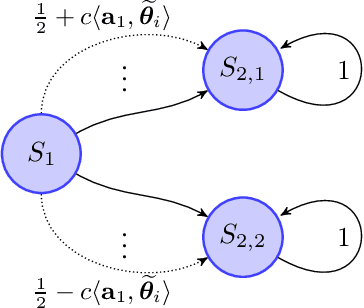
We study the model-based reward-free reinforcement learning with linear function approximation for episodic Markov decision processes (MDPs). In this setting, the agent works in two phases. In the exploration phase, the agent interacts with the environment and collects samples without the reward. In the planning phase, the agent is given a specific reward function and uses samples collected from the exploration phase to learn a good policy. We propose a new provably efficient algorithm, called UCRL-RFE under the Linear Mixture MDP assumption, where the transition probability kernel of the MDP can be parameterized by a linear function over certain feature mappings defined on the triplet of state, action, and next state. We show that to obtain an $\epsilon$-optimal policy for arbitrary reward function, UCRL-RFE needs to sample at most $\tilde O(H^5d^2\epsilon^{-2})$ episodes during the exploration phase. Here, $H$ is the length of the episode, $d$ is the dimension of the feature mapping. We also propose a variant of UCRL-RFE using Bernstein-type bonus and show that it needs to sample at most $\tilde O(H^4d(H + d)\epsilon^{-2})$ to achieve an $\epsilon$-optimal policy. By constructing a special class of linear Mixture MDPs, we also prove that for any reward-free algorithm, it needs to sample at least $\tilde \Omega(H^2d\epsilon^{-2})$ episodes to obtain an $\epsilon$-optimal policy. Our upper bound matches the lower bound in terms of the dependence on $\epsilon$ and the dependence on $d$ if $H \ge d$.
Last Iterate Risk Bounds of SGD with Decaying Stepsize for Overparameterized Linear Regression
Oct 12, 2021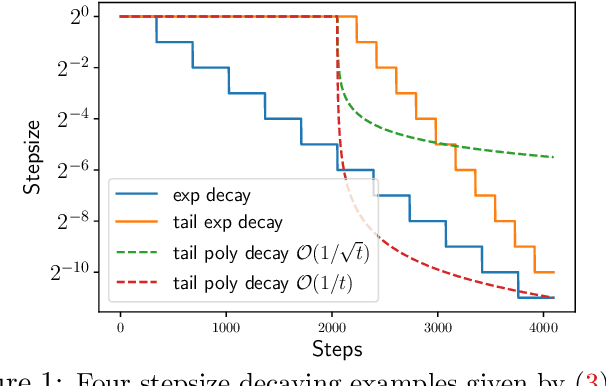
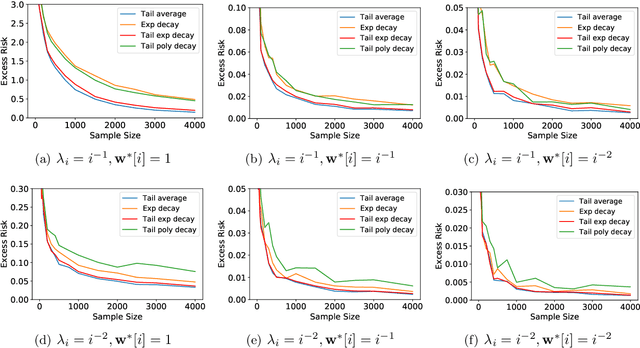
Stochastic gradient descent (SGD) has been demonstrated to generalize well in many deep learning applications. In practice, one often runs SGD with a geometrically decaying stepsize, i.e., a constant initial stepsize followed by multiple geometric stepsize decay, and uses the last iterate as the output. This kind of SGD is known to be nearly minimax optimal for classical finite-dimensional linear regression problems (Ge et al., 2019), and provably outperforms SGD with polynomially decaying stepsize in terms of the statistical minimax rates. However, a sharp analysis for the last iterate of SGD with decaying step size in the overparameterized setting is still open. In this paper, we provide problem-dependent analysis on the last iterate risk bounds of SGD with decaying stepsize, for (overparameterized) linear regression problems. In particular, for SGD with geometrically decaying stepsize (or tail geometrically decaying stepsize), we prove nearly matching upper and lower bounds on the excess risk. Our results demonstrate the generalization ability of SGD for a wide class of overparameterized problems, and can recover the minimax optimal results up to logarithmic factors in the classical regime. Moreover, we provide an excess risk lower bound for SGD with polynomially decaying stepsize and illustrate the advantage of geometrically decaying stepsize in an instance-wise manner, which complements the minimax rate comparison made in previous work.
