 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth Priors in Removal Neural Radiance Fields
May 01, 2024
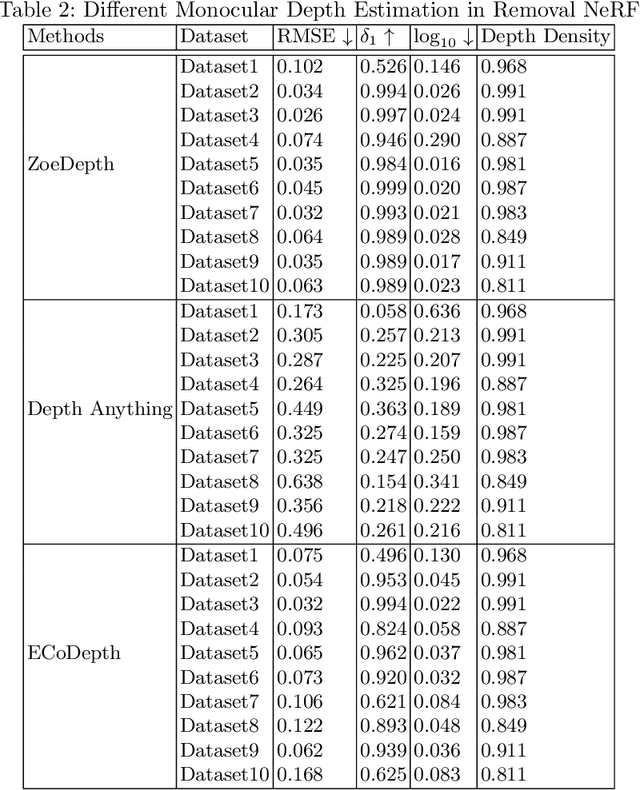


Neural Radiance Fields (NeRF) have shown impressive results in 3D reconstruction and generating novel views. A key challenge within NeRF is the editing of reconstructed scenes, such as object removal, which requires maintaining consistency across multiple views and ensuring high-quality synthesised perspectives. Previous studies have incorporated depth priors, typically from LiDAR or sparse depth measurements provided by COLMAP, to improve the performance of object removal in NeRF. However, these methods are either costly or time-consuming. In this paper, we propose a novel approach that integrates monocular depth estimates with NeRF-based object removal models to significantly reduce time consumption and enhance the robustness and quality of scene generation and object removal. We conducted a thorough evaluation of COLMAP's dense depth reconstruction on the KITTI dataset to verify its accuracy in depth map generation. Our findings suggest that COLMAP can serve as an effective alternative to a ground truth depth map where such information is missing or costly to obtain. Additionally, we integrated various monocular depth estimation methods into the removal NeRF model, i.e., SpinNeRF, to assess their capacity to improve object removal performance. Our experimental results highlight the potential of monocular depth estimation to substantially improve NeRF applications.
Dual-Modal Prompting for Sketch-Based Image Retrieval
Apr 29, 2024



Sketch-based image retrieval (SBIR) associates hand-drawn sketches with their corresponding realistic images. In this study, we aim to tackle two major challenges of this task simultaneously: i) zero-shot, dealing with unseen categories, and ii) fine-grained, referring to intra-category instance-level retrieval. Our key innovation lies in the realization that solely addressing this cross-category and fine-grained recognition task from the generalization perspective may be inadequate since the knowledge accumulated from limited seen categories might not be fully valuable or transferable to unseen target categories. Inspired by this, in this work, we propose a dual-modal prompting CLIP (DP-CLIP) network, in which an adaptive prompting strategy is designed. Specifically, to facilitate the adaptation of our DP-CLIP toward unpredictable target categories, we employ a set of images within the target category and the textual category label to respectively construct a set of category-adaptive prompt tokens and channel scales. By integrating the generated guidance, DP-CLIP could gain valuable category-centric insights, efficiently adapting to novel categories and capturing unique discriminative clues for effective retrieval within each target category. With these designs, our DP-CLIP outperforms the state-of-the-art fine-grained zero-shot SBIR method by 7.3% in Acc.@1 on the Sketchy dataset. Meanwhile, in the other two category-level zero-shot SBIR benchmarks, our method also achieves promising performance.
Recall, Retrieve and Reason: Towards Better In-Context Relation Extraction
Apr 27, 2024



