 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Segment Anything Model 3 for Concept-Driven Lesion Segmentation in Medical Images: An Experimental Study
Mar 26, 2026Accurate lesion segmentation is essential in medical image analysis, yet most existing methods are designed for specific anatomical sites or imaging modalities, limiting their generalizability. Recent vision-language foundation models enable concept-driven segmentation in natural images, offering a promising direction for more flexible medical image analysis. However, concept-prompt-based lesion segmentation, particularly with the latest Segment Anything Model 3 (SAM3), remains underexplored. In this work, we present a systematic evaluation of SAM3 for lesion segmentation. We assess its performance using geometric bounding boxes and concept-based text and image prompts across multiple modalities, including multiparametric MRI, CT, ultrasound, dermoscopy, and endoscopy. To improve robustness, we incorporate additional prior knowledge, such as adjacent-slice predictions, multiparametric information, and prior annotations. We further compare different fine-tuning strategies, including partial module tuning, adapter-based methods, and full-model optimization. Experiments on 13 datasets covering 11 lesion types demonstrate that SAM3 achieves strong cross-modality generalization, reliable concept-driven segmentation, and accurate lesion delineation. These results highlight the potential of concept-based foundation models for scalable and practical medical image segmentation. Code and trained models will be released at: https://github.com/apple1986/lesion-sam3
Exploiting DINOv3-Based Self-Supervised Features for Robust Few-Shot Medical Image Segmentation
Jan 12, 2026Deep learning-based automatic medical image segmentation plays a critical role in clinical diagnosis and treatment planning but remains challenging in few-shot scenarios due to the scarcity of annotated training data. Recently, self-supervised foundation models such as DINOv3, which were trained on large natural image datasets, have shown strong potential for dense feature extraction that can help with the few-shot learning challenge. Yet, their direct application to medical images is hindered by domain differences. In this work, we propose DINO-AugSeg, a novel framework that leverages DINOv3 features to address the few-shot medical image segmentation challenge. Specifically, we introduce WT-Aug, a wavelet-based feature-level augmentation module that enriches the diversity of DINOv3-extracted features by perturbing frequency components, and CG-Fuse, a contextual information-guided fusion module that exploits cross-attention to integrate semantic-rich low-resolution features with spatially detailed high-resolution features. Extensive experiments on six public benchmarks spanning five imaging modalities, including MRI, CT, ultrasound, endoscopy, and dermoscopy, demonstrate that DINO-AugSeg consistently outperforms existing methods under limited-sample conditions. The results highlight the effectiveness of incorporating wavelet-domain augmentation and contextual fusion for robust feature representation, suggesting DINO-AugSeg as a promising direction for advancing few-shot medical image segmentation. Code and data will be made available on https://github.com/apple1986/DINO-AugSeg.
Segment Anything for Video: A Comprehensive Review of Video Object Segmentation and Tracking from Past to Future
Jul 30, 2025



Video Object Segmentation and Tracking (VOST) presents a complex yet critical challenge in computer vision, requiring robust integration of segmentation and tracking across temporally dynamic frames. Traditional methods have struggled with domain generalization, temporal consistency, and computational efficiency. The emergence of foundation models like the Segment Anything Model (SAM) and its successor, SAM2, has introduced a paradigm shift, enabling prompt-driven segmentation with strong generalization capabilities. Building upon these advances, this survey provides a comprehensive review of SAM/SAM2-based methods for VOST, structured along three temporal dimensions: past, present, and future. We examine strategies for retaining and updating historical information (past), approaches for extracting and optimizing discriminative features from the current frame (present), and motion prediction and trajectory estimation mechanisms for anticipating object dynamics in subsequent frames (future). In doing so, we highlight the evolution from early memory-based architectures to the streaming memory and real-time segmentation capabilities of SAM2. We also discuss recent innovations such as motion-aware memory selection and trajectory-guided prompting, which aim to enhance both accuracy and efficiency. Finally, we identify remaining challenges including memory redundancy, error accumulation, and prompt inefficiency, and suggest promising directions for future research. This survey offers a timely and structured overview of the field, aiming to guide researchers and practitioners in advancing the state of VOST through the lens of foundation models.
