 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSE-GAN: Dynamic Semantic Evolution Generative Adversarial Network for Text-to-Image Generation
Sep 03, 2022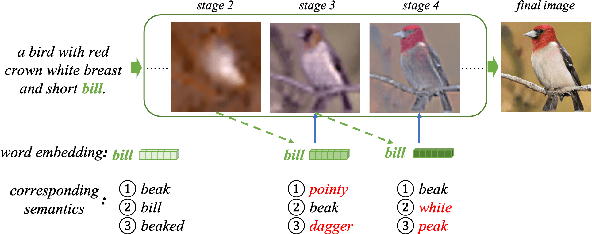
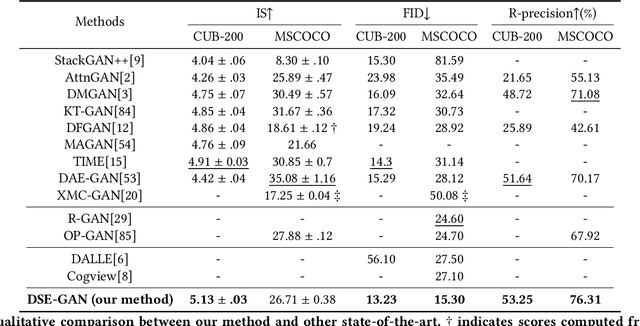
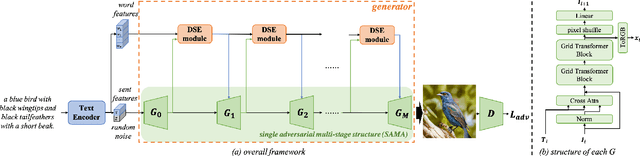

Text-to-image generation aims at generating realistic images which are semantically consistent with the given text. Previous works mainly adopt the multi-stage architecture by stacking generator-discriminator pairs to engage multiple adversarial training, where the text semantics used to provide generation guidance remain static across all stages. This work argues that text features at each stage should be adaptively re-composed conditioned on the status of the historical stage (i.e., historical stage's text and image features) to provide diversified and accurate semantic guidance during the coarse-to-fine generation process. We thereby propose a novel Dynamical Semantic Evolution GAN (DSE-GAN) to re-compose each stage's text features under a novel single adversarial multi-stage architecture. Specifically, we design (1) Dynamic Semantic Evolution (DSE) module, which first aggregates historical image features to summarize the generative feedback, and then dynamically selects words required to be re-composed at each stage as well as re-composed them by dynamically enhancing or suppressing different granularity subspace's semantics. (2) Single Adversarial Multi-stage Architecture (SAMA), which extends the previous structure by eliminating complicated multiple adversarial training requirements and therefore allows more stages of text-image interactions, and finally facilitates the DSE module. We conduct comprehensive experiments and show that DSE-GAN achieves 7.48\% and 37.8\% relative FID improvement on two widely used benchmarks, i.e., CUB-200 and MSCOCO, respectively.
Structure-aware Editable Morphable Model for 3D Facial Detail Animation and Manipulation
Jul 19, 2022

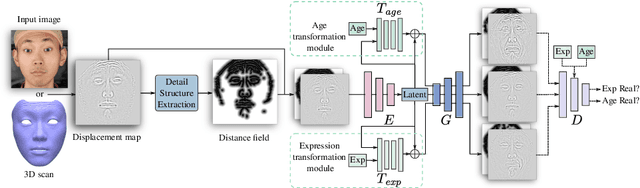
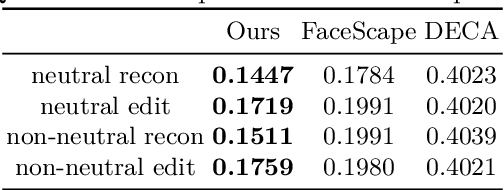
Morphable models are essential for the statistical modeling of 3D faces. Previous works on morphable models mostly focus on large-scale facial geometry but ignore facial details. This paper augments morphable models in representing facial details by learning a Structure-aware Editable Morphable Model (SEMM). SEMM introduces a detail structure representation based on the distance field of wrinkle lines, jointly modeled with detail displacements to establish better correspondences and enable intuitive manipulation of wrinkle structure. Besides, SEMM introduces two transformation modules to translate expression blendshape weights and age values into changes in latent space, allowing effective semantic detail editing while maintaining identity. Extensive experiments demonstrate that the proposed model compactly represents facial details, outperforms previous methods in expression animation qualitatively and quantitatively, and achieves effective age editing and wrinkle line editing of facial details. Code and model are available at https://github.com/gerwang/facial-detail-manipulation.
