 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Prompt Tuning Based Textual Entailment Model for E-commerce Entity Typing
Nov 04, 2022The explosion of e-commerce has caused the need for processing and analysis of product titles, like entity typing in product titles. However, the rapid activity in e-commerce has led to the rapid emergence of new entities, which is difficult to be solved by general entity typing. Besides, product titles in e-commerce have very different language styles from text data in general domain. In order to handle new entities in product titles and address the special language styles problem of product titles in e-commerce domain, we propose our textual entailment model with continuous prompt tuning based hypotheses and fusion embeddings for e-commerce entity typing. First, we reformulate the entity typing task into a textual entailment problem to handle new entities that are not present during training. Second, we design a model to automatically generate textual entailment hypotheses using a continuous prompt tuning method, which can generate better textual entailment hypotheses without manual design. Third, we utilize the fusion embeddings of BERT embedding and CharacterBERT embedding with a two-layer MLP classifier to solve the problem that the language styles of product titles in e-commerce are different from that of general domain. To analyze the effect of each contribution, we compare the performance of entity typing and textual entailment model, and conduct ablation studies on continuous prompt tuning and fusion embeddings. We also evaluate the impact of different prompt template initialization for the continuous prompt tuning. We show our proposed model improves the average F1 score by around 2% compared to the baseline BERT entity typing model.
Mitigating Health Disparities in EHR via Deconfounder
Oct 28, 2022Health disparities, or inequalities between different patient demographics, are becoming crucial in medical decision-making, especially in Electronic Health Record (EHR) predictive modeling. To ensure the fairness of sensitive attributes, conventional studies mainly adopt calibration or re-weighting methods to balance the performance on among different demographic groups. However, we argue that these methods have some limitations. First, these methods usually mean a trade-off between the model's performance and fairness. Second, many methods completely attribute unfairness to the data collection process, which lacks substantial evidence. In this paper, we provide an empirical study to discover the possibility of using deconfounder to address the disparity issue in healthcare. Our study can be summarized in two parts. The first part is a pilot study demonstrating the exacerbation of disparity when unobserved confounders exist. The second part proposed a novel framework, Parity Medical Deconfounder (PriMeD), to deal with the disparity issue in healthcare datasets. Inspired by the deconfounder theory, PriMeD adopts a Conditional Variational Autoencoder (CVAE) to learn latent factors (substitute confounders) for observational data, and extensive experiments are provided to show its effectiveness.
Few-Shot Intent Detection via Contrastive Pre-Training and Fine-Tuning
Sep 13, 2021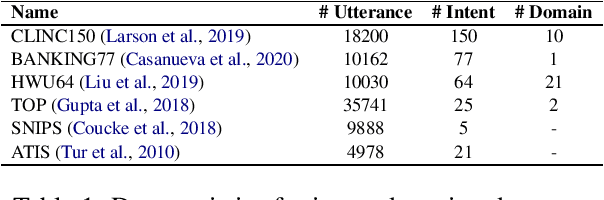
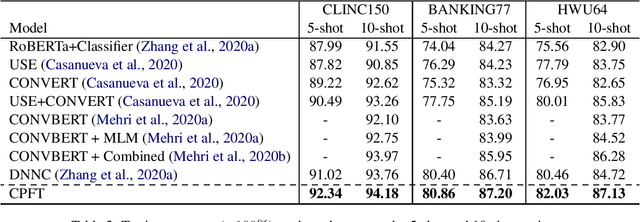

In this work, we focus on a more challenging few-shot intent detection scenario where many intents are fine-grained and semantically similar. We present a simple yet effective few-shot intent detection schema via contrastive pre-training and fine-tuning. Specifically, we first conduct self-supervised contrastive pre-training on collected intent datasets, which implicitly learns to discriminate semantically similar utterances without using any labels. We then perform few-shot intent detection together with supervised contrastive learning, which explicitly pulls utterances from the same intent closer and pushes utterances across different intents farther. Experimental results show that our proposed method achieves state-of-the-art performance on three challenging intent detection datasets under 5-shot and 10-shot settings.
