 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Low-Rank Simplicity Bias in Deep Networks
Mar 18, 2021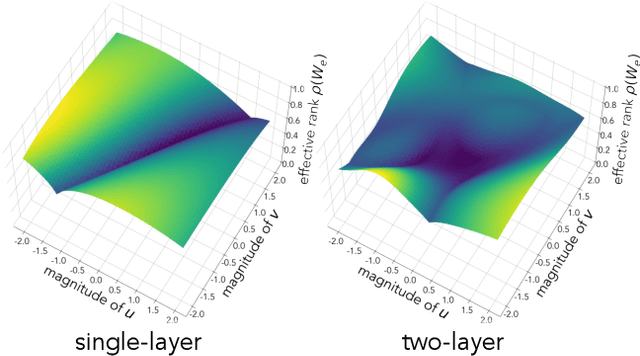
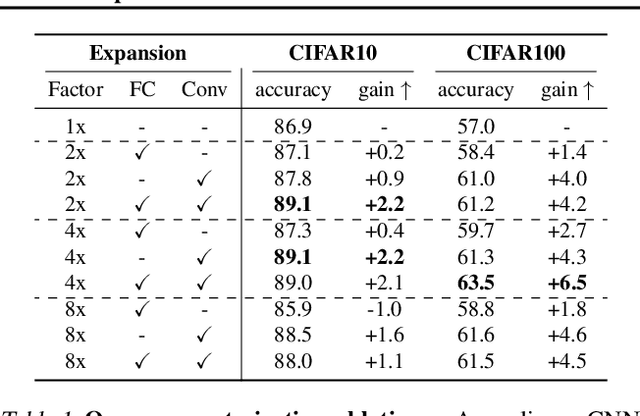
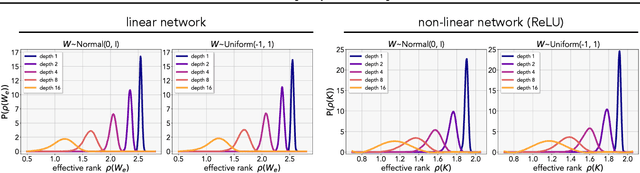
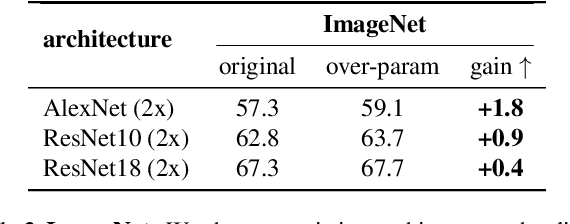
Modern deep neural networks are highly over-parameterized compared to the data on which they are trained, yet they often generalize remarkably well. A flurry of recent work has asked: why do deep networks not overfit to their training data? We investigate the hypothesis that deeper nets are implicitly biased to find lower rank solutions and that these are the solutions that generalize well. We prove for the asymptotic case that the percent volume of low effective-rank solutions increases monotonically as linear neural networks are made deeper. We then show empirically that our claim holds true on finite width models. We further empirically find that a similar result holds for non-linear networks: deeper non-linear networks learn a feature space whose kernel has a lower rank. We further demonstrate how linear over-parameterization of deep non-linear models can be used to induce low-rank bias, improving generalization performance without changing the effective model capacity. We evaluate on various model architectures and demonstrate that linearly over-parameterized models outperform existing baselines on image classification tasks, including ImageNet.
Using latent space regression to analyze and leverage compositionality in GANs
Mar 18, 2021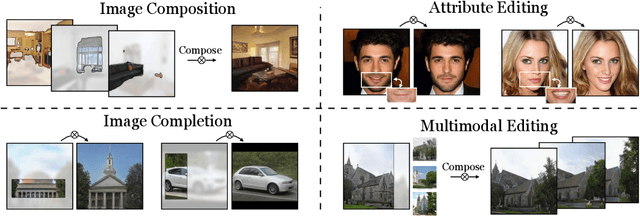



In recent years, Generative Adversarial Networks have become ubiquitous in both research and public perception, but how GANs convert an unstructured latent code to a high quality output is still an open question. In this work, we investigate regression into the latent space as a probe to understand the compositional properties of GANs. We find that combining the regressor and a pretrained generator provides a strong image prior, allowing us to create composite images from a collage of random image parts at inference time while maintaining global consistency. To compare compositional properties across different generators, we measure the trade-offs between reconstruction of the unrealistic input and image quality of the regenerated samples. We find that the regression approach enables more localized editing of individual image parts compared to direct editing in the latent space, and we conduct experiments to quantify this independence effect. Our method is agnostic to the semantics of edits, and does not require labels or predefined concepts during training. Beyond image composition, our method extends to a number of related applications, such as image inpainting or example-based image editing, which we demonstrate on several GANs and datasets, and because it uses only a single forward pass, it can operate in real-time. Code is available on our project page: https://chail.github.io/latent-composition/.
