 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaRF: Differentiable Random Forest for Reaction Yield Prediction with a Few Trails
Aug 22, 2022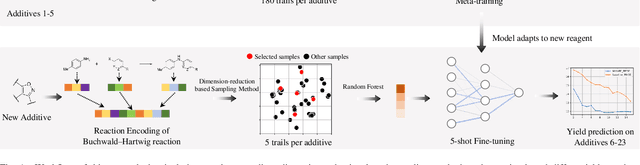
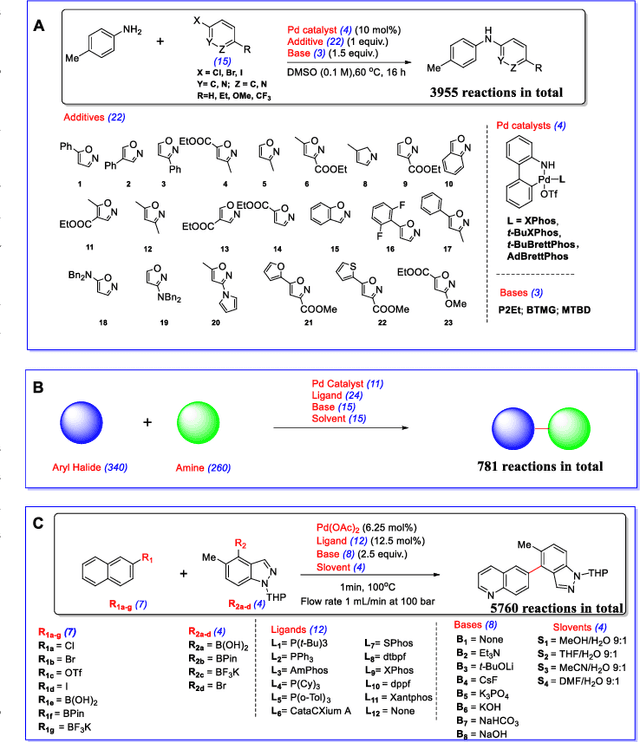
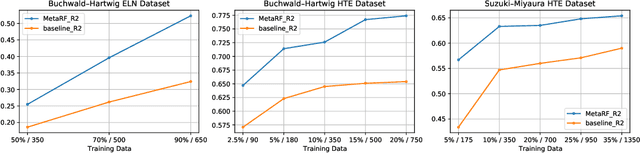
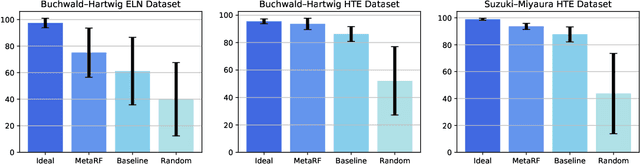
Artificial intelligence has deeply revolutionized the field of medicinal chemistry with many impressive applications, but the success of these applications requires a massive amount of training samples with high-quality annotations, which seriously limits the wide usage of data-driven methods. In this paper, we focus on the reaction yield prediction problem, which assists chemists in selecting high-yield reactions in a new chemical space only with a few experimental trials. To attack this challenge, we first put forth MetaRF, an attention-based differentiable random forest model specially designed for the few-shot yield prediction, where the attention weight of a random forest is automatically optimized by the meta-learning framework and can be quickly adapted to predict the performance of new reagents while given a few additional samples. To improve the few-shot learning performance, we further introduce a dimension-reduction based sampling method to determine valuable samples to be experimentally tested and then learned. Our methodology is evaluated on three different datasets and acquires satisfactory performance on few-shot prediction. In high-throughput experimentation (HTE) datasets, the average yield of our methodology's top 10 high-yield reactions is relatively close to the results of ideal yield selection.