Pseudo Siamese Network for Few-shot Intent Generation
May 03, 2021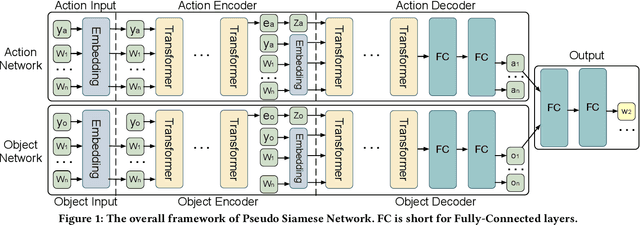
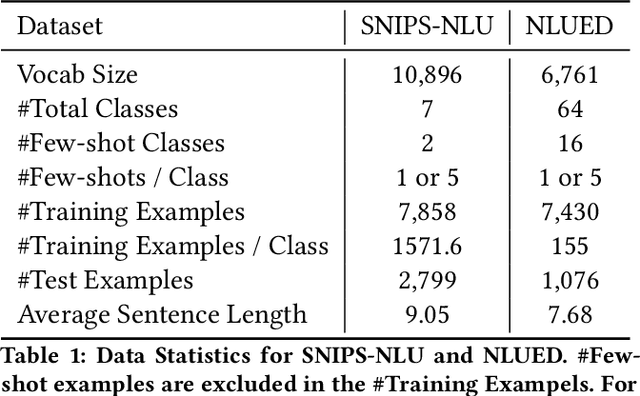
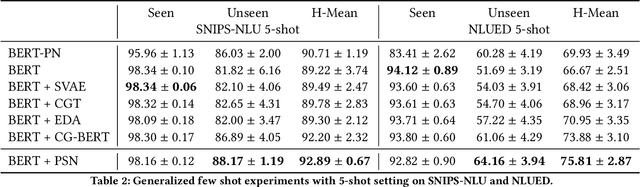
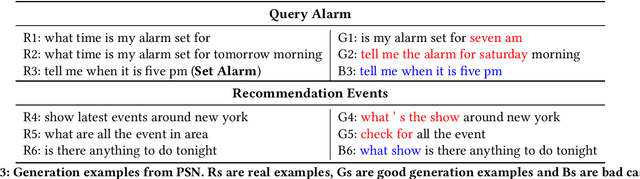
Few-shot intent detection is a challenging task due to the scare annotation problem. In this paper, we propose a Pseudo Siamese Network (PSN) to generate labeled data for few-shot intents and alleviate this problem. PSN consists of two identical subnetworks with the same structure but different weights: an action network and an object network. Each subnetwork is a transformer-based variational autoencoder that tries to model the latent distribution of different components in the sentence. The action network is learned to understand action tokens and the object network focuses on object-related expressions. It provides an interpretable framework for generating an utterance with an action and an object existing in a given intent. Experiments on two real-world datasets show that PSN achieves state-of-the-art performance for the generalized few shot intent detection task.
Incremental Few-shot Text Classification with Multi-round New Classes: Formulation, Dataset and System
Apr 24, 2021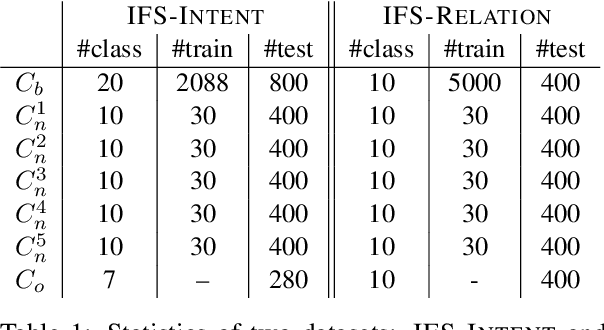
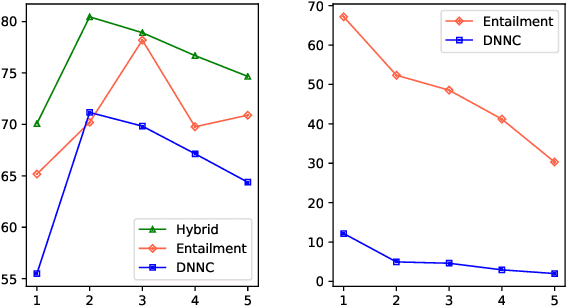
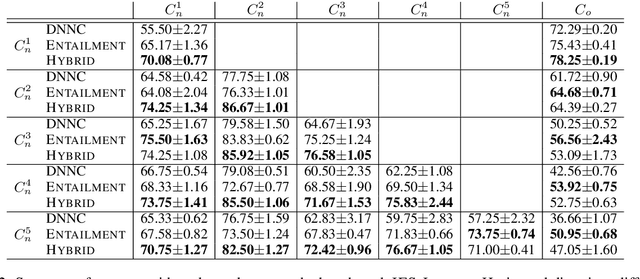
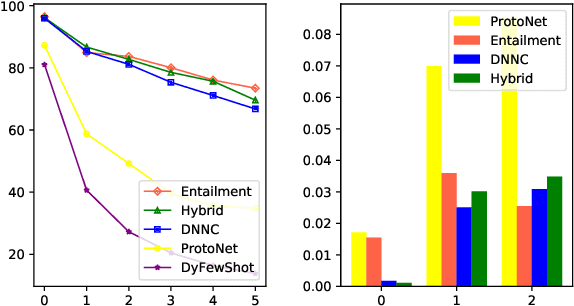
Text classification is usually studied by labeling natural language texts with relevant categories from a predefined set. In the real world, new classes might keep challenging the existing system with limited labeled data. The system should be intelligent enough to recognize upcoming new classes with a few examples. In this work, we define a new task in the NLP domain, incremental few-shot text classification, where the system incrementally handles multiple rounds of new classes. For each round, there is a batch of new classes with a