Relation extraction (RE) aims to identify relations between entities mentioned in texts. Although large language models (LLMs) have demonstrated impressive in-context learning (ICL) abilities in various tasks, they still suffer from poor performances compared to most supervised fine-tuned RE methods. Utilizing ICL for RE with LLMs encounters two challenges: (1) retrieving good demonstrations from training examples, and (2) enabling LLMs exhibit strong ICL abilities in RE. On the one hand, retrieving good demonstrations is a non-trivial process in RE, which easily results in low relevance regarding entities and relations. On the other hand, ICL with an LLM achieves poor performance in RE while RE is different from language modeling in nature or the LLM is not large enough. In this work, we propose a novel recall-retrieve-reason RE framework that synergizes LLMs with retrieval corpora (training examples) to enable relevant retrieving and reliable in-context reasoning. Specifically, we distill the consistently ontological knowledge from training datasets to let LLMs generate relevant entity pairs grounded by retrieval corpora as valid queries. These entity pairs are then used to retrieve relevant training examples from the retrieval corpora as demonstrations for LLMs to conduct better ICL via instruction tuning. Extensive experiments on different LLMs and RE datasets demonstrate that our method generates relevant and valid entity pairs and boosts ICL abilities of LLMs, achieving competitive or new state-of-the-art performance on sentence-level RE compared to previous supervised fine-tuning methods and ICL-based methods.
Meta In-Context Learning Makes Large Language Models Better Zero and Few-Shot Relation Extractors
Apr 27, 2024



Relation extraction (RE) is an important task that aims to identify the relationships between entities in texts. While large language models (LLMs) have revealed remarkable in-context learning (ICL) capability for general zero and few-shot learning, recent studies indicate that current LLMs still struggle with zero and few-shot RE. Previous studies are mainly dedicated to design prompt formats and select good examples for improving ICL-based RE. Although both factors are vital for ICL, if one can fundamentally boost the ICL capability of LLMs in RE, the zero and few-shot RE performance via ICL would be significantly improved. To this end, we introduce \textsc{Micre} (\textbf{M}eta \textbf{I}n-\textbf{C}ontext learning of LLMs for \textbf{R}elation \textbf{E}xtraction), a new meta-training framework for zero and few-shot RE where an LLM is tuned to do ICL on a diverse collection of RE datasets (i.e., learning to learn in context for RE). Through meta-training, the model becomes more effectively to learn a new RE task in context by conditioning on a few training examples with no parameter updates or task-specific templates at inference time, enabling better zero and few-shot task generalization. We experiment \textsc{Micre} on various LLMs with different model scales and 12 public RE datasets, and then evaluate it on unseen RE benchmarks under zero and few-shot settings. \textsc{Micre} delivers comparable or superior performance compared to a range of baselines including supervised fine-tuning and typical in-context learning methods. We find that the gains are particular significant for larger model scales, and using a diverse set of the meta-training RE datasets is key to improvements. Empirically, we show that \textsc{Micre} can transfer the relation semantic knowledge via relation label name during inference on target RE datasets.
Multi-view Image Prompted Multi-view Diffusion for Improved 3D Generation
Apr 26, 2024Using image as prompts for 3D generation demonstrate particularly strong performances compared to using text prompts alone, for images provide a more intuitive guidance for the 3D generation process. In this work, we delve into the potential of using multiple image prompts, instead of a single image prompt, for 3D generation. Specifically, we build on ImageDream, a novel image-prompt multi-view diffusion model, to support multi-view images as the input prompt. Our method, dubbed MultiImageDream, reveals that transitioning from a single-image prompt to multiple-image prompts enhances the performance of multi-view and 3D object generation according to various quantitative evaluation metrics and qualitative assessments. This advancement is achieved without the necessity of fine-tuning the pre-trained ImageDream multi-view diffusion model.
Enhancing Prompt Following with Visual Control Through Training-Free Mask-Guided Diffusion
Apr 23, 2024



Recently, integrating visual controls into text-to-image~(T2I) models, such as ControlNet method, has received significant attention for finer control capabilities. While various training-free methods make efforts to enhance prompt following in T2I models, the issue with visual control is still rarely studied, especially in the scenario that visual controls are misaligned with text prompts. In this paper, we address the challenge of ``Prompt Following With Visual Control" and propose a training-free approach named Mask-guided Prompt Following (MGPF). Object masks are introduced to distinct aligned and misaligned parts of visual controls and prompts. Meanwhile, a network, dubbed as Masked ControlNet, is designed to utilize these object masks for object generation in the misaligned visual control region. Further, to improve attribute matching, a simple yet efficient loss is designed to align the attention maps of attributes with object regions constrained by ControlNet and object masks. The efficacy and superiority of MGPF are validated through comprehensive quantitative and qualitative experiments.
Enhancing 3D Fidelity of Text-to-3D using Cross-View Correspondences
Apr 16, 2024

