 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Test-Time Model Adaptation without Forgetting
Apr 06, 2022
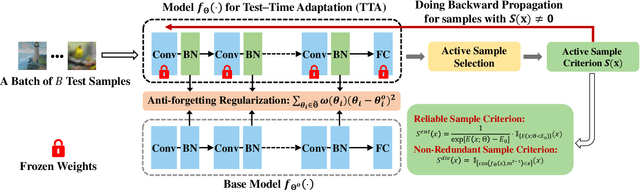
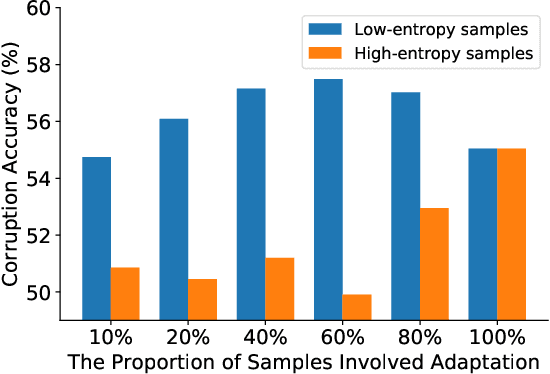
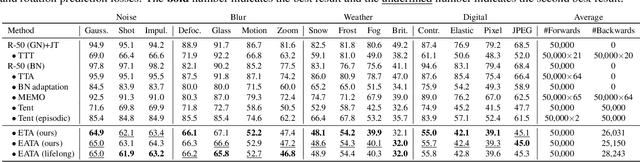
Test-time adaptation (TTA) seeks to tackle potential distribution shifts between training and testing data by adapting a given model w.r.t. any testing sample. This task is particularly important for deep models when the test environment changes frequently. Although some recent attempts have been made to handle this task, we still face two practical challenges: 1) existing methods have to perform backward computation for each test sample, resulting in unbearable prediction cost to many applications; 2) while existing TTA solutions can significantly improve the test performance on out-of-distribution data, they often suffer from severe performance degradation on in-distribution data after TTA (known as catastrophic forgetting). In this paper, we point out that not all the test samples contribute equally to model adaptation, and high-entropy ones may lead to noisy gradients that could disrupt the model. Motivated by this, we propose an active sample selection criterion to identify reliable and non-redundant samples, on which the model is updated to minimize the entropy loss for test-time adaptation. Furthermore, to alleviate the forgetting issue, we introduce a Fisher regularizer to constrain important model parameters from drastic changes, where the Fisher importance is estimated from test samples with generated pseudo labels. Extensive experiments on CIFAR-10-C, ImageNet-C, and ImageNet-R verify the effectiveness of our proposed method.
Boost Test-Time Performance with Closed-Loop Inference
Mar 26, 2022
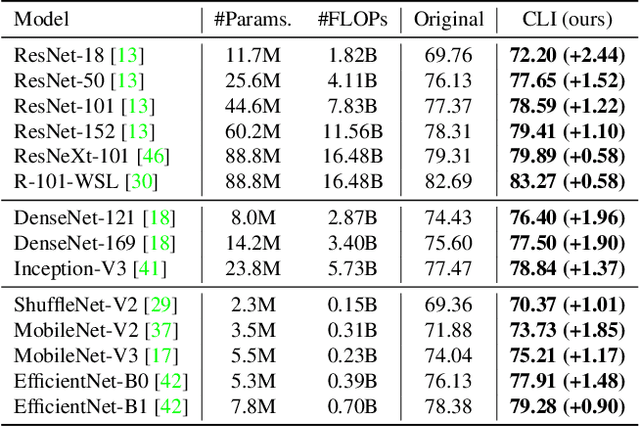
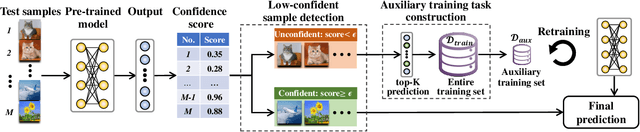
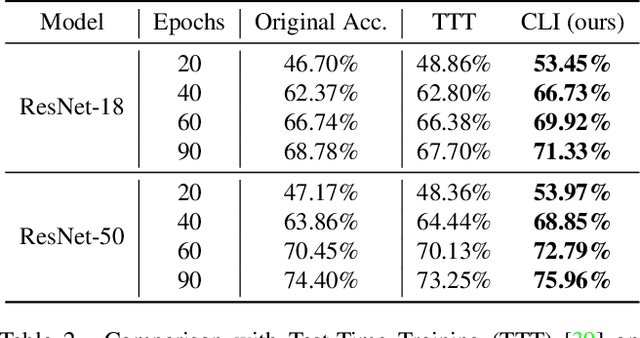
Conventional deep models predict a test sample with a single forward propagation, which, however, may not be sufficient for predicting hard-classified samples. On the contrary, we human beings may need to carefully check the sample many times before making a final decision. During the recheck process, one may refine/adjust the prediction by referring to related samples. Motivated by this, we propose to predict those hard-classified test samples in a looped manner to boost the model performance. However, this idea may pose a critical challenge: how to construct looped inference, so that the original erroneous predictions on these hard test samples can be corrected with little additional effort. To address this, we propose a general Closed-Loop Inference (CLI) method. Specifically, we first devise a filtering criterion to identify those hard-classified test samples that need additional inference loops. For each hard sample, we construct an additional auxiliary learning task based on its original top-$K$ predictions to calibrate the model, and then use the calibrated model to obtain the final prediction. Promising results on ImageNet (in-distribution test samples) and ImageNet-C (out-of-distribution test samples) demonstrate the effectiveness of CLI in improving the performance of any pre-trained model.
