 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCANet: Curved Guide Line Network with Adaptive Decoder for Lane Detection
Apr 23, 2023



Lane detection is challenging due to the complicated on road scenarios and line deformation from different camera perspectives. Lots of solutions were proposed, but can not deal with corner lanes well. To address this problem, this paper proposes a new top-down deep learning lane detection approach, CANET. A lane instance is first responded by the heat-map on the U-shaped curved guide line at global semantic level, thus the corresponding features of each lane are aggregated at the response point. Then CANET obtains the heat-map response of the entire lane through conditional convolution, and finally decodes the point set to describe lanes via adaptive decoder. The experimental results show that CANET reaches SOTA in different metrics. Our code will be released soon.
S4OD: Semi-Supervised learning for Single-Stage Object Detection
Apr 09, 2022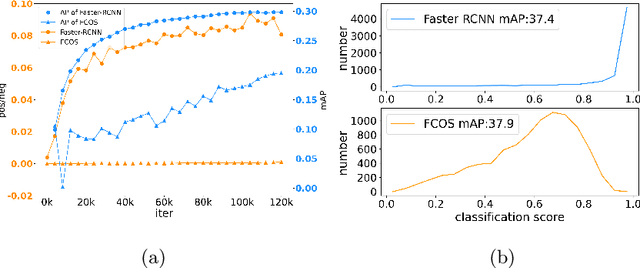
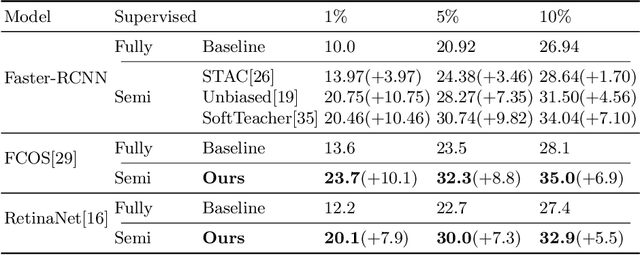
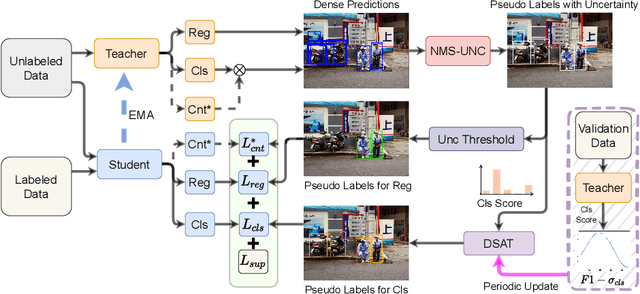

Single-stage detectors suffer from extreme foreground-background class imbalance, while two-stage detectors do not. Therefore, in semi-supervised object detection, two-stage detectors can deliver remarkable performance by only selecting high-quality pseudo labels based on classification scores. However, directly applying this strategy to single-stage detectors would aggravate the class imbalance with fewer positive samples. Thus, single-stage detectors have to consider both quality and quantity of pseudo labels simultaneously. In this paper, we design a dynamic self-adaptive threshold (DSAT) strategy in classification branch, which can automatically select pseudo labels to achieve an optimal trade-off between quality and quantity. Besides, to assess the regression quality of pseudo labels in single-stage detectors, we propose a module to compute the regression uncertainty of boxes based on Non-Maximum Suppression. By leveraging only 10% labeled data from COCO, our method achieves 35.0% AP on anchor-free detector (FCOS) and 32.9% on anchor-based detector (RetinaNet).
