 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Recognition by Request
Jul 28, 2022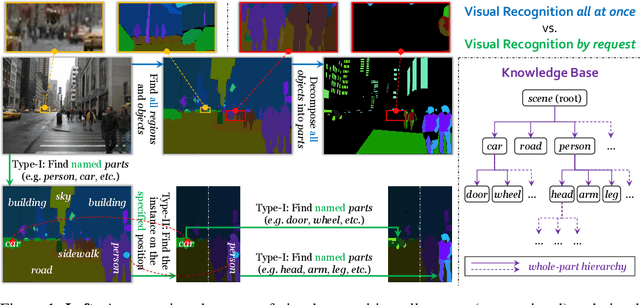
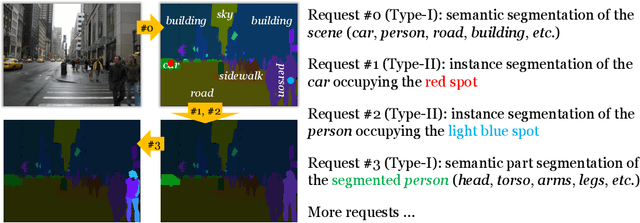

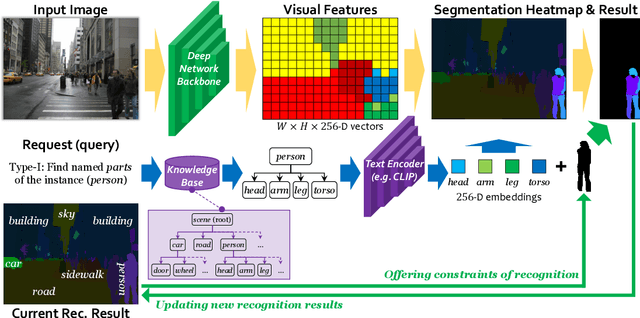
In this paper, we present a novel protocol of annotation and evaluation for visual recognition. Different from traditional settings, the protocol does not require the labeler/algorithm to annotate/recognize all targets (objects, parts, etc.) at once, but instead raises a number of recognition instructions and the algorithm recognizes targets by request. This mechanism brings two beneficial properties to reduce the burden of annotation, namely, (i) variable granularity: different scenarios can have different levels of annotation, in particular, object parts can be labeled only in large and clear instances, (ii) being open-domain: new concepts can be added to the database in minimal costs. To deal with the proposed setting, we maintain a knowledge base and design a query-based visual recognition framework that constructs queries on-the-fly based on the requests. We evaluate the recognition system on two mixed-annotated datasets, CPP and ADE20K, and demonstrate its promising ability of learning from partially labeled data as well as adapting to new concepts with only text labels.
Active Pointly-Supervised Instance Segmentation
Jul 23, 2022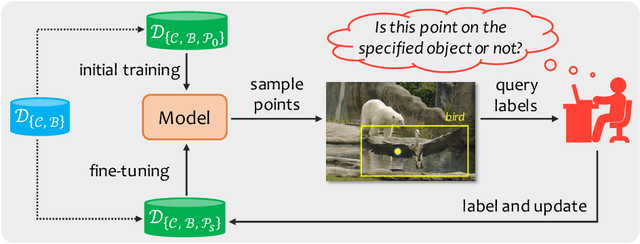
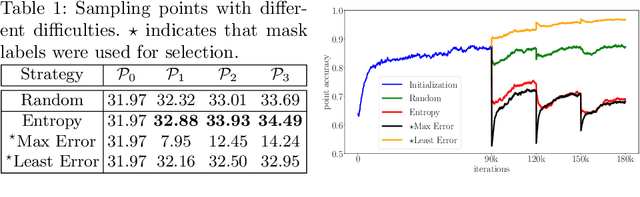
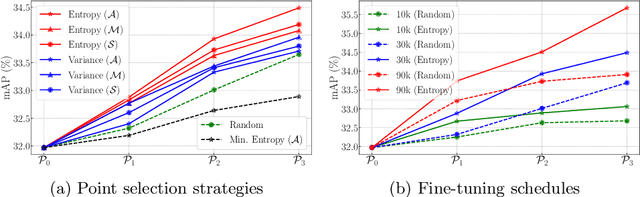

The requirement of expensive annotations is a major burden for training a well-performed instance segmentation model. In this paper, we present an economic active learning setting, named active pointly-supervised instance segmentation (APIS), which starts with box-level annotations and iteratively samples a point within the box and asks if it falls on the object. The key of APIS is to find the most desirable points to maximize the segmentation accuracy with limited annotation budgets. We formulate this setting and propose several uncertainty-based sampling strategies. The model developed with these strategies yields consistent performance gain on the challenging MS-COCO dataset, compared against other learning strategies. The results suggest that APIS, integrating the advantages of active learning and point-based supervision, is an effective learning paradigm for label-efficient instance segmentation.