iNeRF: Inverting Neural Radiance Fields for Pose Estimation
Dec 10, 2020
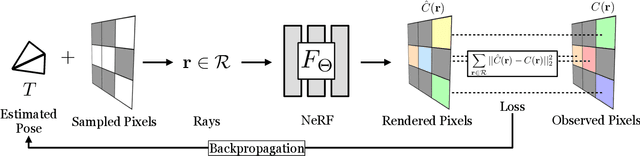
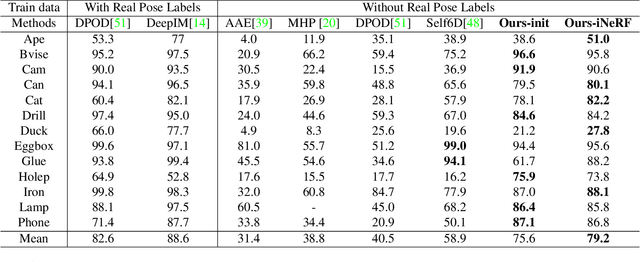
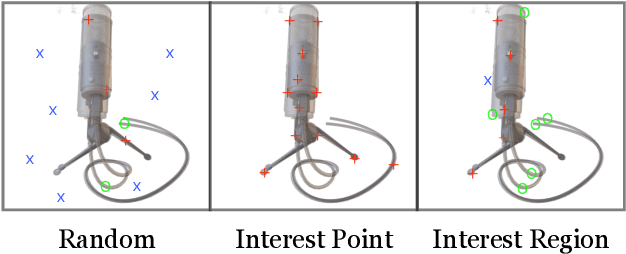
We present iNeRF, a framework that performs pose estimation by "inverting" a trained Neural Radiance Field (NeRF). NeRFs have been shown to be remarkably effective for the task of view synthesis - synthesizing photorealistic novel views of real-world scenes or objects. In this work, we investigate whether we can apply analysis-by-synthesis with NeRF for 6DoF pose estimation - given an image, find the translation and rotation of a camera relative to a 3D model. Starting from an initial pose estimate, we use gradient descent to minimize the residual between pixels rendered from an already-trained NeRF and pixels in an observed image. In our experiments, we first study 1) how to sample rays during pose refinement for iNeRF to collect informative gradients and 2) how different batch sizes of rays affect iNeRF on a synthetic dataset. We then show that for complex real-world scenes from the LLFF dataset, iNeRF can improve NeRF by estimating the camera poses of novel images and using these images as additional training data for NeRF. Finally, we show iNeRF can be combined with feature-based pose initialization. The approach outperforms all other RGB-based methods relying on synthetic data on LineMOD.