few labeled examples per class. Two major challenges exist in this new task: (i) For the learning process, the system should incrementally learn new classes round by round without re-training on the examples of preceding classes; (ii) For the performance, the system should perform well on new classes without much loss on preceding classes. In addition to formulating the new task, we also release two benchmark datasets in the incremental few-shot setting: intent classification and relation classification. Moreover, we propose two entailment approaches, ENTAILMENT and HYBRID, which show promise for solving this novel problem.
Composed Variational Natural Language Generation for Few-shot Intents
Sep 21, 2020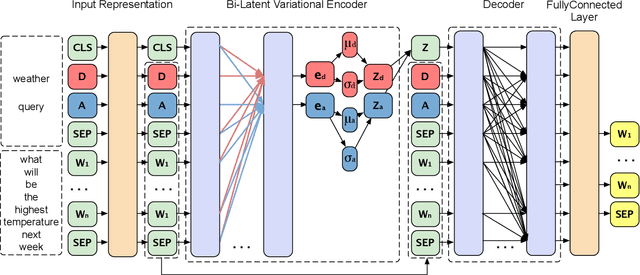
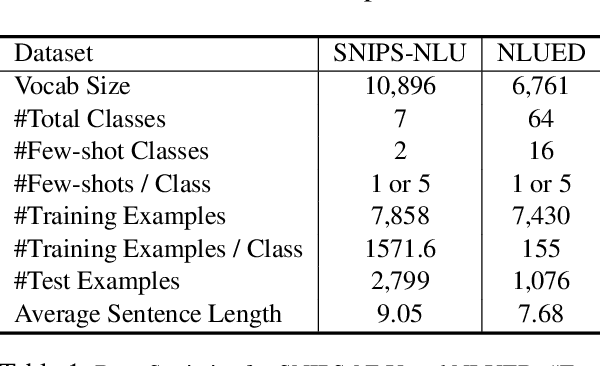
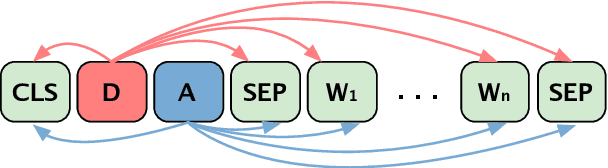
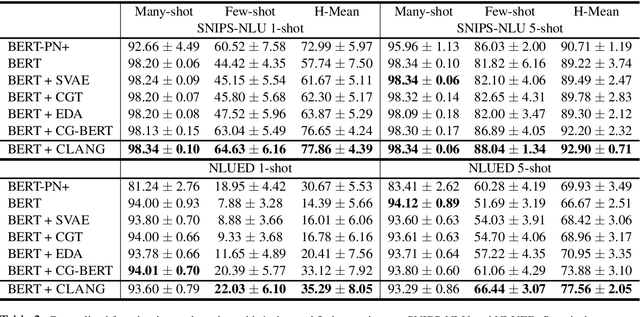
In this paper, we focus on generating training examples for few-shot intents in the realistic imbalanced scenario. To build connections between existing many-shot intents and few-shot intents, we consider an intent as a combination of a domain and an action, and propose a composed variational natural language generator (CLANG), a transformer-based conditional variational autoencoder. CLANG utilizes two latent variables to represent the utterances corresponding to two different independent parts (domain and action) in the intent, and the latent variables are composed together to generate natural examples. Additionally, to improve the generator learning, we adopt the contrastive regularization loss that contrasts the in-class with the out-of-class utterance generation given the intent. To evaluate the quality of the generated utterances, experiments are conducted on the generalized few-shot intent detection task. Empirical results show that our proposed model achieves state-of-the-art performances on two real-world intent detection datasets.
