 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisfluency Detection using Auto-Correlational Neural Networks
Oct 28, 2018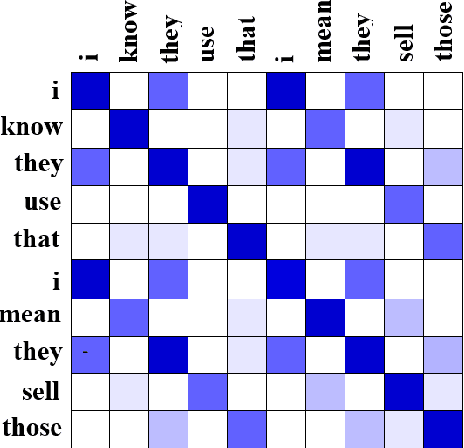
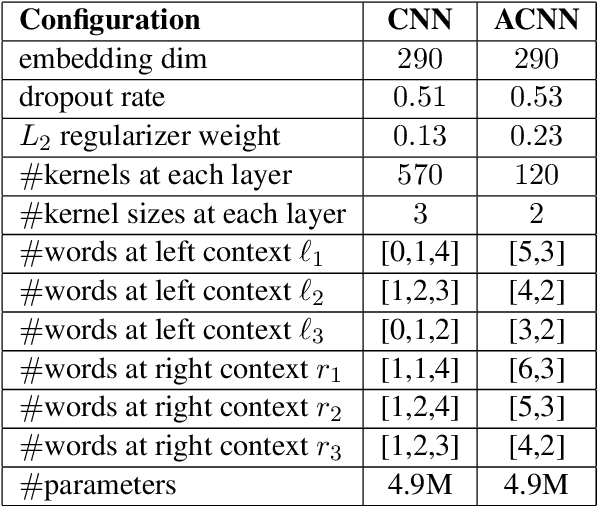
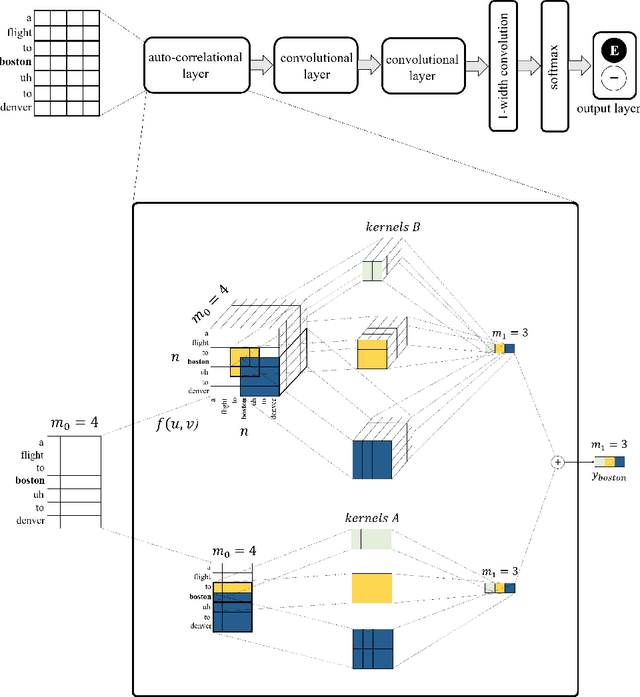
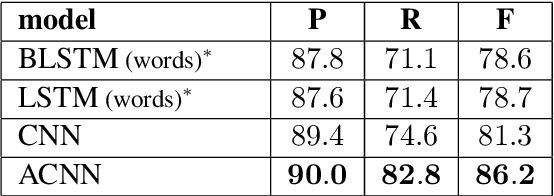
In recent years, the natural language processing community has moved away from task-specific feature engineering, i.e., researchers discovering ad-hoc feature representations for various tasks, in favor of general-purpose methods that learn the input representation by themselves. However, state-of-the-art approaches to disfluency detection in spontaneous speech transcripts currently still depend on an array of hand-crafted features, and other representations derived from the output of pre-existing systems such as language models or dependency parsers. As an alternative, this paper proposes a simple yet effective model for automatic disfluency detection, called an auto-correlational neural network (ACNN). The model uses a convolutional neural network (CNN) and augments it with a new auto-correlation operator at the lowest layer that can capture the kinds of "rough copy" dependencies that are characteristic of repair disfluencies in speech. In experiments, the ACNN model outperforms the baseline CNN on a disfluency detection task with a 5% increase in f-score, which is close to the previous best result on this task.
