 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Low-rank Matching Attention based Cross-modal Feature Fusion Method for Conversational Emotion Recognition
Jun 16, 2023



Conversational emotion recognition (CER) is an important research topic in human-computer interactions. Although deep learning (DL) based CER approaches have achieved excellent performance, existing cross-modal feature fusion methods used in these DL-based approaches either ignore the intra-modal and inter-modal emotional interaction or have high computational complexity. To address these issues, this paper develops a novel cross-modal feature fusion method for the CER task, i.e., the low-rank matching attention method (LMAM). By setting a matching weight and calculating attention scores between modal features row by row, LMAM contains fewer parameters than the self-attention method. We further utilize the low-rank decomposition method on the weight to make the parameter number of LMAM less than one-third of the self-attention. Therefore, LMAM can potentially alleviate the over-fitting issue caused by a large number of parameters. Additionally, by computing and fusing the similarity of intra-modal and inter-modal features, LMAM can also fully exploit the intra-modal contextual information within each modality and the complementary semantic information across modalities (i.e., text, video and audio) simultaneously. Experimental results on some benchmark datasets show that LMAM can be embedded into any existing state-of-the-art DL-based CER methods and help boost their performance in a plug-and-play manner. Also, experimental results verify the superiority of LMAM compared with other popular cross-modal fusion methods. Moreover, LMAM is a general cross-modal fusion method and can thus be applied to other multi-modal recognition tasks, e.g., session recommendation and humour detection.
SFP: Spurious Feature-targeted Pruning for Out-of-Distribution Generalization
May 19, 2023



Model substructure learning aims to find an invariant network substructure that can have better out-of-distribution (OOD) generalization than the original full structure. Existing works usually search the invariant substructure using modular risk minimization (MRM) with fully exposed out-domain data, which may bring about two drawbacks: 1) Unfairness, due to the dependence of the full exposure of out-domain data; and 2) Sub-optimal OOD generalization, due to the equally feature-untargeted pruning on the whole data distribution. Based on the idea that in-distribution (ID) data with spurious features may have a lower experience risk, in this paper, we propose a novel Spurious Feature-targeted model Pruning framework, dubbed SFP, to automatically explore invariant substructures without referring to the above drawbacks. Specifically, SFP identifies spurious features within ID instances during training using our theoretically verified task loss, upon which, SFP attenuates the corresponding feature projections in model space to achieve the so-called spurious feature-targeted pruning. This is typically done by removing network branches with strong dependencies on identified spurious features, thus SFP can push the model learning toward invariant features and pull that out of spurious features and devise optimal OOD generalization. Moreover, we also conduct detailed theoretical analysis to provide the rationality guarantee and a proof framework for OOD structures via model sparsity, and for the first time, reveal how a highly biased data distribution affects the model's OOD generalization. Experiments on various OOD datasets show that SFP can significantly outperform both structure-based and non-structure-based OOD generalization SOTAs, with accuracy improvement up to 4.72% and 23.35%, respectively
Detecting Spoilers in Movie Reviews with External Movie Knowledge and User Networks
Apr 22, 2023



Online movie review platforms are providing crowdsourced feedback for the film industry and the general public, while spoiler reviews greatly compromise user experience. Although preliminary research efforts were made to automatically identify spoilers, they merely focus on the review content itself, while robust spoiler detection requires putting the review into the context of facts and knowledge regarding movies, user behavior on film review platforms, and more. In light of these challenges, we first curate a large-scale network-based spoiler detection dataset LCS and a comprehensive and up-to-date movie knowledge base UKM. We then propose MVSD, a novel Multi-View Spoiler Detection framework that takes into account the external knowledge about movies and user activities on movie review platforms. Specifically, MVSD constructs three interconnecting heterogeneous information networks to model diverse data sources and their multi-view attributes, while we design and employ a novel heterogeneous graph neural network architecture for spoiler detection as node-level classification. Extensive experiments demonstrate that MVSD advances the state-of-the-art on two spoiler detection datasets, while the introduction of external knowledge and user interactions help ground robust spoiler detection. Our data and code are available at https://github.com/Arthur-Heng/Spoiler-Detection
Noisy Correspondence Learning with Meta Similarity Correction
Apr 13, 2023



Despite the success of multimodal learning in cross-modal retrieval task, the remarkable progress relies on the correct correspondence among multimedia data. However, collecting such ideal data is expensive and time-consuming. In practice, most widely used datasets are harvested from the Internet and inevitably contain mismatched pairs. Training on such noisy correspondence datasets causes performance degradation because the cross-modal retrieval methods can wrongly enforce the mismatched data to be similar. To tackle this problem, we propose a Meta Similarity Correction Network (MSCN) to provide reliable similarity scores. We view a binary classification task as the meta-process that encourages the MSCN to learn discrimination from positive and negative meta-data. To further alleviate the influence of noise, we design an effective data purification strategy using meta-data as prior knowledge to remove the noisy samples. Extensive experiments are conducted to demonstrate the strengths of our method in both synthetic and real-world noises, including Flickr30K, MS-COCO, and Conceptual Captions.
Disentangled Generation with Information Bottleneck for Few-Shot Learning
Nov 29, 2022



