 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeURLB: Unsupervised Reinforcement Learning Benchmark
Oct 28, 2021
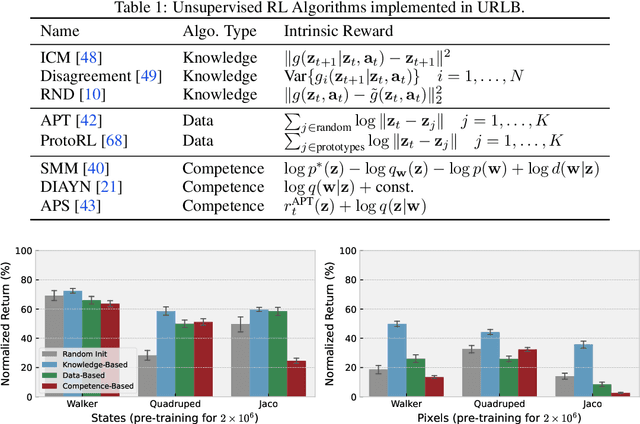

Deep Reinforcement Learning (RL) has emerged as a powerful paradigm to solve a range of complex yet specific control tasks. Yet training generalist agents that can quickly adapt to new tasks remains an outstanding challenge. Recent advances in unsupervised RL have shown that pre-training RL agents with self-supervised intrinsic rewards can result in efficient adaptation. However, these algorithms have been hard to compare and develop due to the lack of a unified benchmark. To this end, we introduce the Unsupervised Reinforcement Learning Benchmark (URLB). URLB consists of two phases: reward-free pre-training and downstream task adaptation with extrinsic rewards. Building on the DeepMind Control Suite, we provide twelve continuous control tasks from three domains for evaluation and open-source code for eight leading unsupervised RL methods. We find that the implemented baselines make progress but are not able to solve URLB and propose directions for future research.
Temporal-Difference Value Estimation via Uncertainty-Guided Soft Updates
Oct 28, 2021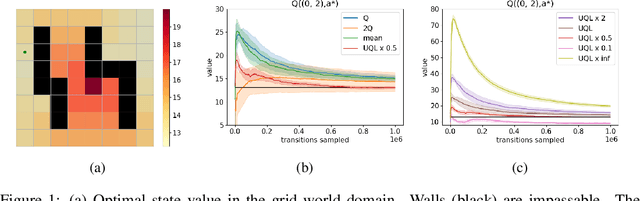

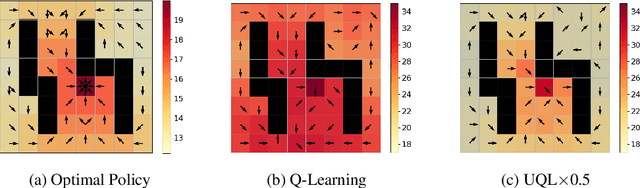
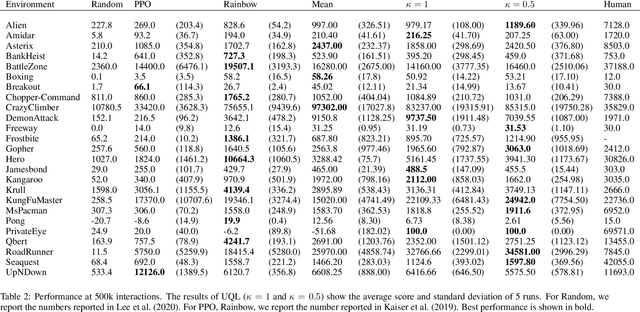
Temporal-Difference (TD) learning methods, such as Q-Learning, have proven effective at learning a policy to perform control tasks. One issue with methods like Q-Learning is that the value update introduces bias when predicting the TD target of a unfamiliar state. Estimation noise becomes a bias after the max operator in the policy improvement step, and carries over to value estimations of other states, causing Q-Learning to overestimate the Q value. Algorithms like Soft Q-Learning (SQL) introduce the notion of a soft-greedy policy, which reduces the estimation bias via soft updates in early stages of training. However, the inverse temperature $\beta$ that controls the softness of an update is usually set by a hand-designed heuristic, which can be inaccurate at capturing the uncertainty in the target estimate. Under the belief that $\beta$ is closely related to the (state dependent) model uncertainty, Entropy Regularized Q-Learning (EQL) further introduces a principled scheduling of $\beta$ by maintaining a collection of the model parameters that characterizes model uncertainty. In this paper, we present Unbiased Soft Q-Learning (UQL), which extends the work of EQL from two action, finite state spaces to multi-action, infinite state space Markov Decision Processes. We also provide a principled numerical scheduling of $\beta$, extended from SQL and using model uncertainty, during the optimization process. We show the theoretical guarantees and the effectiveness of this update method in experiments on several discrete control environments.
