 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Tensor-Aided Channel Estimation for Hardware Impaired Device Identification
Mar 13, 2025In this paper, we investigate the joint generalized channel estimation and device identification problem in Internet of Things (IoT) networks {under multipath propagation}. To fully utilize the received signal, we decompose the generalized channel into three components: transmitter hardware characteristics, path gains, and angles of arrival. By modelling the received signals as parallel factor (PARAFAC) tensors, we develop alternating least squares (ALS)-based algorithms to simultaneously estimate the generalized channels and identify the transmitters. Simulation results show that the proposed scheme outperforms {both Khatri-Rao Factorization (KRF) and the conventional least squares (LS) method} in terms of channel estimation accuracy and achieves performance close to the derived Cramer-Rao lower bound.
Certainly Bot Or Not? Trustworthy Social Bot Detection via Robust Multi-Modal Neural Processes
Mar 11, 2025



Social bot detection is crucial for mitigating misinformation, online manipulation, and coordinated inauthentic behavior. While existing neural network-based detectors perform well on benchmarks, they struggle with generalization due to distribution shifts across datasets and frequently produce overconfident predictions for out-of-distribution accounts beyond the training data. To address this, we introduce a novel Uncertainty Estimation for Social Bot Detection (UESBD) framework, which quantifies the predictive uncertainty of detectors beyond mere classification. For this task, we propose Robust Multi-modal Neural Processes (RMNP), which aims to enhance the robustness of multi-modal neural processes to modality inconsistencies caused by social bot camouflage. RMNP first learns unimodal representations through modality-specific encoders. Then, unimodal attentive neural processes are employed to encode the Gaussian distribution of unimodal latent variables. Furthermore, to avoid social bots stealing human features to camouflage themselves thus causing certain modalities to provide conflictive information, we introduce an evidential gating network to explicitly model the reliability of modalities. The joint latent distribution is learned through the generalized product of experts, which takes the reliability of each modality into consideration during fusion. The final prediction is obtained through Monte Carlo sampling of the joint latent distribution followed by a decoder. Experiments on three real-world benchmarks show the effectiveness of RMNP in classification and uncertainty estimation, as well as its robustness to modality conflicts.
Dynamic Path Navigation for Motion Agents with LLM Reasoning
Mar 10, 2025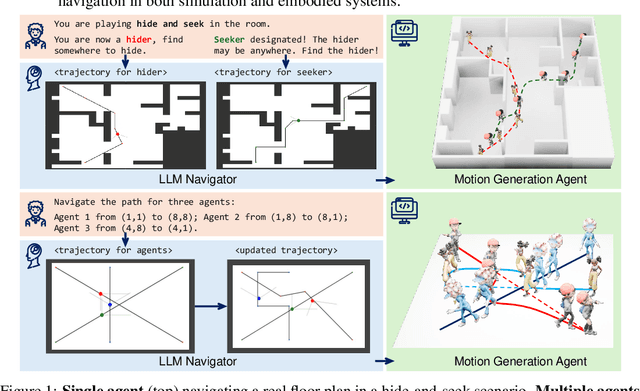
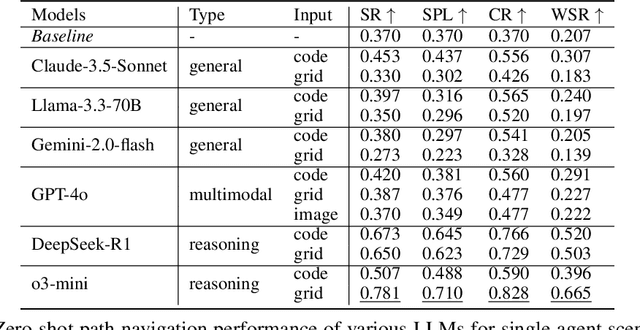
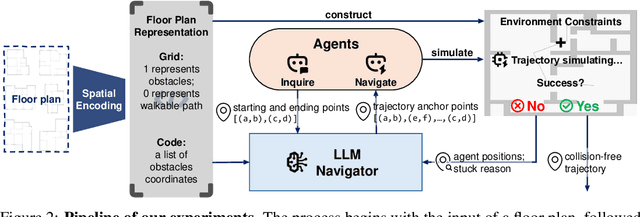
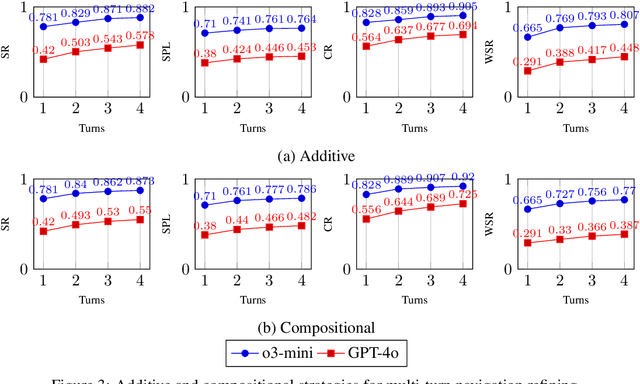
Large Language Models (LLMs) have demonstrated strong generalizable reasoning and planning capabilities. However, their efficacies in spatial path planning and obstacle-free trajectory generation remain underexplored. Leveraging LLMs for navigation holds significant potential, given LLMs' ability to handle unseen scenarios, support user-agent interactions, and provide global control across complex systems, making them well-suited for agentic planning and humanoid motion generation. As one of the first studies in this domain, we explore the zero-shot navigation and path generation capabilities of LLMs by constructing a dataset and proposing an evaluation protocol. Specifically, we represent paths using anchor points connected by straight lines, enabling movement in various directions. This approach offers greater flexibility and practicality compared to previous methods while remaining simple and intuitive for LLMs. We demonstrate that, when tasks are well-structured in this manner, modern LLMs exhibit substantial planning proficiency in avoiding obstacles while autonomously refining navigation with the generated motion to reach the target. Further, this spatial reasoning ability of a single LLM motion agent interacting in a static environment can be seamlessly generalized in multi-motion agents coordination in dynamic environments. Unlike traditional approaches that rely on single-step planning or local policies, our training-free LLM-based method enables global, dynamic, closed-loop planning, and autonomously resolving collision issues.