A Critical Analysis of Image-based Camera Pose Estimation Techniques
Jan 15, 2022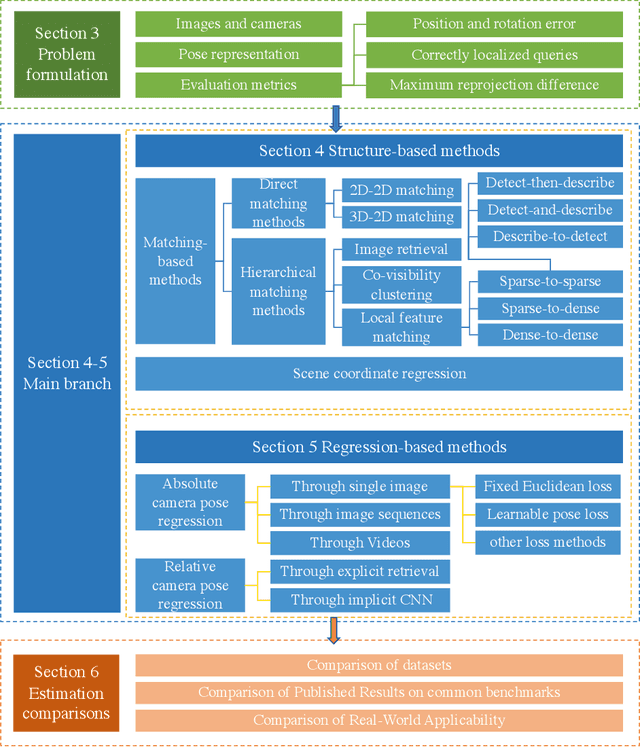
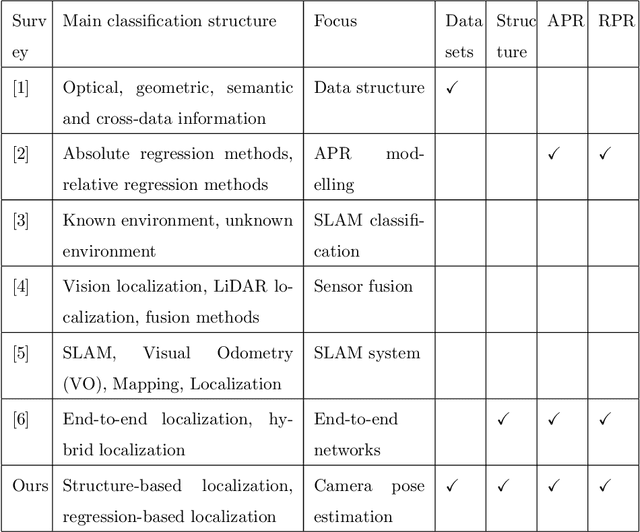
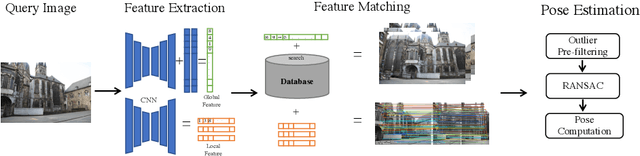
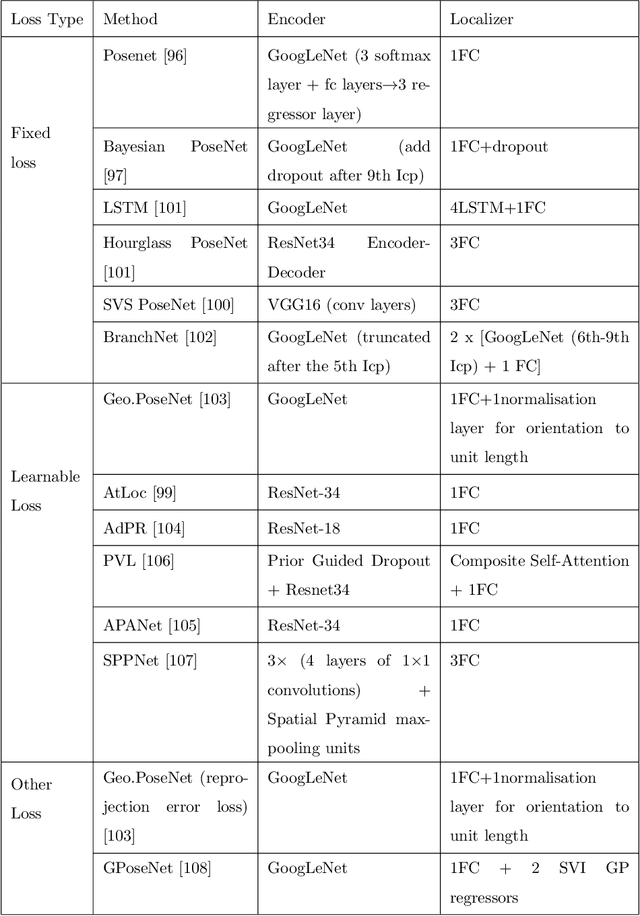
Camera, and associated with its objects within the field of view, localization could benefit many computer vision fields, such as autonomous driving, robot navigation, and augmented reality (AR). In this survey, we first introduce specific application areas and the evaluation metrics for camera localization pose according to different sub-tasks (learning-based 2D-2D task, feature-based 2D-3D task, and 3D-3D task). Then, we review common methods for structure-based camera pose estimation approaches, absolute pose regression and relative pose regression approaches by critically modelling the methods to inspire further improvements in their algorithms such as loss functions, neural network structures. Furthermore, we summarise what are the popular datasets used for camera localization and compare the quantitative and qualitative results of these methods with detailed performance metrics. Finally, we discuss future research possibilities and applications.