Adaptive Sampling for Heterogeneous Rank Aggregation from Noisy Pairwise Comparisons
Oct 08, 2021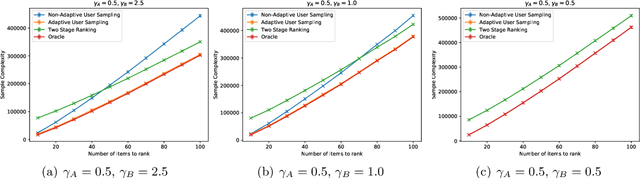
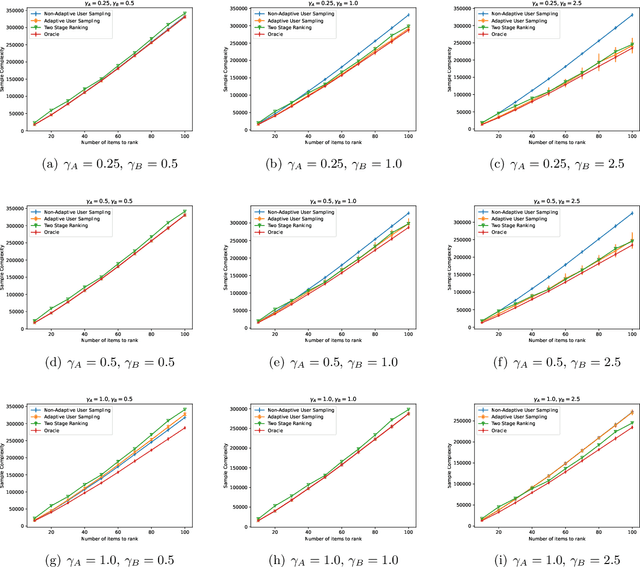
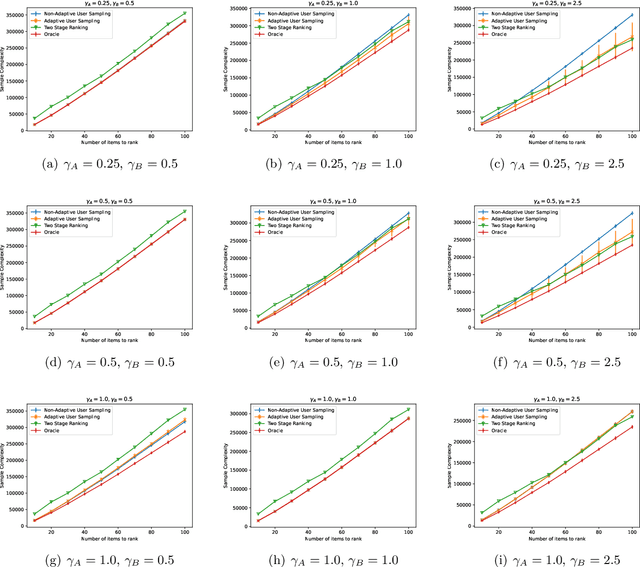
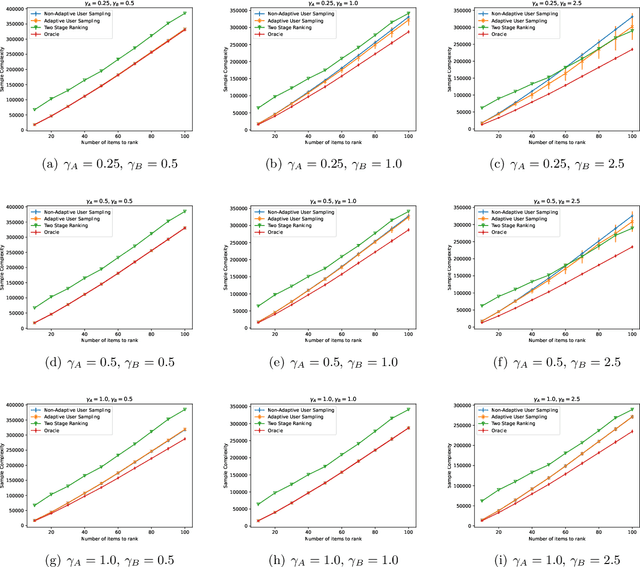
In heterogeneous rank aggregation problems, users often exhibit various accuracy levels when comparing pairs of items. Thus a uniform querying strategy over users may not be optimal. To address this issue, we propose an elimination-based active sampling strategy, which estimates the ranking of items via noisy pairwise comparisons from users and improves the users' average accuracy by maintaining an active set of users. We prove that our algorithm can return the true ranking of items with high probability. We also provide a sample complexity bound for the proposed algorithm which is better than that of non-active strategies in the literature. Experiments are provided to show the empirical advantage of the proposed methods over the state-of-the-art baselines.
Understanding the Generalization of Adam in Learning Neural Networks with Proper Regularization
Aug 25, 2021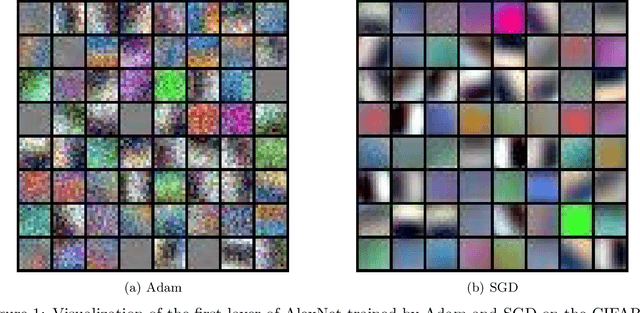
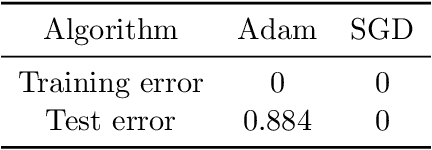