Learning Set Functions Under the Optimal Subset Oracle via Equivariant Variational Inference
Mar 03, 2022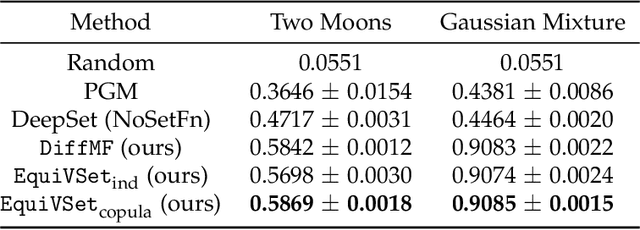
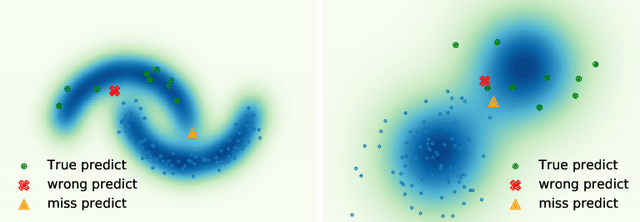
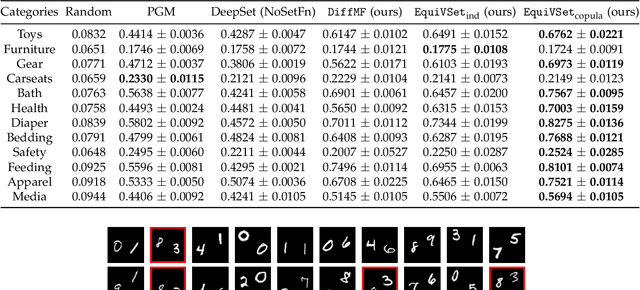

Learning set functions becomes increasingly more important in many applications like product recommendation and compound selection in AI-aided drug discovery. The majority of existing works study methodologies of set function learning under the function value oracle, which, however, requires expensive supervision signals. This renders it impractical for applications with only weak supervisions under the Optimal Subset (OS) oracle, the study of which is surprisingly overlooked. In this work, we present a principled yet practical maximum likelihood learning framework, termed as EquiVSet, that simultaneously meets the following desiderata of learning set functions under the OS oracle: i) permutation invariance of the set mass function being modeled; ii) permission of varying ground set; iii) fully differentiability; iv) minimum prior; and v) scalability. The main components of our framework involve: an energy-based treatment of the set mass function, DeepSet-style architectures to handle permutation invariance, mean-field variational inference, and its amortized variants. Although the framework is embarrassingly simple, empirical studies on three real-world applications (including Amazon product recommendation, set anomaly detection and compound selection for virtual screening) demonstrate that EquiVSet outperforms the baselines by a large margin.