Entity-enhanced Adaptive Reconstruction Network for Weakly Supervised Referring Expression Grounding
Jul 18, 2022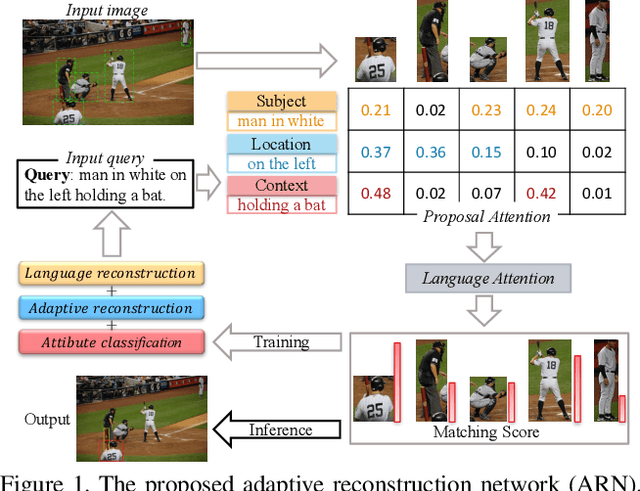
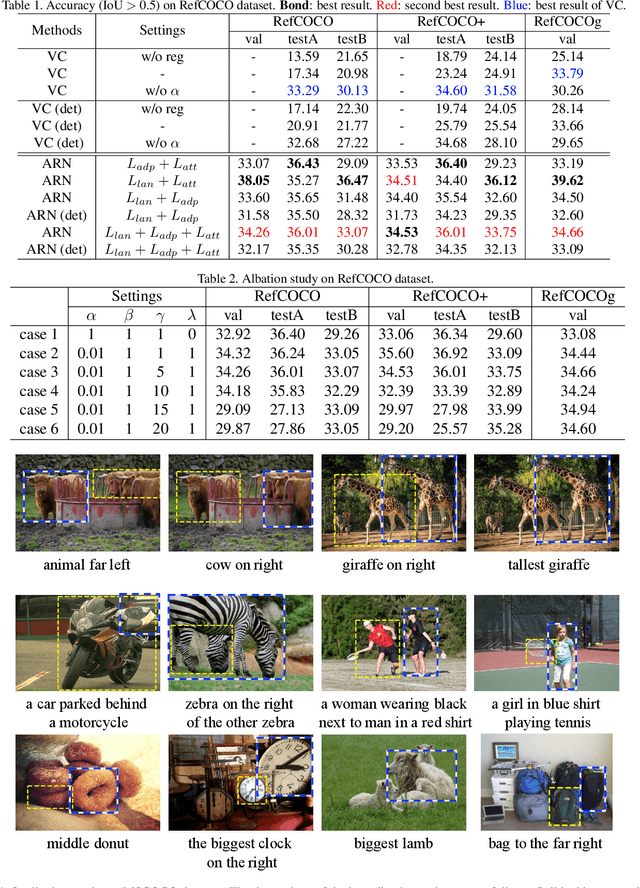
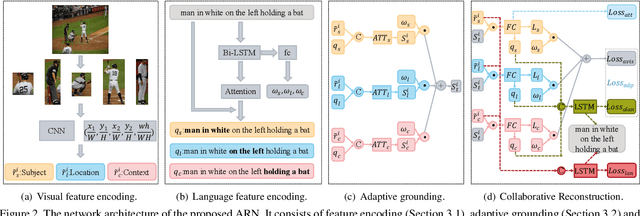
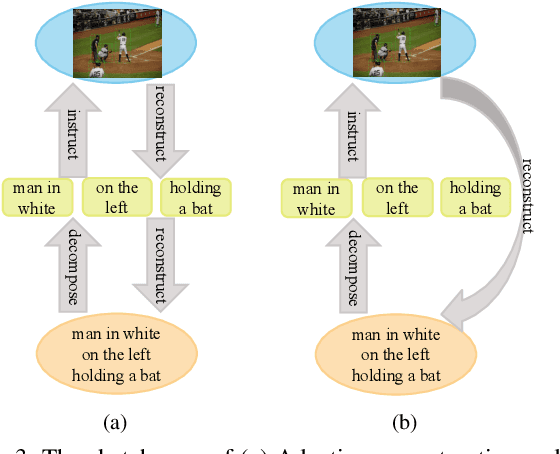
Weakly supervised Referring Expression Grounding (REG) aims to ground a particular target in an image described by a language expression while lacking the correspondence between target and expression. Two main problems exist in weakly supervised REG. First, the lack of region-level annotations introduces ambiguities between proposals and queries. Second, most previous weakly supervised REG methods ignore the discriminative location and context of the referent, causing difficulties in distinguishing the target from other same-category objects. To address the above challenges, we design an entity-enhanced adaptive reconstruction network (EARN). Specifically, EARN includes three modules: entity enhancement, adaptive grounding, and collaborative reconstruction. In entity enhancement, we calculate semantic similarity as supervision to select the candidate proposals. Adaptive grounding calculates the ranking score of candidate proposals upon subject, location and context with hierarchical attention. Collaborative reconstruction measures the ranking result from three perspectives: adaptive reconstruction, language reconstruction and attribute classification. The adaptive mechanism helps to alleviate the variance of different referring expressions. Experiments on five datasets show EARN outperforms existing state-of-the-art methods. Qualitative results demonstrate that the proposed EARN can better handle the situation where multiple objects of a particular category are situated together.