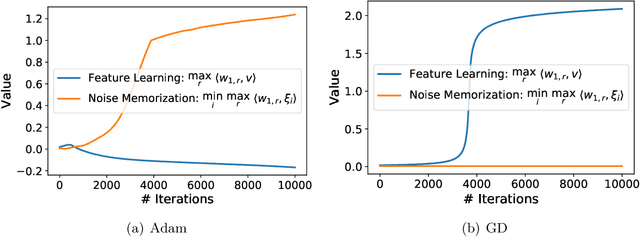
Adaptive gradient methods such as Adam have gained increasing popularity in deep learning optimization. However, it has been observed that compared with (stochastic) gradient descent, Adam can converge to a different solution with a significantly worse test error in many deep learning applications such as image classification, even with a fine-tuned regularization. In this paper, we provide a theoretical explanation for this phenomenon: we show that in the nonconvex setting of learning over-parameterized two-layer convolutional neural networks starting from the same random initialization, for a class of data distributions (inspired from image data), Adam and gradient descent (GD) can converge to different global solutions of the training objective with provably different generalization errors, even with weight decay regularization. In contrast, we show that if the training objective is convex, and the weight decay regularization is employed, any optimization algorithms including Adam and GD will converge to the same solution if the training is successful. This suggests that the inferior generalization performance of Adam is fundamentally tied to the nonconvex landscape of deep learning optimization.