Towards More Generalizable One-shot Visual Imitation Learning
Oct 26, 2021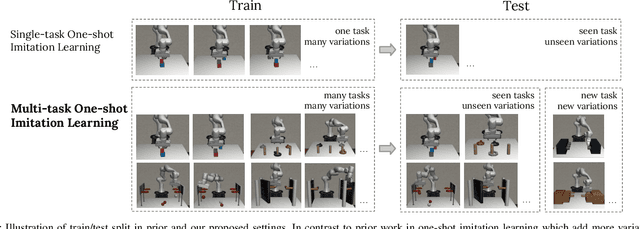

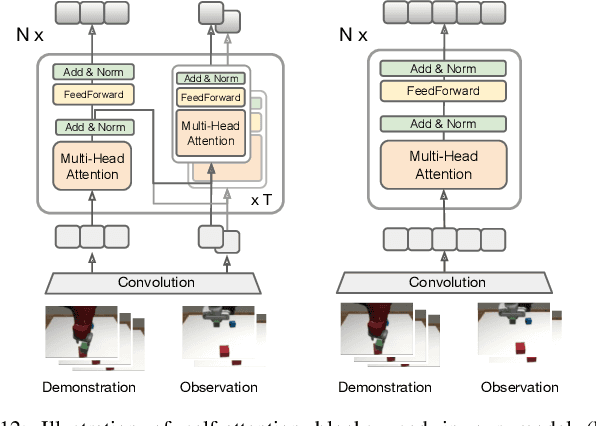
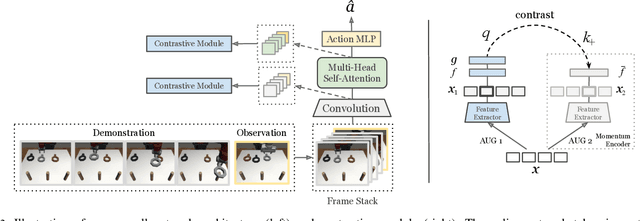
A general-purpose robot should be able to master a wide range of tasks and quickly learn a novel one by leveraging past experiences. One-shot imitation learning (OSIL) approaches this goal by training an agent with (pairs of) expert demonstrations, such that at test time, it can directly execute a new task from just one demonstration. However, so far this framework has been limited to training on many variations of one task, and testing on other unseen but similar variations of the same task. In this work, we push for a higher level of generalization ability by investigating a more ambitious multi-task setup. We introduce a diverse suite of vision-based robot manipulation tasks, consisting of 7 tasks, a total of 61 variations, and a continuum of instances within each variation. For consistency and comparison purposes, we first train and evaluate single-task agents (as done in prior few-shot imitation work). We then study the multi-task setting, where multi-task training is followed by (i) one-shot imitation on variations within the training tasks, (ii) one-shot imitation on new tasks, and (iii) fine-tuning on new tasks. Prior state-of-the-art, while performing well within some single tasks, struggles in these harder multi-task settings. To address these limitations, we propose MOSAIC (Multi-task One-Shot Imitation with self-Attention and Contrastive learning), which integrates a self-attention model architecture and a temporal contrastive module to enable better task disambiguation and more robust representation learning. Our experiments show that MOSAIC outperforms prior state of the art in learning efficiency, final performance, and learns a multi-task policy with promising generalization ability via fine-tuning on novel tasks.