A Survey on Label-efficient Deep Segmentation: Bridging the Gap between Weak Supervision and Dense Prediction
Jul 04, 2022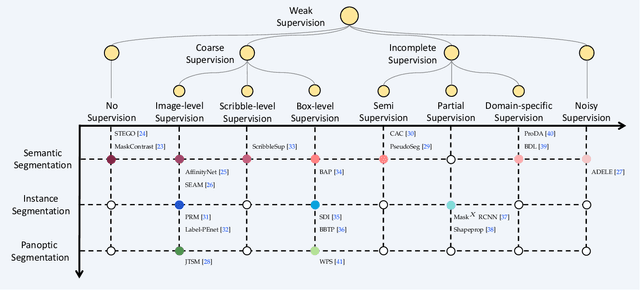
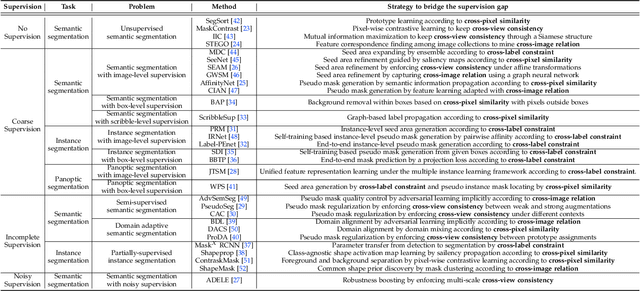

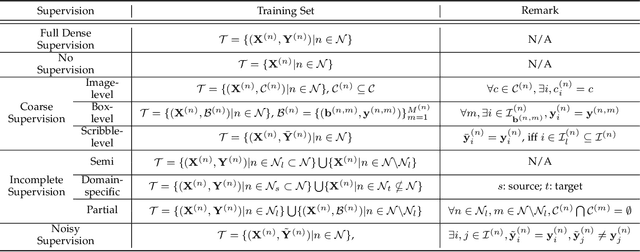
The rapid development of deep learning has made a great progress in segmentation, one of the fundamental tasks of computer vision. However, the current segmentation algorithms mostly rely on the availability of pixel-level annotations, which are often expensive, tedious, and laborious. To alleviate this burden, the past years have witnessed an increasing attention in building label-efficient, deep-learning-based segmentation algorithms. This paper offers a comprehensive review on label-efficient segmentation methods. To this end, we first develop a taxonomy to organize these methods according to the supervision provided by different types of weak labels (including no supervision, coarse supervision, incomplete supervision and noisy supervision) and supplemented by the types of segmentation problems (including semantic segmentation, instance segmentation and panoptic segmentation). Next, we summarize the existing label-efficient segmentation methods from a unified perspective that discusses an important question: how to bridge the gap between weak supervision and dense prediction -- the current methods are mostly based on heuristic priors, such as cross-pixel similarity, cross-label constraint, cross-view consistency, cross-image relation, etc. Finally, we share our opinions about the future research directions for label-efficient deep segmentation.
