 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupled Federated Learning for ASR with Non-IID Data
Jun 18, 2022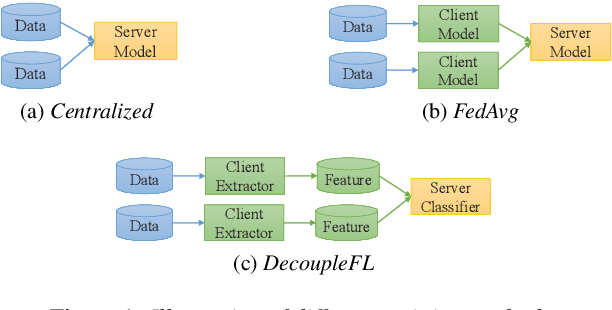
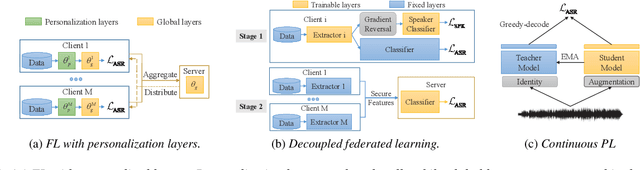
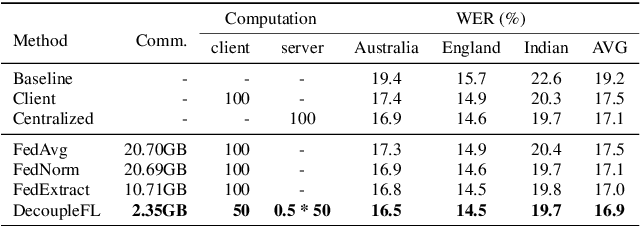
Automatic speech recognition (ASR) with federated learning (FL) makes it possible to leverage data from multiple clients without compromising privacy. The quality of FL-based ASR could be measured by recognition performance, communication and computation costs. When data among different clients are not independently and identically distributed (non-IID), the performance could degrade significantly. In this work, we tackle the non-IID issue in FL-based ASR with personalized FL, which learns personalized models for each client. Concretely, we propose two types of personalized FL approaches for ASR. Firstly, we adapt the personalization layer based FL for ASR, which keeps some layers locally to learn personalization models. Secondly, to reduce the communication and computation costs, we propose decoupled federated learning (DecoupleFL). On one hand, DecoupleFL moves the computation burden to the server, thus decreasing the computation on clients. On the other hand, DecoupleFL communicates secure high-level features instead of model parameters, thus reducing communication cost when models are large. Experiments demonstrate two proposed personalized FL-based ASR approaches could reduce WER by 2.3% - 3.4% compared with FedAvg. Among them, DecoupleFL has only 11.4% communication and 75% computation cost compared with FedAvg, which is also significantly less than the personalization layer based FL.
Streaming non-autoregressive model for any-to-many voice conversion
Jun 15, 2022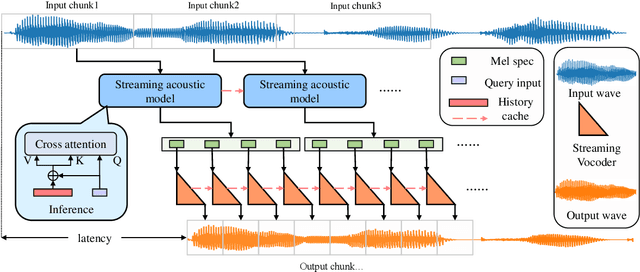
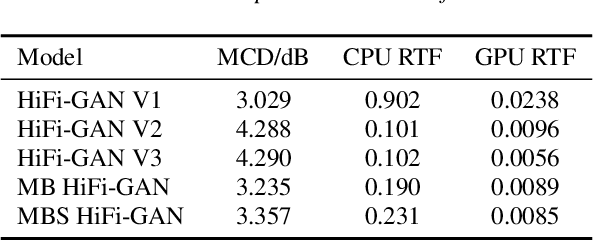
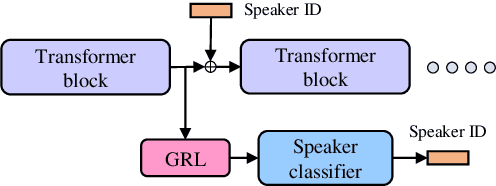
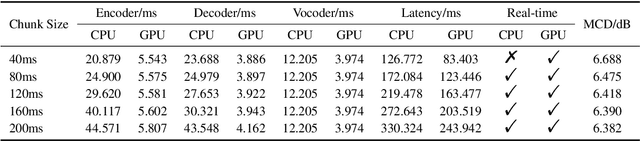