Transformer for Graphs: An Overview from Architecture Perspective
Feb 17, 2022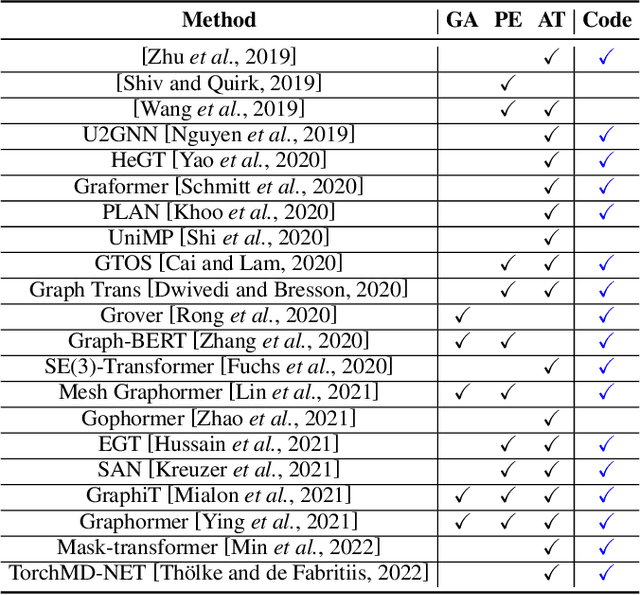
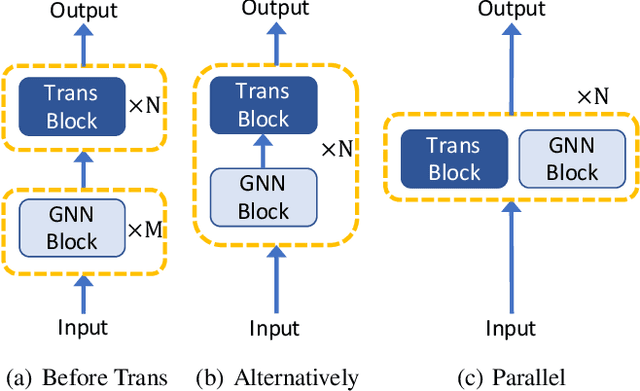
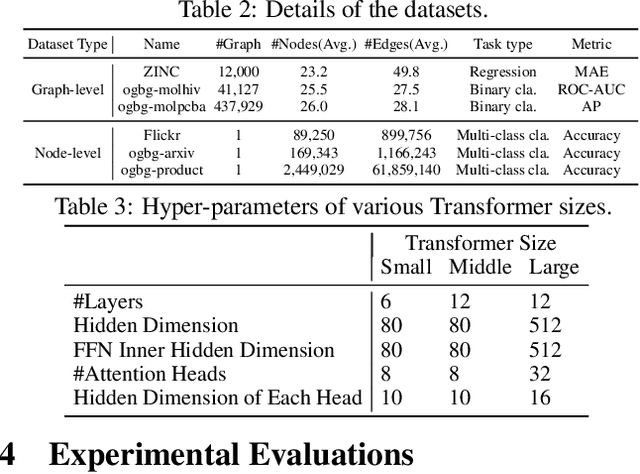
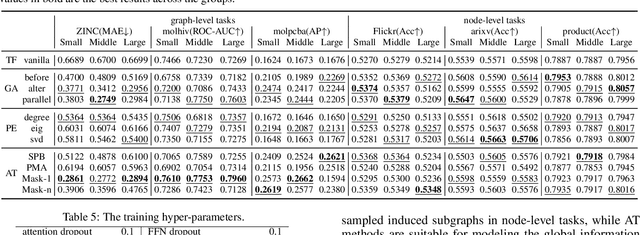
Recently, Transformer model, which has achieved great success in many artificial intelligence fields, has demonstrated its great potential in modeling graph-structured data. Till now, a great variety of Transformers has been proposed to adapt to the graph-structured data. However, a comprehensive literature review and systematical evaluation of these Transformer variants for graphs are still unavailable. It's imperative to sort out the existing Transformer models for graphs and systematically investigate their effectiveness on various graph tasks. In this survey, we provide a comprehensive review of various Graph Transformer models from the architectural design perspective. We first disassemble the existing models and conclude three typical ways to incorporate the graph information into the vanilla Transformer: 1) GNNs as Auxiliary Modules, 2) Improved Positional Embedding from Graphs, and 3) Improved Attention Matrix from Graphs. Furthermore, we implement the representative components in three groups and conduct a comprehensive comparison on various kinds of famous graph data benchmarks to investigate the real performance gain of each component. Our experiments confirm the benefits of current graph-specific modules on Transformer and reveal their advantages on different kinds of graph tasks.