On Evaluation of Embodied Navigation Agents
Jul 18, 2018Skillful mobile operation in three-dimensional environments is a primary topic of study in Artificial Intelligence. The past two years have seen a surge of creative work on navigation. This creative output has produced a plethora of sometimes incompatible task definitions and evaluation protocols. To coordinate ongoing and future research in this area, we have convened a working group to study empirical methodology in navigation research. The present document summarizes the consensus recommendations of this working group. We discuss different problem statements and the role of generalization, present evaluation measures, and provide standard scenarios that can be used for benchmarking.
Face-Cap: Image Captioning using Facial Expression Analysis
Jul 06, 2018
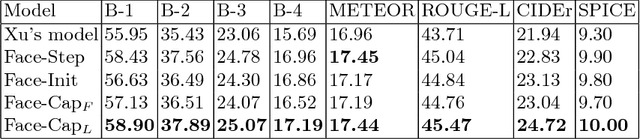
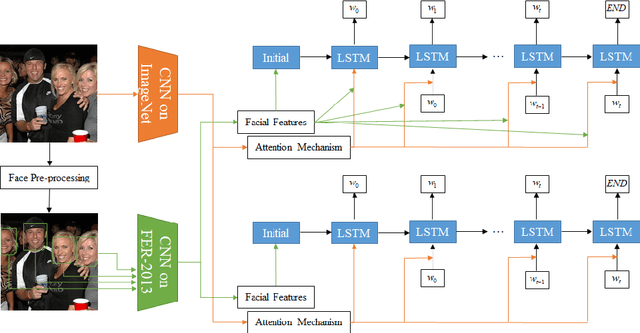
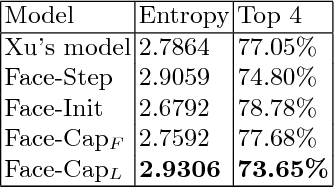
Image captioning is the process of generating a natural language description of an image. Most current image captioning models, however, do not take into account the emotional aspect of an image, which is very relevant to activities and interpersonal relationships represented therein. Towards developing a model that can produce human-like captions incorporating these, we use facial expression features extracted from images including human faces, with the aim of improving the descriptive ability of the model. In this work, we present two variants of our Face-Cap model, which embed facial expression features in different ways, to generate image captions. Using all standard evaluation metrics, our Face-Cap models outperform a state-of-the-art baseline model for generating image captions when applied to an image caption dataset extracted from the standard Flickr 30K dataset, consisting of around 11K images containing faces. An analysis of the captions finds that, perhaps surprisingly, the improvement in caption quality appears to come not from the addition of adjectives linked to emotional aspects of the images, but from more variety in the actions described in the captions.
