 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn to Propagate Reliably on Noisy Affinity Graphs
Jul 17, 2020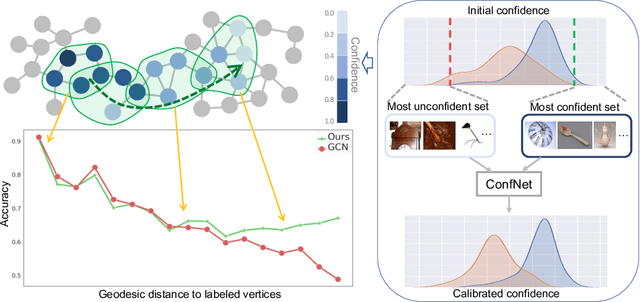
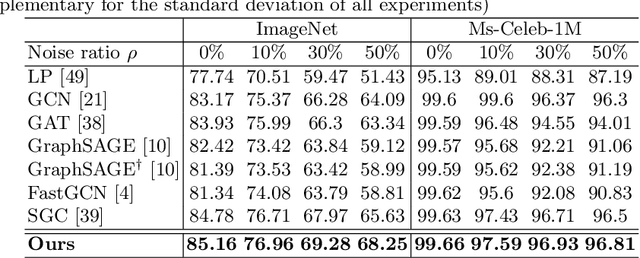
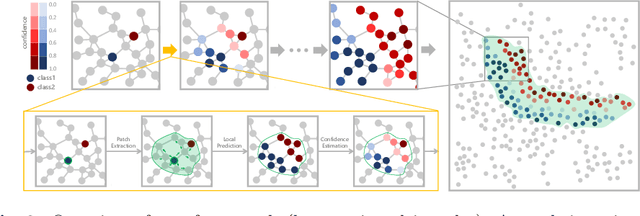
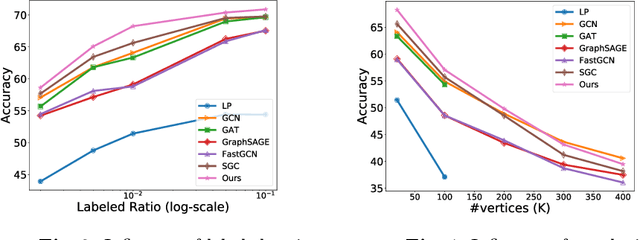
Recent works have shown that exploiting unlabeled data through label propagation can substantially reduce the labeling cost, which has been a critical issue in developing visual recognition models. Yet, how to propagate labels reliably, especially on a dataset with unknown outliers, remains an open question. Conventional methods such as linear diffusion lack the capability of handling complex graph structures and may perform poorly when the seeds are sparse. Latest methods based on graph neural networks would face difficulties on performance drop as they scale out to noisy graphs. To overcome these difficulties, we propose a new framework that allows labels to be propagated reliably on large-scale real-world data. This framework incorporates (1) a local graph neural network to predict accurately on varying local structures while maintaining high scalability, and (2) a confidence-based path scheduler that identifies outliers and moves forward the propagation frontier in a prudent way. Experiments on both ImageNet and Ms-Celeb-1M show that our confidence guided framework can significantly improve the overall accuracies of the propagated labels, especially when the graph is very noisy.
A Local-to-Global Approach to Multi-modal Movie Scene Segmentation
Apr 28, 2020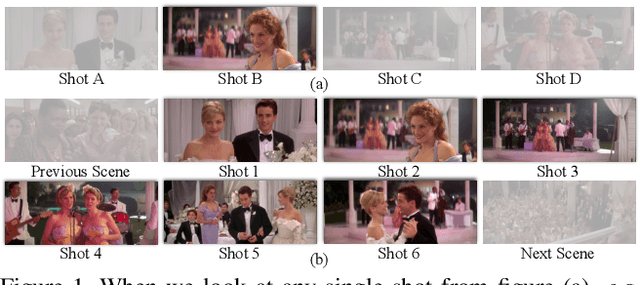


Scene, as the crucial unit of storytelling in movies, contains complex activities of actors and their interactions in a physical environment. Identifying the composition of scenes serves as a critical step towards semantic understanding of movies. This is very challenging -- compared to the videos studied in conventional vision problems, e.g. action recognition, as scenes in movies usually contain much richer temporal structures and more complex semantic information. Towards this goal, we scale up the scene segmentation task by building a large-scale video dataset MovieScenes, which contains 21K annotated scene segments from 150 movies. We further propose a local-to-global scene segmentation framework, which integrates multi-modal information across three levels, i.e. clip, segment, and movie. This framework is able to distill complex semantics from hierarchical temporal structures over a long movie, providing top-down guidance for scene segmentation. Our experiments show that the proposed network is able to segment a movie into scenes with high accuracy, consistently outperforming previous methods. We also found that pretraining on our MovieScenes can bring significant improvements to the existing approaches.