MADS: Multi-Attribute Document Supervision for Zero-Shot Image Classification
Mar 10, 2025Zero-shot learning (ZSL) aims to train a model on seen classes and recognize unseen classes by knowledge transfer through shared auxiliary information. Recent studies reveal that documents from encyclopedias provide helpful auxiliary information. However, existing methods align noisy documents, entangled in visual and non-visual descriptions, with image regions, yet solely depend on implicit learning. These models fail to filter non-visual noise reliably and incorrectly align non-visual words to image regions, which is harmful to knowledge transfer. In this work, we propose a novel multi-attribute document supervision framework to remove noises at both document collection and model learning stages. With the help of large language models, we introduce a novel prompt algorithm that automatically removes non-visual descriptions and enriches less-described documents in multiple attribute views. Our proposed model, MADS, extracts multi-view transferable knowledge with information decoupling and semantic interactions for semantic alignment at local and global levels. Besides, we introduce a model-agnostic focus loss to explicitly enhance attention to visually discriminative information during training, also improving existing methods without additional parameters. With comparable computation costs, MADS consistently outperforms the SOTA by 7.2% and 8.2% on average in three benchmarks for document-based ZSL and GZSL settings, respectively. Moreover, we qualitatively offer interpretable predictions from multiple attribute views.
REArtGS: Reconstructing and Generating Articulated Objects via 3D Gaussian Splatting with Geometric and Motion Constraints
Mar 09, 2025Articulated objects, as prevalent entities in human life, their 3D representations play crucial roles across various applications. However, achieving both high-fidelity textured surface reconstruction and dynamic generation for articulated objects remains challenging for existing methods. In this paper, we present REArtGS, a novel framework that introduces additional geometric and motion constraints to 3D Gaussian primitives, enabling high-quality textured surface reconstruction and generation for articulated objects. Specifically, given multi-view RGB images of arbitrary two states of articulated objects, we first introduce an unbiased Signed Distance Field (SDF) guidance to regularize Gaussian opacity fields, enhancing geometry constraints and improving surface reconstruction quality. Then we establish deformable fields for 3D Gaussians constrained by the kinematic structures of articulated objects, achieving unsupervised generation of surface meshes in unseen states. Extensive experiments on both synthetic and real datasets demonstrate our approach achieves high-quality textured surface reconstruction for given states, and enables high-fidelity surface generation for unseen states. Codes will be released within the next four months.
mmDEAR: mmWave Point Cloud Density Enhancement for Accurate Human Body Reconstruction
Mar 04, 2025



Millimeter-wave (mmWave) radar offers robust sensing capabilities in diverse environments, making it a highly promising solution for human body reconstruction due to its privacy-friendly and non-intrusive nature. However, the significant sparsity of mmWave point clouds limits the estimation accuracy. To overcome this challenge, we propose a two-stage deep learning framework that enhances mmWave point clouds and improves human body reconstruction accuracy. Our method includes a mmWave point cloud enhancement module that densifies the raw data by leveraging temporal features and a multi-stage completion network, followed by a 2D-3D fusion module that extracts both 2D and 3D motion features to refine SMPL parameters. The mmWave point cloud enhancement module learns the detailed shape and posture information from 2D human masks in single-view images. However, image-based supervision is involved only during the training phase, and the inference relies solely on sparse point clouds to maintain privacy. Experiments on multiple datasets demonstrate that our approach outperforms state-of-the-art methods, with the enhanced point clouds further improving performance when integrated into existing models.