Partially-Supervised Image Captioning
Jun 15, 2018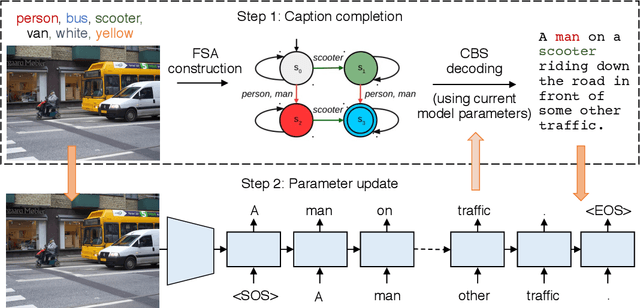
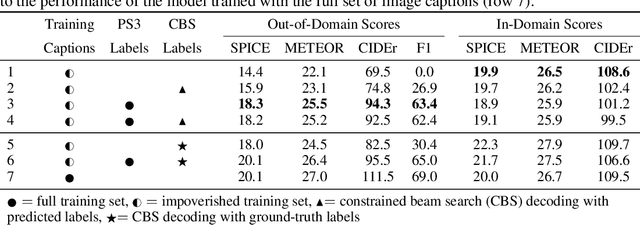
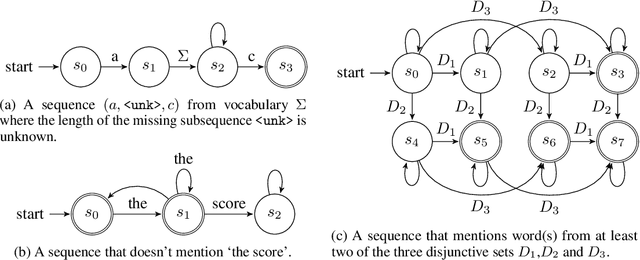
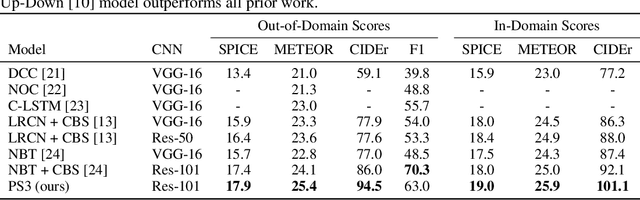
Image captioning models are becoming increasingly successful at describing the content of images in restricted domains. However, if these models are to function in the wild - for example, as aids for the visually impaired - a much larger number and variety of visual concepts must be understood. In this work, we teach image captioning models new visual concepts with partial supervision, such as available from object detection and image label datasets. As these datasets contain text fragments rather than complete captions, we formulate this problem as learning from incomplete data. To flexibly characterize our uncertainty about the unobserved complete sequence, we represent each incomplete training sequence with its own finite state automaton encoding acceptable complete sequences. We then propose a novel algorithm for training sequence models, such as recurrent neural networks, on incomplete sequences specified in this manner. In the context of image captioning, our method lifts the restriction that previously required image captioning models to be trained on paired image-sentence corpora only, or otherwise required specialized model architectures to take advantage of alternative data modalities. Applying our approach to an existing neural captioning model, we achieve state of the art results on the novel object captioning task using the COCO dataset. We further show that we can train a captioning model to describe new visual concepts from the Open Images dataset while maintaining competitive COCO evaluation scores.
Vision-and-Language Navigation: Interpreting visually-grounded navigation instructions in real environments
Apr 05, 2018
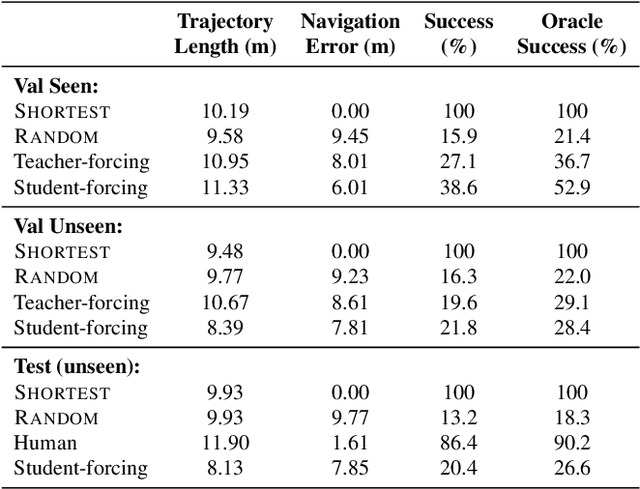
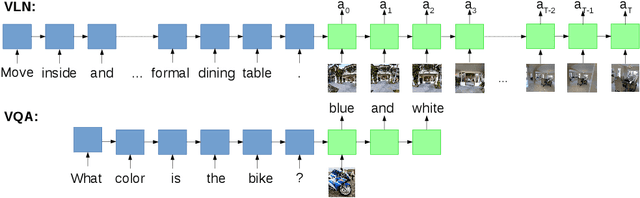