Voice conversion models have developed for decades, and current mainstream research focuses on non-streaming voice conversion. However, streaming voice conversion is more suitable for practical application scenarios than non-streaming voice conversion. In this paper, we propose a streaming any-to-many voice conversion based on fully non-autoregressive model, which includes a streaming transformer based acoustic model and a streaming vocoder. Streaming transformer based acoustic model is composed of a pre-trained encoder from streaming end-to-end based automatic speech recognition model and a decoder modified on FastSpeech blocks. Streaming vocoder is designed for streaming task with pseudo quadrature mirror filter bank and causal convolution. Experimental results show that the proposed method achieves significant performance both in latency and conversion quality and can be real-time on CPU and GPU.
Audio-Visual Scene Classification Using A Transfer Learning Based Joint Optimization Strategy
Apr 25, 2022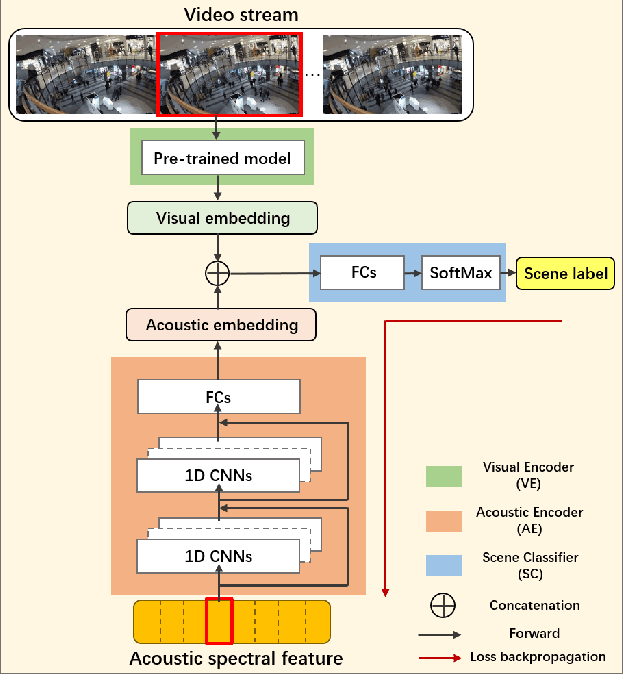


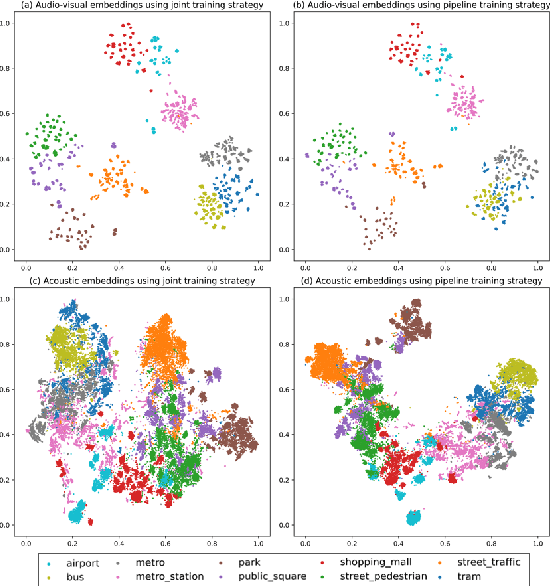
Recently, audio-visual scene classification (AVSC) has attracted increasing attention from multidisciplinary communities. Previous studies tended to adopt a pipeline training strategy, which uses well-trained visual and acoustic encoders to extract high-level representations (embeddings) first, then utilizes them to train the audio-visual classifier. In this way, the extracted embeddings are well suited for uni-modal classifiers, but not necessarily suited for multi-modal ones. In this paper, we propose a joint training framework, using the acoustic features and raw images directly as inputs for the AVSC task. Specifically, we retrieve the bottom layers of pre-trained image models as visual encoder, and jointly optimize the scene classifier and 1D-CNN based acoustic encoder during training. We evaluate the approach on the development dataset of TAU Urban Audio-Visual Scenes 2021. The experimental results show that our proposed approach achieves significant improvement over the conventional pipeline training strategy. Moreover, our best single system outperforms previous state-of-the-art methods, yielding a log loss of 0.1517 and accuracy of 94.59% on the official test fold.