2nd Place Solution for VisDA 2021 Challenge -- Universally Domain Adaptive Image Recognition
Oct 27, 2021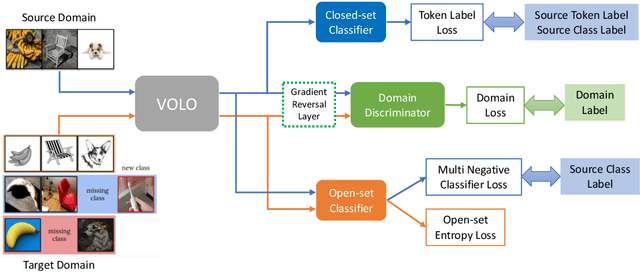
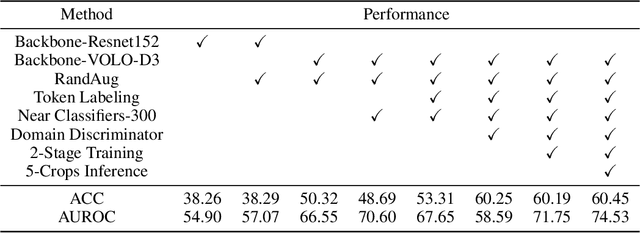
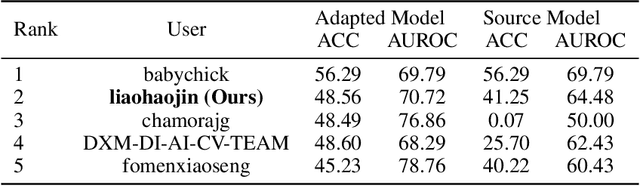
The Visual Domain Adaptation (VisDA) 2021 Challenge calls for unsupervised domain adaptation (UDA) methods that can deal with both input distribution shift and label set variance between the source and target domains. In this report, we introduce a universal domain adaptation (UniDA) method by aggregating several popular feature extraction and domain adaptation schemes. First, we utilize VOLO, a Transformer-based architecture with state-of-the-art performance in several visual tasks, as the backbone to extract effective feature representations. Second, we modify the open-set classifier of OVANet to recognize the unknown class with competitive accuracy and robustness. As shown in the leaderboard, our proposed UniDA method ranks the 2nd place with 48.56% ACC and 70.72% AUROC in the VisDA 2021 Challenge.
Multi-Source Domain Adaptation for Object Detection
Jun 30, 2021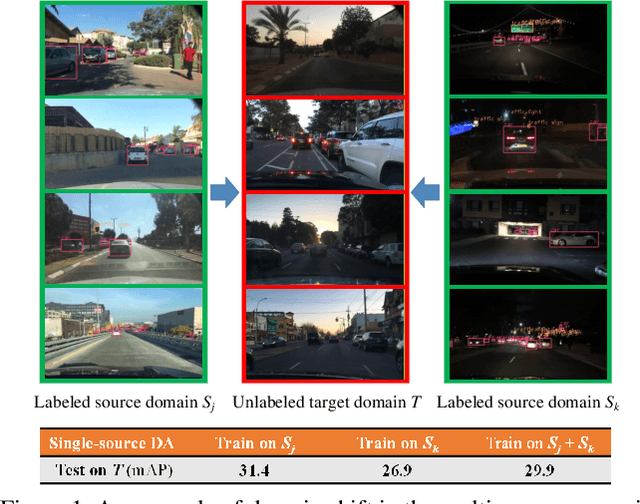
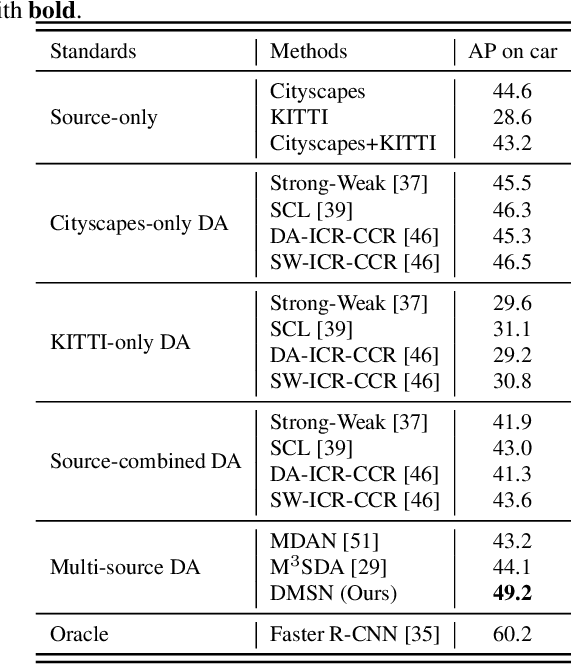
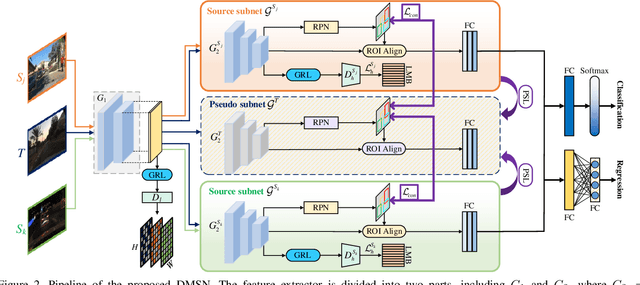
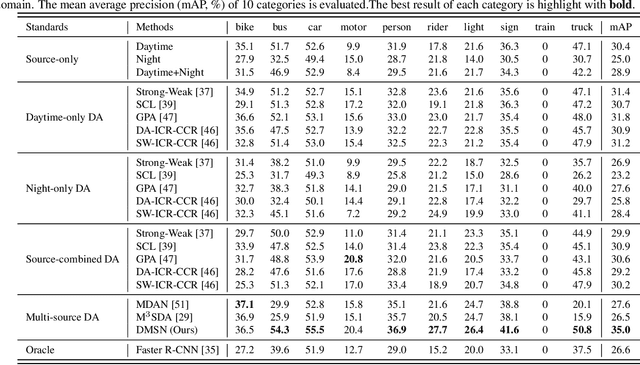
To reduce annotation labor associated with object detection, an increasing number of studies focus on transferring the learned knowledge from a labeled source domain to another unlabeled target domain. However, existing methods assume that the labeled data are sampled from a single source domain, which ignores a more generalized scenario, where labeled data are from multiple source domains. For the more challenging task, we propose a unified Faster R-CNN based framework, termed Divide-and-Merge Spindle Network (DMSN), which can simultaneously enhance domain invariance and preserve discriminative power. Specifically, the