A robot that can carry out a natural-language instruction has been a dream since before the Jetsons cartoon series imagined a life of leisure mediated by a fleet of attentive robot helpers. It is a dream that remains stubbornly distant. However, recent advances in vision and language methods have made incredible progress in closely related areas. This is significant because a robot interpreting a natural-language navigation instruction on the basis of what it sees is carrying out a vision and language process that is similar to Visual Question Answering. Both tasks can be interpreted as visually grounded sequence-to-sequence translation problems, and many of the same methods are applicable. To enable and encourage the application of vision and language methods to the problem of interpreting visually-grounded navigation instructions, we present the Matterport3D Simulator -- a large-scale reinforcement learning environment based on real imagery. Using this simulator, which can in future support a range of embodied vision and language tasks, we provide the first benchmark dataset for visually-grounded natural language navigation in real buildings -- the Room-to-Room (R2R) dataset.
Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering
Mar 14, 2018



Top-down visual attention mechanisms have been used extensively in image captioning and visual question answering (VQA) to enable deeper image understanding through fine-grained analysis and even multiple steps of reasoning. In this work, we propose a combined bottom-up and top-down attention mechanism that enables attention to be calculated at the level of objects and other salient image regions. This is the natural basis for attention to be considered. Within our approach, the bottom-up mechanism (based on Faster R-CNN) proposes image regions, each with an associated feature vector, while the top-down mechanism determines feature weightings. Applying this approach to image captioning, our results on the MSCOCO test server establish a new state-of-the-art for the task, achieving CIDEr / SPICE / BLEU-4 scores of 117.9, 21.5 and 36.9, respectively. Demonstrating the broad applicability of the method, applying the same approach to VQA we obtain first place in the 2017 VQA Challenge.
Tips and Tricks for Visual Question Answering: Learnings from the 2017 Challenge
Aug 09, 2017
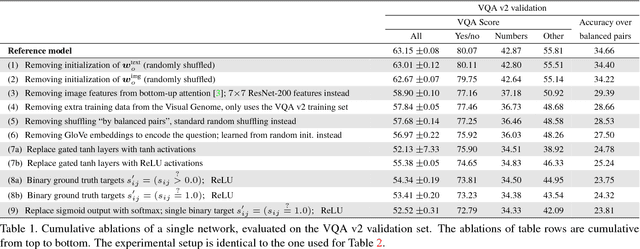

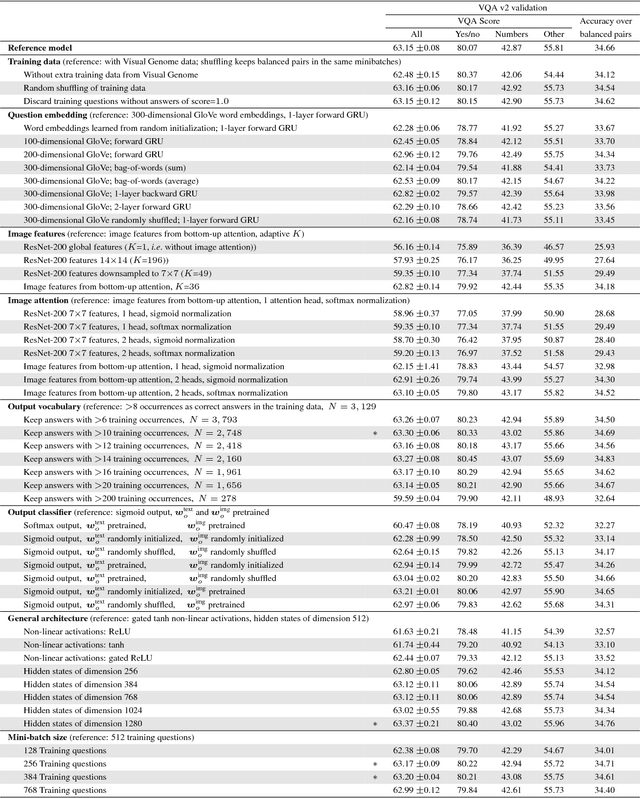