Back-ends Selection for Deep Speaker Embeddings
Apr 25, 2022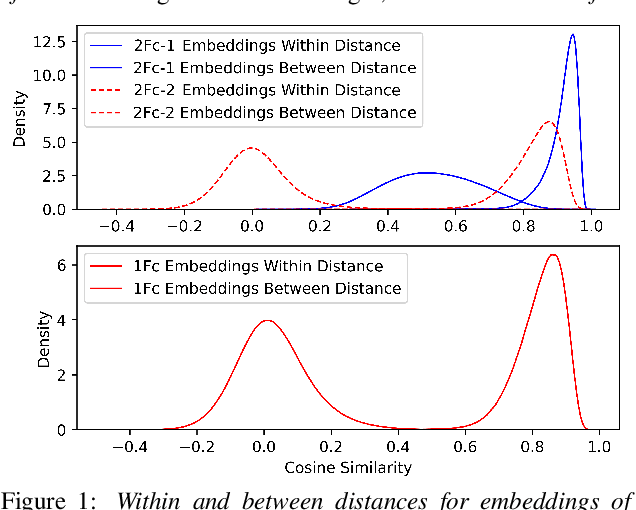
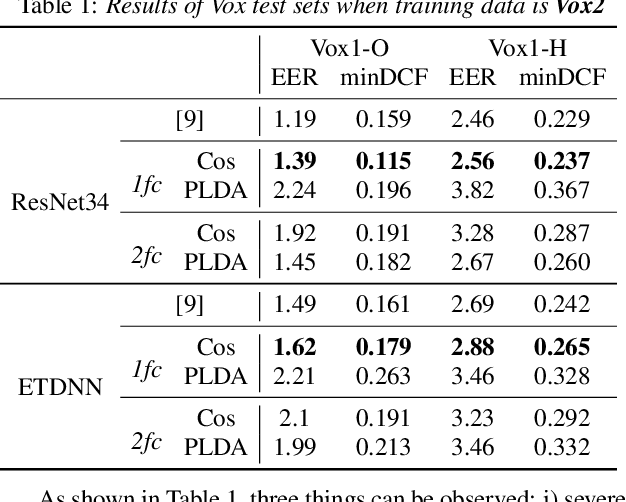
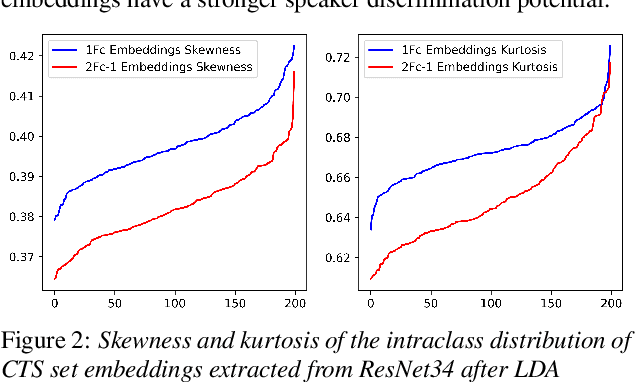
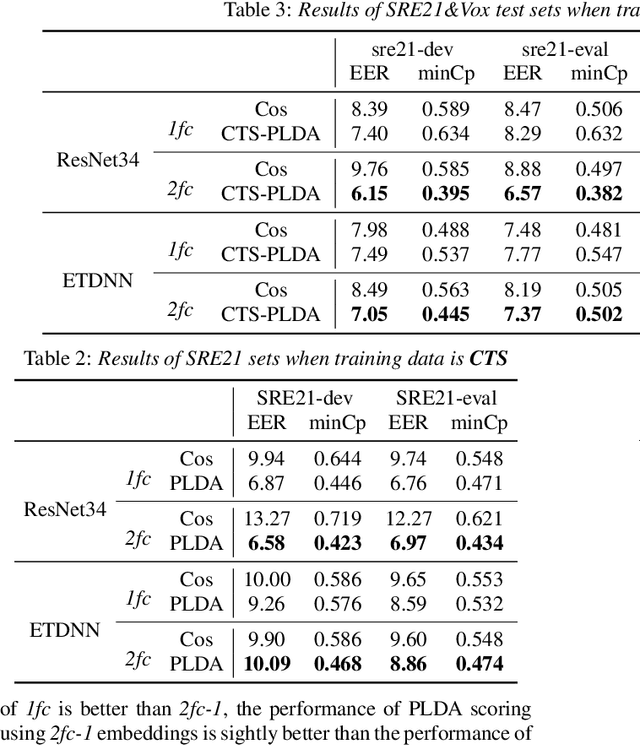
Probabilistic Linear Discriminant Analysis (PLDA) was the dominant and necessary back-end for early speaker recognition approaches, like i-vector and x-vector. However, with the development of neural networks and margin-based loss functions, we can obtain deep speaker embeddings (DSEs), which have advantages of increased inter-class separation and smaller intra-class distances. In this case, PLDA seems unnecessary or even counterproductive for the discriminative embeddings, and cosine similarity scoring (Cos) achieves better performance than PLDA in some situations. Motivated by this, in this paper, we systematically explore how to select back-ends (Cos or PLDA) for deep speaker embeddings to achieve better performance in different situations. By analyzing PLDA and the properties of DSEs extracted from models with different numbers of segment-level layers, we make the conjecture that Cos is better in same-domain situations and PLDA is better in cross-domain situations. We conduct experiments on VoxCeleb and NIST SRE datasets in four application situations, single-/multi-domain training and same-/cross-domain test, to validate our conjecture and briefly explain why back-ends adaption algorithms work.