Controllable 3D Face Synthesis with Conditional Generative Occupancy Fields
Jun 16, 2022
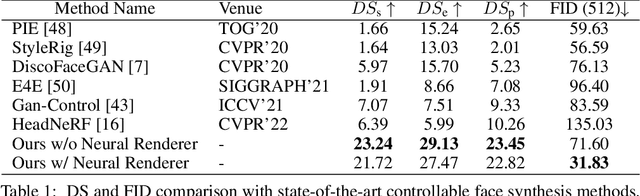
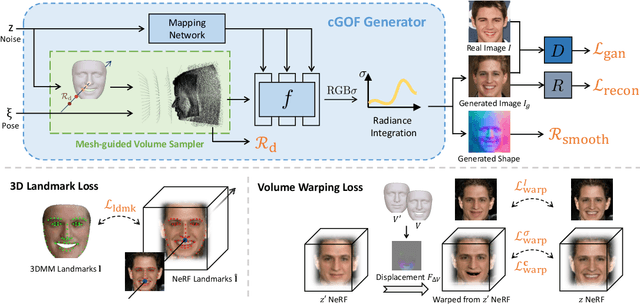
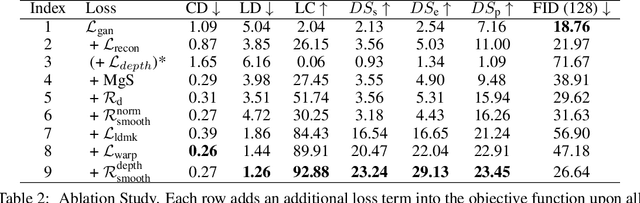
Capitalizing on the recent advances in image generation models, existing controllable face image synthesis methods are able to generate high-fidelity images with some levels of controllability, e.g., controlling the shapes, expressions, textures, and poses of the generated face images. However, these methods focus on 2D image generative models, which are prone to producing inconsistent face images under large expression and pose changes. In this paper, we propose a new NeRF-based conditional 3D face synthesis framework, which enables 3D controllability over the generated face images by imposing explicit 3D conditions from 3D face priors. At its core is a conditional Generative Occupancy Field (cGOF) that effectively enforces the shape of the generated face to commit to a given 3D Morphable Model (3DMM) mesh. To achieve accurate control over fine-grained 3D face shapes of the synthesized image, we additionally incorporate a 3D landmark loss as well as a volume warping loss into our synthesis algorithm. Experiments validate the effectiveness of the proposed method, which is able to generate high-fidelity face images and shows more precise 3D controllability than state-of-the-art 2D-based controllable face synthesis methods. Find code and demo at https://keqiangsun.github.io/projects/cgof.