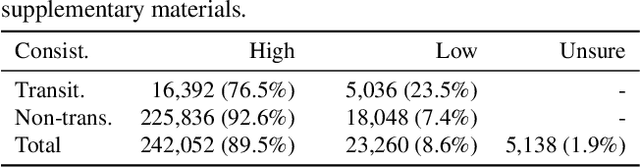
A Graph-Based Framework to Bridge Movies and Synopses
Oct 24, 2019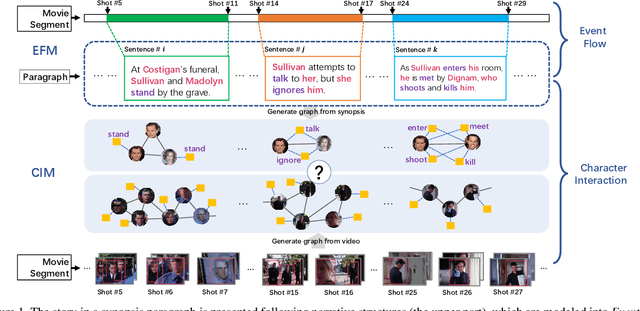
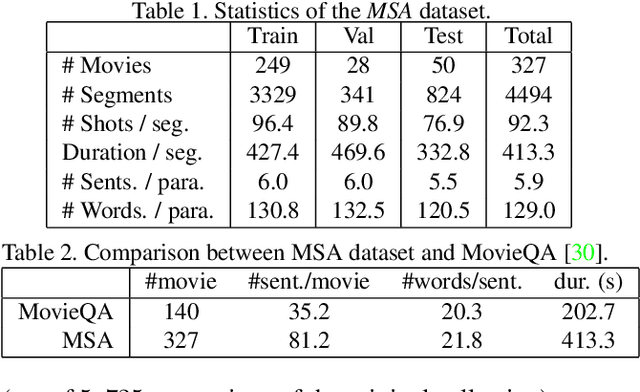

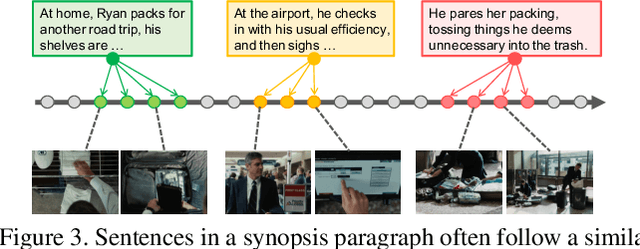
Inspired by the remarkable advances in video analytics, research teams are stepping towards a greater ambition -- movie understanding. However, compared to those activity videos in conventional datasets, movies are significantly different. Generally, movies are much longer and consist of much richer temporal structures. More importantly, the interactions among characters play a central role in expressing the underlying story. To facilitate the efforts along this direction, we construct a dataset called Movie Synopses Associations (MSA) over 327 movies, which provides a synopsis for each movie, together with annotated associations between synopsis paragraphs and movie segments. On top of this dataset, we develop a framework to perform matching between movie segments and synopsis paragraphs. This framework integrates different aspects of a movie, including event dynamics and character interactions, and allows them to be matched with parsed paragraphs, based on a graph-based formulation. Our study shows that the proposed framework remarkably improves the matching accuracy over conventional feature-based methods. It also reveals the importance of narrative structures and character interactions in movie understanding.
WIDER Face and Pedestrian Challenge 2018: Methods and Results
Feb 19, 2019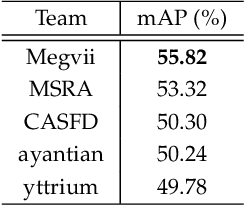

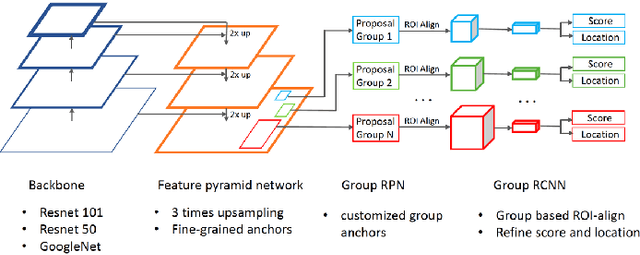
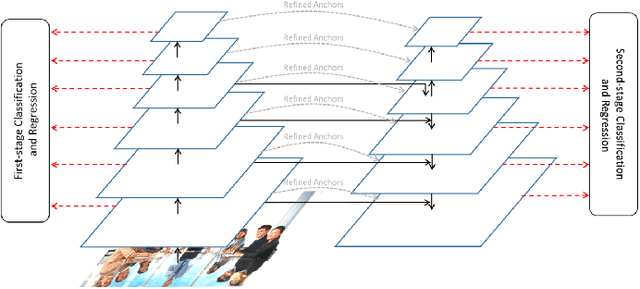
This paper presents a review of the 2018 WIDER Challenge on Face and Pedestrian. The challenge focuses on the problem of precise localization of human faces and bodies, and accurate association of identities. It comprises of three tracks: (i) WIDER Face which aims at soliciting new approaches to advance the state-of-the-art in face detection, (ii) WIDER Pedestrian which aims to find effective and efficient approaches to address the problem of pedestrian detection in unconstrained environments, and (iii) WIDER Person Search which presents an exciting challenge of searching persons across 192 movies. In total, 73 teams made valid submissions to the challenge tracks. We summarize the winning solutions for all three tracks. and present discussions on open problems and potential research directions in these topics.