Multi-label Zero-shot Classification by Learning to Transfer from External Knowledge
Jul 31, 2020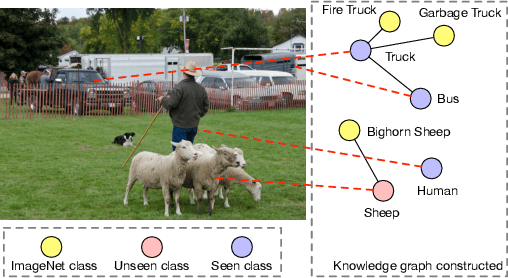
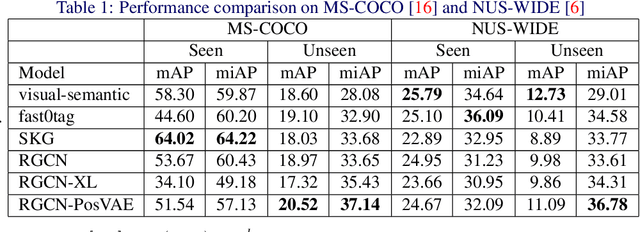
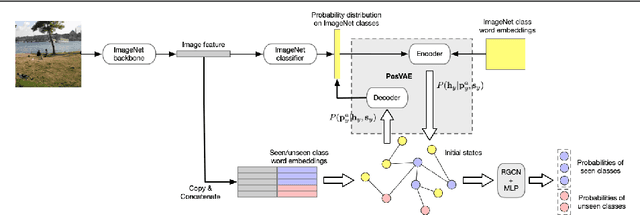
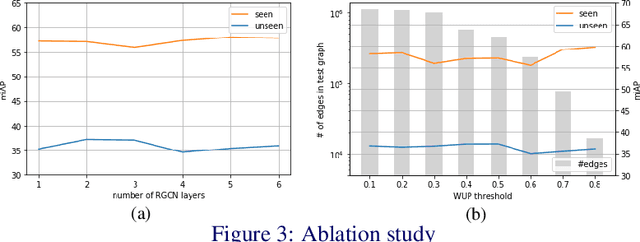
Multi-label zero-shot classification aims to predict multiple unseen class labels for an input image. It is more challenging than its single-label counterpart. On one hand, the unconstrained number of labels assigned to each image makes the model more easily overfit to those seen classes. On the other hand, there is a large semantic gap between seen and unseen classes in the existing multi-label classification datasets. To address these difficult issues, this paper introduces a novel multi-label zero-shot classification framework by learning to transfer from external knowledge. We observe that ImageNet is commonly used to pretrain the feature extractor and has a large and fine-grained label space. This motivates us to exploit it as external knowledge to bridge the seen and unseen classes and promote generalization. Specifically, we construct a knowledge graph including not only classes from the target dataset but also those from ImageNet. Since ImageNet labels are not available in the target dataset, we propose a novel PosVAE module to infer their initial states in the extended knowledge graph. Then we design a relational graph convolutional network (RGCN) to propagate information among classes and achieve knowledge transfer. Experimental results on two benchmark datasets demonstrate the effectiveness of the proposed approach.