Pseudo-label Guided Cross-video Pixel Contrast for Robotic Surgical Scene Segmentation with Limited Annotations
Jul 20, 2022



Surgical scene segmentation is fundamentally crucial for prompting cognitive assistance in robotic surgery. However, pixel-wise annotating surgical video in a frame-by-frame manner is expensive and time consuming. To greatly reduce the labeling burden, in this work, we study semi-supervised scene segmentation from robotic surgical video, which is practically essential yet rarely explored before. We consider a clinically suitable annotation situation under the equidistant sampling. We then propose PGV-CL, a novel pseudo-label guided cross-video contrast learning method to boost scene segmentation. It effectively leverages unlabeled data for a trusty and global model regularization that produces more discriminative feature representation. Concretely, for trusty representation learning, we propose to incorporate pseudo labels to instruct the pair selection, obtaining more reliable representation pairs for pixel contrast. Moreover, we expand the representation learning space from previous image-level to cross-video, which can capture the global semantics to benefit the learning process. We extensively evaluate our method on a public robotic surgery dataset EndoVis18 and a public cataract dataset CaDIS. Experimental results demonstrate the effectiveness of our method, consistently outperforming the state-of-the-art semi-supervised methods under different labeling ratios, and even surpassing fully supervised training on EndoVis18 with 10.1% labeling.
Instance Shadow Detection with A Single-Stage Detector
Jul 11, 2022



This paper formulates a new problem, instance shadow detection, which aims to detect shadow instance and the associated object instance that cast each shadow in the input image. To approach this task, we first compile a new dataset with the masks for shadow instances, object instances, and shadow-object associations. We then design an evaluation metric for quantitative evaluation of the performance of instance shadow detection. Further, we design a single-stage detector to perform instance shadow detection in an end-to-end manner, where the bidirectional relation learning module and the deformable maskIoU head are proposed in the detector to directly learn the relation between shadow instances and object instances and to improve the accuracy of the predicted masks. Finally, we quantitatively and qualitatively evaluate our method on the benchmark dataset of instance shadow detection and show the applicability of our method on light direction estimation and photo editing.
RePFormer: Refinement Pyramid Transformer for Robust Facial Landmark Detection
Jul 08, 2022
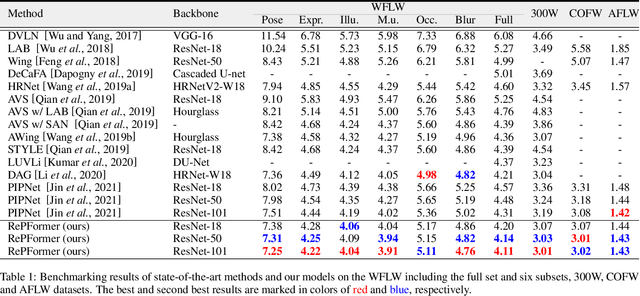
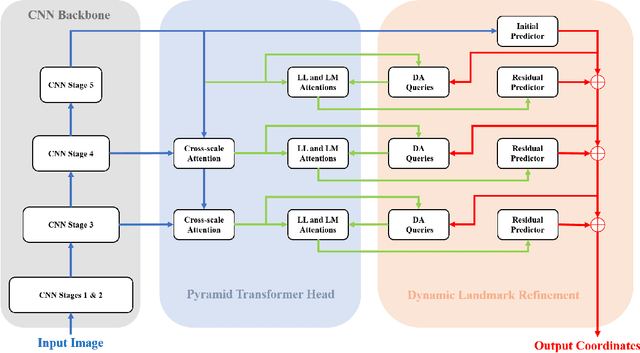
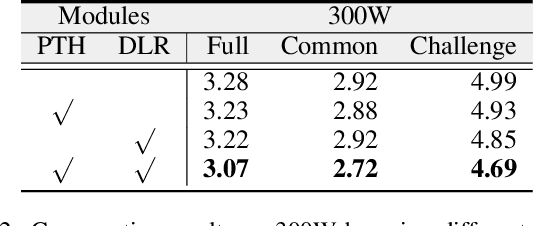
This paper presents a Refinement Pyramid Transformer (RePFormer) for robust facial landmark detection. Most facial landmark detectors focus on learning representative image features. However, these CNN-based feature representations are not robust enough to handle complex real-world scenarios due to ignoring the internal structure of landmarks, as well as the relations between landmarks and context. In this work, we formulate the facial landmark detection task as refining landmark queries along pyramid memories. Specifically, a pyramid transformer head (PTH) is introduced to build both homologous relations among landmarks and heterologous relations between landmarks and cross-scale contexts. Besides, a dynamic landmark refinement (DLR) module is designed to decompose the landmark regression into an end-to-end refinement procedure, where the dynamically aggregated queries are transformed to residual coordinates predictions. Extensive experimental results on four facial landmark detection benchmarks and their various subsets demonstrate the superior performance and high robustness of our framework.