A SAM-guided and Match-based Semi-Supervised Segmentation Framework for Medical Imaging
Nov 25, 2024



This study introduces SAMatch, a SAM-guided Match-based framework for semi-supervised medical image segmentation, aimed at improving pseudo label quality in data-scarce scenarios. While Match-based frameworks are effective, they struggle with low-quality pseudo labels due to the absence of ground truth. SAM, pre-trained on a large dataset, generalizes well across diverse tasks and assists in generating high-confidence prompts, which are then used to refine pseudo labels via fine-tuned SAM. SAMatch is trained end-to-end, allowing for dynamic interaction between the models. Experiments on the ACDC cardiac MRI, BUSI breast ultrasound, and MRLiver datasets show SAMatch achieving state-of-the-art results, with Dice scores of 89.36%, 77.76%, and 80.04%, respectively, using minimal labeled data. SAMatch effectively addresses challenges in semi-supervised segmentation, offering a powerful tool for segmentation in data-limited environments. Code and data are available at https://github.com/apple1986/SAMatch.
DBF-Net: A Dual-Branch Network with Feature Fusion for Ultrasound Image Segmentation
Nov 17, 2024Accurately segmenting lesions in ultrasound images is challenging due to the difficulty in distinguishing boundaries between lesions and surrounding tissues. While deep learning has improved segmentation accuracy, there is limited focus on boundary quality and its relationship with body structures. To address this, we introduce UBBS-Net, a dual-branch deep neural network that learns the relationship between body and boundary for improved segmentation. We also propose a feature fusion module to integrate body and boundary information. Evaluated on three public datasets, UBBS-Net outperforms existing methods, achieving Dice Similarity Coefficients of 81.05% for breast cancer, 76.41% for brachial plexus nerves, and 87.75% for infantile hemangioma segmentation. Our results demonstrate the effectiveness of UBBS-Net for ultrasound image segmentation. The code is available at https://github.com/apple1986/DBF-Net.
Noise Adaption Network for Morse Code Image Classification
Oct 24, 2024The escalating significance of information security has underscored the per-vasive role of encryption technology in safeguarding communication con-tent. Morse code, a well-established and effective encryption method, has found widespread application in telegraph communication and various do-mains. However, the transmission of Morse code images faces challenges due to diverse noises and distortions, thereby hindering comprehensive clas-sification outcomes. Existing methodologies predominantly concentrate on categorizing Morse code images affected by a single type of noise, neglecting the multitude of scenarios that noise pollution can generate. To overcome this limitation, we propose a novel two-stage approach, termed the Noise Adaptation Network (NANet), for Morse code image classification. Our method involves exclusive training on pristine images while adapting to noisy ones through the extraction of critical information unaffected by noise. In the initial stage, we introduce a U-shaped network structure designed to learn representative features and denoise images. Subsequently, the second stage employs a deep convolutional neural network for classification. By leveraging the denoising module from the first stage, our approach achieves enhanced accuracy and robustness in the subsequent classification phase. We conducted an evaluation of our approach on a diverse dataset, encom-passing Gaussian, salt-and-pepper, and uniform noise variations. The results convincingly demonstrate the superiority of our methodology over existing approaches. The datasets are available on https://github.com/apple1986/MorseCodeImageClassify