CG-BERT: Conditional Text Generation with BERT for Generalized Few-shot Intent Detection
Apr 04, 2020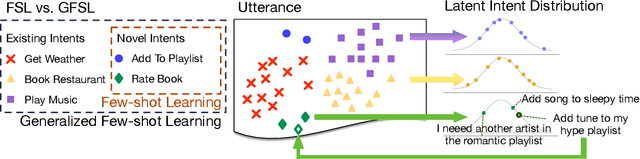
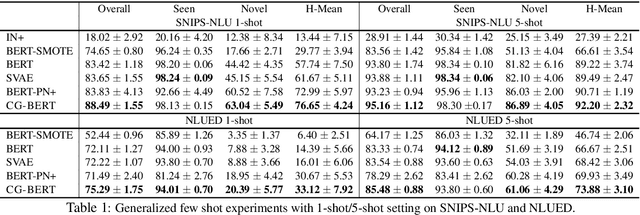
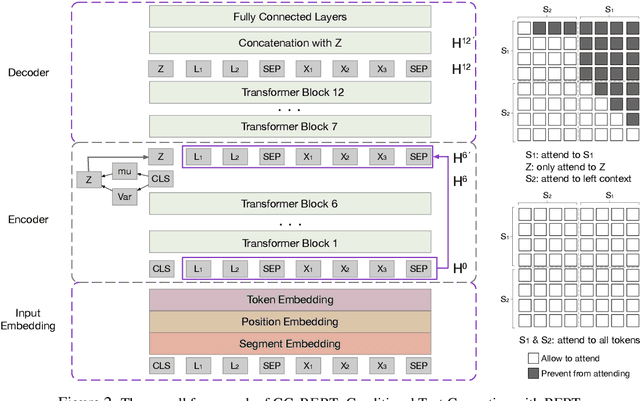
In this paper, we formulate a more realistic and difficult problem setup for the intent detection task in natural language understanding, namely Generalized Few-Shot Intent Detection (GFSID). GFSID aims to discriminate a joint label space consisting of both existing intents which have enough labeled data and novel intents which only have a few examples for each class. To approach this problem, we propose a novel model, Conditional Text Generation with BERT (CG-BERT). CG-BERT effectively leverages a large pre-trained language model to generate text conditioned on the intent label. By modeling the utterance distribution with variational inference, CG-BERT can generate diverse utterances for the novel intents even with only a few utterances available. Experimental results show that CG-BERT achieves state-of-the-art performance on the GFSID task with 1-shot and 5-shot settings on two real-world datasets.
MZET: Memory Augmented Zero-Shot Fine-grained Named Entity Typing
Apr 02, 2020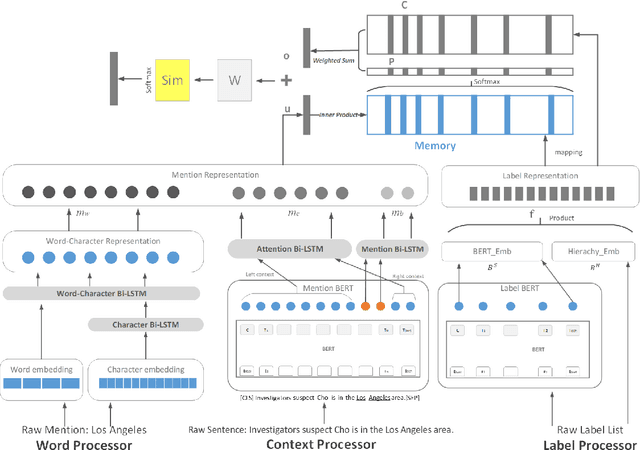
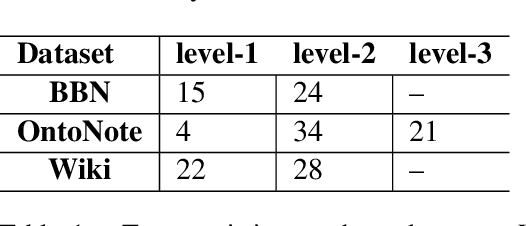
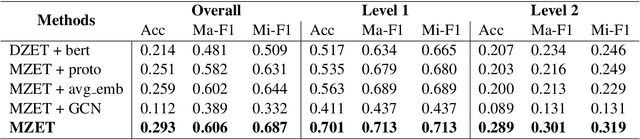
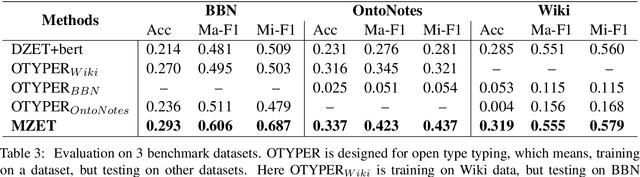
Named entity typing (NET) is a classification task of assigning an entity mention in the context with given semantic types. However, with the growing size and granularity of the entity types, rare researches in previous concern with newly emerged entity types. In this paper, we propose MZET, a novel memory augmented FNET (Fine-grained NET) model, to tackle the unseen types in a zero-shot