APS: Active Pretraining with Successor Features
Aug 31, 2021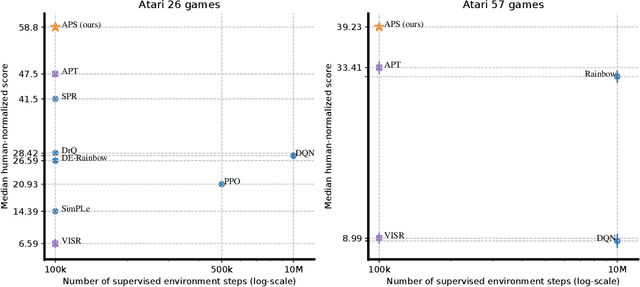
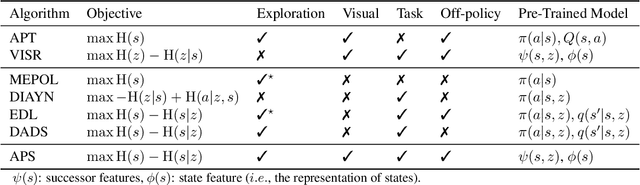
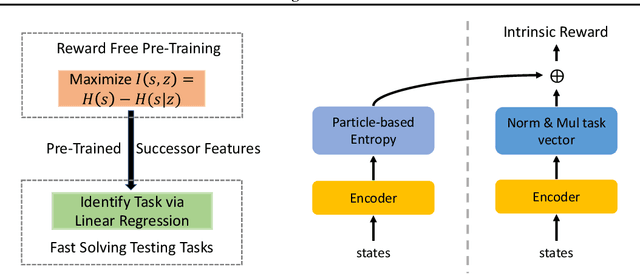
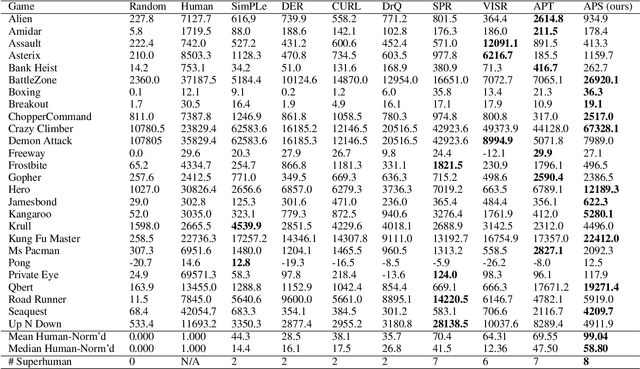
We introduce a new unsupervised pretraining objective for reinforcement learning. During the unsupervised reward-free pretraining phase, the agent maximizes mutual information between tasks and states induced by the policy. Our key contribution is a novel lower bound of this intractable quantity. We show that by reinterpreting and combining variational successor features~\citep{Hansen2020Fast} with nonparametric entropy maximization~\citep{liu2021behavior}, the intractable mutual information can be efficiently optimized. The proposed method Active Pretraining with Successor Feature (APS) explores the environment via nonparametric entropy maximization, and the explored data can be efficiently leveraged to learn behavior by variational successor features. APS addresses the limitations of existing mutual information maximization based and entropy maximization based unsupervised RL, and combines the best of both worlds. When evaluated on the Atari 100k data-efficiency benchmark, our approach significantly outperforms previous methods combining unsupervised pretraining with task-specific finetuning.