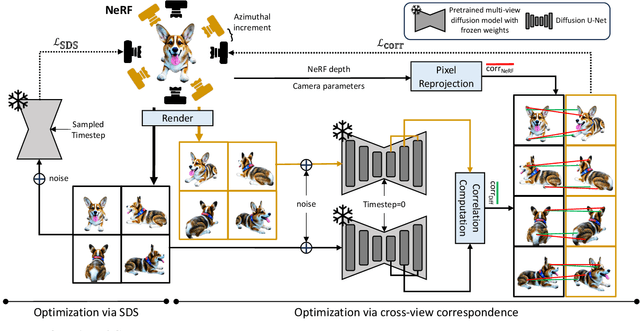

Leveraging multi-view diffusion models as priors for 3D optimization have alleviated the problem of 3D consistency, e.g., the Janus face problem or the content drift problem, in zero-shot text-to-3D models. However, the 3D geometric fidelity of the output remains an unresolved issue; albeit the rendered 2D views are realistic, the underlying geometry may contain errors such as unreasonable concavities. In this work, we propose CorrespondentDream, an effective method to leverage annotation-free, cross-view correspondences yielded from the diffusion U-Net to provide additional 3D prior to the NeRF optimization process. We find that these correspondences are strongly consistent with human perception, and by adopting it in our loss design, we are able to produce NeRF models with geometries that are more coherent with common sense, e.g., more smoothed object surface, yielding higher 3D fidelity. We demonstrate the efficacy of our approach through various comparative qualitative results and a solid user study.
HQ-Edit: A High-Quality Dataset for Instruction-based Image Editing
Apr 15, 2024



This study introduces HQ-Edit, a high-quality instruction-based image editing dataset with around 200,000 edits. Unlike prior approaches relying on attribute guidance or human feedback on building datasets, we devise a scalable data collection pipeline leveraging advanced foundation models, namely GPT-4V and DALL-E 3. To ensure its high quality, diverse examples are first collected online, expanded, and then used to create high-quality diptychs featuring input and output images with detailed text prompts, followed by precise alignment ensured through post-processing. In addition, we propose two evaluation metrics, Alignment and Coherence, to quantitatively assess the quality of image edit pairs using GPT-4V. HQ-Edits high-resolution images, rich in detail and accompanied by comprehensive editing prompts, substantially enhance the capabilities of existing image editing models. For example, an HQ-Edit finetuned InstructPix2Pix can attain state-of-the-art image editing performance, even surpassing those models fine-tuned with human-annotated data. The project page is https://thefllood.github.io/HQEdit_web.
COCONut: Modernizing COCO Segmentation
Apr 12, 2024



In recent decades, the vision community has witnessed remarkable progress in visual recognition, partially owing to advancements in dataset benchmarks. Notably, the established COCO benchmark has propelled the development of modern detection and segmentation systems. However, the COCO segmentation benchmark has seen comparatively slow improvement over the last decade. Originally equipped with coarse polygon annotations for thing instances, it gradually incorporated coarse superpixel annotations for stuff regions, which were subsequently heuristically amalgamated to yield panoptic segmentation annotations. These annotations, executed by different groups of raters, have resulted not only in coarse segmentation masks but also in inconsistencies between segmentation types. In this study, we undertake a comprehensive reevaluation of the COCO segmentation annotations. By enhancing the annotation quality and expanding the dataset to encompass 383K images with more than 5.18M panoptic masks, we introduce COCONut, the COCO Next Universal segmenTation dataset. COCONut harmonizes segmentation annotations across semantic, instance, and panoptic segmentation with meticulously crafted high-quality masks, and establishes a robust benchmark for all segmentation tasks. To our knowledge, COCONut stands as the inaugural large-scale universal segmentation dataset, verified by human raters. We anticipate that the release of COCONut will significantly contribute to the community's ability to assess the progress of novel neural networks.
Self-Explainable Affordance Learning with Embodied Caption
Apr 08, 2024



In the field of visual affordance learning, previous methods mainly used abundant images or videos that delineate human behavior patterns to identify action possibility regions for object manipulation, with a variety of applications in robotic tasks. However, they encounter a main challenge of action ambiguity, illustrated by the vagueness like whether to beat or carry a drum, and the complexities involved in processing intricate scenes. Moreover, it is important for human intervention to rectify robot errors in time. To address these issues, we introduce Self-Explainable Affordance learning (SEA) with embodied caption. This innovation enables robots to articulate their intentions and bridge the gap between explainable vision-language caption and visual affordance learning. Due to a lack of appropriate dataset, we unveil a pioneering dataset and metrics tailored for this task, which integrates images, heatmaps, and embodied captions. Furthermore, we propose a novel model to effectively combine affordance grounding with self-explanation in a simple but efficient manner. Extensive quantitative and qualitative experiments demonstrate our method's effectiveness.