manner. MZET incorporates character-level, word-level, and contextural-level information to learn the entity mention representation. Besides, MZET considers the semantic meaning and the hierarchical structure into the entity type representation. Finally, through the memory component which models the relationship between the entity mention and the entity type, MZET transfer the knowledge from seen entity types to the zero-shot ones. Extensive experiments on three public datasets show prominent performance obtained by MZET, which surpasses the state-of-the-art FNET neural network models with up to 7\% gain in Micro-F1 and Macro-F1 score.
Adv-BERT: BERT is not robust on misspellings! Generating nature adversarial samples on BERT
Feb 27, 2020
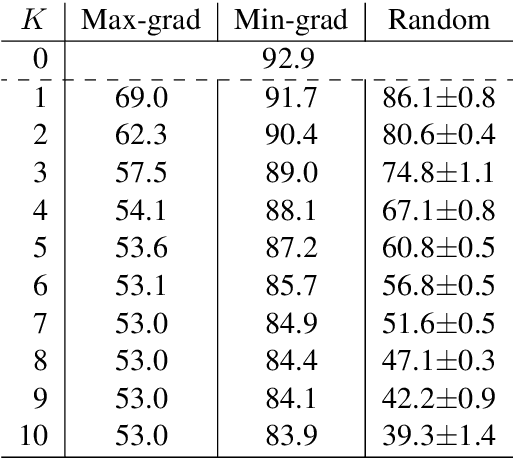
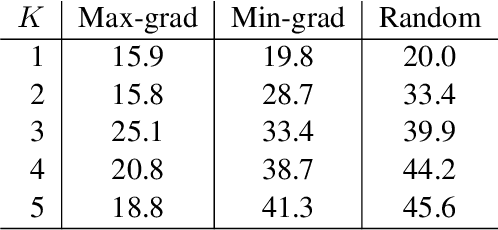
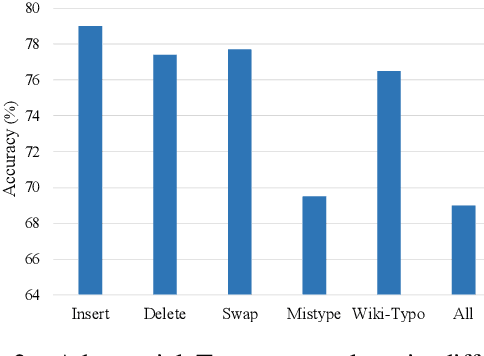
There is an increasing amount of literature that claims the brittleness of deep neural networks in dealing with adversarial examples that are created maliciously. It is unclear, however, how the models will perform in realistic scenarios where \textit{natural rather than malicious} adversarial instances often exist. This work systematically explores the robustness of BERT, the state-of-the-art Transformer-style model in NLP, in dealing with noisy data, particularly mistakes in typing the keyboard, that occur inadvertently. Intensive experiments on sentiment analysis and question answering benchmarks indicate that: (i) Typos in various words of a sentence do not influence equally. The typos in informative words make severer damages; (ii) Mistype is the most damaging factor, compared with inserting, deleting, etc.; (iii) Humans and machines have different focuses on recognizing adversarial attacks.