Personal VAD 2.0: Optimizing Personal Voice Activity Detection for On-Device Speech Recognition
Apr 13, 2022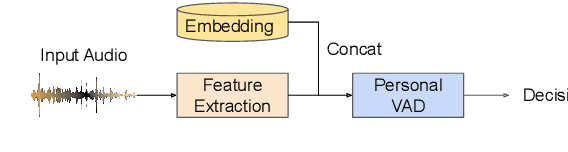
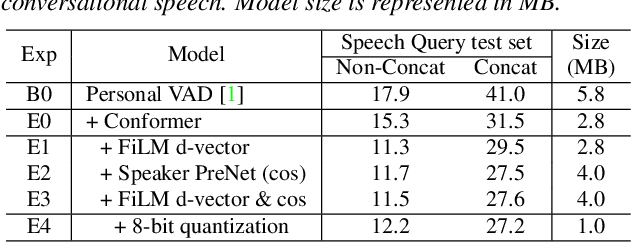
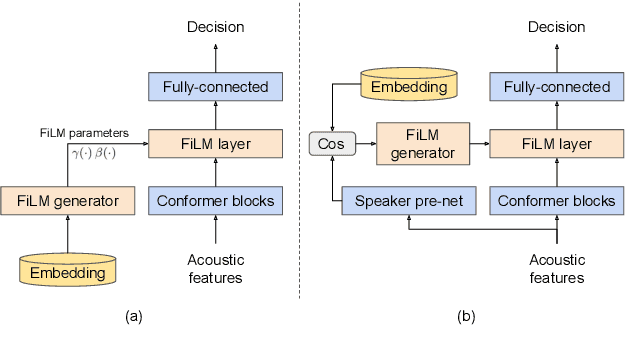
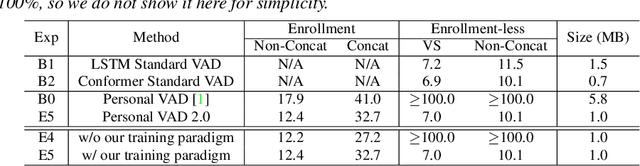
Personalization of on-device speech recognition (ASR) has seen explosive growth in recent years, largely due to the increasing popularity of personal assistant features on mobile devices and smart home speakers. In this work, we present Personal VAD 2.0, a personalized voice activity detector that detects the voice activity of a target speaker, as part of a streaming on-device ASR system. Although previous proof-of-concept studies have validated the effectiveness of Personal VAD, there are still several critical challenges to address before this model can be used in production: first, the quality must be satisfactory in both enrollment and enrollment-less scenarios; second, it should operate in a streaming fashion; and finally, the model size should be small enough to fit a limited latency and CPU/Memory budget. To meet the multi-faceted requirements, we propose a series of novel designs: 1) advanced speaker embedding modulation methods; 2) a new training paradigm to generalize to enrollment-less conditions; 3) architecture and runtime optimizations for latency and resource restrictions. Extensive experiments on a realistic speech recognition system demonstrated the state-of-the-art performance of our proposed method.
Fast fluorescence lifetime imaging analysis via extreme learning machine
Mar 25, 2022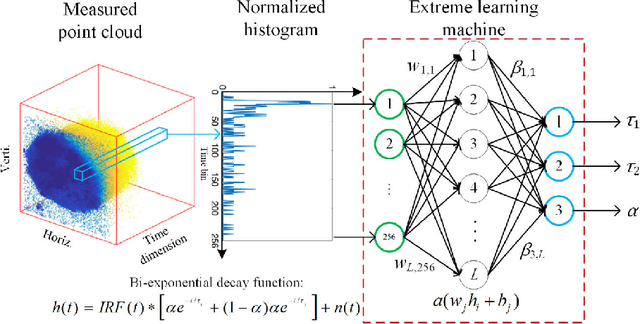

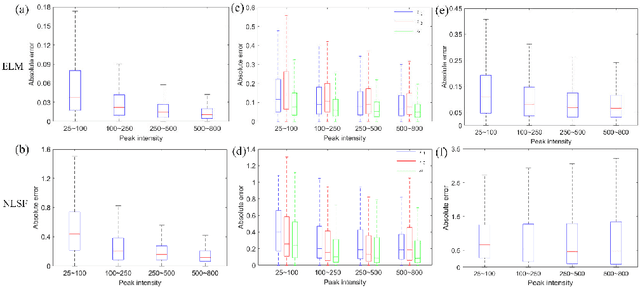
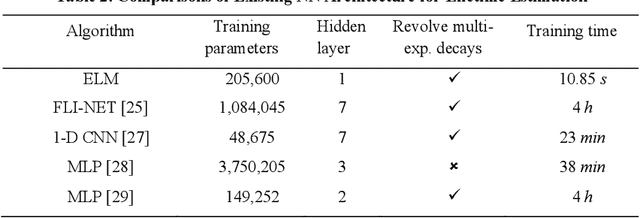
We present a fast and accurate analytical method for fluorescence lifetime imaging microscopy (FLIM) using the extreme learning machine (ELM). We used extensive metrics to evaluate ELM and existing algorithms. First, we compared these algorithms using synthetic datasets. Results indicate that ELM can obtain higher fidelity, even in low-photon conditions. Afterwards, we used ELM to retrieve lifetime components from human prostate cancer cells loaded with gold nanosensors, showing that ELM also outperforms the iterative fitting and non-fitting algorithms. By comparing ELM with a computational efficient neural network, ELM achieves comparable accuracy with less training and inference time. As there is no back-propagation process for ELM during the training phase, the training speed is much higher than existing neural network approaches. The proposed strategy is promising for edge computing with online training.