CTA-RNN: Channel and Temporal-wise Attention RNN Leveraging Pre-trained ASR Embeddings for Speech Emotion Recognition
Mar 31, 2022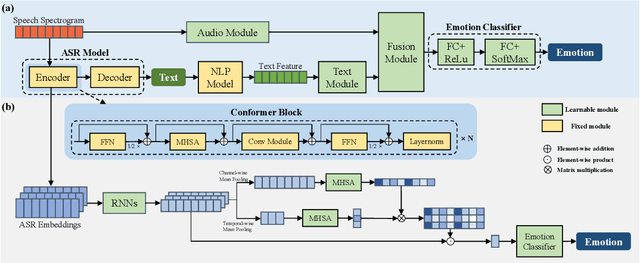

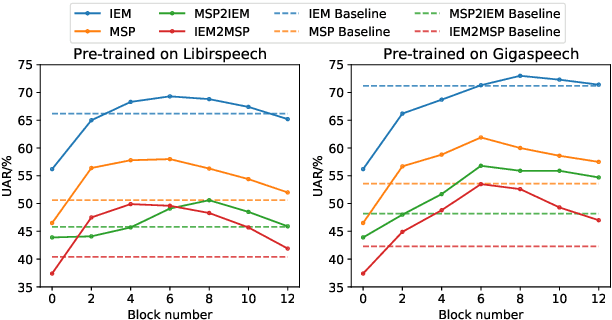
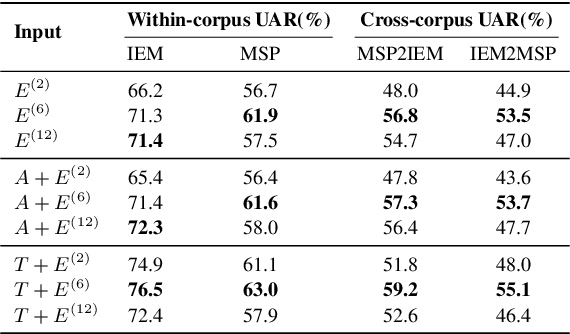
Previous research has looked into ways to improve speech emotion recognition (SER) by utilizing both acoustic and linguistic cues of speech. However, the potential association between state-of-the-art ASR models and the SER task has yet to be investigated. In this paper, we propose a novel channel and temporal-wise attention RNN (CTA-RNN) architecture based on the intermediate representations of pre-trained ASR models. Specifically, the embeddings of a large-scale pre-trained end-to-end ASR encoder contain both acoustic and linguistic information, as well as the ability to generalize to different speakers, making them well suited for downstream SER task. To further exploit the embeddings from different layers of the ASR encoder, we propose a novel CTA-RNN architecture to capture the emotional salient parts of embeddings in both the channel and temporal directions. We evaluate our approach on two popular benchmark datasets, IEMOCAP and MSP-IMPROV, using both within-corpus and cross-corpus settings. Experimental results show that our proposed method can achieve excellent performance in terms of accuracy and robustness.