Skill Preferences: Learning to Extract and Execute Robotic Skills from Human Feedback
Aug 11, 2021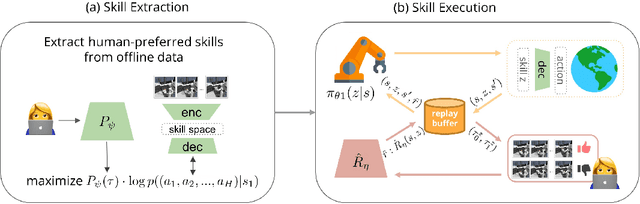
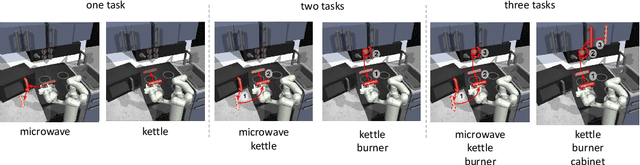
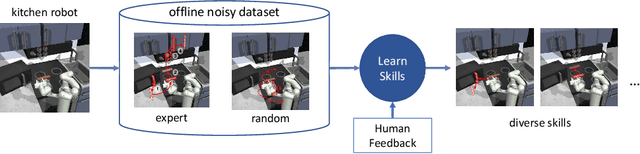
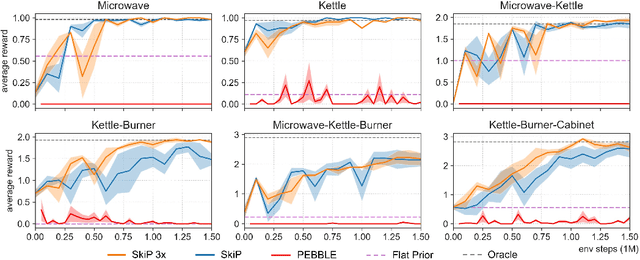
A promising approach to solving challenging long-horizon tasks has been to extract behavior priors (skills) by fitting generative models to large offline datasets of demonstrations. However, such generative models inherit the biases of the underlying data and result in poor and unusable skills when trained on imperfect demonstration data. To better align skill extraction with human intent we present Skill Preferences (SkiP), an algorithm that learns a model over human preferences and uses it to extract human-aligned skills from offline data. After extracting human-preferred skills, SkiP also utilizes human feedback to solve down-stream tasks with RL. We show that SkiP enables a simulated kitchen robot to solve complex multi-step manipulation tasks and substantially outperforms prior leading RL algorithms with human preferences as well as leading skill extraction algorithms without human preferences.
Playful Interactions for Representation Learning
Jul 19, 2021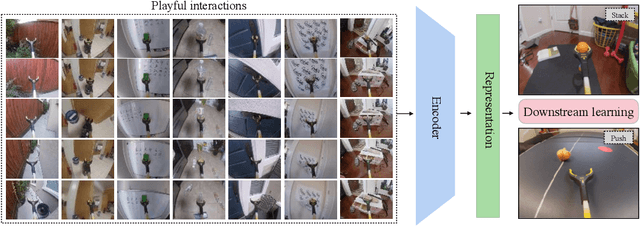


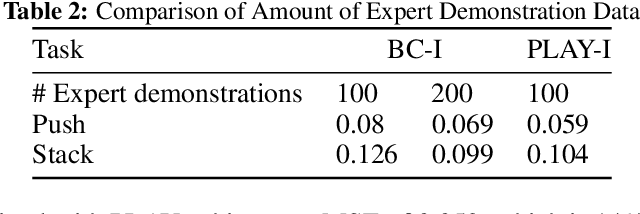
One of the key challenges in visual imitation learning is collecting large amounts of expert demonstrations for a given task. While methods for collecting human demonstrations are becoming easier with teleoperation methods and the use of low-cost assistive tools, we often still require 100-1000 demonstrations for every task to learn a visual representation and policy. To address this, we turn to an alternate form of data that does not require task-specific demonstrations -- play. Playing is a fundamental method children use to learn a set of skills and behaviors and visual representations in early learning. Importantly, play data is diverse, task-agnostic, and relatively cheap to obtain. In this work, we propose to use playful interactions in a self-supervised manner to learn visual representations for downstream tasks. We collect 2 hours of playful data in 19 diverse environments and use self-predictive learning to extract visual representations. Given these representations, we train policies using imitation learning for two downstream tasks: Pushing and Stacking. We demonstrate that our visual representations generalize better than standard behavior cloning and can achieve similar performance with only half the number of required demonstrations. Our representations, which are trained from scratch, compare favorably against ImageNet pretrained representations. Finally, we provide an experimental analysis on the effects of different pretraining modes on downstream task learning.