Masked Transformer for Neighhourhood-aware Click-Through Rate Prediction
Jan 25, 2022
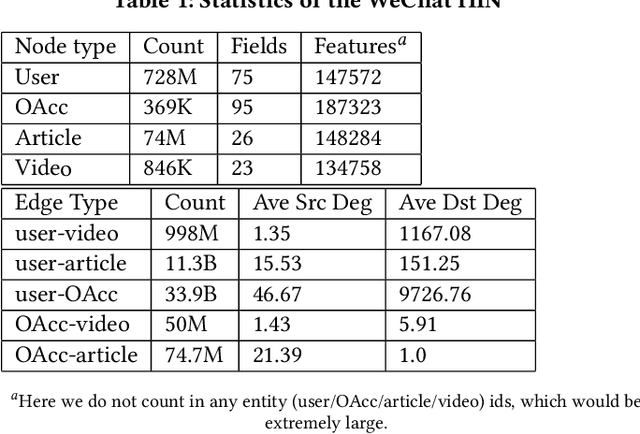
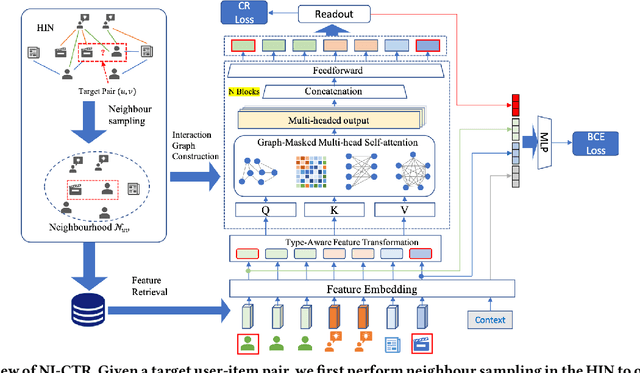
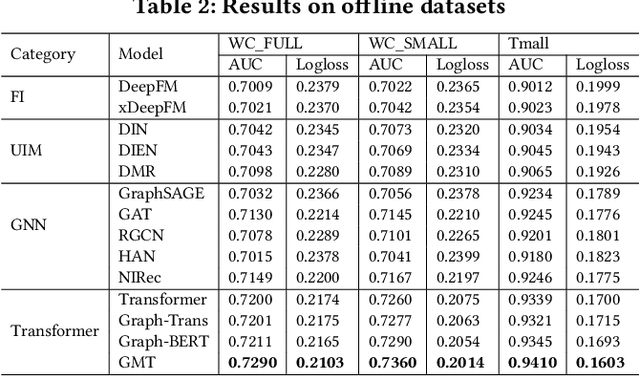
Click-Through Rate (CTR) prediction, is an essential component of online advertising. The mainstream techniques mostly focus on feature interaction or user interest modeling, which rely on users' directly interacted items. The performance of these methods are usally impeded by inactive behaviours and system's exposure, incurring that the features extracted do not contain enough information to represent all potential interests. For this sake, we propose Neighbor-Interaction based CTR prediction, which put this task into a Heterogeneous Information Network (HIN) setting, then involves local neighborhood of the target user-item pair in the HIN to predict their linkage. In order to enhance the representation of the local neighbourhood, we consider four types of topological interaction among the nodes, and propose a novel Graph-masked Transformer architecture to effectively incorporates both feature and topological information. We conduct comprehensive experiments on two real world datasets and the experimental results show that our proposed method outperforms state-of-the-art CTR models significantly.
DrugOOD: Out-of-Distribution (OOD) Dataset Curator and Benchmark for AI-aided Drug Discovery -- A Focus on Affinity Prediction Problems with Noise Annotations
Jan 24, 2022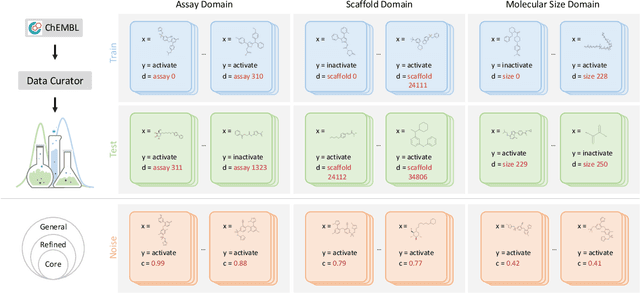

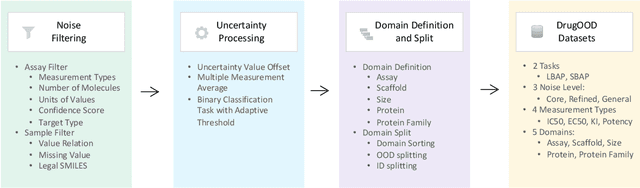
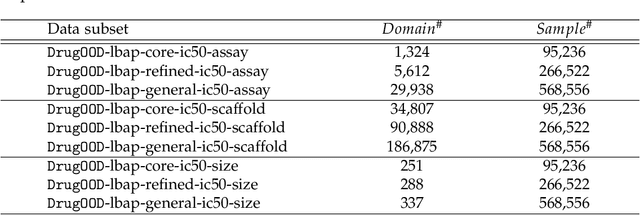
AI-aided drug discovery (AIDD) is gaining increasing popularity due to its promise of making the search for new pharmaceuticals quicker, cheaper and more efficient. In spite of its extensive use in many fields, such as ADMET prediction, virtual screening, protein folding and generative chemistry, little has been explored in terms of the out-of-distribution (OOD) learning problem with \emph{noise}, which is inevitable in real world AIDD applications. In this work, we present DrugOOD, a systematic OOD dataset curator and benchmark for AI-aided drug discovery, which comes with an