Bailando: 3D Dance Generation by Actor-Critic GPT with Choreographic Memory
Mar 25, 2022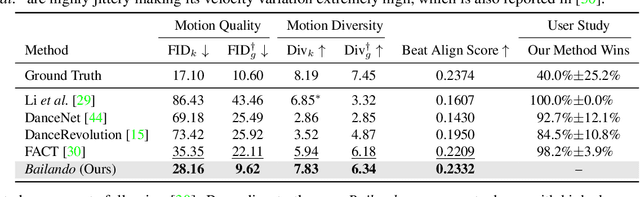
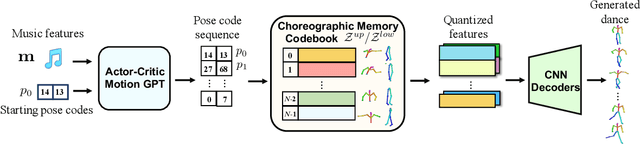
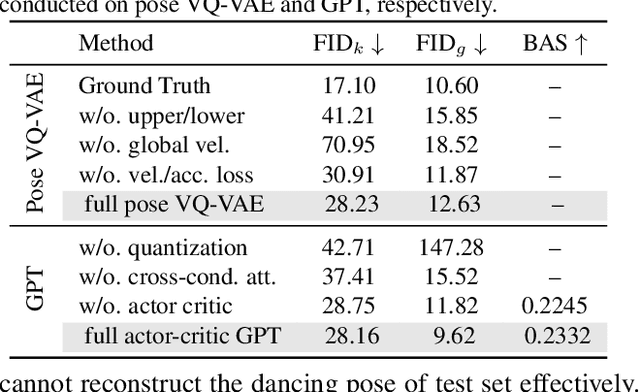
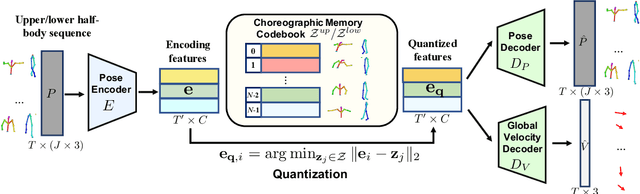
Driving 3D characters to dance following a piece of music is highly challenging due to the spatial constraints applied to poses by choreography norms. In addition, the generated dance sequence also needs to maintain temporal coherency with different music genres. To tackle these challenges, we propose a novel music-to-dance framework, Bailando, with two powerful components: 1) a choreographic memory that learns to summarize meaningful dancing units from 3D pose sequence to a quantized codebook, 2) an actor-critic Generative Pre-trained Transformer (GPT) that composes these units to a fluent dance coherent to the music. With the learned choreographic memory, dance generation is realized on the quantized units that meet high choreography standards, such that the generated dancing sequences are confined within the spatial constraints. To achieve synchronized alignment between diverse motion tempos and music beats, we introduce an actor-critic-based reinforcement learning scheme to the GPT with a newly-designed beat-align reward function. Extensive experiments on the standard benchmark demonstrate that our proposed framework achieves state-of-the-art performance both qualitatively and quantitatively. Notably, the learned choreographic memory is shown to discover human-interpretable dancing-style poses in an unsupervised manner.