Hierarchical Few-Shot Imitation with Skill Transition Models
Jul 19, 2021
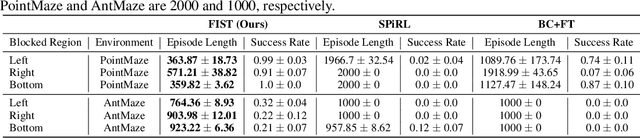
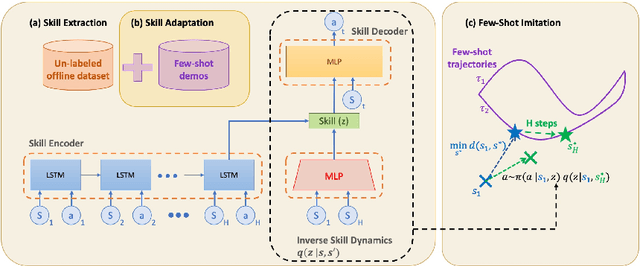

A desirable property of autonomous agents is the ability to both solve long-horizon problems and generalize to unseen tasks. Recent advances in data-driven skill learning have shown that extracting behavioral priors from offline data can enable agents to solve challenging long-horizon tasks with reinforcement learning. However, generalization to tasks unseen during behavioral prior training remains an outstanding challenge. To this end, we present Few-shot Imitation with Skill Transition Models (FIST), an algorithm that extracts skills from offline data and utilizes them to generalize to unseen tasks given a few downstream demonstrations. FIST learns an inverse skill dynamics model, a distance function, and utilizes a semi-parametric approach for imitation. We show that FIST is capable of generalizing to new tasks and substantially outperforms prior baselines in navigation experiments requiring traversing unseen parts of a large maze and 7-DoF robotic arm experiments requiring manipulating previously unseen objects in a kitchen.
The MineRL BASALT Competition on Learning from Human Feedback
Jul 05, 2021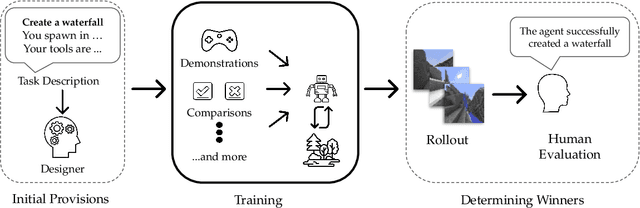

The last decade has seen a significant increase of interest in deep learning research, with many public successes that have demonstrated its potential. As such, these systems are now being incorporated into commercial products. With this comes an additional challenge: how can we build AI systems that solve tasks where there is not a crisp, well-defined specification? While multiple solutions have been proposed, in this competition we focus on one in particular: learning from human feedback. Rather than training AI systems using a predefined reward function or using a labeled dataset with a predefined set of categories, we instead train the AI system using a learning signal derived from some form of human feedback, which can evolve over time as the understanding of the task changes, or as the capabilities of the AI system improve. The MineRL BASALT competition aims to spur forward research on this important class of techniques. We design a suite of four tasks in Minecraft for which we expect it will be hard to write down hardcoded reward functions. These tasks are defined by a paragraph of natural language: for example, "create a waterfall and take a scenic picture of it", with additional clarifying details. Participants must train a separate agent for each task, using any method they want. Agents are then evaluated by humans who have read the task description. To help participants get started, we provide a dataset of human demonstrations on each of the four tasks, as well as an imitation learning baseline that leverages these demonstrations. Our hope is that this competition will improve our ability to build AI systems that do what their designers intend them to do, even when the intent cannot be easily formalized. Besides allowing AI to solve more tasks, this can also enable more effective regulation of AI systems, as well as making progress on the value alignment problem.
Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble
Jul 01, 2021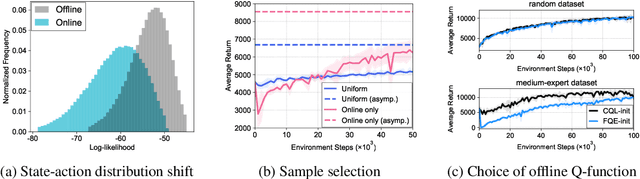
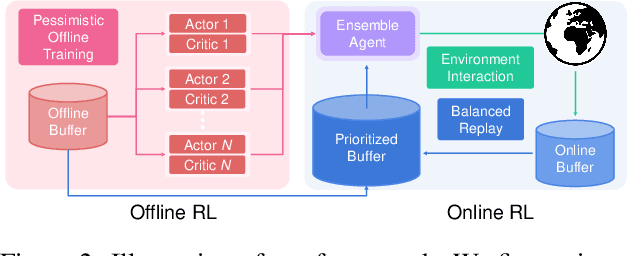
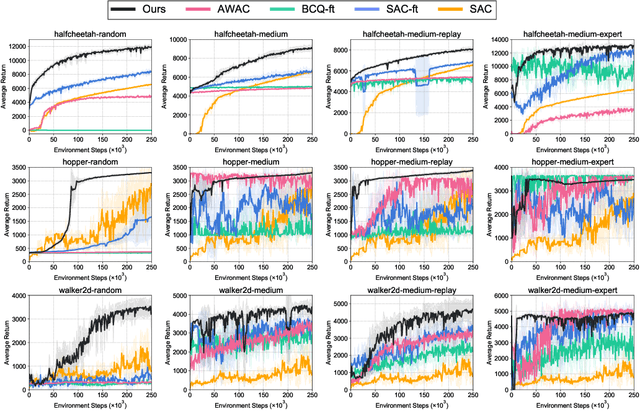
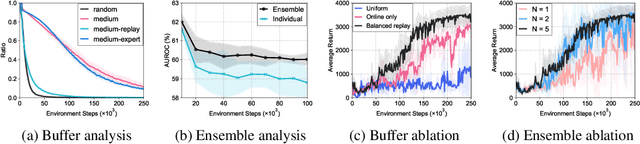
Recent advance in deep offline reinforcement learning (RL) has made it possible to train strong robotic agents from offline datasets. However, depending on the quality of the trained agents and the application being considered, it is often desirable to fine-tune such agents via further online interactions. In this paper, we observe that state-action distribution shift may lead to severe bootstrap error during fine-tuning, which destroys the good initial policy obtained via offline RL. To address this issue, we first propose a balanced replay scheme that prioritizes samples encountered online while also encouraging the use of near-on-policy samples from the offline dataset. Furthermore, we leverage multiple Q-functions trained pessimistically offline, thereby preventing overoptimism concerning unfamiliar actions at novel states during the initial training phase. We show that the proposed method improves sample-efficiency and final performance of the fine-tuned robotic agents on various locomotion and manipulation tasks. Our code is available at: https://github.com/shlee94/Off2OnRL.
Decision Transformer: Reinforcement Learning via Sequence Modeling
Jun 24, 2021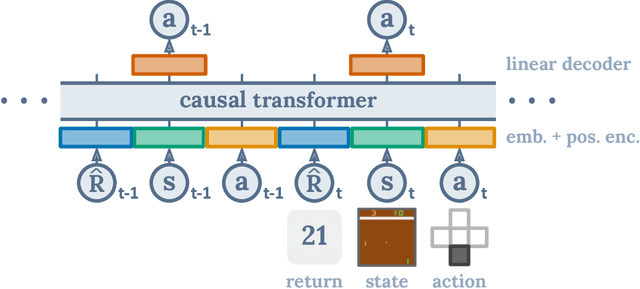
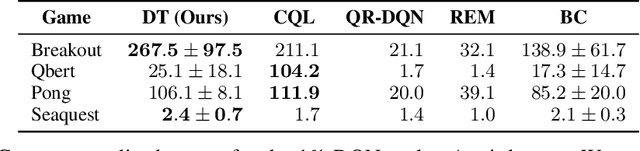

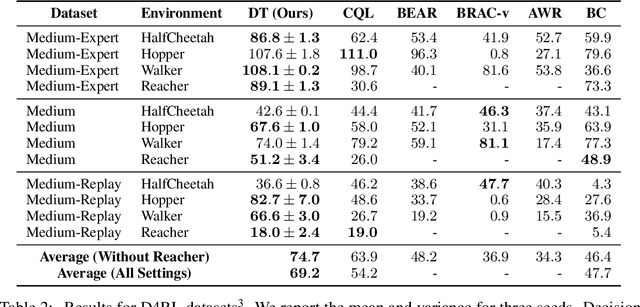
We introduce a framework that abstracts Reinforcement Learning (RL) as a sequence modeling problem. This allows us to draw upon the simplicity and scalability of the Transformer architecture, and associated advances in language modeling such as GPT-x and BERT. In particular, we present Decision Transformer, an architecture that casts the problem of RL as conditional sequence modeling. Unlike prior approaches to RL that fit value functions or compute policy gradients, Decision Transformer simply outputs the optimal actions by leveraging a causally masked Transformer. By conditioning an autoregressive model on the desired return (reward), past states, and actions, our Decision Transformer model can generate future actions that achieve the desired return. Despite its simplicity, Decision Transformer matches or exceeds the performance of state-of-the-art model-free offline RL baselines on Atari, OpenAI Gym, and Key-to-Door tasks.