framework contains multiple source subnets and a pseudo target subnet. First, we propose a hierarchical feature alignment strategy to conduct strong and weak alignments for low- and high-level features, respectively, considering their different effects for object detection. Second, we develop a novel pseudo subnet learning algorithm to approximate optimal parameters of pseudo target subset by weighted combination of parameters in different source subnets. Finally, a consistency regularization for region proposal network is proposed to facilitate each subnet to learn more abstract invariances. Extensive experiments on different adaptation scenarios demonstrate the effectiveness of the proposed model.
2nd Place Solution for Waymo Open Dataset Challenge -- Real-time 2D Object Detection
Jun 16, 2021
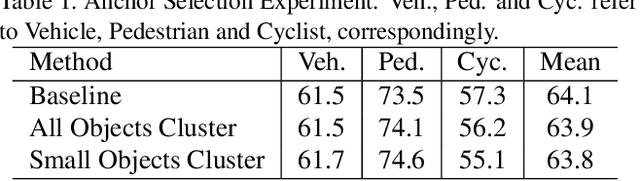
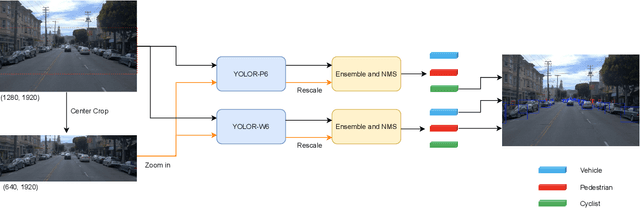
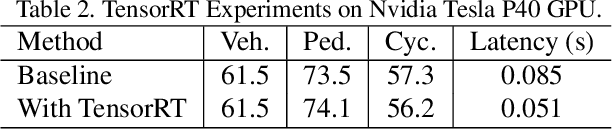
In an autonomous driving system, it is essential to recognize vehicles, pedestrians and cyclists from images. Besides the high accuracy of the prediction, the requirement of real-time running brings new challenges for convolutional network models. In this report, we introduce a real-time method to detect the 2D objects from images. We aggregate several popular one-stage object detectors and train the models of variety input strategies independently, to yield better performance for accurate multi-scale detection of each category, especially for small objects. For model acceleration, we leverage TensorRT to optimize the inference time of our detection pipeline. As shown in the leaderboard, our proposed detection framework ranks the 2nd place with 75.00% L1 mAP and 69.72% L2 mAP in the real-time 2D detection track of the Waymo Open Dataset Challenges, while our framework achieves the latency of 45.8ms/frame on an Nvidia Tesla V100 GPU.