Attentive Temporal Pooling for Conformer-based Streaming Language Identification in Long-form Speech
Mar 21, 2022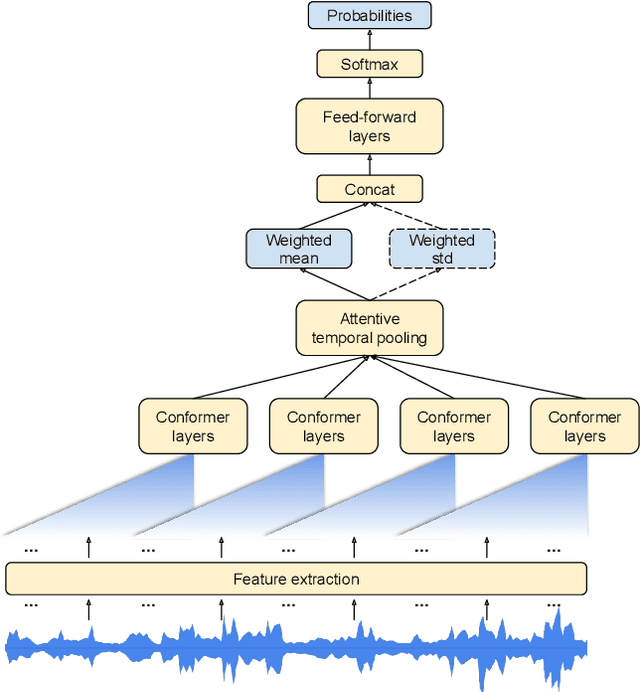
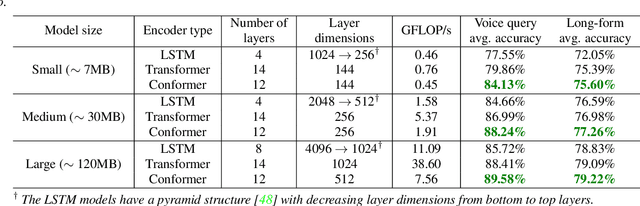
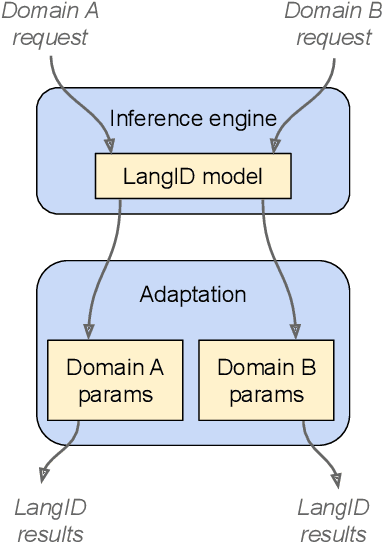
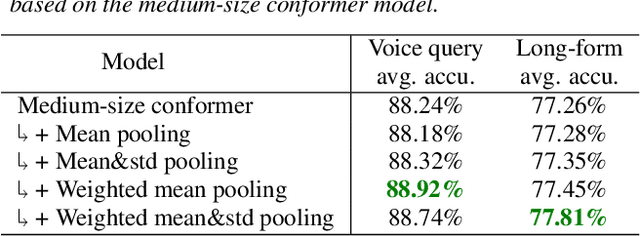
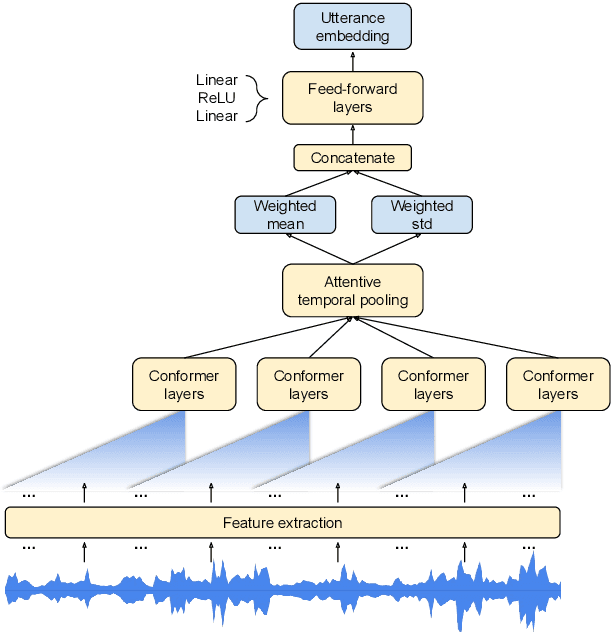
In this paper, we introduce a novel language identification system based on conformer layers. We propose an attentive temporal pooling mechanism to allow the model to carry information in long-form audio via a recurrent form, such that the inference can be performed in a streaming fashion. Additionally, a simple domain adaptation mechanism is introduced to allow adapting an existing language identification model to a new domain where the prior language distribution is different. We perform a comparative study of different model topologies under different constraints of model size, and find that conformer-base models outperform LSTM and transformer based models. Our experiments also show that attentive temporal pooling and domain adaptation significantly improve the model accuracy.