ORF-Net: Deep Omni-supervised Rib Fracture Detection from Chest CT Scans
Jul 05, 2022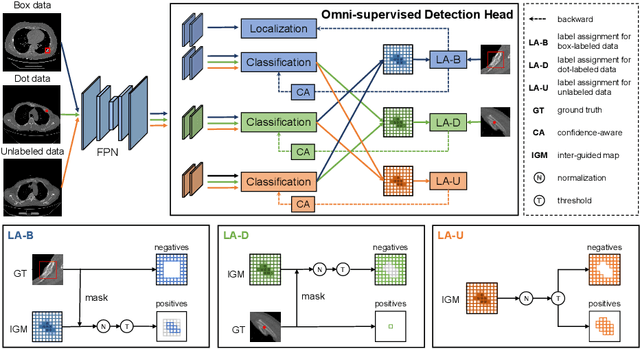
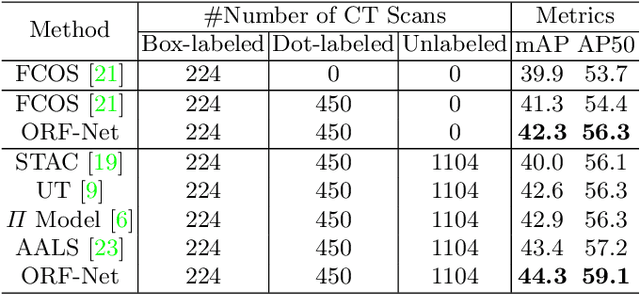
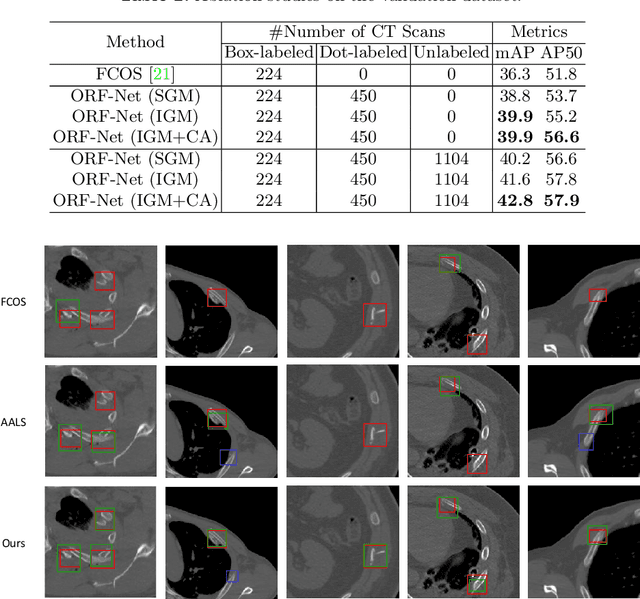
Most of the existing object detection works are based on the bounding box annotation: each object has a precise annotated box. However, for rib fractures, the bounding box annotation is very labor-intensive and time-consuming because radiologists need to investigate and annotate the rib fractures on a slice-by-slice basis. Although a few studies have proposed weakly-supervised methods or semi-supervised methods, they could not handle different forms of supervision simultaneously. In this paper, we proposed a novel omni-supervised object detection network, which can exploit multiple different forms of annotated data to further improve the detection performance. Specifically, the proposed network contains an omni-supervised detection head, in which each form of annotation data corresponds to a unique classification branch. Furthermore, we proposed a dynamic label assignment strategy for different annotated forms of data to facilitate better learning for each branch. Moreover, we also design a confidence-aware classification loss to emphasize the samples with high confidence and further improve the model's performance. Extensive experiments conducted on the testing dataset show our proposed method outperforms other state-of-the-art approaches consistently, demonstrating the efficacy of deep omni-supervised learning on improving rib fracture detection performance.