Scene Graphs: A Survey of Generations and Applications
Mar 17, 2021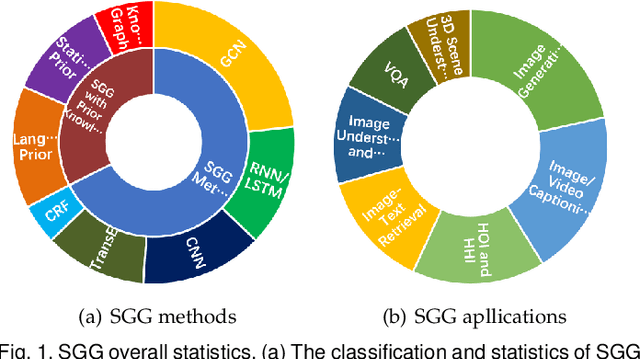

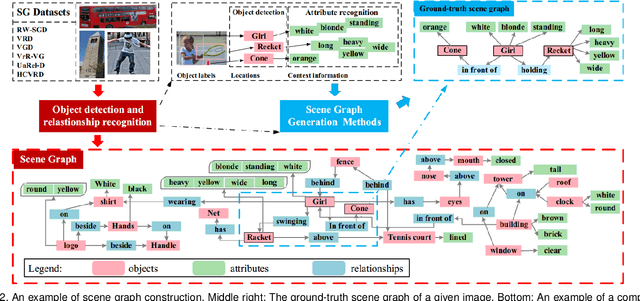
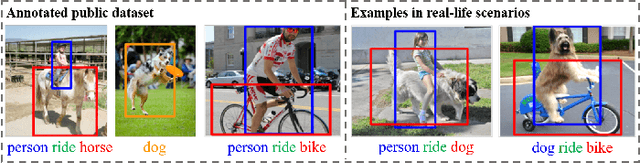
Scene graph is a structured representation of a scene that can clearly express the objects, attributes, and relationships between objects in the scene. As computer vision technology continues to develop, people are no longer satisfied with simply detecting and recognizing objects in images; instead, people look forward to a higher level of understanding and reasoning about visual scenes. For example, given an image, we want to not only detect and recognize objects in the image, but also know the relationship between objects (visual relationship detection), and generate a text description (image captioning) based on the image content. Alternatively, we might want the machine to tell us what the little girl in the image is doing (Visual Question Answering (VQA)), or even remove the dog from the image and find similar images (image editing and retrieval), etc. These tasks require a higher level of understanding and reasoning for image vision tasks. The scene graph is just such a powerful tool for scene understanding. Therefore, scene graphs have attracted the attention of a large number of researchers, and related research is often cross-modal, complex, and rapidly developing. However, no relatively systematic survey of scene graphs exists at present. To this end, this survey conducts a comprehensive investigation of the current scene graph research. More specifically, we first summarized the general definition of the scene graph, then conducted a comprehensive and systematic discussion on the generation method of the scene graph (SGG) and the SGG with the aid of prior knowledge. We then investigated the main applications of scene graphs and summarized the most commonly used datasets. Finally, we provide some insights into the future development of scene graphs. We believe this will be a very helpful foundation for future research on scene graphs.
