 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2DGH: 2D Gaussian-Hermite Splatting for High-quality Rendering and Better Geometry Reconstruction
Aug 30, 2024



2D Gaussian Splatting has recently emerged as a significant method in 3D reconstruction, enabling novel view synthesis and geometry reconstruction simultaneously. While the well-known Gaussian kernel is broadly used, its lack of anisotropy and deformation ability leads to dim and vague edges at object silhouettes, limiting the reconstruction quality of current Gaussian splatting methods. To enhance the representation power, we draw inspiration from quantum physics and propose to use the Gaussian-Hermite kernel as the new primitive in Gaussian splatting. The new kernel takes a unified mathematical form and extends the Gaussian function, which serves as the zero-rank term in the updated formulation. Our experiments demonstrate the extraordinary performance of Gaussian-Hermite kernel in both geometry reconstruction and novel-view synthesis tasks. The proposed kernel outperforms traditional Gaussian Splatting kernels, showcasing its potential for high-quality 3D reconstruction and rendering.
PRTGaussian: Efficient Relighting Using 3D Gaussians with Precomputed Radiance Transfer
Aug 10, 2024We present PRTGaussian, a realtime relightable novel-view synthesis method made possible by combining 3D Gaussians and Precomputed Radiance Transfer (PRT). By fitting relightable Gaussians to multi-view OLAT data, our method enables real-time, free-viewpoint relighting. By estimating the radiance transfer based on high-order spherical harmonics, we achieve a balance between capturing detailed relighting effects and maintaining computational efficiency. We utilize a two-stage process: in the first stage, we reconstruct a coarse geometry of the object from multi-view images. In the second stage, we initialize 3D Gaussians with the obtained point cloud, then simultaneously refine the coarse geometry and learn the light transport for each Gaussian. Extensive experiments on synthetic datasets show that our approach can achieve fast and high-quality relighting for general objects. Code and data are available at https://github.com/zhanglbthu/PRTGaussian.
NeRF as Non-Distant Environment Emitter in Physics-based Inverse Rendering
Feb 07, 2024



Physics-based inverse rendering aims to jointly optimize shape, materials, and lighting from captured 2D images. Here lighting is an important part of achieving faithful light transport simulation. While the environment map is commonly used as the lighting model in inverse rendering, we show that its distant lighting assumption leads to spatial invariant lighting, which can be an inaccurate approximation in real-world inverse rendering. We propose to use NeRF as a spatially varying environment lighting model and build an inverse rendering pipeline using NeRF as the non-distant environment emitter. By comparing our method with the environment map on real and synthetic datasets, we show that our NeRF-based emitter models the scene lighting more accurately and leads to more accurate inverse rendering. Project page and video: https://nerfemitterpbir.github.io/.
High-Quality Mesh Blendshape Generation from Face Videos via Neural Inverse Rendering
Jan 16, 2024



Readily editable mesh blendshapes have been widely used in animation pipelines, while recent advancements in neural geometry and appearance representations have enabled high-quality inverse rendering. Building upon these observations, we introduce a novel technique that reconstructs mesh-based blendshape rigs from single or sparse multi-view videos, leveraging state-of-the-art neural inverse rendering. We begin by constructing a deformation representation that parameterizes vertex displacements into differential coordinates with tetrahedral connections, allowing for high-quality vertex deformation on high-resolution meshes. By constructing a set of semantic regulations in this representation, we achieve joint optimization of blendshapes and expression coefficients. Furthermore, to enable a user-friendly multi-view setup with unsynchronized cameras, we propose a neural regressor to model time-varying motion parameters. This approach implicitly considers the time difference across multiple cameras, enhancing the accuracy of motion modeling. Experiments demonstrate that, with the flexible input of single or sparse multi-view videos, we reconstruct personalized high-fidelity blendshapes. These blendshapes are both geometrically and semantically accurate, and they are compatible with industrial animation pipelines. Code and data will be released.
ShadowNeuS: Neural SDF Reconstruction by Shadow Ray Supervision
Nov 25, 2022



By supervising camera rays between a scene and multi-view image planes, NeRF reconstructs a neural scene representation for the task of novel view synthesis. On the other hand, shadow rays between the light source and the scene have yet to be considered. Therefore, we propose a novel shadow ray supervision scheme that optimizes both the samples along the ray and the ray location. By supervising shadow rays, we successfully reconstruct a neural SDF of the scene from single-view pure shadow or RGB images under multiple lighting conditions. Given single-view binary shadows, we train a neural network to reconstruct a complete scene not limited by the camera's line of sight. By further modeling the correlation between the image colors and the shadow rays, our technique can also be effectively extended to RGB inputs. We compare our method with previous works on challenging tasks of shape reconstruction from single-view binary shadow or RGB images and observe significant improvements. The code and data will be released.
Structure-aware Editable Morphable Model for 3D Facial Detail Animation and Manipulation
Jul 19, 2022

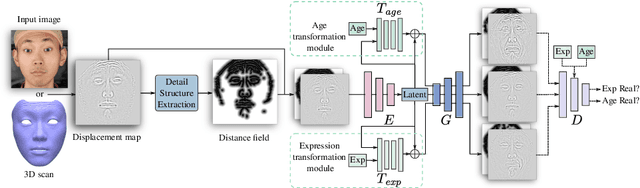
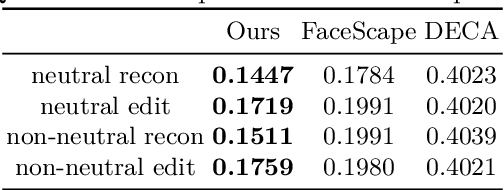
Morphable models are essential for the statistical modeling of 3D faces. Previous works on morphable models mostly focus on large-scale facial geometry but ignore facial details. This paper augments morphable models in representing facial details by learning a Structure-aware Editable Morphable Model (SEMM). SEMM introduces a detail structure representation based on the distance field of wrinkle lines, jointly modeled with detail displacements to establish better correspondences and enable intuitive manipulation of wrinkle structure. Besides, SEMM introduces two transformation modules to translate expression blendshape weights and age values into changes in latent space, allowing effective semantic detail editing while maintaining identity. Extensive experiments demonstrate that the proposed model compactly represents facial details, outperforms previous methods in expression animation qualitatively and quantitatively, and achieves effective age editing and wrinkle line editing of facial details. Code and model are available at https://github.com/gerwang/facial-detail-manipulation.