Few-shot learning (FSL), which aims to classify unseen classes with few samples, is challenging due to data scarcity. Although various generative methods have been explored for FSL, the entangled generation process of these methods exacerbates the distribution shift in FSL, thus greatly limiting the quality of generated samples. To these challenges, we propose a novel Information Bottleneck (IB) based Disentangled Generation Framework for FSL, termed as DisGenIB, that can simultaneously guarantee the discrimination and diversity of generated samples. Specifically, we formulate a novel framework with information bottleneck that applies for both disentangled representation learning and sample generation. Different from existing IB-based methods that can hardly exploit priors, we demonstrate our DisGenIB can effectively utilize priors to further facilitate disentanglement. We further prove in theory that some previous generative and disentanglement methods are special cases of our DisGenIB, which demonstrates the generality of the proposed DisGenIB. Extensive experiments on challenging FSL benchmarks confirm the effectiveness and superiority of DisGenIB, together with the validity of our theoretical analyses. Our codes will be open-source upon acceptance.
Generalized Category Discovery with Decoupled Prototypical Network
Nov 28, 2022Generalized Category Discovery (GCD) aims to recognize both known and novel categories from a set of unlabeled data, based on another dataset labeled with only known categories. Without considering differences between known and novel categories, current methods learn about them in a coupled manner, which can hurt model's generalization and discriminative ability. Furthermore, the coupled training approach prevents these models transferring category-specific knowledge explicitly from labeled data to unlabeled data, which can lose high-level semantic information and impair model performance. To mitigate above limitations, we present a novel model called Decoupled Prototypical Network (DPN). By formulating a bipartite matching problem for category prototypes, DPN can not only decouple known and novel categories to achieve different training targets effectively, but also align known categories in labeled and unlabeled data to transfer category-specific knowledge explicitly and capture high-level semantics. Furthermore, DPN can learn more discriminative features for both known and novel categories through our proposed Semantic-aware Prototypical Learning (SPL). Besides capturing meaningful semantic information, SPL can also alleviate the noise of hard pseudo labels through semantic-weighted soft assignment. Extensive experiments show that DPN outperforms state-of-the-art models by a large margin on all evaluation metrics across multiple benchmark datasets. Code and data are available at https://github.com/Lackel/DPN.
Power Efficient Video Super-Resolution on Mobile NPUs with Deep Learning, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022