Parameter-Free Attentive Scoring for Speaker Verification
Mar 10, 2022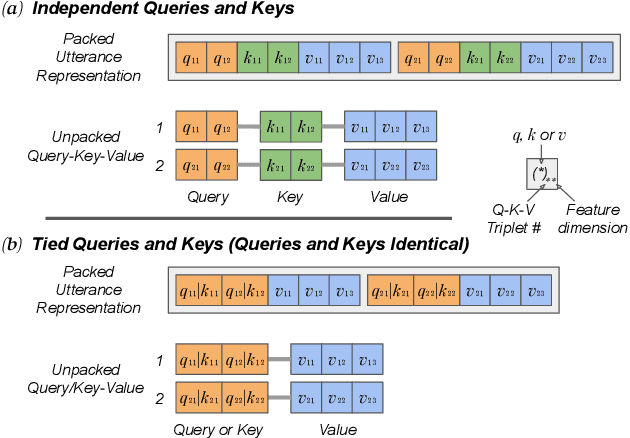
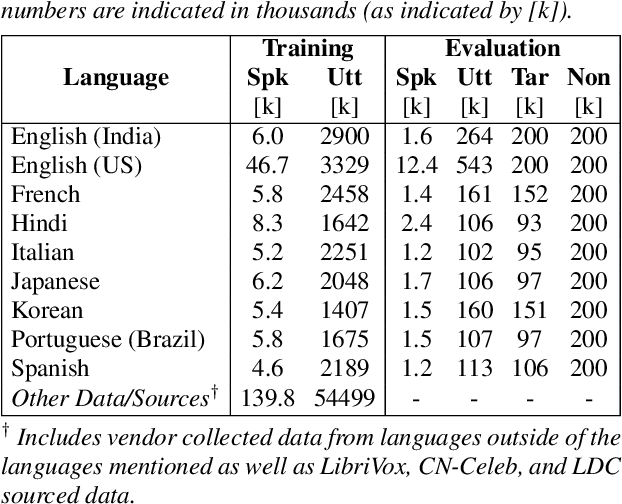
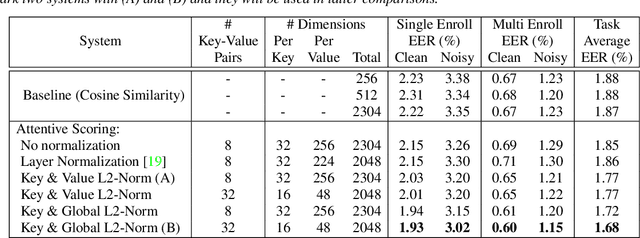
This paper presents a novel study of parameter-free attentive scoring for speaker verification. Parameter-free scoring provides the flexibility of comparing speaker representations without the need of an accompanying parametric scoring model. Inspired by the attention component in Transformer neural networks, we propose a variant of the scaled dot product attention mechanism to compare enrollment and test segment representations. In addition, this work explores the effect on performance of (i) different types of normalization, (ii) independent versus tied query/key estimation, (iii) varying the number of key-value pairs and (iv) pooling multiple enrollment utterance statistics. Experimental results for a 4 task average show that a simple parameter-free attentive scoring mechanism can improve the average EER by 10% over the best cosine similarity baseline.