Person Search in Videos with One Portrait Through Visual and Temporal Links
Jul 27, 2018
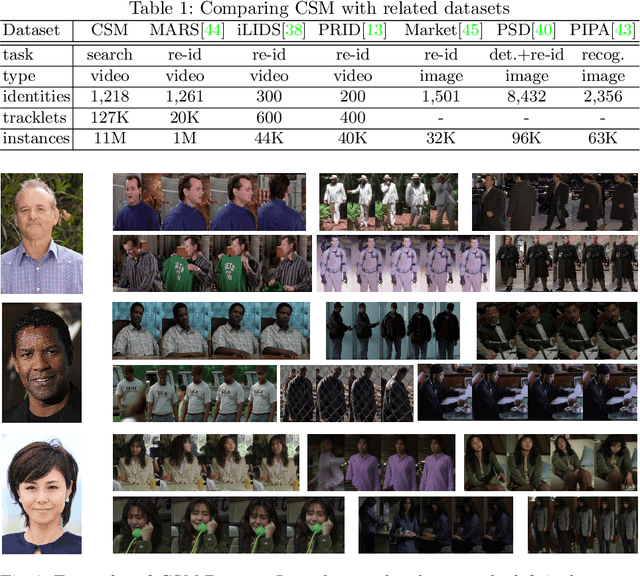
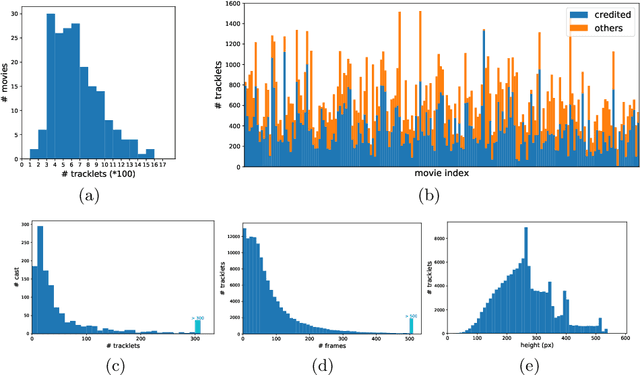
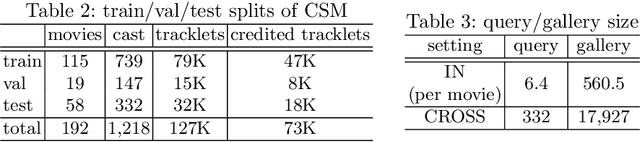
In real-world applications, e.g. law enforcement and video retrieval, one often needs to search a certain person in long videos with just one portrait. This is much more challenging than the conventional settings for person re-identification, as the search may need to be carried out in the environments different from where the portrait was taken. In this paper, we aim to tackle this challenge and propose a novel framework, which takes into account the identity invariance along a tracklet, thus allowing person identities to be propagated via both the visual and the temporal links. We also develop a novel scheme called Progressive Propagation via Competitive Consensus, which significantly improves the reliability of the propagation process. To promote the study of person search, we construct a large-scale benchmark, which contains 127K manually annotated tracklets from 192 movies. Experiments show that our approach remarkably outperforms mainstream person re-id methods, raising the mAP from 42.16% to 62.27%.