Reading and Writing: Discriminative and Generative Modeling for Self-Supervised Text Recognition
Jul 01, 2022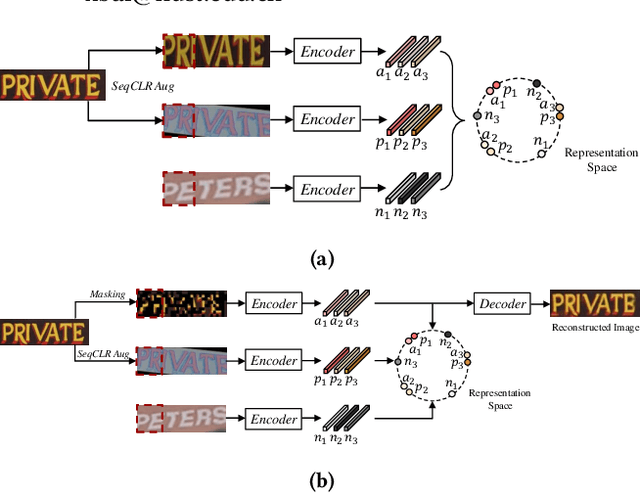
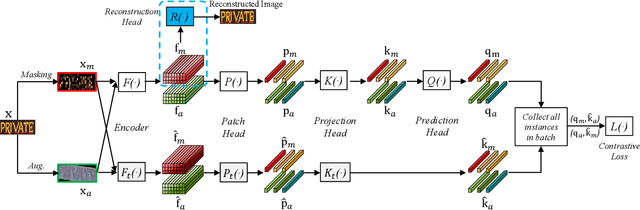
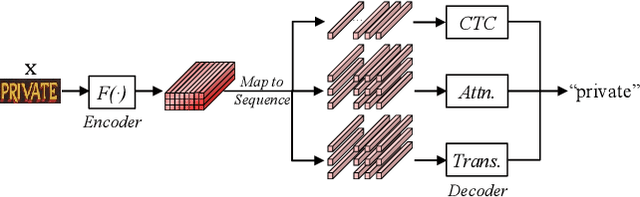
Existing text recognition methods usually need large-scale training data. Most of them rely on synthetic training data due to the lack of annotated real images. However, there is a domain gap between the synthetic data and real data, which limits the performance of the text recognition models. Recent self-supervised text recognition methods attempted to utilize unlabeled real images by introducing contrastive learning, which mainly learns the discrimination of the text images. Inspired by the observation that humans learn to recognize the texts through both reading and writing, we propose to learn discrimination and generation by integrating contrastive learning and masked image modeling in our self-supervised method. The contrastive learning branch is adopted to learn the discrimination of text images, which imitates the reading behavior of humans. Meanwhile, masked image modeling is firstly introduced for text recognition to learn the context generation of the text images, which is similar to the writing behavior. The experimental results show that our method outperforms previous self-supervised text recognition methods by 10.2%-20.2% on irregular scene text recognition datasets. Moreover, our proposed text recognizer exceeds previous state-of-the-art text recognition methods by averagely 5.3% on 11 benchmarks, with similar model size. We also demonstrate that our pre-trained model can be easily applied to other text-related tasks with obvious performance gain.