Communication-efficient Byzantine-robust distributed learning with statistical guarantee
Feb 28, 2021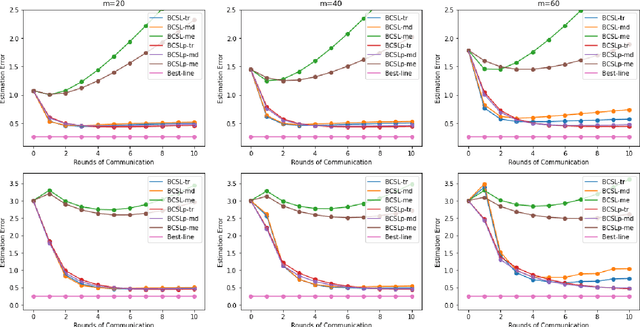
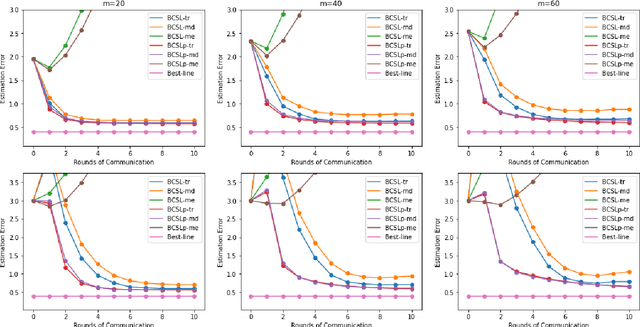
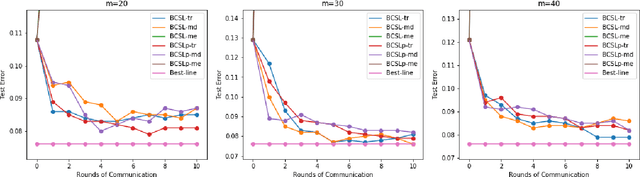
Communication efficiency and robustness are two major issues in modern distributed learning framework. This is due to the practical situations where some computing nodes may have limited communication power or may behave adversarial behaviors. To address the two issues simultaneously, this paper develops two communication-efficient and robust distributed learning algorithms for convex problems. Our motivation is based on surrogate likelihood framework and the median and trimmed mean operations. Particularly, the proposed algorithms are provably robust against Byzantine failures, and also achieve optimal statistical rates for strong convex losses and convex (non-smooth) penalties. For typical statistical models such as generalized linear models, our results show that statistical errors dominate optimization errors in finite iterations. Simulated and real data experiments are conducted to demonstrate the numerical performance of our algorithms.
SmartDeal: Re-Modeling Deep Network Weights for Efficient Inference and Training
Jan 04, 2021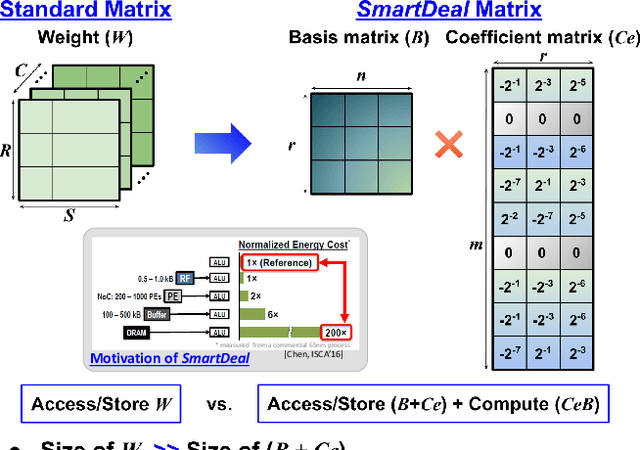

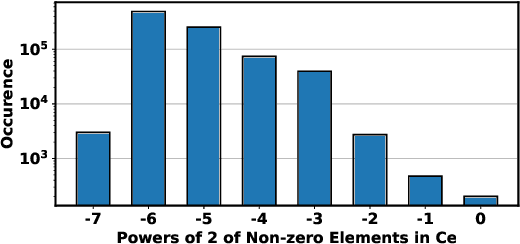
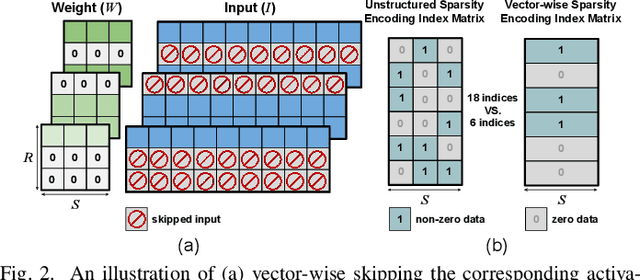
The record-breaking performance of deep neural networks (DNNs) comes with heavy parameterization, leading to external dynamic random-access memory (DRAM) for storage. The prohibitive energy of DRAM accesses makes it non-trivial to deploy DNN on resource-constrained devices, calling for minimizing the weight and data movements to improve the energy efficiency. We present SmartDeal (SD), an algorithm framework to trade higher-cost memory storage/access for lower-cost computation, in order to aggressively boost the storage and energy efficiency, for both inference and training. The core of SD is a novel weight decomposition with structural constraints, carefully crafted to unleash the hardware efficiency potential. Specifically, we decompose each weight tensor as the product of a small basis matrix and a large structurally sparse coefficient matrix whose non-zeros are quantized to power-of-2. The resulting sparse and quantized DNNs enjoy greatly reduced energy for data movement and weight storage, incurring minimal overhead to recover the original weights thanks to