This paper presents a state-of-the-art model for visual question answering (VQA), which won the first place in the 2017 VQA Challenge. VQA is a task of significant importance for research in artificial intelligence, given its multimodal nature, clear evaluation protocol, and potential real-world applications. The performance of deep neural networks for VQA is very dependent on choices of architectures and hyperparameters. To help further research in the area, we describe in detail our high-performing, though relatively simple model. Through a massive exploration of architectures and hyperparameters representing more than 3,000 GPU-hours, we identified tips and tricks that lead to its success, namely: sigmoid outputs, soft training targets, image features from bottom-up attention, gated tanh activations, output embeddings initialized using GloVe and Google Images, large mini-batches, and smart shuffling of training data. We provide a detailed analysis of their impact on performance to assist others in making an appropriate selection.
Guided Open Vocabulary Image Captioning with Constrained Beam Search
Jul 19, 2017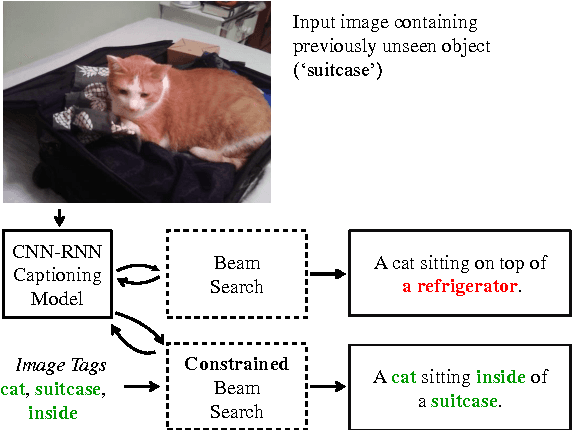
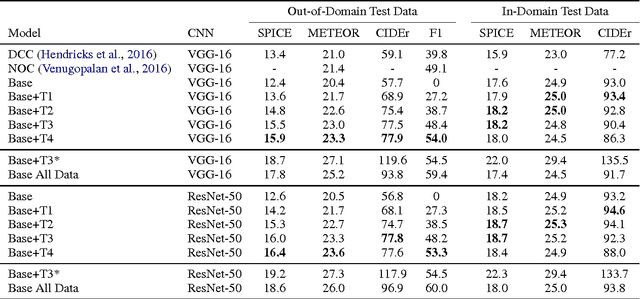
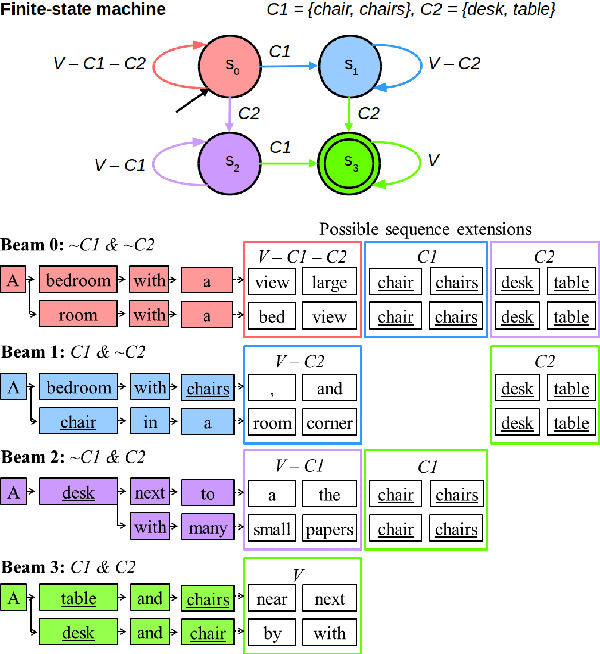

Existing image captioning models do not generalize well to out-of-domain images containing novel scenes or objects. This limitation severely hinders the use of these models in real world applications dealing with images in the wild. We address this problem using a flexible approach that enables existing deep captioning architectures to take advantage of image taggers at test time, without re-training. Our method uses constrained beam search to force the inclusion of selected tag words in the output, and fixed, pretrained word embeddings to facilitate vocabulary expansion to previously unseen tag words. Using this approach we achieve state of the art results for out-of-domain captioning on MSCOCO (and improved results for in-domain captioning). Perhaps surprisingly, our results significantly outperform approaches that incorporate the same tag predictions into the learning algorithm. We also show that we can significantly improve the quality of generated ImageNet captions by leveraging ground-truth labels.