Towards Generalizable Person Re-identification with a Bi-stream Generative Model
Jun 26, 2022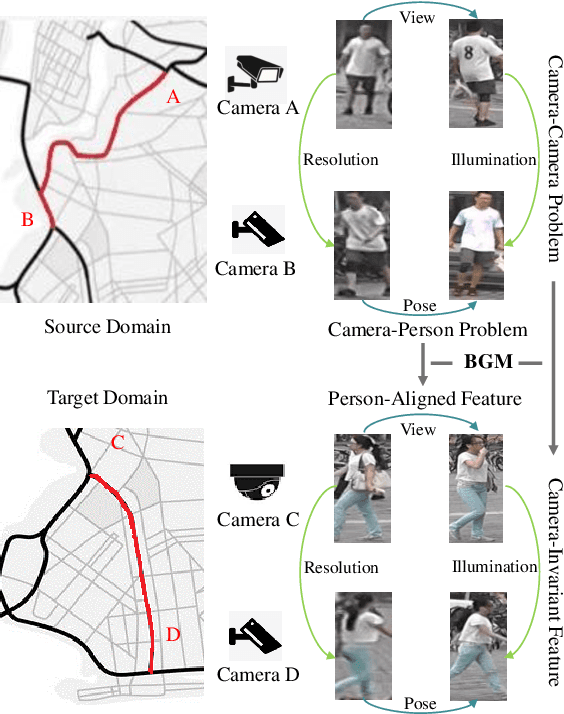
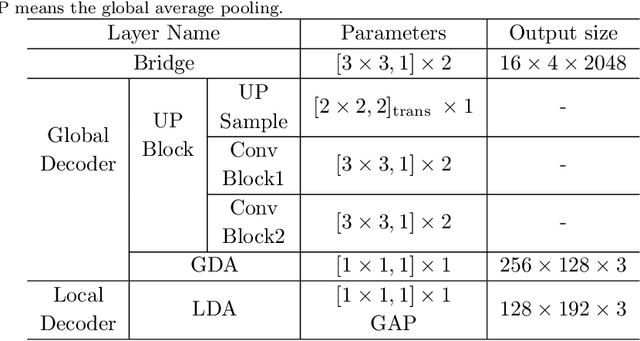
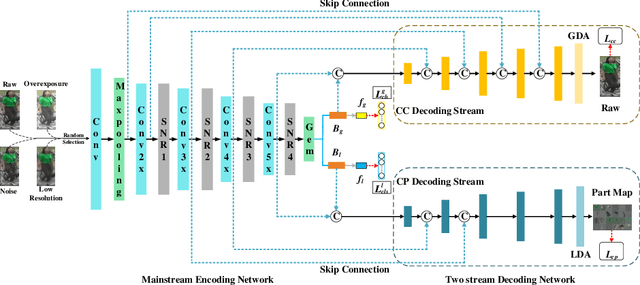
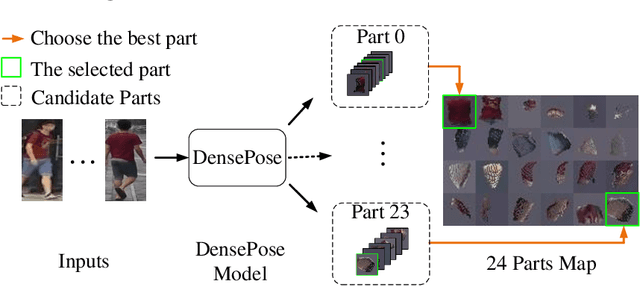
Generalizable person re-identification (re-ID) has attracted growing attention due to its powerful adaptation capability in the unseen data domain. However, existing solutions often neglect either crossing cameras (e.g., illumination and resolution differences) or pedestrian misalignments (e.g., viewpoint and pose discrepancies), which easily leads to poor generalization capability when adapted to the new domain. In this paper, we formulate these difficulties as: 1) Camera-Camera (CC) problem, which denotes the various human appearance changes caused by different cameras; 2) Camera-Person (CP) problem, which indicates the pedestrian misalignments caused by the same identity person under different camera viewpoints or changing pose. To solve the above issues, we propose a Bi-stream Generative Model (BGM) to learn the fine-grained representations fused with camera-invariant global feature and pedestrian-aligned local feature, which contains an encoding network and two stream decoding sub-networks. Guided by original pedestrian images, one stream is employed to learn a camera-invariant global feature for the CC problem via filtering cross-camera interference factors. For the CP problem, another stream learns a pedestrian-aligned local feature for pedestrian alignment using information-complete densely semantically aligned part maps. Moreover, a part-weighted loss function is presented to reduce the influence of missing parts on pedestrian alignment. Extensive experiments demonstrate that our method outperforms the state-of-the-art methods on the large-scale generalizable re-ID benchmarks, involving domain generalization setting and cross-domain setting.