the sparse bit-operations and cost-favorable computations. Beyond inference, we take another leap to embrace energy-efficient training, introducing innovative techniques to address the unique roadblocks arising in training while preserving the SD structures. We also design a dedicated hardware accelerator to fully utilize the SD structure to improve the real energy efficiency and latency. We conduct experiments on both multiple tasks, models and datasets in different settings. Results show that: 1) applied to inference, SD achieves up to 2.44x energy efficiency as evaluated via real hardware implementations; 2) applied to training, SD leads to 10.56x and 4.48x reduction in the storage and training energy, with negligible accuracy loss compared to state-of-the-art training baselines. Our source codes are available online.
Emotional Semantics-Preserved and Feature-Aligned CycleGAN for Visual Emotion Adaptation
Nov 25, 2020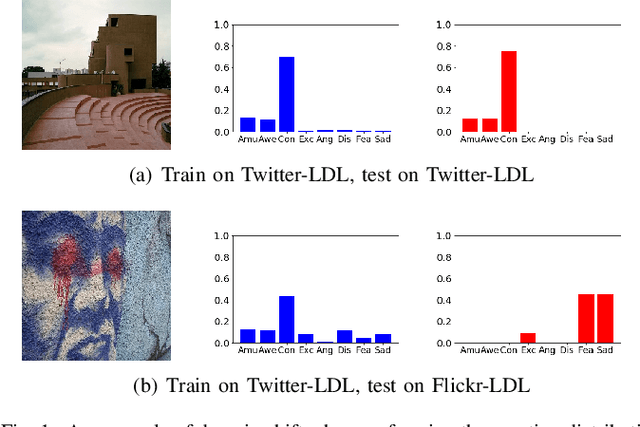

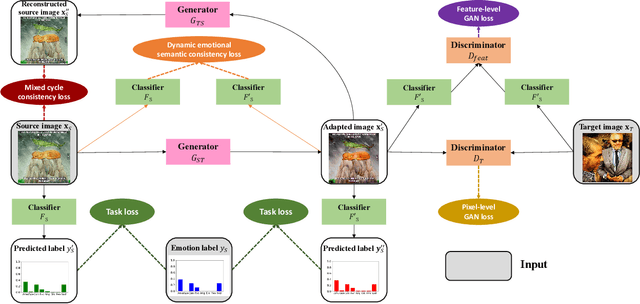
Thanks to large-scale labeled training data, deep neural networks (DNNs) have obtained remarkable success in many vision and multimedia tasks. However, because of the presence of domain shift, the learned knowledge of the well-trained DNNs cannot be well generalized to new domains or datasets that have few labels. Unsupervised domain adaptation (UDA) studies the problem of transferring models trained on one labeled source domain to another unlabeled target domain. In this paper, we focus on UDA in visual emotion analysis for both emotion distribution learning and dominant emotion classification. Specifically, we design a novel end-to-end cycle-consistent adversarial model, termed CycleEmotionGAN++. First, we generate an adapted domain to align the source and target domains on the pixel-level by improving CycleGAN with a multi-scale structured cycle-consistency loss. During the image translation, we propose a dynamic emotional semantic consistency loss to preserve the emotion labels of the source images. Second, we train a transferable task classifier on the adapted domain with feature-level alignment between the adapted and target domains. We conduct extensive UDA experiments on the Flickr-LDL & Twitter-LDL datasets for distribution learning and ArtPhoto & FI datasets for emotion classification. The results demonstrate the significant improvements yielded by the proposed CycleEmotionGAN++ as compared to state-of-the-art UDA approaches.