From Trailers to Storylines: An Efficient Way to Learn from Movies
Jun 14, 2018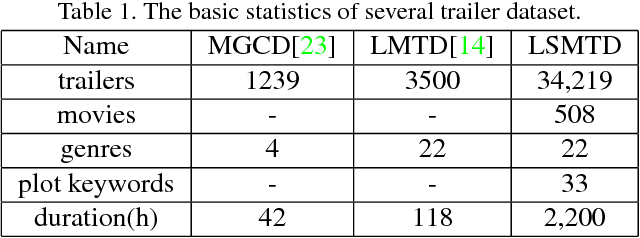

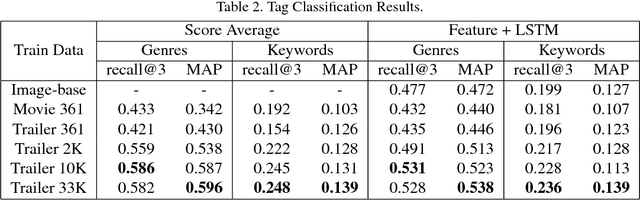
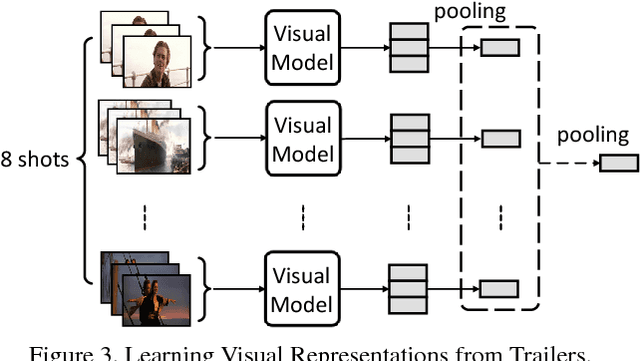
The millions of movies produced in the human history are valuable resources for computer vision research. However, learning a vision model from movie data would meet with serious difficulties. A major obstacle is the computational cost -- the length of a movie is often over one hour, which is substantially longer than the short video clips that previous study mostly focuses on. In this paper, we explore an alternative approach to learning vision models from movies. Specifically, we consider a framework comprised of a visual module and a temporal analysis module. Unlike conventional learning methods, the proposed approach learns these modules from different sets of data -- the former from trailers while the latter from movies. This allows distinctive visual features to be learned within a reasonable budget while still preserving long-term temporal structures across an entire movie. We construct a large-scale dataset for this study and define a series of tasks on top. Experiments on this dataset showed that the proposed method can substantially reduce the training time while obtaining highly effective features and coherent temporal structures.
Unifying Identification and Context Learning for Person Recognition
Jun 08, 2018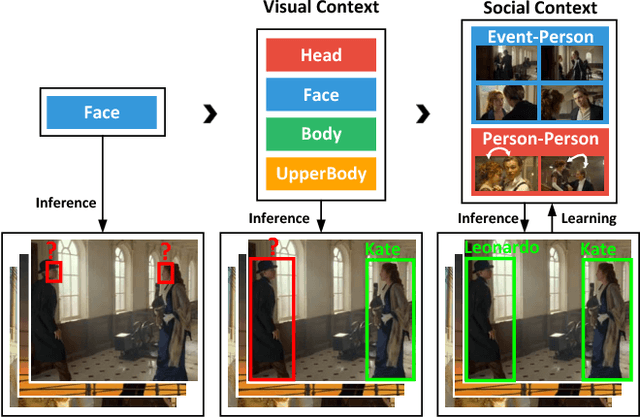
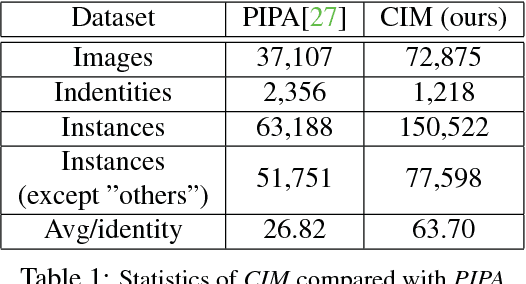
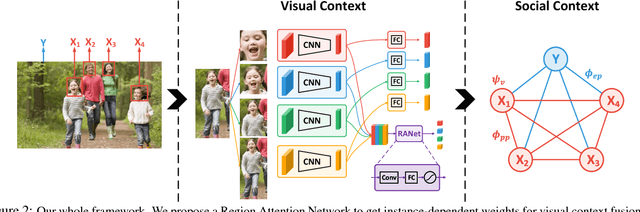

Despite the great success of face recognition techniques, recognizing persons under unconstrained settings remains challenging. Issues like profile views, unfavorable lighting, and occlusions can cause substantial difficulties. Previous works have attempted to tackle this problem by exploiting the context, e.g. clothes and social relations. While showing promising improvement, they are usually limited in two important aspects, relying on simple heuristics to combine different cues and separating the construction of context from people identities. In this work, we aim to move beyond such limitations and propose a new framework to leverage context for person recognition. In particular, we propose a Region Attention Network, which is learned to adaptively combine visual cues with instance-dependent weights. We also develop a unified formulation, where the social contexts are learned along with the reasoning of people identities. These models substantially improve the robustness when working with the complex contextual relations in unconstrained environments. On two large datasets, PIPA and Cast In Movies (CIM), a new dataset proposed in this work, our method consistently achieves state-of-the-art performance under multiple evaluation policies.