Masked Autoencoders are Robust Data Augmentors
Jun 10, 2022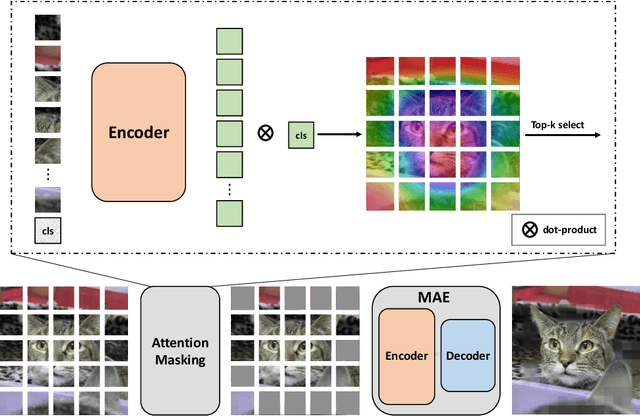
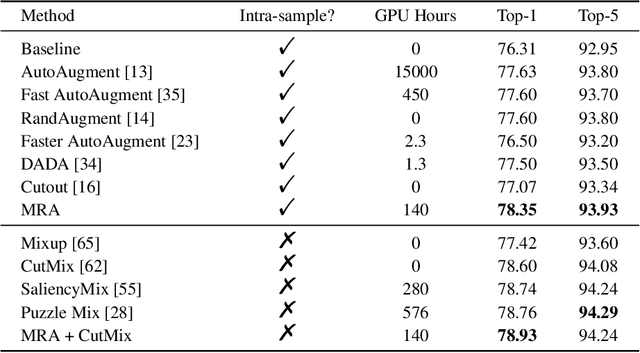
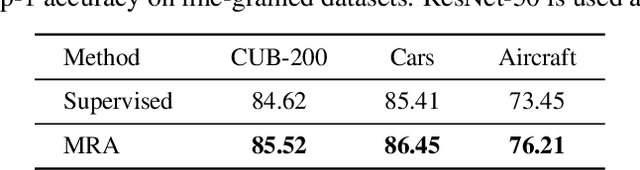

Deep neural networks are capable of learning powerful representations to tackle complex vision tasks but expose undesirable properties like the over-fitting issue. To this end, regularization techniques like image augmentation are necessary for deep neural networks to generalize well. Nevertheless, most prevalent image augmentation recipes confine themselves to off-the-shelf linear transformations like scale, flip, and colorjitter. Due to their hand-crafted property, these augmentations are insufficient to generate truly hard augmented examples. In this paper, we propose a novel perspective of augmentation to regularize the training process. Inspired by the recent success of applying masked image modeling to self-supervised learning, we adopt the self-supervised masked autoencoder to generate the distorted view of the input images. We show that utilizing such model-based nonlinear transformation as data augmentation can improve high-level recognition tasks. We term the proposed method as \textbf{M}ask-\textbf{R}econstruct \textbf{A}ugmentation (MRA). The extensive experiments on various image classification benchmarks verify the effectiveness of the proposed augmentation. Specifically, MRA consistently enhances the performance on supervised, semi-supervised as well as few-shot classification. The code will be available at \url{https://github.com/haohang96/MRA}.
DE-Net: Dynamic Text-guided Image Editing Adversarial Networks
Jun 02, 2022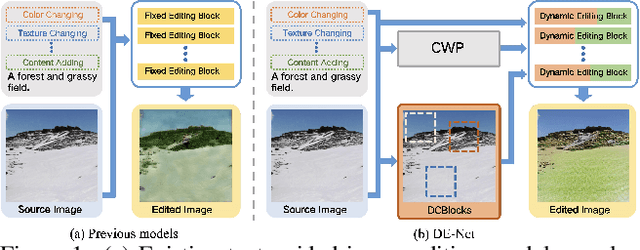
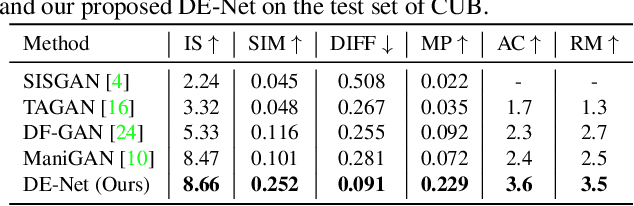
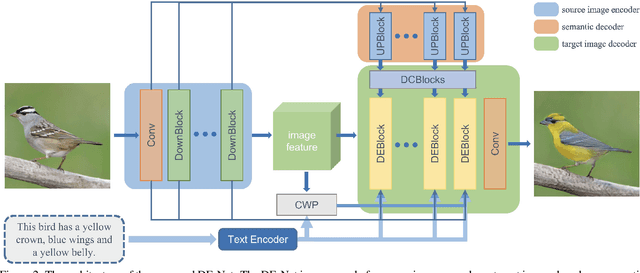
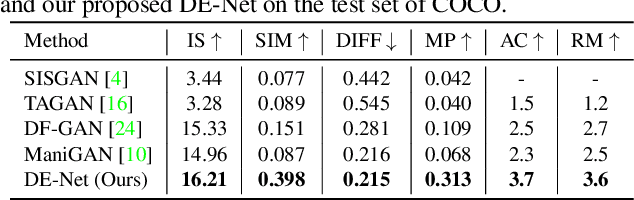