open-source Python package that fully automates the data curation and OOD benchmarking processes. We focus on one of the most crucial problems in AIDD: drug target binding affinity prediction, which involves both macromolecule (protein target) and small-molecule (drug compound). In contrast to only providing fixed datasets, DrugOOD offers automated dataset curator with user-friendly customization scripts, rich domain annotations aligned with biochemistry knowledge, realistic noise annotations and rigorous benchmarking of state-of-the-art OOD algorithms. Since the molecular data is often modeled as irregular graphs using graph neural network (GNN) backbones, DrugOOD also serves as a valuable testbed for \emph{graph OOD learning} problems. Extensive empirical studies have shown a significant performance gap between in-distribution and out-of-distribution experiments, which highlights the need to develop better schemes that can allow for OOD generalization under noise for AIDD.
RetroComposer: Discovering Novel Reactions by Composing Templates for Retrosynthesis Prediction
Dec 20, 2021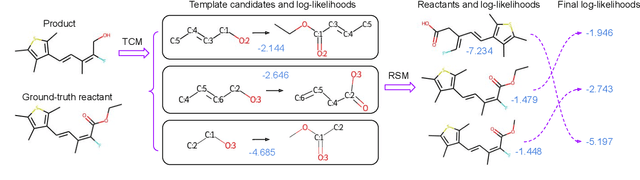
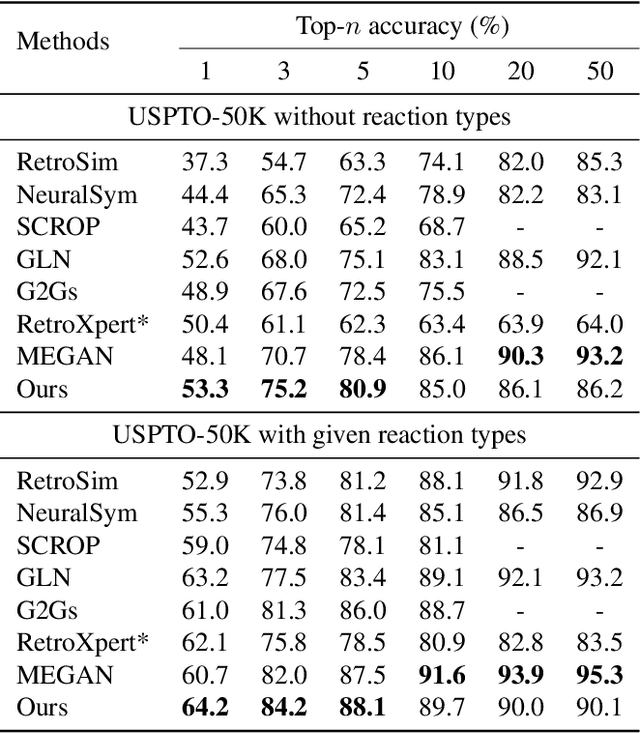
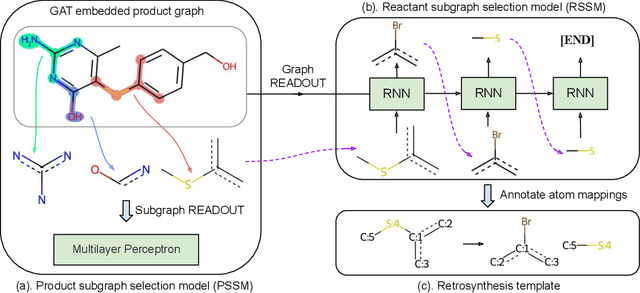
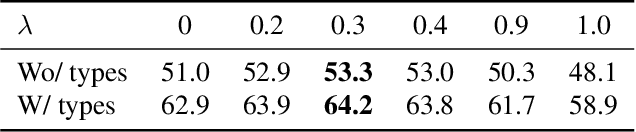
The main target of retrosynthesis is to recursively decompose desired molecules into available building blocks. Existing template-based retrosynthesis methods follow a template selection stereotype and suffer from the limited training templates, which prevents them from discovering novel reactions. To overcome the limitation, we propose an innovative retrosynthesis prediction framework that can compose novel templates beyond training templates. So far as we know, this is the first method that can find novel templates for retrosynthesis prediction. Besides, we propose an effective reactant candidates scoring model that can capture atom-level transformation information, and it helps our method outperform existing methods by a large margin. Experimental results show that our method can produce novel templates for 328 test reactions in the USPTO-50K dataset, including 21 test reactions that are not covered by the training templates.