Single-domain Generalization in Medical Image Segmentation via Test-time Adaptation from Shape Dictionary
Jun 29, 2022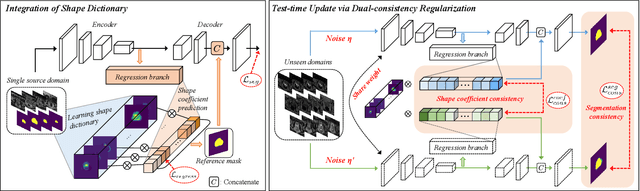
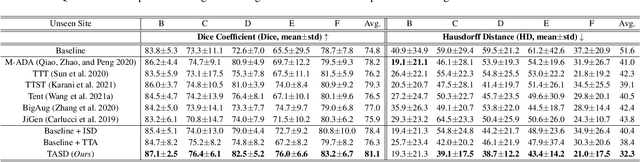

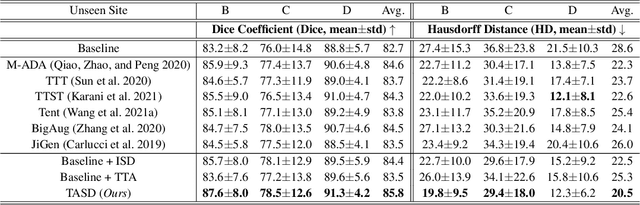
Domain generalization typically requires data from multiple source domains for model learning. However, such strong assumption may not always hold in practice, especially in medical field where the data sharing is highly concerned and sometimes prohibitive due to privacy issue. This paper studies the important yet challenging single domain generalization problem, in which a model is learned under the worst-case scenario with only one source domain to directly generalize to different unseen target domains. We present a novel approach to address this problem in medical image segmentation, which extracts and integrates the semantic shape prior information of segmentation that are invariant across domains and can be well-captured even from single domain data to facilitate segmentation under distribution shifts. Besides, a test-time adaptation strategy with dual-consistency regularization is further devised to promote dynamic incorporation of these shape priors under each unseen domain to improve model generalizability. Extensive experiments on two medical image segmentation tasks demonstrate the consistent improvements of our method across various unseen domains, as well as its superiority over state-of-the-art approaches in addressing domain generalization under the worst-case scenario.