Video super-resolution is one of the most popular tasks on mobile devices, being widely used for an automatic improvement of low-bitrate and low-resolution video streams. While numerous solutions have been proposed for this problem, they are usually quite computationally demanding, demonstrating low FPS rates and power efficiency on mobile devices. In this Mobile AI challenge, we address this problem and propose the participants to design an end-to-end real-time video super-resolution solution for mobile NPUs optimized for low energy consumption. The participants were provided with the REDS training dataset containing video sequences for a 4X video upscaling task. The runtime and power efficiency of all models was evaluated on the powerful MediaTek Dimensity 9000 platform with a dedicated AI processing unit capable of accelerating floating-point and quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 500 FPS rate and 0.2 [Watt / 30 FPS] power consumption. A detailed description of all models developed in the challenge is provided in this paper.
PAR: Political Actor Representation Learning with Social Context and Expert Knowledge
Oct 15, 2022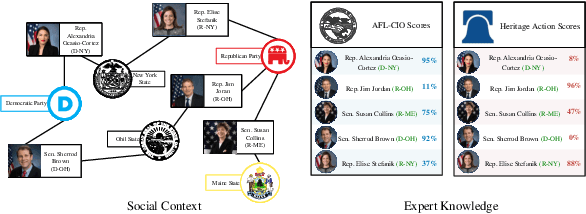
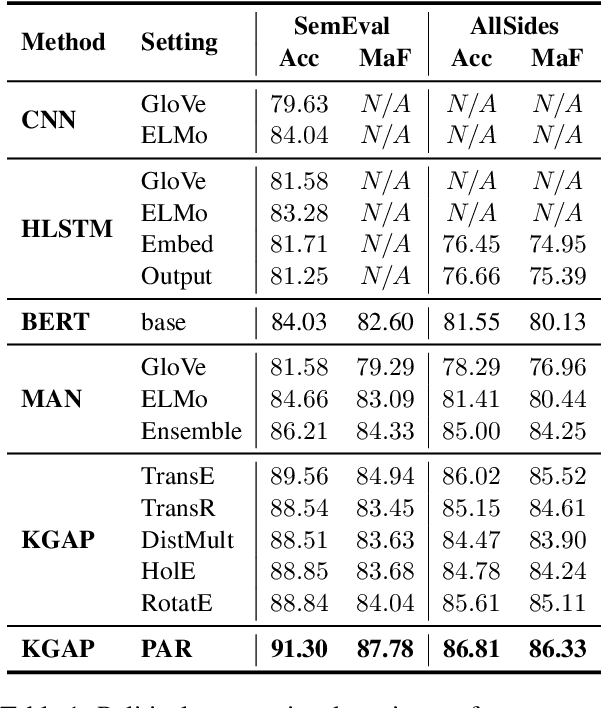
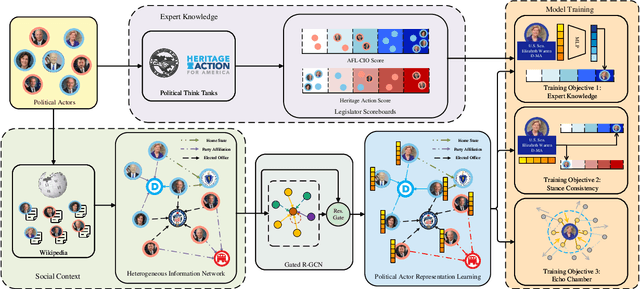
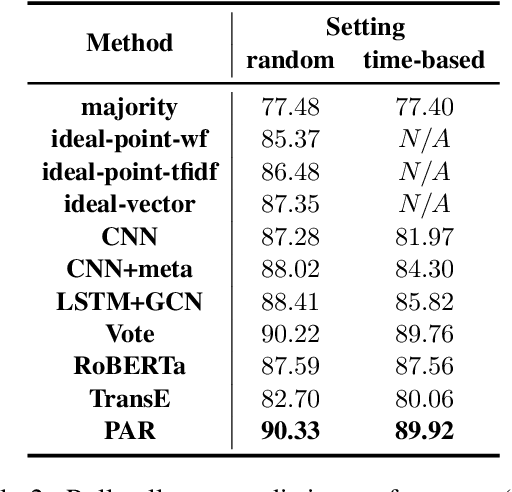
Modeling the ideological perspectives of political actors is an essential task in computational political science with applications in many downstream tasks. Existing approaches are generally limited to textual data and voting records, while they neglect the rich social context and valuable expert knowledge for holistic ideological analysis. In this paper, we propose \textbf{PAR}, a \textbf{P}olitical \textbf{A}ctor \textbf{R}epresentation learning framework that jointly leverages social context and expert knowledge. Specifically, we retrieve and extract factual statements about legislators to leverage social context information. We then construct a heterogeneous information network to incorporate social context and use relational graph neural networks to learn legislator representations. Finally, we train PAR with three objectives to align representation learning with expert knowledge, model ideological stance consistency, and simulate the echo chamber phenomenon. Extensive experiments demonstrate that PAR is better at augmenting political text understanding and successfully advances the state-of-the-art in political perspective detection and roll call vote prediction. Further analysis proves that PAR learns representations that reflect the political reality and provide new insights into political behavior.
Fine-grained Category Discovery under Coarse-grained supervision with Hierarchical Weighted Self-contrastive Learning
Oct 14, 2022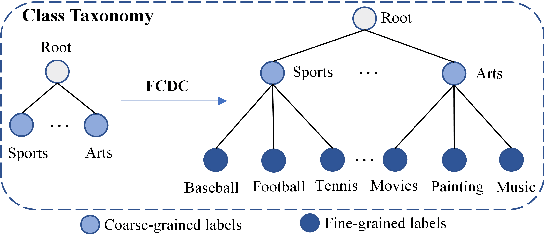
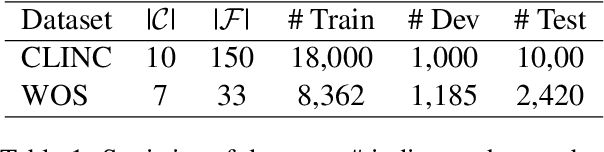
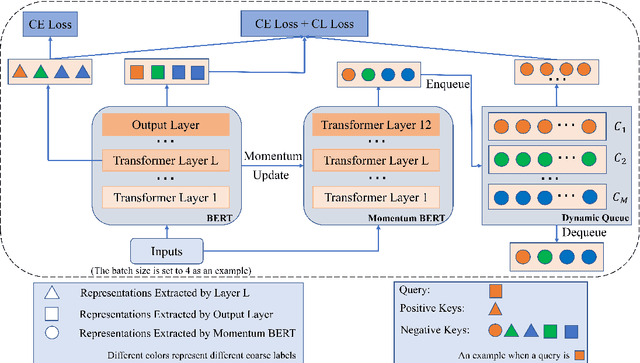
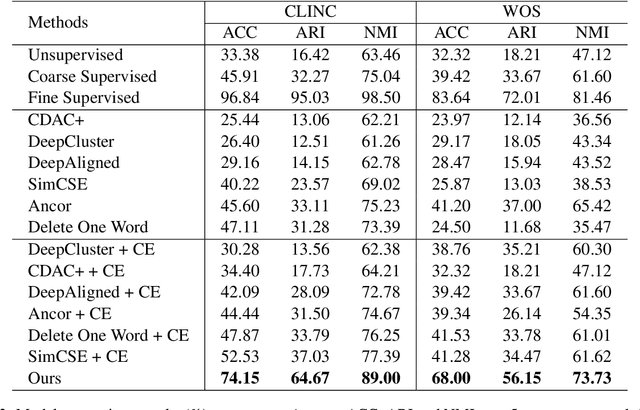
Novel category discovery aims at adapting models trained on known categories to novel categories. Previous works only focus on the scenario where known and novel categories are of the same granularity. In this paper, we investigate a new practical scenario called Fine-grained Category Discovery under Coarse-grained supervision (FCDC). FCDC aims at discovering fine-grained categories with only coarse-grained labeled data, which can adapt models to categories of different granularity from known ones and reduce significant labeling cost. It is also a challenging task since supervised training on coarse-grained categories tends to focus on inter-class distance (distance between coarse-grained classes) but ignore intra-class distance (distance between fine-grained sub-classes) which is essential for separating fine-grained categories. Considering most current methods cannot transfer knowledge from coarse-grained level to fine-grained level, we propose a hierarchical weighted self-contrastive network by building a novel weighted self-contrastive module and combining it with supervised learning in a hierarchical manner. Extensive experiments on public datasets show both effectiveness and efficiency of our model over compared methods. Code and data are available at https://github.com/Lackel/Hierarchical_Weighted_SCL.
GraTO: Graph Neural Network Framework Tackling Over-smoothing with Neural Architecture Search
Aug 18, 2022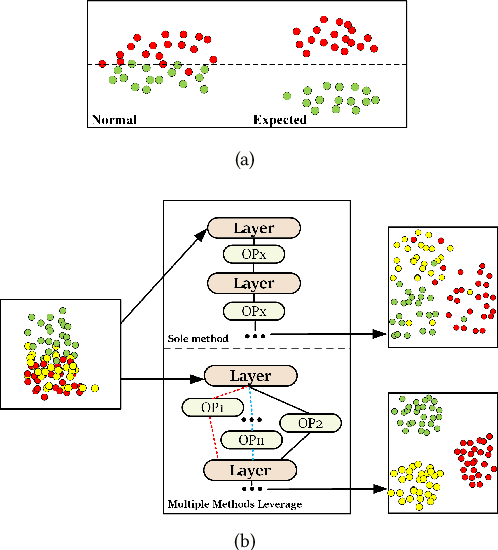