SVIP: Sequence VerIfication for Procedures in Videos
Dec 14, 2021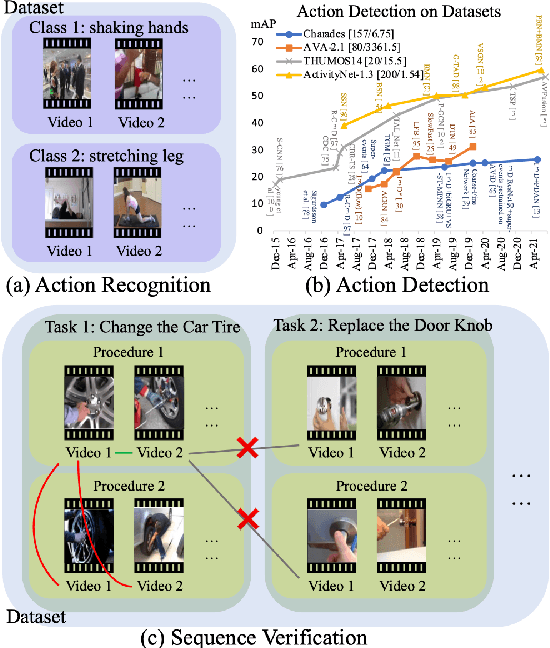

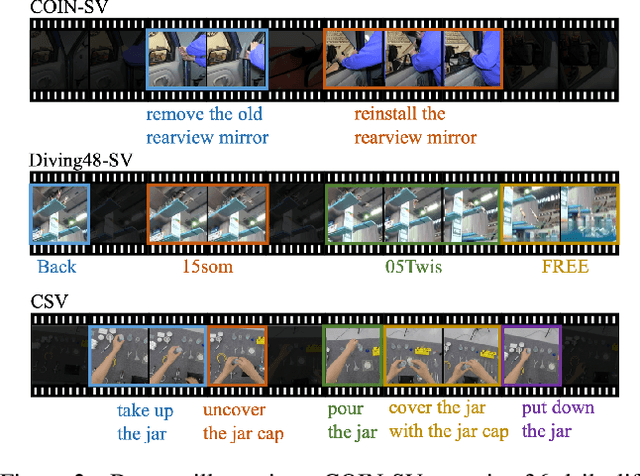
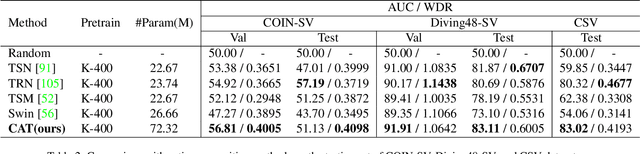
In this paper, we propose a novel sequence verification task that aims to distinguish positive video pairs performing the same action sequence from negative ones with step-level transformations but still conducting the same task. Such a challenging task resides in an open-set setting without prior action detection or segmentation that requires event-level or even frame-level annotations. To that end, we carefully reorganize two publicly available action-related datasets with step-procedure-task structure. To fully investigate the effectiveness of any method, we collect a scripted video dataset enumerating all kinds of step-level transformations in chemical experiments. Besides, a novel evaluation metric Weighted Distance Ratio is introduced to ensure equivalence for different step-level transformations during evaluation. In the end, a simple but effective baseline based on the transformer with a novel sequence alignment loss is introduced to better characterize long-term dependency between steps, which outperforms other action recognition methods. Codes and data will be released.