Dynamic Bank Learning for Semi-supervised Federated Image Diagnosis with Class Imbalance
Jun 27, 2022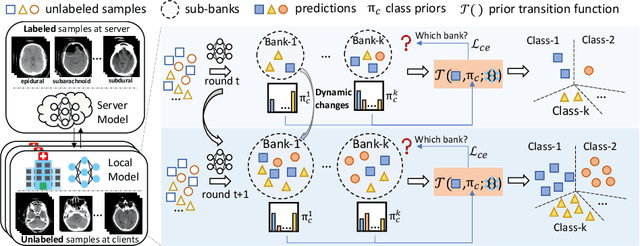
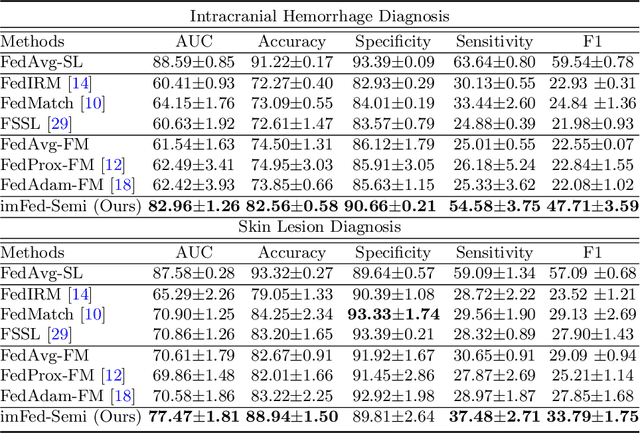
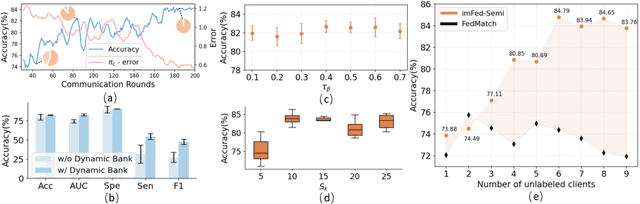
Despite recent progress on semi-supervised federated learning (FL) for medical image diagnosis, the problem of imbalanced class distributions among unlabeled clients is still unsolved for real-world use. In this paper, we study a practical yet challenging problem of class imbalanced semi-supervised FL (imFed-Semi), which allows all clients to have only unlabeled data while the server just has a small amount of labeled data. This imFed-Semi problem is addressed by a novel dynamic bank learning scheme, which improves client training by exploiting class proportion information. This scheme consists of two parts, i.e., the dynamic bank construction to distill various class proportions for each local client, and the sub-bank classification to impose the local model to learn different class proportions. We evaluate our approach on two public real-world medical datasets, including the intracranial hemorrhage diagnosis with 25,000 CT slices and skin lesion diagnosis with 10,015 dermoscopy images. The effectiveness of our method has been validated with significant performance improvements (7.61% and 4.69%) compared with the second-best on the accuracy, as well as comprehensive analytical studies. Code is available at https://github.com/med-air/imFedSemi.
Robust Medical Image Classification from Noisy Labeled Data with Global and Local Representation Guided Co-training
May 10, 2022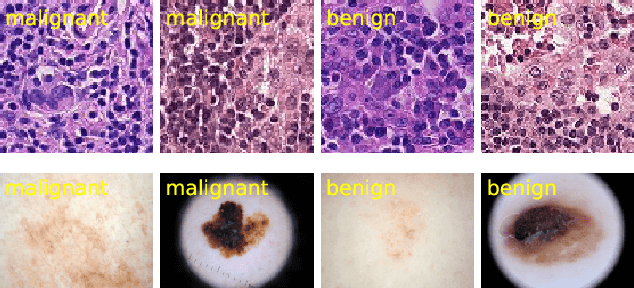
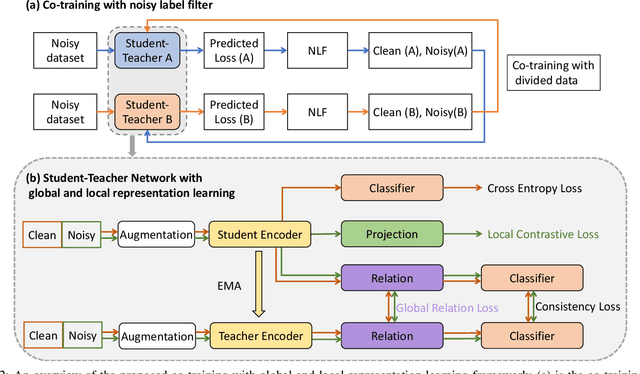
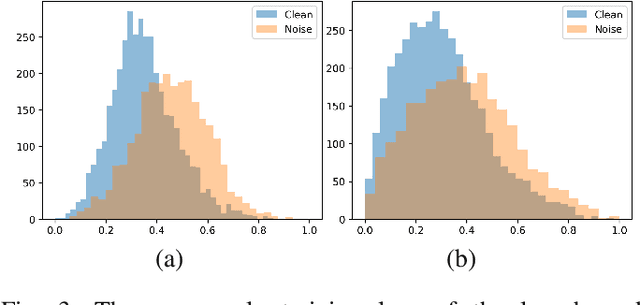
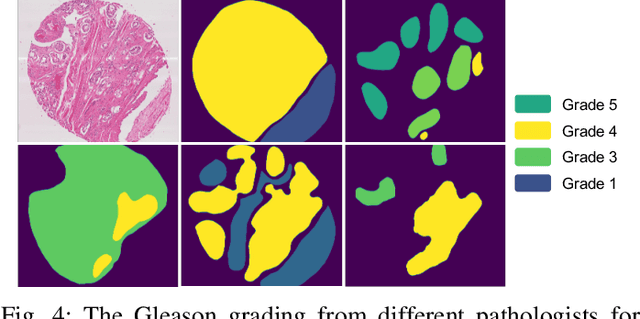
Deep neural networks have achieved remarkable success in a wide variety of natural image and medical image computing tasks. However, these achievements indispensably rely on accurately annotated training data. If encountering some noisy-labeled images, the network training procedure would suffer from difficulties, leading