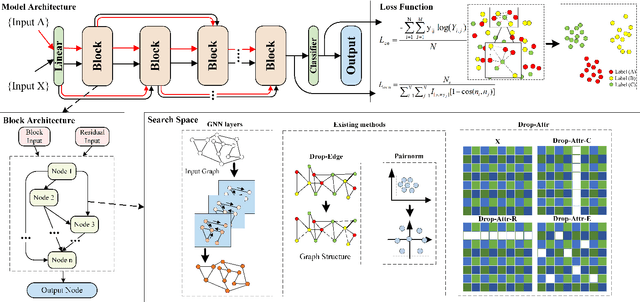

Current Graph Neural Networks (GNNs) suffer from the over-smoothing problem, which results in indistinguishable node representations and low model performance with more GNN layers. Many methods have been put forward to tackle this problem in recent years. However, existing tackling over-smoothing methods emphasize model performance and neglect the over-smoothness of node representations. Additional, different approaches are applied one at a time, while there lacks an overall framework to jointly leverage multiple solutions to the over-smoothing challenge. To solve these problems, we propose GraTO, a framework based on neural architecture search to automatically search for GNNs architecture. GraTO adopts a novel loss function to facilitate striking a balance between model performance and representation smoothness. In addition to existing methods, our search space also includes DropAttribute, a novel scheme for alleviating the over-smoothing challenge, to fully leverage diverse solutions. We conduct extensive experiments on six real-world datasets to evaluate GraTo, which demonstrates that GraTo outperforms baselines in the over-smoothing metrics and achieves competitive performance in accuracy. GraTO is especially effective and robust with increasing numbers of GNN layers. Further experiments bear out the quality of node representations learned with GraTO and the effectiveness of model architecture. We make cide of GraTo available at Github (\url{https://github.com/fxsxjtu/GraTO}).