Graph Convolutional Module for Temporal Action Localization in Videos
Dec 01, 2021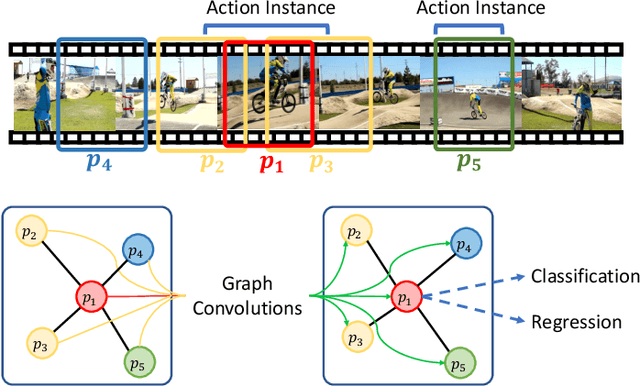
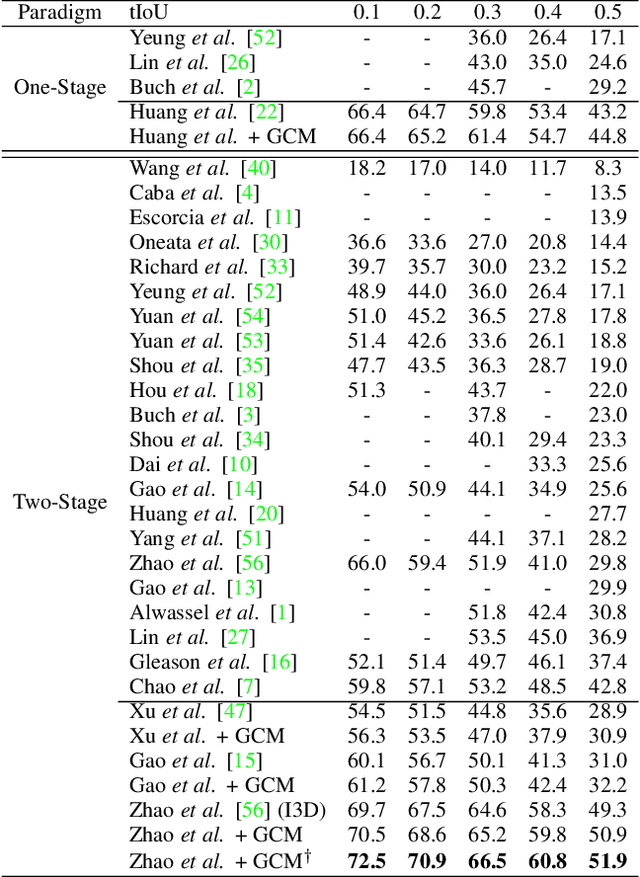
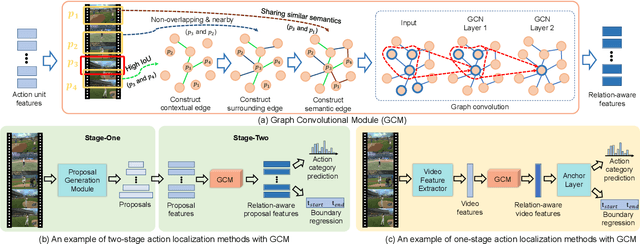
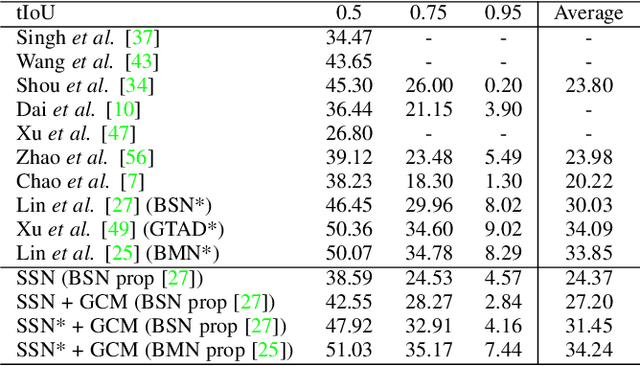
Temporal action localization has long been researched in computer vision. Existing state-of-the-art action localization methods divide each video into multiple action units (i.e., proposals in two-stage methods and segments in one-stage methods) and then perform action recognition/regression on each of them individually, without explicitly exploiting their relations during learning. In this paper, we claim that the relations between action units play an important role in action localization, and a more powerful action detector should not only capture the local content of each action unit but also allow a wider field of view on the context related to it. To this end, we propose a general graph convolutional module (GCM) that can be easily plugged into existing action localization methods, including two-stage and one-stage paradigms. To be specific, we first construct a graph, where each action unit is represented as a node and their relations between two action units as an edge. Here, we use two types of relations, one for capturing the temporal connections between different action units, and the other one for characterizing their semantic relationship. Particularly for the temporal connections in two-stage methods, we further explore two different kinds of edges, one connecting the overlapping action units and the other one connecting surrounding but disjointed units. Upon the graph we built, we then apply graph convolutional networks (GCNs) to model the relations among different action units, which is able to learn more informative representations to enhance action localization. Experimental results show that our GCM consistently improves the performance of existing action localization methods, including two-stage methods (e.g., CBR and R-C3D) and one-stage methods (e.g., D-SSAD), verifying the generality and effectiveness of our GCM.