to a sub-optimal classifier. This problem is even more severe in the medical image analysis field, as the annotation quality of medical images heavily relies on the expertise and experience of annotators. In this paper, we propose a novel collaborative training paradigm with global and local representation learning for robust medical image classification from noisy-labeled data to combat the lack of high quality annotated medical data. Specifically, we employ the self-ensemble model with a noisy label filter to efficiently select the clean and noisy samples. Then, the clean samples are trained by a collaborative training strategy to eliminate the disturbance from imperfect labeled samples. Notably, we further design a novel global and local representation learning scheme to implicitly regularize the networks to utilize noisy samples in a self-supervised manner. We evaluated our proposed robust learning strategy on four public medical image classification datasets with three types of label noise,ie,random noise, computer-generated label noise, and inter-observer variability noise. Our method outperforms other learning from noisy label methods and we also conducted extensive experiments to analyze each component of our method.
3D Perception based Imitation Learning under Limited Demonstration for Laparoscope Control in Robotic Surgery
Apr 07, 2022
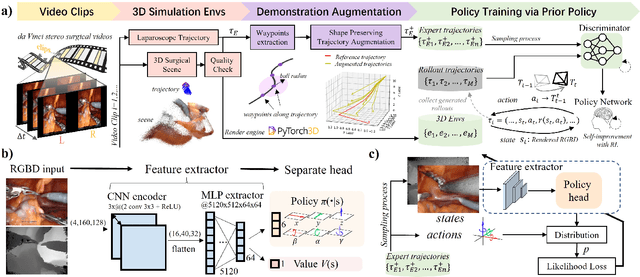
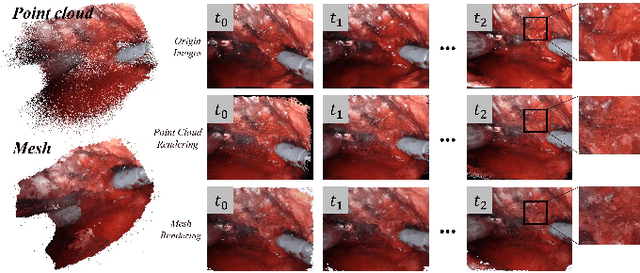
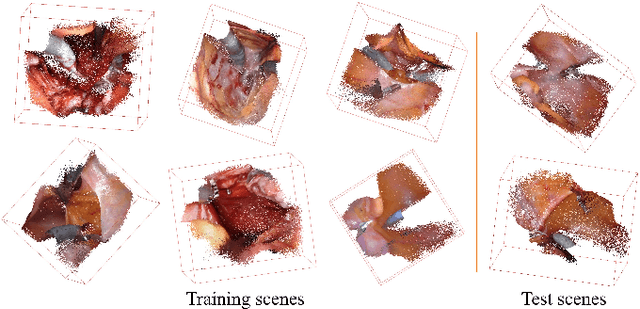
Automatic laparoscope motion control is fundamentally important for surgeons to efficiently perform operations. However, its traditional control methods based on tool tracking without considering information hidden in surgical scenes are not intelligent enough, while the latest supervised imitation learning (IL)-based methods require expensive sensor data and suffer from distribution mismatch issues caused by limited demonstrations. In this paper, we propose a novel Imitation Learning framework for Laparoscope Control (ILLC) with reinforcement learning (RL), which can efficiently learn the control policy