Open Source MagicData-RAMC: A Rich Annotated Mandarin Conversational Speech Dataset
Mar 31, 2022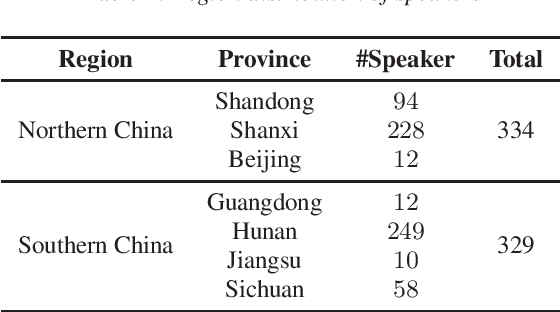
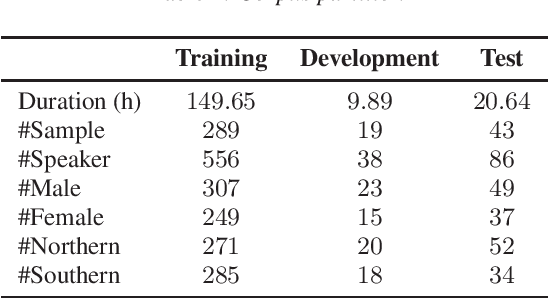
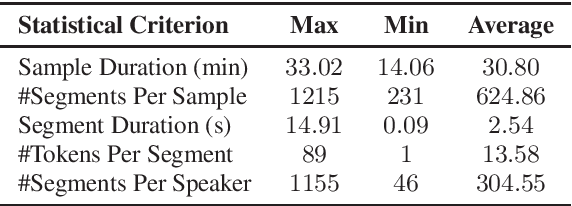
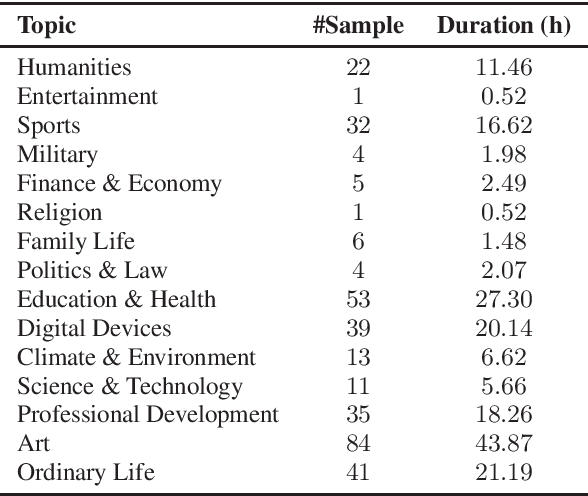
This paper introduces a high-quality rich annotated Mandarin conversational (RAMC) speech dataset called MagicData-RAMC. The MagicData-RAMC corpus contains 180 hours of conversational speech data recorded from native speakers of Mandarin Chinese over mobile phones with a sampling rate of 16 kHz. The dialogs in MagicData-RAMC are classified into 15 diversified domains and tagged with topic labels, ranging from science and technology to ordinary life. Accurate transcription and precise speaker voice activity timestamps are manually labeled for each sample. Speakers' detailed information is also provided. As a Mandarin speech dataset designed for dialog scenarios with high quality and rich annotations, MagicData-RAMC enriches the data diversity in the Mandarin speech community and allows extensive research on a series of speech-related tasks, including automatic speech recognition, speaker diarization, topic detection, keyword search, text-to-speech, etc. We also conduct several relevant tasks and provide experimental results to help evaluate the dataset.