Are Large Vision Language Models Good Game Players?
Mar 04, 2025Large Vision Language Models (LVLMs) have demonstrated remarkable abilities in understanding and reasoning about both visual and textual information. However, existing evaluation methods for LVLMs, primarily based on benchmarks like Visual Question Answering and image captioning, often fail to capture the full scope of LVLMs' capabilities. These benchmarks are limited by issues such as inadequate assessment of detailed visual perception, data contamination, and a lack of focus on multi-turn reasoning. To address these challenges, we propose \method{}, a game-based evaluation framework designed to provide a comprehensive assessment of LVLMs' cognitive and reasoning skills in structured environments. \method{} uses a set of games to evaluate LVLMs on four core tasks: Perceiving, Question Answering, Rule Following, and End-to-End Playing, with each target task designed to assess specific abilities, including visual perception, reasoning, decision-making, etc. Based on this framework, we conduct extensive experiments that explore the limitations of current LVLMs, such as handling long structured outputs and perceiving detailed and dense elements. Code and data are publicly available at https://github.com/xinke-wang/LVLM-Playground.
Ground-level Viewpoint Vision-and-Language Navigation in Continuous Environments
Feb 26, 2025



Vision-and-Language Navigation (VLN) empowers agents to associate time-sequenced visual observations with corresponding instructions to make sequential decisions. However, generalization remains a persistent challenge, particularly when dealing with visually diverse scenes or transitioning from simulated environments to real-world deployment. In this paper, we address the mismatch between human-centric instructions and quadruped robots with a low-height field of view, proposing a Ground-level Viewpoint Navigation (GVNav) approach to mitigate this issue. This work represents the first attempt to highlight the generalization gap in VLN across varying heights of visual observation in realistic robot deployments. Our approach leverages weighted historical observations as enriched spatiotemporal contexts for instruction following, effectively managing feature collisions within cells by assigning appropriate weights to identical features across different viewpoints. This enables low-height robots to overcome challenges such as visual obstructions and perceptual mismatches. Additionally, we transfer the connectivity graph from the HM3D and Gibson datasets as an extra resource to enhance spatial priors and a more comprehensive representation of real-world scenarios, leading to improved performance and generalizability of the waypoint predictor in real-world environments. Extensive experiments demonstrate that our Ground-level Viewpoint Navigation (GVnav) approach significantly improves performance in both simulated environments and real-world deployments with quadruped robots.
Secure and Efficient Watermarking for Latent Diffusion Models in Model Distribution Scenarios
Feb 18, 2025



Latent diffusion models have exhibited considerable potential in generative tasks. Watermarking is considered to be an alternative to safeguard the copyright of generative models and prevent their misuse. However, in the context of model distribution scenarios, the accessibility of models to large scale of model users brings new challenges to the security, efficiency and robustness of existing watermark solutions. To address these issues, we propose a secure and efficient watermarking solution. A new security mechanism is designed to prevent watermark leakage and watermark escape, which considers watermark randomness and watermark-model association as two constraints for mandatory watermark injection. To reduce the time cost of training the security module, watermark injection and the security mechanism are decoupled, ensuring that fine-tuning VAE only accomplishes the security mechanism without the burden of learning watermark patterns. A watermark distribution-based verification strategy is proposed to enhance the robustness against diverse attacks in the model distribution scenarios. Experimental results prove that our watermarking consistently outperforms existing six baselines on effectiveness and robustness against ten image processing attacks and adversarial attacks, while enhancing security in the distribution scenarios.
Vertical Federated Continual Learning via Evolving Prototype Knowledge
Feb 13, 2025Vertical Federated Learning (VFL) has garnered significant attention as a privacy-preserving machine learning framework for sample-aligned feature federation. However, traditional VFL approaches do not address the challenges of class and feature continual learning, resulting in catastrophic forgetting of knowledge from previous tasks. To address the above challenge, we propose a novel vertical federated continual learning method, named Vertical Federated Continual Learning via Evolving Prototype Knowledge (V-LETO), which primarily facilitates the transfer of knowledge from previous tasks through the evolution of prototypes. Specifically, we propose an evolving prototype knowledge method, enabling the global model to retain both previous and current task knowledge. Furthermore, we introduce a model optimization technique that mitigates the forgetting of previous task knowledge by restricting updates to specific parameters of the local model, thereby enhancing overall performance. Extensive experiments conducted in both CIL and FIL settings demonstrate that our method, V-LETO, outperforms the other state-of-the-art methods. For example, our method outperforms the state-of-the-art method by 10.39% and 35.15% for CIL and FIL tasks, respectively. Our code is available at https://anonymous.4open.science/r/V-LETO-0108/README.md.