What makes fake images detectable? Understanding properties that generalize
Aug 24, 2020
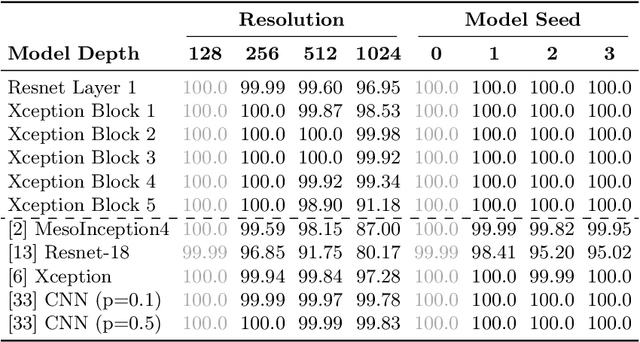
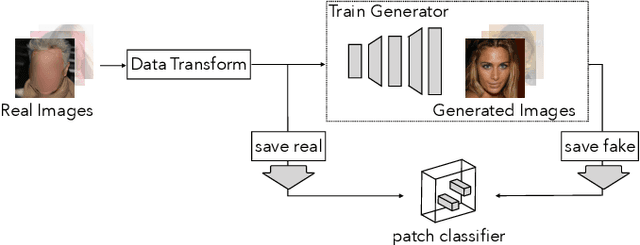
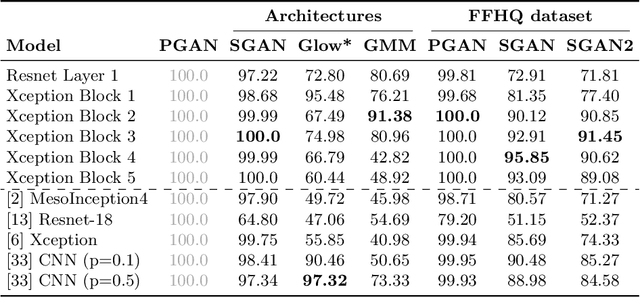
The quality of image generation and manipulation is reaching impressive levels, making it increasingly difficult for a human to distinguish between what is real and what is fake. However, deep networks can still pick up on the subtle artifacts in these doctored images. We seek to understand what properties of fake images make them detectable and identify what generalizes across different model architectures, datasets, and variations in training. We use a patch-based classifier with limited receptive fields to visualize which regions of fake images are more easily detectable. We further show a technique to exaggerate these detectable properties and demonstrate that, even when the image generator is adversarially finetuned against a fake image classifier, it is still imperfect and leaves detectable artifacts in certain image patches. Code is available at https://chail.github.io/patch-forensics/.
Noisy Agents: Self-supervised Exploration by Predicting Auditory Events
Jul 27, 2020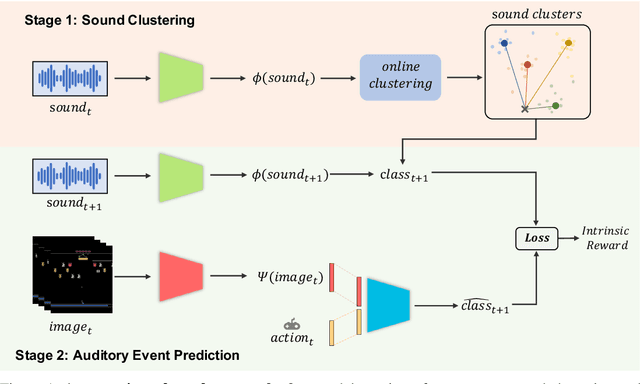

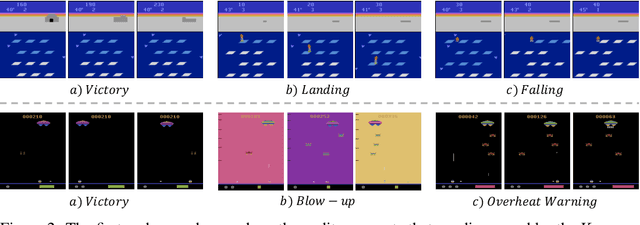

Humans integrate multiple sensory modalities (e.g. visual and audio) to build a causal understanding of the physical world. In this work, we propose a novel type of intrinsic motivation for Reinforcement Learning (RL) that encourages the agent to understand the causal effect of its actions through auditory event prediction. First, we allow the agent to collect a small amount of acoustic data and use K-means to discover underlying auditory event clusters. We then train a neural network to predict the auditory events and use the prediction errors as intrinsic rewards to guide RL exploration. Experimental results on Atari games show that our new intrinsic motivation significantly outperforms several state-of-the-art baselines. We further visualize our noisy agents' behavior in a physics environment and demonstrate that our newly designed intrinsic reward leads to the emergence of physical interaction behaviors (e.g. contact with objects).