Improving CTC-based speech recognition via knowledge transferring from pre-trained language models
Feb 22, 2022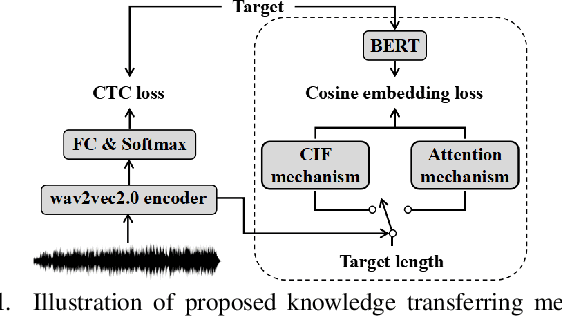
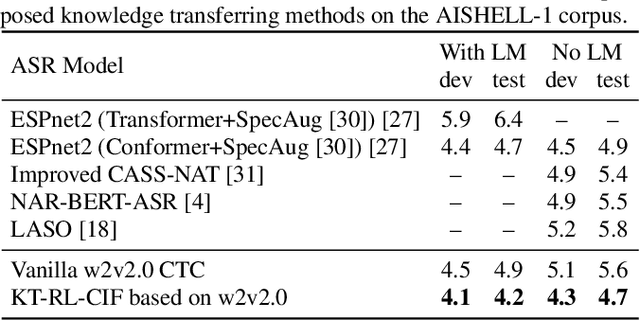
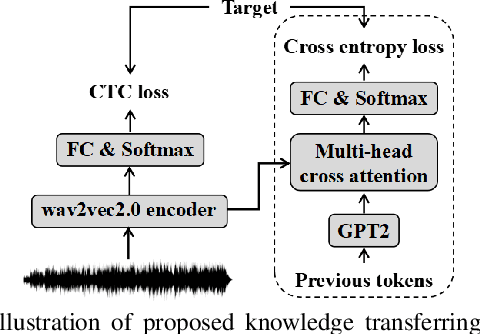
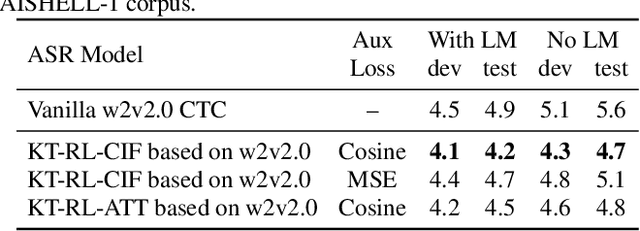
Recently, end-to-end automatic speech recognition models based on connectionist temporal classification (CTC) have achieved impressive results, especially when fine-tuned from wav2vec2.0 models. Due to the conditional independence assumption, CTC-based models are always weaker than attention-based encoder-decoder models and require the assistance of external language models (LMs). To solve this issue, we propose two knowledge transferring methods that leverage pre-trained LMs, such as BERT and GPT2, to improve CTC-based models. The first method is based on representation learning, in which the CTC-based models use the representation produced by BERT as an auxiliary learning target. The second method is based on joint classification learning, which combines GPT2 for text modeling with a hybrid CTC/attention architecture. Experiment on AISHELL-1 corpus yields a character error rate (CER) of 4.2% on the test set. When compared to the vanilla CTC-based models fine-tuned from the wav2vec2.0 models, our knowledge transferring method reduces CER by 16.1% relatively without external LMs.