$p$-Laplacian Based Graph Neural Networks
Nov 14, 2021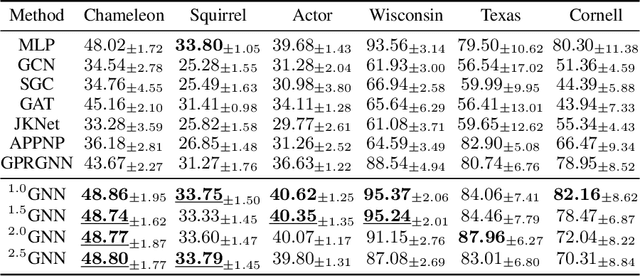
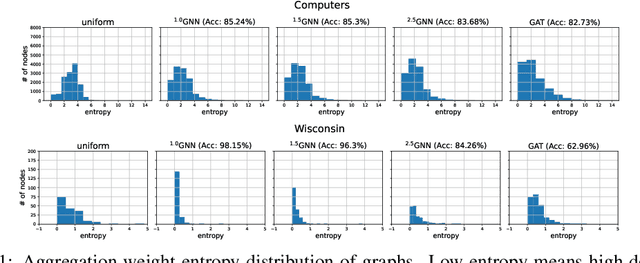
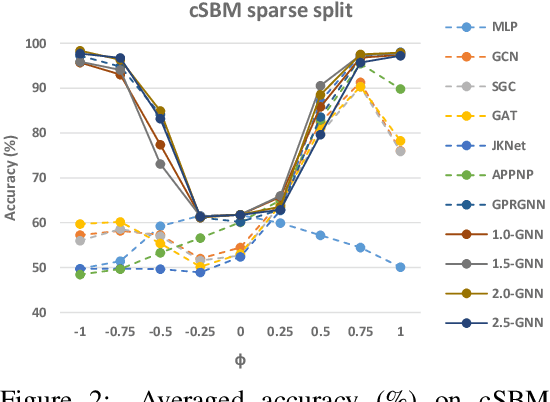
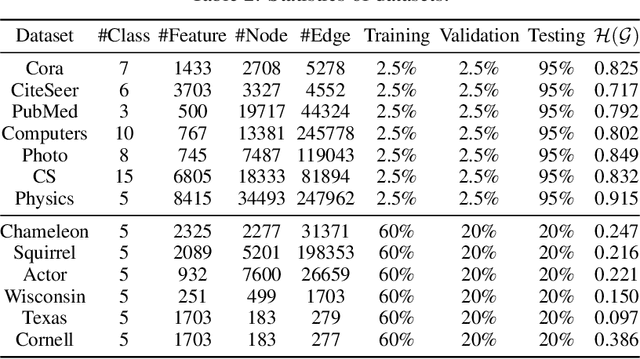
Graph neural networks (GNNs) have demonstrated superior performance for semi-supervised node classification on graphs, as a result of their ability to exploit node features and topological information simultaneously. However, most GNNs implicitly assume that the labels of nodes and their neighbors in a graph are the same or consistent, which does not hold in heterophilic graphs, where the labels of linked nodes are likely to differ. Hence, when the topology is non-informative for label prediction, ordinary GNNs may work significantly worse than simply applying multi-layer perceptrons (MLPs) on each node. To tackle the above problem, we propose a new $p$-Laplacian based GNN model, termed as $^p$GNN, whose message passing mechanism is derived from a discrete regularization framework and could be theoretically explained as an approximation of a polynomial graph filter defined on the spectral domain of $p$-Laplacians. The spectral analysis shows that the new message passing mechanism works simultaneously as low-pass and high-pass filters, thus making $^p$GNNs are effective on both homophilic and heterophilic graphs. Empirical studies on real-world and synthetic datasets validate our findings and demonstrate that $^p$GNNs significantly outperform several state-of-the-art GNN architectures on heterophilic benchmarks while achieving competitive performance on homophilic benchmarks. Moreover, $^p$GNNs can adaptively learn aggregation weights and are robust to noisy edges.