Text-guided image editing models have shown remarkable results. However, there remain two problems. First, they employ fixed manipulation modules for various editing requirements (e.g., color changing, texture changing, content adding and removing), which result in over-editing or insufficient editing. Second, they do not clearly distinguish between text-required parts and text-irrelevant parts, which leads to inaccurate editing. To solve these limitations, we propose: (i) a Dynamic Editing Block (DEBlock) which combines spatial- and channel-wise manipulations dynamically for various editing requirements. (ii) a Combination Weights Predictor (CWP) which predicts the combination weights for DEBlock according to the inference on text and visual features. (iii) a Dynamic text-adaptive Convolution Block (DCBlock) which queries source image features to distinguish text-required parts and text-irrelevant parts. Extensive experiments demonstrate that our DE-Net achieves excellent performance and manipulates source images more effectively and accurately. Code is available at \url{https://github.com/tobran/DE-Net}.
HiVLP: Hierarchical Vision-Language Pre-Training for Fast Image-Text Retrieval
May 31, 2022
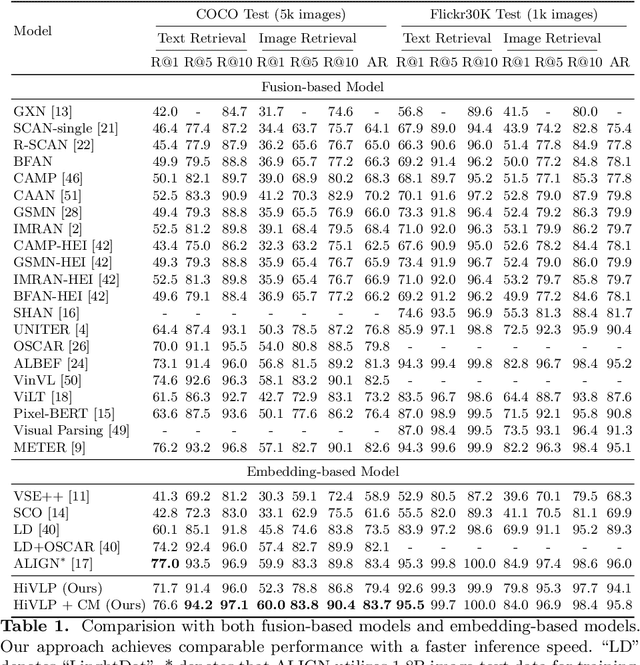
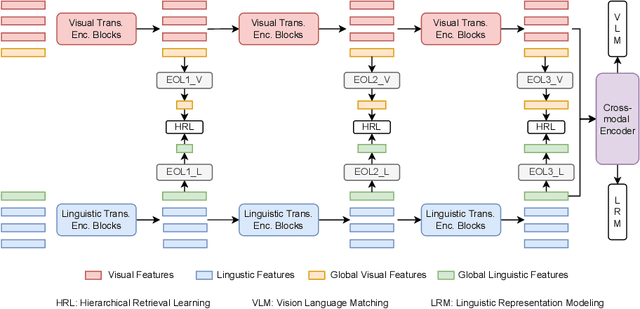
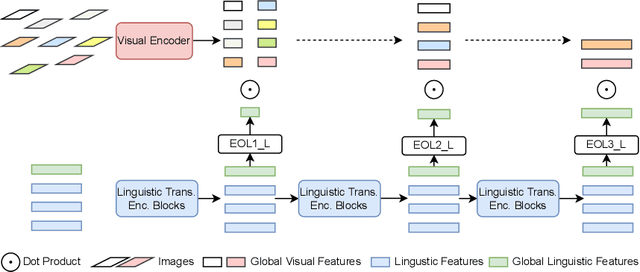
In the past few years, the emergence of vision-language pre-training (VLP) has brought cross-modal retrieval to a new era. However, due to the latency and computation demand, it is commonly challenging to apply VLP in a real-time online retrieval system. To alleviate the defect, this paper proposes a \textbf{Hi}erarchical \textbf{V}ision-\textbf{}Language \textbf{P}re-Training (\textbf{HiVLP}) for fast Image-Text Retrieval (ITR). Specifically, we design a novel hierarchical retrieval objective, which uses the representation of different dimensions for coarse-to-fine ITR, i.e., using low-dimensional representation for large-scale coarse retrieval and high-dimensional representation for small-scale fine retrieval. We evaluate our proposed HiVLP on two popular image-text retrieval