SPICE: Semantic Propositional Image Caption Evaluation
Jul 29, 2016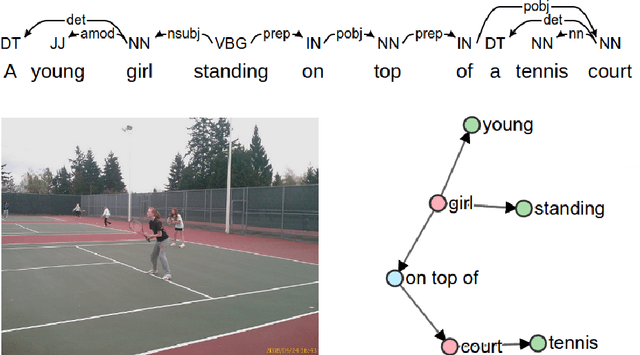
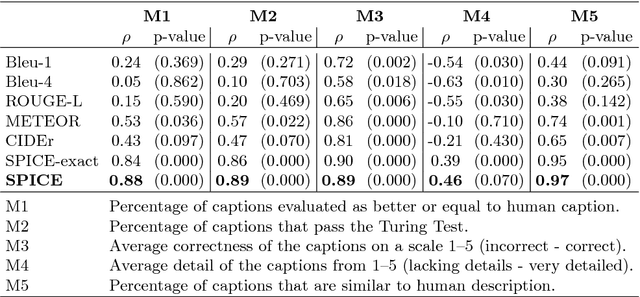
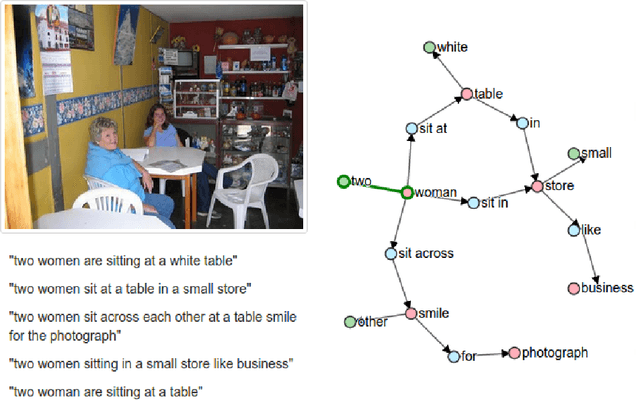
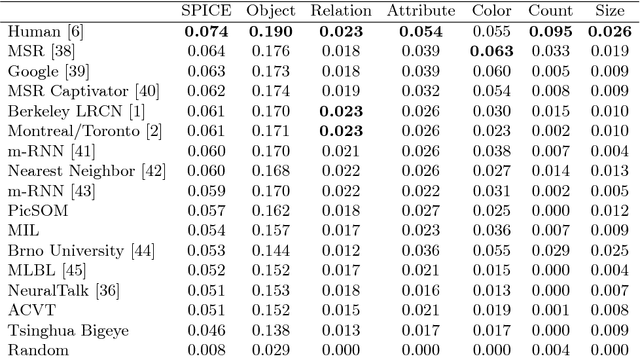
There is considerable interest in the task of automatically generating image captions. However, evaluation is challenging. Existing automatic evaluation metrics are primarily sensitive to n-gram overlap, which is neither necessary nor sufficient for the task of simulating human judgment. We hypothesize that semantic propositional content is an important component of human caption evaluation, and propose a new automated caption evaluation metric defined over scene graphs coined SPICE. Extensive evaluations across a range of models and datasets indicate that SPICE captures human judgments over model-generated captions better than other automatic metrics (e.g., system-level correlation of 0.88 with human judgments on the MS COCO dataset, versus 0.43 for CIDEr and 0.53 for METEOR). Furthermore, SPICE can answer questions such as `which caption-generator best understands colors?' and `can caption-generators count?'