The HCCL-DKU system for fake audio generation task of the 2022 ICASSP ADD Challenge
Jan 29, 2022The voice conversion task is to modify the speaker identity of continuous speech while preserving the linguistic content. Generally, the naturalness and similarity are two main metrics for evaluating the conversion quality, which has been improved significantly in recent years. This paper presents the HCCL-DKU entry for the fake audio generation task of the 2022 ICASSP ADD challenge. We propose a novel ppg-based voice conversion model that adopts a fully end-to-end structure. Experimental results show that the proposed method outperforms other conversion models, including Tacotron-based and Fastspeech-based models, on conversion quality and spoofing performance against anti-spoofing systems. In addition, we investigate several post-processing methods for better spoofing power. Finally, we achieve second place with a deception success rate of 0.916 in the ADD challenge.
Improving non-autoregressive end-to-end speech recognition with pre-trained acoustic and language models
Jan 26, 2022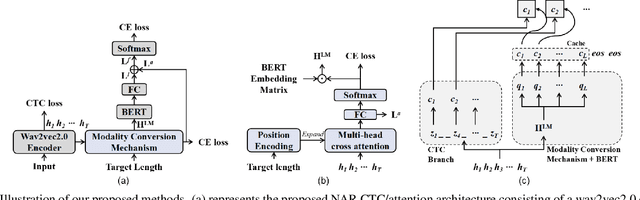
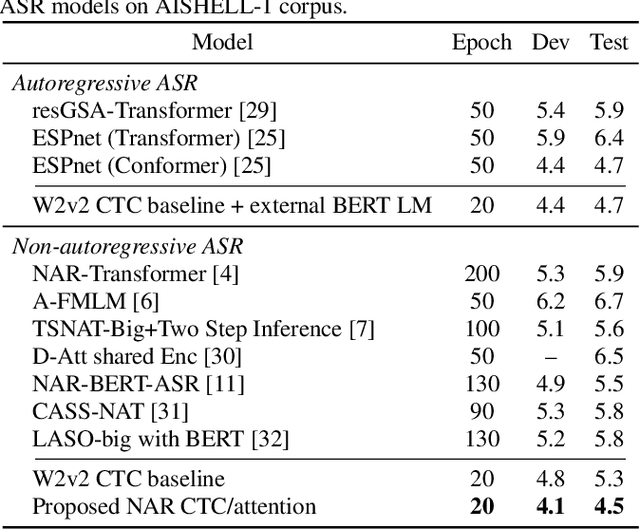
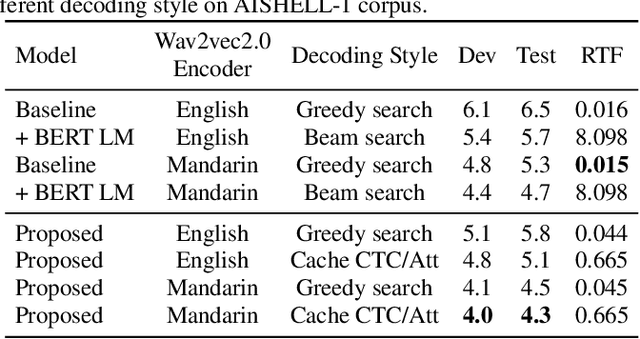
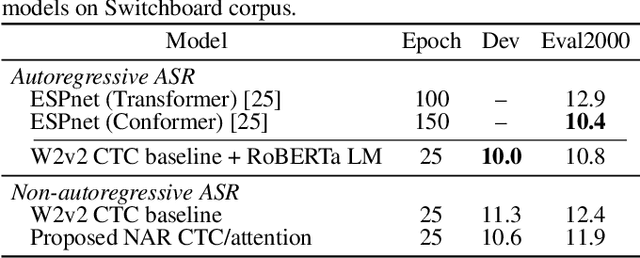
While Transformers have achieved promising results in end-to-end (E2E) automatic speech recognition (ASR), their autoregressive (AR) structure becomes a bottleneck for speeding up the decoding process. For real-world deployment, ASR systems are desired to be highly accurate while achieving fast inference. Non-autoregressive (NAR) models have become a popular alternative due to their fast inference speed, but they still fall behind AR systems in recognition accuracy. To fulfill the two demands, in this paper, we propose a NAR CTC/attention model utilizing both pre-trained acoustic and language models: wav2vec2.0 and BERT. To bridge the modality gap between speech and text representations obtained from the pre-trained models, we design a novel modality conversion mechanism, which is more suitable for logographic languages. During inference, we employ a CTC branch to generate a target length, which enables the BERT to predict tokens in parallel. We also design a cache-based CTC/attention joint decoding method to improve the recognition accuracy while keeping the decoding speed fast. Experimental results show that the proposed NAR model greatly outperforms our strong wav2vec2.0 CTC baseline (15.1% relative CER reduction on AISHELL-1). The proposed NAR model significantly surpasses previous NAR systems on the AISHELL-1 benchmark and shows a potential for English tasks.