benchmarks, i.e., Flickr30k and COCO. Extensive experiments demonstrate that our HiVLP not only has fast inference speed but also can be easily scaled to large-scale ITR scenarios. The detailed results show that HiVLP is $1,427$$\sim$$120,649\times$ faster than the fusion-based model UNITER and 2$\sim$5 faster than the fastest embedding-based model LightingDot in different candidate scenarios. It also achieves about +4.9 AR on COCO and +3.8 AR on Flickr30K than LightingDot and achieves comparable performance with the state-of-the-art (SOTA) fusion-based model METER.
Fast Dynamic Radiance Fields with Time-Aware Neural Voxels
May 30, 2022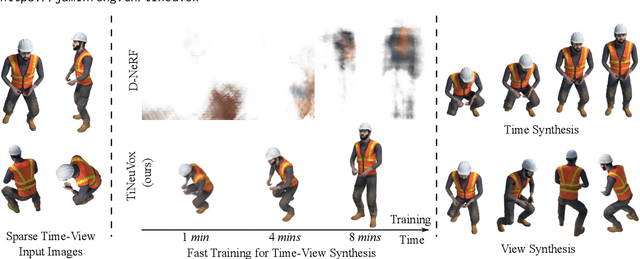

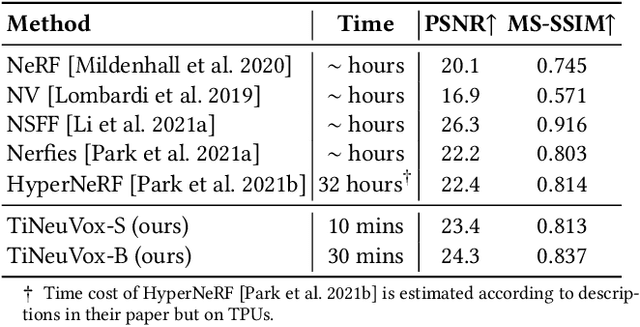
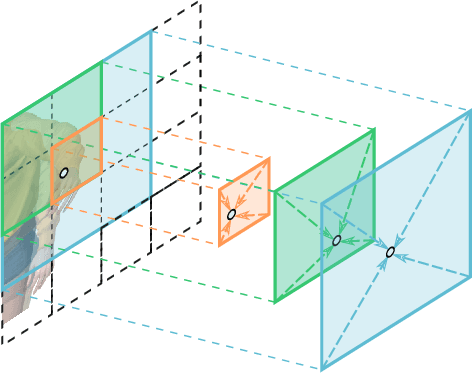
Neural radiance fields (NeRF) have shown great success in modeling 3D scenes and synthesizing novel-view images. However, most previous NeRF methods take much time to optimize one single scene. Explicit data structures, e.g. voxel features, show great potential to accelerate the training process. However, voxel features face two big challenges to be applied to dynamic scenes, i.e. modeling temporal information and capturing different scales of point motions. We propose a radiance field framework by representing scenes with time-aware voxel features, named as TiNeuVox. A tiny coordinate deformation network is introduced to model coarse motion trajectories and temporal information is further enhanced in the radiance network. A multi-distance interpolation method is proposed and applied on voxel features to model both small and large motions. Our framework significantly accelerates the optimization of dynamic radiance fields while maintaining high rendering quality. Empirical evaluation is performed on both synthetic and real scenes. Our TiNeuVox completes training with only 8 minutes and 8-MB storage cost while showing similar or even better rendering performance than previous dynamic NeRF methods.