On Differentiating Parameterized Argmin and Argmax Problems with Application to Bi-level Optimization
Jul 21, 2016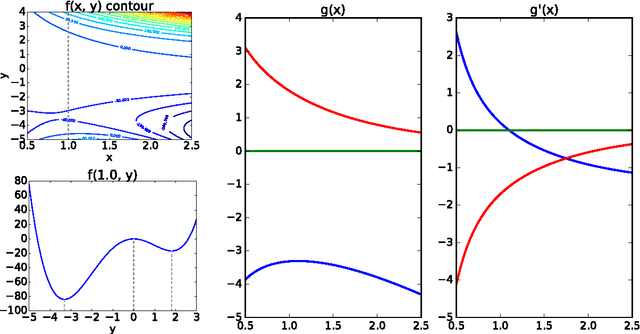
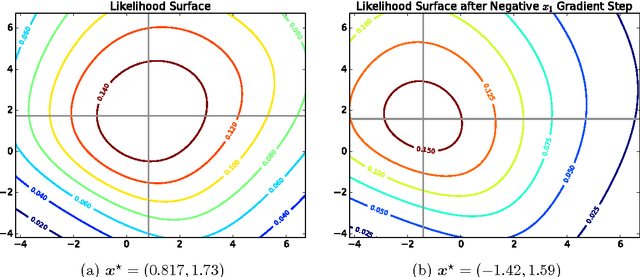
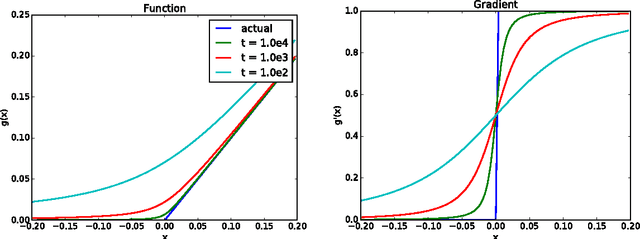
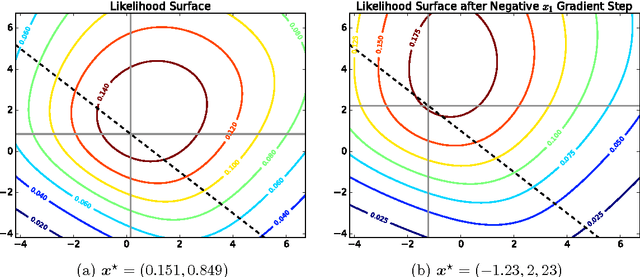
Some recent works in machine learning and computer vision involve the solution of a bi-level optimization problem. Here the solution of a parameterized lower-level problem binds variables that appear in the objective of an upper-level problem. The lower-level problem typically appears as an argmin or argmax optimization problem. Many techniques have been proposed to solve bi-level optimization problems, including gradient descent, which is popular with current end-to-end learning approaches. In this technical report we collect some results on differentiating argmin and argmax optimization problems with and without constraints and provide some insightful motivating examples.