Closing the Gap between Single-User and Multi-User VoiceFilter-Lite
Feb 24, 2022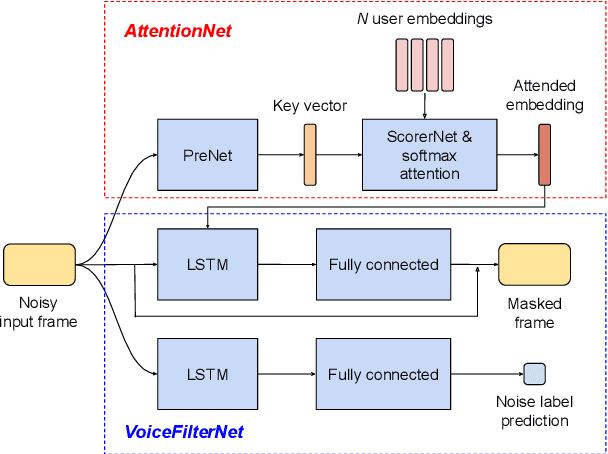
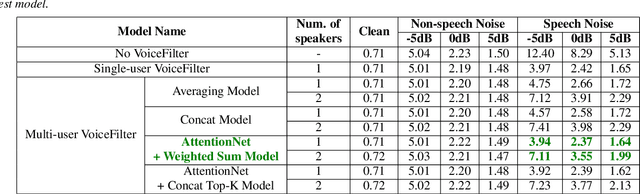
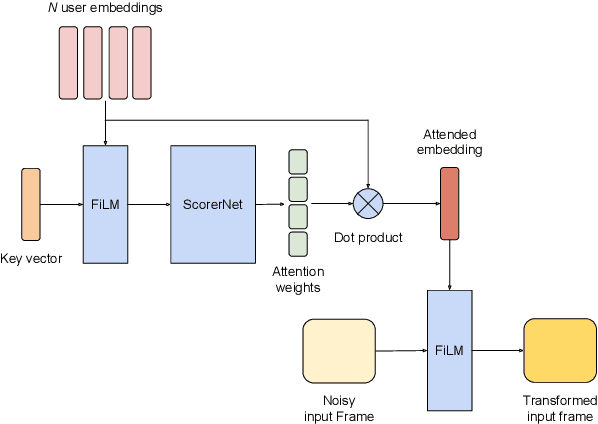
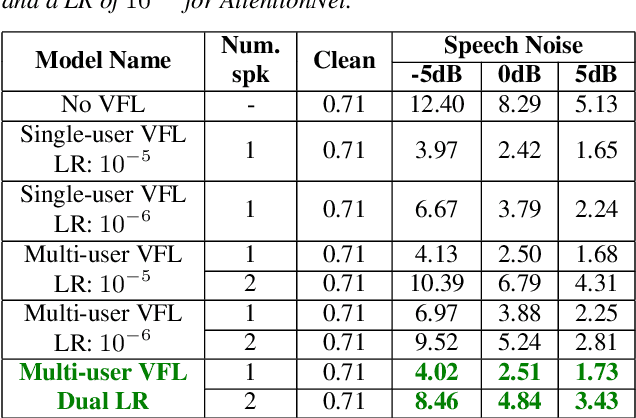
VoiceFilter-Lite is a speaker-conditioned voice separation model that plays a crucial role in improving speech recognition and speaker verification by suppressing overlapping speech from non-target speakers. However, one limitation of VoiceFilter-Lite, and other speaker-conditioned speech models in general, is that these models are usually limited to a single target speaker. This is undesirable as most smart home devices now support multiple enrolled users. In order to extend the benefits of personalization to multiple users, we previously developed an attention-based speaker selection mechanism and applied it to VoiceFilter-Lite. However, the original multi-user VoiceFilter-Lite model suffers from significant performance degradation compared with single-user models. In this paper, we devised a series of experiments to improve the multi-user VoiceFilter-Lite model. By incorporating a dual learning rate schedule and by using feature-wise linear modulation (FiLM) to condition the model with the attended speaker embedding, we successfully closed the performance gap between multi-user and single-user VoiceFilter-Lite models on single-speaker evaluations. At the same time, the new model can also be easily extended to support any number of users, and significantly outperforms our previously published model on multi-speaker evaluations.