Data Augmentation based Consistency Contrastive Pre-training for Automatic Speech Recognition
Dec 23, 2021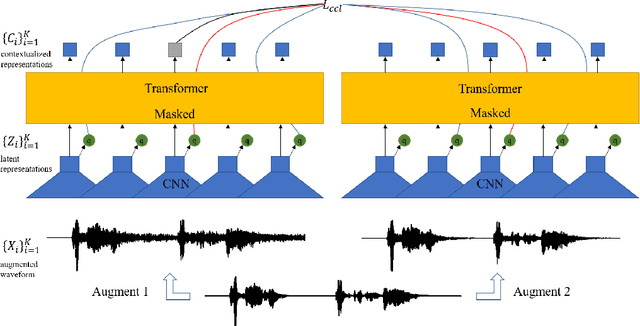
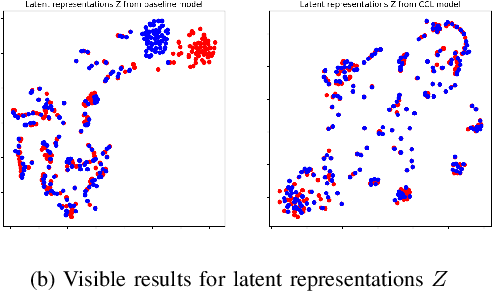
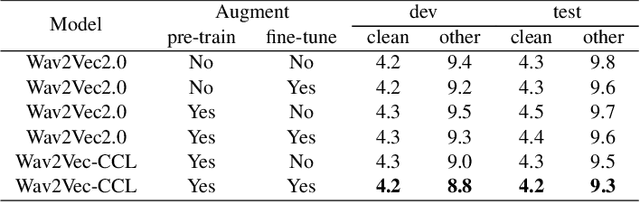
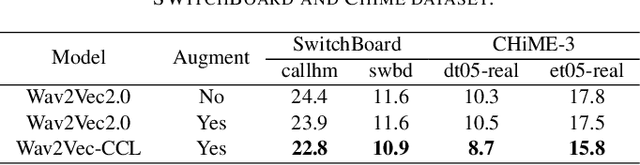
Self-supervised acoustic pre-training has achieved amazing results on the automatic speech recognition (ASR) task. Most of the successful acoustic pre-training methods use contrastive learning to learn the acoustic representations by distinguish the representations from different time steps, ignoring the speaker and environment robustness. As a result, the pre-trained model could show poor performance when meeting out-of-domain data during fine-tuning. In this letter, we design a novel consistency contrastive learning (CCL) method by utilizing data augmentation for acoustic pre-training. Different kinds of augmentation are applied on the original audios and then the augmented audios are fed into an encoder. The encoder should not only contrast the representations within one audio but also maximize the measurement of the representations across different augmented audios. By this way, the pre-trained model can learn a text-related representation method which is more robust with the change of the speaker or the environment.Experiments show that by applying the CCL method on the Wav2Vec2.0, better results can be realized both on the in-domain data and the out-of-domain data. Especially for noisy out-of-domain data, more than 15% relative improvement can be obtained.