Understanding Contrastive Representation Learning through Alignment and Uniformity on the Hypersphere
Jun 17, 2020


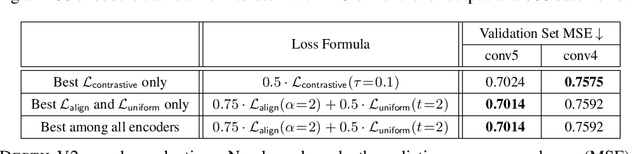
Contrastive representation learning has been outstandingly successful in practice. In this work, we identify two key properties related to the contrastive loss: (1) alignment (closeness) of features from positive pairs, and (2) uniformity of the induced distribution of the (normalized) features on the hypersphere. We prove that, asymptotically, the contrastive loss optimizes these properties, and analyze their positive effects on downstream tasks. Empirically, we introduce an optimizable metric to quantify each property. Extensive experiments on standard vision and language datasets confirm the strong agreement between both metrics and downstream task performance. Remarkably, directly optimizing for these two metrics leads to representations with comparable or better performance at downstream tasks than contrastive learning. Project Page: https://ssnl.github.io/hypersphere Code: https://github.com/SsnL/align_uniform
What makes for good views for contrastive learning
May 20, 2020
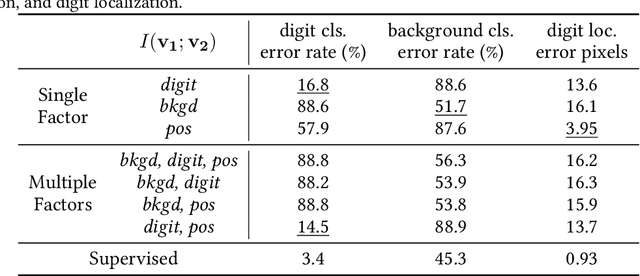
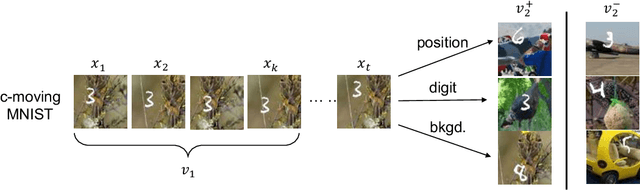
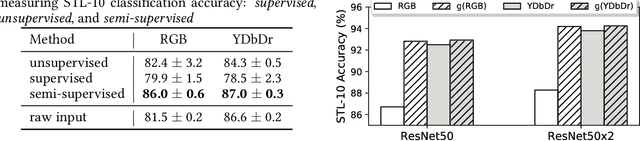
Contrastive learning between multiple views of the data has recently achieved state of the art performance in the field of self-supervised representation learning. Despite its success, the influence of different view choices has been less studied. In this paper, we use empirical analysis to better understand the importance of view selection, and argue that we should reduce the mutual information (MI) between views while keeping task-relevant information intact. To verify this hypothesis, we devise unsupervised and semi-supervised frameworks that learn effective views by aiming to reduce their MI. We also consider data augmentation as a way to reduce MI, and show that increasing data augmentation indeed leads to decreasing MI and improves downstream classification accuracy. As a by-product, we also achieve a new state-of-the-art accuracy on unsupervised pre-training for ImageNet classification ($73\%$ top-1 linear readoff with a ResNet-50). In addition, transferring our models to PASCAL VOC object detection and COCO instance segmentation consistently outperforms supervised pre-training. Code:http://github.com/HobbitLong/PyContrast
Supervised Contrastive Learning
Apr 23, 2020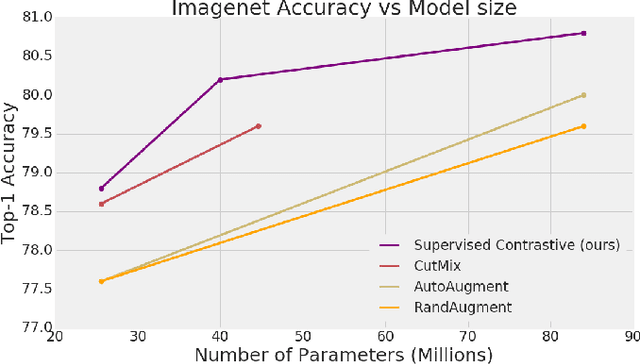
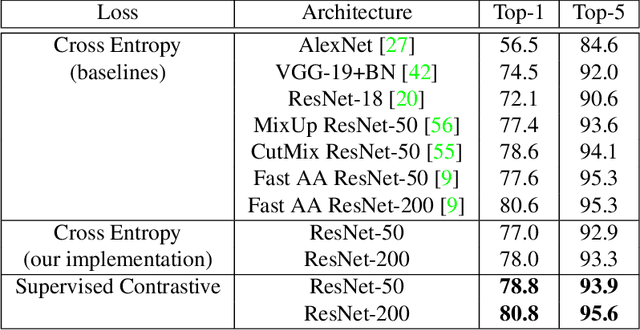
