 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInductive Generalization for Robotic Manipulation
Jun 19, 2026Understanding the generalization capabilities of visuomotor policies is essential in the development of capable robotic agents. Generalizable models learn structures that transfer across domains. However, in practice, visuomotor policies test performance by interpolation on known distributions using unstructured domain shifts (e.g. lighting, clutter, diverse objects). We argue that to measure generalization capabilities we must instead test the inductive capacity of policies on progressively harder, out-of-distribution task variants. We call this inductive generalization, drawing directly on how axis-based evaluation has revealed inherent generalization limitations in language models (e.g. sequence length, counting) arXiv:2502.00197 . We provide a reusable and formal evaluation protocol for measuring inductive generalization in any manipulation policy, and establish baselines showing that existing paradigms fail this test; e.g. SoTA Vision-Language-Action models and find that policies that appear to generalize to prior domain shifts (distractors, etc) fail inductive generalization tests. These results expose a class of learning challenges orthogonal to those addressed by data and model scaling in robot learning, yet are imperative to solve in order to realize general purpose robots.
Integrating LMM Planners and 3D Skill Policies for Generalizable Manipulation
Jan 30, 2025



The recent advancements in visual reasoning capabilities of large multimodal models (LMMs) and the semantic enrichment of 3D feature fields have expanded the horizons of robotic capabilities. These developments hold significant potential for bridging the gap between high-level reasoning from LMMs and low-level control policies utilizing 3D feature fields. In this work, we introduce LMM-3DP, a framework that can integrate LMM planners and 3D skill Policies. Our approach consists of three key perspectives: high-level planning, low-level control, and effective integration. For high-level planning, LMM-3DP supports dynamic scene understanding for environment disturbances, a critic agent with self-feedback, history policy memorization, and reattempts after failures. For low-level control, LMM-3DP utilizes a semantic-aware 3D feature field for accurate manipulation. In aligning high-level and low-level control for robot actions, language embeddings representing the high-level policy are jointly attended with the 3D feature field in the 3D transformer for seamless integration. We extensively evaluate our approach across multiple skills and long-horizon tasks in a real-world kitchen environment. Our results show a significant 1.45x success rate increase in low-level control and an approximate 1.5x improvement in high-level planning accuracy compared to LLM-based baselines. Demo videos and an overview of LMM-3DP are available at https://lmm-3dp-release.github.io.
GenSim2: Scaling Robot Data Generation with Multi-modal and Reasoning LLMs
Oct 04, 2024



Robotic simulation today remains challenging to scale up due to the human efforts required to create diverse simulation tasks and scenes. Simulation-trained policies also face scalability issues as many sim-to-real methods focus on a single task. To address these challenges, this work proposes GenSim2, a scalable framework that leverages coding LLMs with multi-modal and reasoning capabilities for complex and realistic simulation task creation, including long-horizon tasks with articulated objects. To automatically generate demonstration data for these tasks at scale, we propose planning and RL solvers that generalize within object categories. The pipeline can generate data for up to 100 articulated tasks with 200 objects and reduce the required human efforts. To utilize such data, we propose an effective multi-task language-conditioned policy architecture, dubbed proprioceptive point-cloud transformer (PPT), that learns from the generated demonstrations and exhibits strong sim-to-real zero-shot transfer. Combining the proposed pipeline and the policy architecture, we show a promising usage of GenSim2 that the generated data can be used for zero-shot transfer or co-train with real-world collected data, which enhances the policy performance by 20% compared with training exclusively on limited real data.
Toward Automated Programming for Robotic Assembly Using ChatGPT
May 13, 2024



Despite significant technological advancements, the process of programming robots for adaptive assembly remains labor-intensive, demanding expertise in multiple domains and often resulting in task-specific, inflexible code. This work explores the potential of Large Language Models (LLMs), like ChatGPT, to automate this process, leveraging their ability to understand natural language instructions, generalize examples to new tasks, and write code. In this paper, we suggest how these abilities can be harnessed and applied to real-world challenges in the manufacturing industry. We present a novel system that uses ChatGPT to automate the process of programming robots for adaptive assembly by decomposing complex tasks into simpler subtasks, generating robot control code, executing the code in a simulated workcell, and debugging syntax and control errors, such as collisions. We outline the architecture of this system and strategies for task decomposition and code generation. Finally, we demonstrate how our system can autonomously program robots for various assembly tasks in a real-world project.
Sim2Real Manipulation on Unknown Objects with Tactile-based Reinforcement Learning
Mar 18, 2024Using tactile sensors for manipulation remains one of the most challenging problems in robotics. At the heart of these challenges is generalization: How can we train a tactile-based policy that can manipulate unseen and diverse objects? In this paper, we propose to perform Reinforcement Learning with only visual tactile sensing inputs on diverse objects in a physical simulator. By training with diverse objects in simulation, it enables the policy to generalize to unseen objects. However, leveraging simulation introduces the Sim2Real transfer problem. To mitigate this problem, we study different tactile representations and evaluate how each affects real-robot manipulation results after transfer. We conduct our experiments on diverse real-world objects and show significant improvements over baselines for the pivoting task. Our project page is available at https://tactilerl.github.io/.
GNFactor: Multi-Task Real Robot Learning with Generalizable Neural Feature Fields
Sep 01, 2023