from limited surgical video clips. Specially, we first extract surgical laparoscope trajectories from unlabeled videos as the demonstrations and reconstruct the corresponding surgical scenes. To fully learn from limited motion trajectory demonstrations, we propose Shape Preserving Trajectory Augmentation (SPTA) to augment these data, and build a simulation environment that supports parallel RGB-D rendering to reinforce the RL policy for interacting with the environment efficiently. With adversarial training for IL, we obtain the laparoscope control policy based on the generated rollouts and surgical demonstrations. Extensive experiments are conducted in unseen reconstructed surgical scenes, and our method outperforms the previous IL methods, which proves the feasibility of our unified learning-based framework for laparoscope control.
Acknowledging the Unknown for Multi-label Learning with Single Positive Labels
Mar 30, 2022
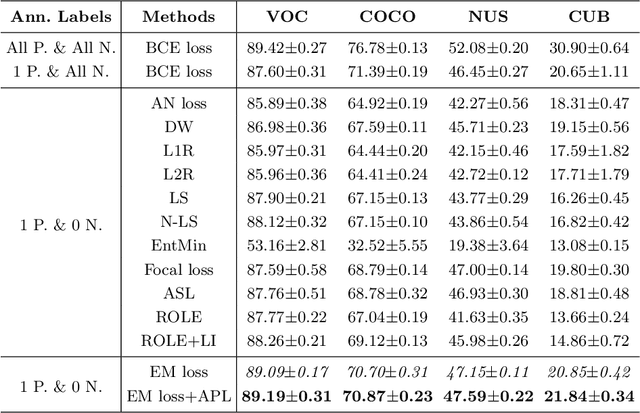
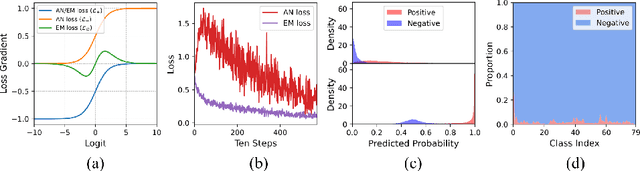

Due to the difficulty of collecting exhaustive multi-label annotations, multi-label training data often contains partial labels. We consider an extreme of this problem, called single positive multi-label learning (SPML), where each multi-label training image has only one positive label. Traditionally, all unannotated labels are assumed as negative labels in SPML, which would introduce false negative labels and make model training be dominated by assumed negative labels. In this work, we choose to treat all unannotated labels from a different perspective, \textit{i.e.} acknowledging they are unknown. Hence, we propose entropy-maximization (EM) loss to maximize the entropy of predicted probabilities for all unannotated labels. Considering the positive-negative label imbalance of unannotated labels, we propose asymmetric pseudo-labeling (APL) with asymmetric-tolerance strategies and a self-paced procedure to provide more precise supervision. Experiments show that our method significantly improves performance and achieves state-of-the-art results on all four benchmarks.