Development of Skip Connection in Deep Neural Networks for Computer Vision and Medical Image Analysis: A Survey
May 02, 2024



Deep learning has made significant progress in computer vision, specifically in image classification, object detection, and semantic segmentation. The skip connection has played an essential role in the architecture of deep neural networks,enabling easier optimization through residual learning during the training stage and improving accuracy during testing. Many neural networks have inherited the idea of residual learning with skip connections for various tasks, and it has been the standard choice for designing neural networks. This survey provides a comprehensive summary and outlook on the development of skip connections in deep neural networks. The short history of skip connections is outlined, and the development of residual learning in deep neural networks is surveyed. The effectiveness of skip connections in the training and testing stages is summarized, and future directions for using skip connections in residual learning are discussed. Finally, we summarize seminal papers, source code, models, and datasets that utilize skip connections in computer vision, including image classification, object detection, semantic segmentation, and image reconstruction. We hope this survey could inspire peer researchers in the community to develop further skip connections in various forms and tasks and the theory of residual learning in deep neural networks. The project page can be found at https://github.com/apple1986/Residual_Learning_For_Images
LeViT-UNet: Make Faster Encoders with Transformer for Medical Image Segmentation
Jul 19, 2021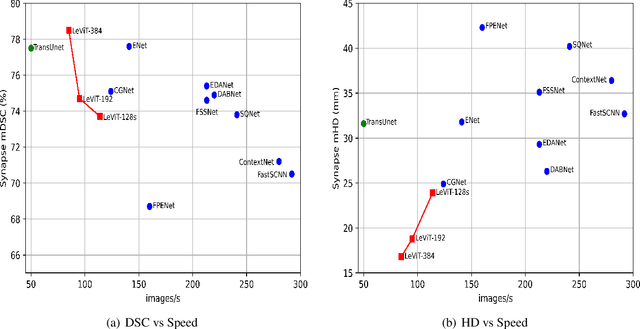
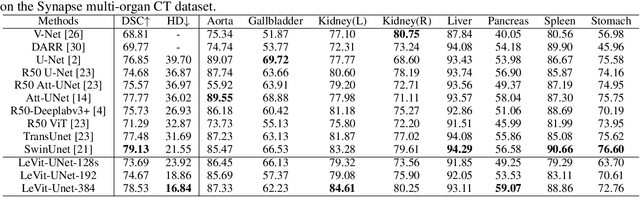
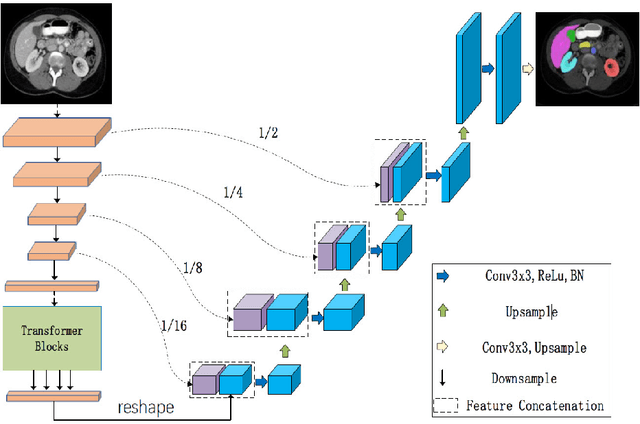
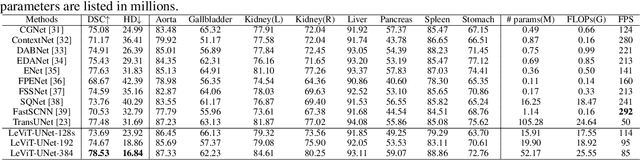
Medical image segmentation plays an essential role in developing computer-assisted diagnosis and therapy systems, yet still faces many challenges. In the past few years, the popular encoder-decoder architectures based on CNNs (e.g., U-Net) have been successfully applied in the task of medical image segmentation. However, due to the locality of convolution operations, they demonstrate limitations in learning global context and long-range spatial relations. Recently, several researchers try to introduce transformers to both the encoder and decoder components with promising results, but the efficiency requires further improvement due to the high computational complexity of transformers. In this paper, we propose LeViT-UNet, which integrates a LeViT Transformer module into the U-Net architecture, for fast and accurate medical image segmentation. Specifically, we use LeViT as the encoder of the LeViT-UNet, which better trades off the accuracy and efficiency of the Transformer block. Moreover, multi-scale feature maps from transformer blocks and convolutional blocks of LeViT are passed into the decoder via skip-connection, which can effectively reuse the spatial information of the feature maps. Our experiments indicate that the proposed LeViT-UNet achieves better performance comparing to various competing methods on several challenging medical image segmentation benchmarks including Synapse and ACDC. Code and models will be publicly available at https://github.com/apple1986/LeViT_UNet.