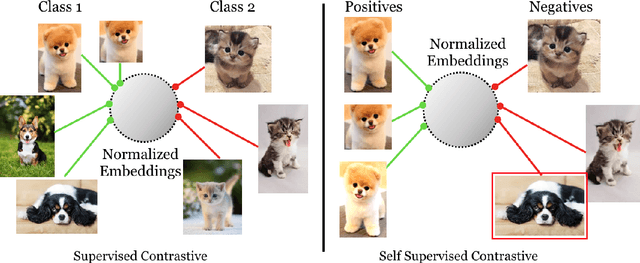
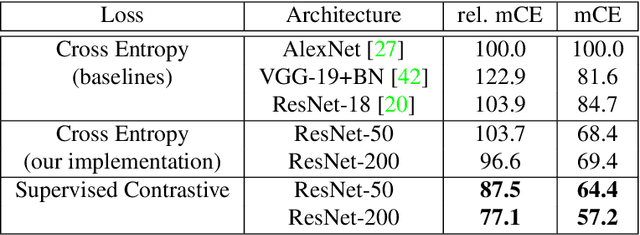
Cross entropy is the most widely used loss function for supervised training of image classification models. In this paper, we propose a novel training methodology that consistently outperforms cross entropy on supervised learning tasks across different architectures and data augmentations. We modify the batch contrastive loss, which has recently been shown to be very effective at learning powerful representations in the self-supervised setting. We are thus able to leverage label information more effectively than cross entropy. Clusters of points belonging to the same class are pulled together in embedding space, while simultaneously pushing apart clusters of samples from different classes. In addition to this, we leverage key ingredients such as large batch sizes and normalized embeddings, which have been shown to benefit self-supervised learning. On both ResNet-50 and ResNet-200, we outperform cross entropy by over 1%, setting a new state of the art number of 78.8% among methods that use AutoAugment data augmentation. The loss also shows clear benefits for robustness to natural corruptions on standard benchmarks on both calibration and accuracy. Compared to cross entropy, our supervised contrastive loss is more stable to hyperparameter settings such as optimizers or data augmentations.
Rethinking Few-Shot Image Classification: a Good Embedding Is All You Need?
Mar 25, 2020
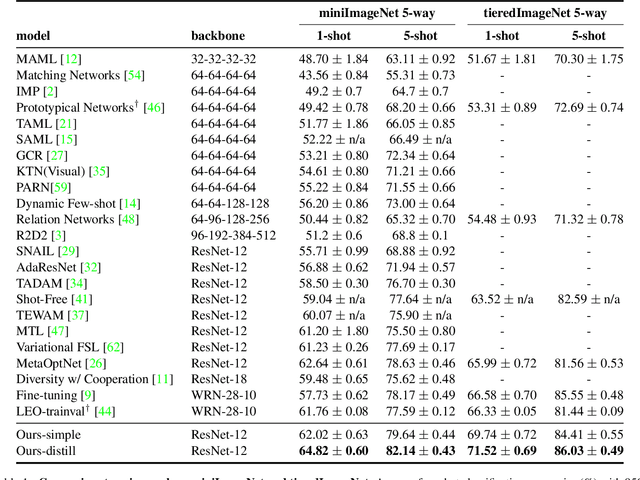
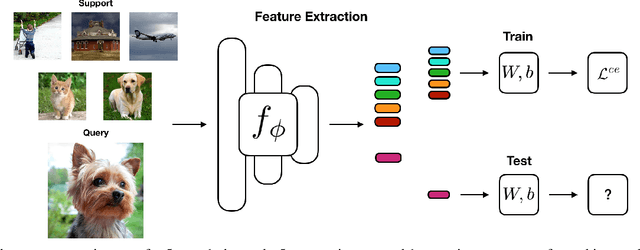
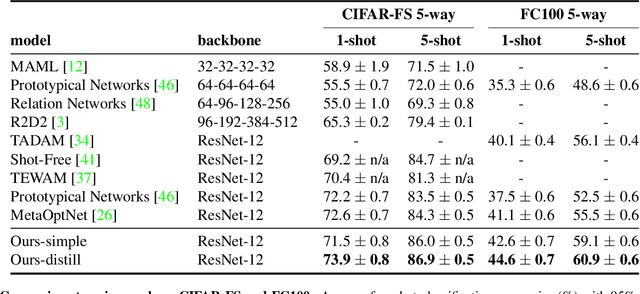
The focus of recent meta-learning research has been on the development of learning algorithms that can quickly adapt to test time tasks with limited data and low computational cost. Few-shot learning is widely used as one of the standard benchmarks in meta-learning. In this work, we show that a simple baseline: learning a supervised or self-supervised representation on the meta-training set, followed by training a linear classifier on top of this representation, outperforms state-of-the-art few-shot learning methods. An additional boost can be achieved through the use of self-distillation. This demonstrates that using a good learned embedding model can be more effective than sophisticated meta-learning algorithms. We believe that our findings motivate a rethinking of few-shot image classification benchmarks and the associated role of meta-learning algorithms. Code is available at: http://github.com/WangYueFt/rfs/.