It is a long-standing problem in robotics to develop agents capable of executing diverse manipulation tasks from visual observations in unstructured real-world environments. To achieve this goal, the robot needs to have a comprehensive understanding of the 3D structure and semantics of the scene. In this work, we present $\textbf{GNFactor}$, a visual behavior cloning agent for multi-task robotic manipulation with $\textbf{G}$eneralizable $\textbf{N}$eural feature $\textbf{F}$ields. GNFactor jointly optimizes a generalizable neural field (GNF) as a reconstruction module and a Perceiver Transformer as a decision-making module, leveraging a shared deep 3D voxel representation. To incorporate semantics in 3D, the reconstruction module utilizes a vision-language foundation model ($\textit{e.g.}$, Stable Diffusion) to distill rich semantic information into the deep 3D voxel. We evaluate GNFactor on 3 real robot tasks and perform detailed ablations on 10 RLBench tasks with a limited number of demonstrations. We observe a substantial improvement of GNFactor over current state-of-the-art methods in seen and unseen tasks, demonstrating the strong generalization ability of GNFactor. Our project website is https://yanjieze.com/GNFactor/ .
Self-Play and Self-Describe: Policy Adaptation with Vision-Language Foundation Models
Dec 14, 2022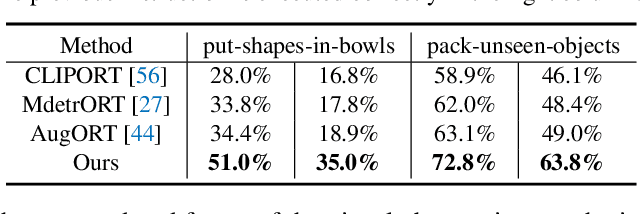
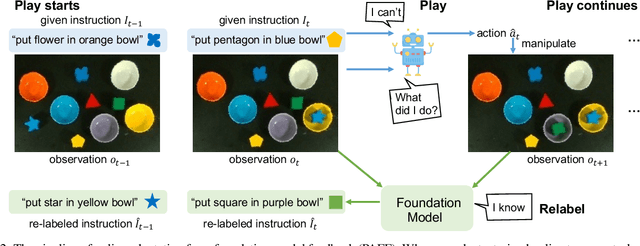

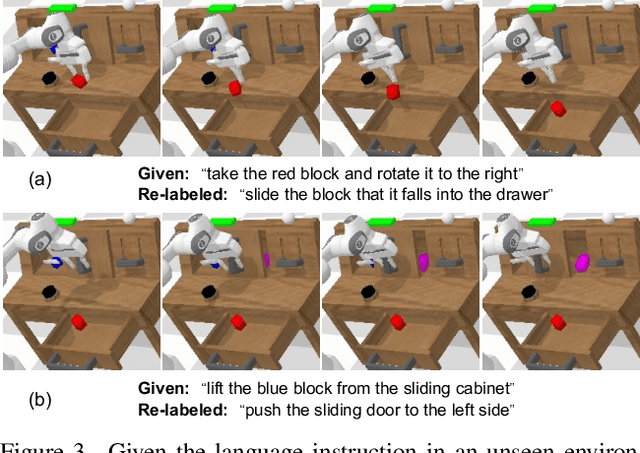
Recent progress on vision-language foundation models have brought significant advancement to building general-purpose robots. By using the pre-trained models to encode the scene and instructions as inputs for decision making, the instruction-conditioned policy can generalize across different objects and tasks. While this is encouraging, the policy still fails in most cases given an unseen task or environment. To adapt the policy to unseen tasks and environments, we explore a new paradigm on leveraging the pre-trained foundation models with Self-PLAY and Self-Describe (SPLAYD). When deploying the trained policy to a new task or a new environment, we first let the policy self-play with randomly generated instructions to record the demonstrations. While the execution could be wrong, we can use the pre-trained foundation models to accurately self-describe (i.e., re-label or classify) the demonstrations. This automatically provides new pairs of demonstration-instruction data for policy fine-tuning. We evaluate our method on a broad range of experiments with the focus on generalization on unseen objects, unseen tasks, unseen environments, and sim-to-real transfer. We show SPLAYD improves baselines by a large margin in all cases. Our project page is available at https://geyuying.github.io/SPLAYD/