CVSS Corpus and Massively Multilingual Speech-to-Speech Translation
Jan 16, 2022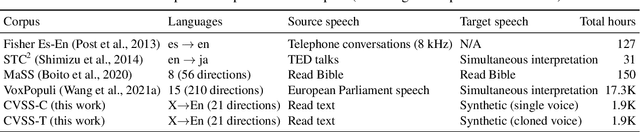
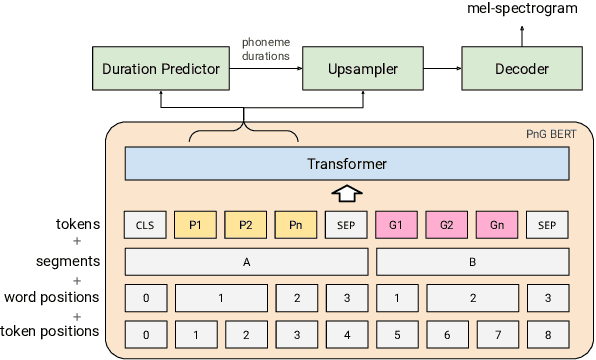
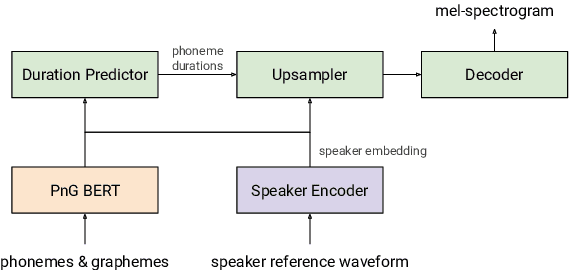
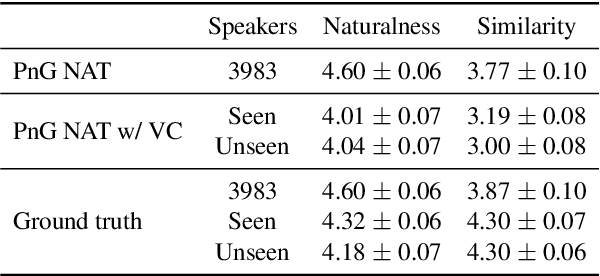
We introduce CVSS, a massively multilingual-to-English speech-to-speech translation (S2ST) corpus, covering sentence-level parallel S2ST pairs from 21 languages into English. CVSS is derived from the Common Voice speech corpus and the CoVoST 2 speech-to-text translation (ST) corpus, by synthesizing the translation text from CoVoST 2 into speech using state-of-the-art TTS systems. Two versions of translation speeches are provided: 1) CVSS-C: All the translation speeches are in a single high-quality canonical voice; 2) CVSS-T: The translation speeches are in voices transferred from the corresponding source speeches. In addition, CVSS provides normalized translation text which matches the pronunciation in the translation speech. On each version of CVSS, we built baseline multilingual direct S2ST models and cascade S2ST models, verifying the effectiveness of the corpus. To build strong cascade S2ST baselines, we trained an ST model on CoVoST 2, which outperforms the previous state-of-the-art trained on the corpus without extra data by 5.8 BLEU. Nevertheless, the performance of the direct S2ST models approaches the strong cascade baselines when trained from scratch, and with only 0.1 or 0.7 BLEU difference on ASR transcribed translation when initialized from matching ST models.