 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePackUV: Packed Gaussian UV Maps for 4D Volumetric Video
Feb 26, 2026Volumetric videos offer immersive 4D experiences, but remain difficult to reconstruct, store, and stream at scale. Existing Gaussian Splatting based methods achieve high-quality reconstruction but break down on long sequences, temporal inconsistency, and fail under large motions and disocclusions. Moreover, their outputs are typically incompatible with conventional video coding pipelines, preventing practical applications. We introduce PackUV, a novel 4D Gaussian representation that maps all Gaussian attributes into a sequence of structured, multi-scale UV atlas, enabling compact, image-native storage. To fit this representation from multi-view videos, we propose PackUV-GS, a temporally consistent fitting method that directly optimizes Gaussian parameters in the UV domain. A flow-guided Gaussian labeling and video keyframing module identifies dynamic Gaussians, stabilizes static regions, and preserves temporal coherence even under large motions and disocclusions. The resulting UV atlas format is the first unified volumetric video representation compatible with standard video codecs (e.g., FFV1) without losing quality, enabling efficient streaming within existing multimedia infrastructure. To evaluate long-duration volumetric capture, we present PackUV-2B, the largest multi-view video dataset to date, featuring more than 50 synchronized cameras, substantial motion, and frequent disocclusions across 100 sequences and 2B (billion) frames. Extensive experiments demonstrate that our method surpasses existing baselines in rendering fidelity while scaling to sequences up to 30 minutes with consistent quality.
* https://ivl.cs.brown.edu/packuv
UVGS: Reimagining Unstructured 3D Gaussian Splatting using UV Mapping
Feb 03, 20253D Gaussian Splatting (3DGS) has demonstrated superior quality in modeling 3D objects and scenes. However, generating 3DGS remains challenging due to their discrete, unstructured, and permutation-invariant nature. In this work, we present a simple yet effective method to overcome these challenges. We utilize spherical mapping to transform 3DGS into a structured 2D representation, termed UVGS. UVGS can be viewed as multi-channel images, with feature dimensions as a concatenation of Gaussian attributes such as position, scale, color, opacity, and rotation. We further find that these heterogeneous features can be compressed into a lower-dimensional (e.g., 3-channel) shared feature space using a carefully designed multi-branch network. The compressed UVGS can be treated as typical RGB images. Remarkably, we discover that typical VAEs trained with latent diffusion models can directly generalize to this new representation without additional training. Our novel representation makes it effortless to leverage foundational 2D models, such as diffusion models, to directly model 3DGS. Additionally, one can simply increase the 2D UV resolution to accommodate more Gaussians, making UVGS a scalable solution compared to typical 3D backbones. This approach immediately unlocks various novel generation applications of 3DGS by inherently utilizing the already developed superior 2D generation capabilities. In our experiments, we demonstrate various unconditional, conditional generation, and inpainting applications of 3DGS based on diffusion models, which were previously non-trivial.
EgoSonics: Generating Synchronized Audio for Silent Egocentric Videos
Jul 30, 2024



We introduce EgoSonics, a method to generate semantically meaningful and synchronized audio tracks conditioned on silent egocentric videos. Generating audio for silent egocentric videos could open new applications in virtual reality, assistive technologies, or for augmenting existing datasets. Existing work has been limited to domains like speech, music, or impact sounds and cannot easily capture the broad range of audio frequencies found in egocentric videos. EgoSonics addresses these limitations by building on the strength of latent diffusion models for conditioned audio synthesis. We first encode and process audio and video data into a form that is suitable for generation. The encoded data is used to train our model to generate audio tracks that capture the semantics of the input video. Our proposed SyncroNet builds on top of ControlNet to provide control signals that enables temporal synchronization to the synthesized audio. Extensive evaluations show that our model outperforms existing work in audio quality, and in our newly proposed synchronization evaluation method. Furthermore, we demonstrate downstream applications of our model in improving video summarization.
Towards Realistic Generative 3D Face Models
Apr 24, 2023



In recent years, there has been significant progress in 2D generative face models fueled by applications such as animation, synthetic data generation, and digital avatars. However, due to the absence of 3D information, these 2D models often struggle to accurately disentangle facial attributes like pose, expression, and illumination, limiting their editing capabilities. To address this limitation, this paper proposes a 3D controllable generative face model to produce high-quality albedo and precise 3D shape leveraging existing 2D generative models. By combining 2D face generative models with semantic face manipulation, this method enables editing of detailed 3D rendered faces. The proposed framework utilizes an alternating descent optimization approach over shape and albedo. Differentiable rendering is used to train high-quality shapes and albedo without 3D supervision. Moreover, this approach outperforms the state-of-the-art (SOTA) methods in the well-known NoW benchmark for shape reconstruction. It also outperforms the SOTA reconstruction models in recovering rendered faces' identities across novel poses by an average of 10%. Additionally, the paper demonstrates direct control of expressions in 3D faces by exploiting latent space leading to text-based editing of 3D faces.
Controllable 3D Generative Adversarial Face Model via Disentangling Shape and Appearance
Aug 30, 2022
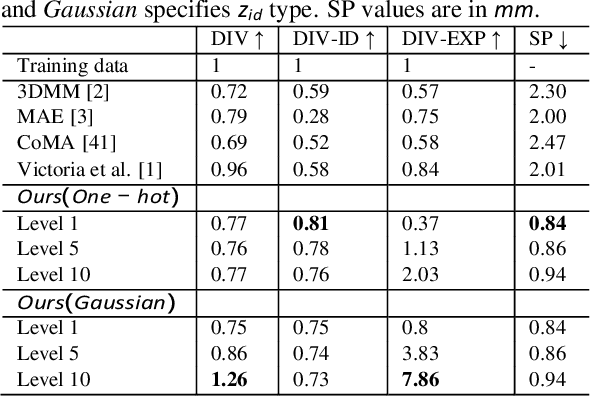
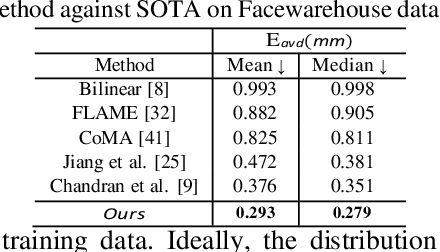
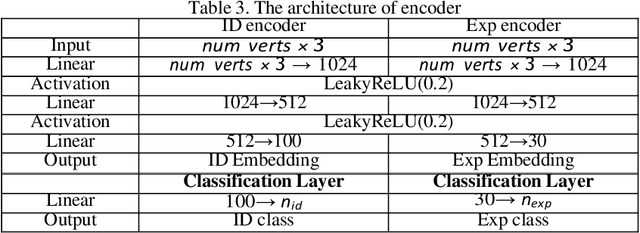
3D face modeling has been an active area of research in computer vision and computer graphics, fueling applications ranging from facial expression transfer in virtual avatars to synthetic data generation. Existing 3D deep learning generative models (e.g., VAE, GANs) allow generating compact face representations (both shape and texture) that can model non-linearities in the shape and appearance space (e.g., scatter effects, specularities, etc.). However, they lack the capability to control the generation of subtle expressions. This paper proposes a new 3D face generative model that can decouple identity and expression and provides granular control over expressions. In particular, we propose using a pair of supervised auto-encoder and generative adversarial networks to produce high-quality 3D faces, both in terms of appearance and shape. Experimental results in the generation of 3D faces learned with holistic expression labels, or Action Unit labels, show how we can decouple identity and expression; gaining fine-control over expressions while preserving identity.