Neural MMO v1.3: A Massively Multiagent Game Environment for Training and Evaluating Neural Networks
Jan 31, 2020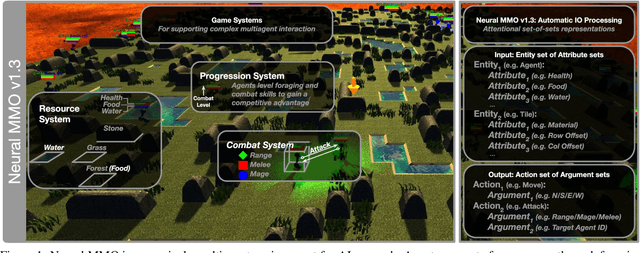
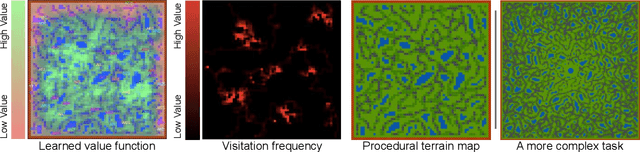
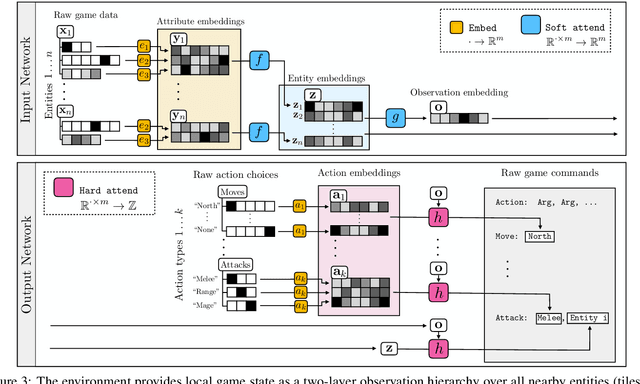
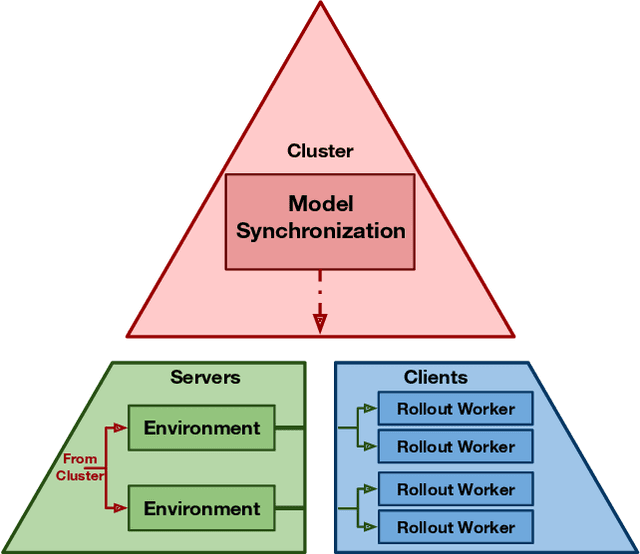
Progress in multiagent intelligence research is fundamentally limited by the number and quality of environments available for study. In recent years, simulated games have become a dominant research platform within reinforcement learning, in part due to their accessibility and interpretability. Previous works have targeted and demonstrated success on arcade, first person shooter (FPS), real-time strategy (RTS), and massive online battle arena (MOBA) games. Our work considers massively multiplayer online role-playing games (MMORPGs or MMOs), which capture several complexities of real-world learning that are not well modeled by any other game genre. We present Neural MMO, a massively multiagent game environment inspired by MMOs and discuss our progress on two more general challenges in multiagent systems engineering for AI research: distributed infrastructure and game IO. We further demonstrate that standard policy gradient methods and simple baseline models can learn interesting emergent exploration and specialization behaviors in this setting.