 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNITE: A Unified Benchmark for Text-to-SQL Evaluation
May 26, 2023


A practical text-to-SQL system should generalize well on a wide variety of natural language questions, unseen database schemas, and novel SQL query structures. To comprehensively evaluate text-to-SQL systems, we introduce a \textbf{UNI}fied benchmark for \textbf{T}ext-to-SQL \textbf{E}valuation (UNITE). It is composed of publicly available text-to-SQL datasets, containing natural language questions from more than 12 domains, SQL queries from more than 3.9K patterns, and 29K databases. Compared to the widely used Spider benchmark \cite{yu-etal-2018-spider}, we introduce $\sim$120K additional examples and a threefold increase in SQL patterns, such as comparative and boolean questions. We conduct a systematic study of six state-of-the-art (SOTA) text-to-SQL parsers on our new benchmark and show that: 1) Codex performs surprisingly well on out-of-domain datasets; 2) specially designed decoding methods (e.g. constrained beam search) can improve performance for both in-domain and out-of-domain settings; 3) explicitly modeling the relationship between questions and schemas further improves the Seq2Seq models. More importantly, our benchmark presents key challenges towards compositional generalization and robustness issues -- which these SOTA models cannot address well. \footnote{Our code and data processing script will be available at \url{https://github.com/XXXX.}}
Dr.Spider: A Diagnostic Evaluation Benchmark towards Text-to-SQL Robustness
Jan 21, 2023



Neural text-to-SQL models have achieved remarkable performance in translating natural language questions into SQL queries. However, recent studies reveal that text-to-SQL models are vulnerable to task-specific perturbations. Previous curated robustness test sets usually focus on individual phenomena. In this paper, we propose a comprehensive robustness benchmark based on Spider, a cross-domain text-to-SQL benchmark, to diagnose the model robustness. We design 17 perturbations on databases, natural language questions, and SQL queries to measure the robustness from different angles. In order to collect more diversified natural question perturbations, we utilize large pretrained language models (PLMs) to simulate human behaviors in creating natural questions. We conduct a diagnostic study of the state-of-the-art models on the robustness set. Experimental results reveal that even the most robust model suffers from a 14.0% performance drop overall and a 50.7% performance drop on the most challenging perturbation. We also present a breakdown analysis regarding text-to-SQL model designs and provide insights for improving model robustness.
Importance of Synthesizing High-quality Data for Text-to-SQL Parsing
Dec 17, 2022



Recently, there has been increasing interest in synthesizing data to improve downstream text-to-SQL tasks. In this paper, we first examined the existing synthesized datasets and discovered that state-of-the-art text-to-SQL algorithms did not further improve on popular benchmarks when trained with augmented synthetic data. We observed two shortcomings: illogical synthetic SQL queries from independent column sampling and arbitrary table joins. To address these issues, we propose a novel synthesis framework that incorporates key relationships from schema, imposes strong typing, and conducts schema-distance-weighted column sampling. We also adopt an intermediate representation (IR) for the SQL-to-text task to further improve the quality of the generated natural language questions. When existing powerful semantic parsers are pre-finetuned on our high-quality synthesized data, our experiments show that these models have significant accuracy boosts on popular benchmarks, including new state-of-the-art performance on Spider.
Improving Cross-task Generalization of Unified Table-to-text Models with Compositional Task Configurations
Dec 17, 2022



There has been great progress in unifying various table-to-text tasks using a single encoder-decoder model trained via multi-task learning (Xie et al., 2022). However, existing methods typically encode task information with a simple dataset name as a prefix to the encoder. This not only limits the effectiveness of multi-task learning, but also hinders the model's ability to generalize to new domains or tasks that were not seen during training, which is crucial for real-world applications. In this paper, we propose compositional task configurations, a set of prompts prepended to the encoder to improve cross-task generalization of unified models. We design the task configurations to explicitly specify the task type, as well as its input and output types. We show that this not only allows the model to better learn shared knowledge across different tasks at training, but also allows us to control the model by composing new configurations that apply novel input-output combinations in a zero-shot manner. We demonstrate via experiments over ten table-to-text tasks that our method outperforms the UnifiedSKG baseline by noticeable margins in both in-domain and zero-shot settings, with average improvements of +0.5 and +12.6 from using a T5-large backbone, respectively.
DecAF: Joint Decoding of Answers and Logical Forms for Question Answering over Knowledge Bases
Sep 30, 2022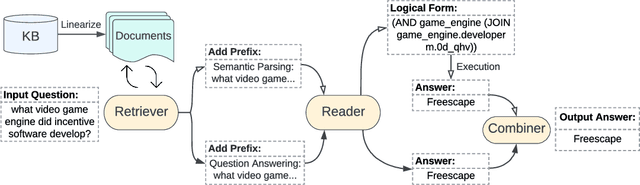
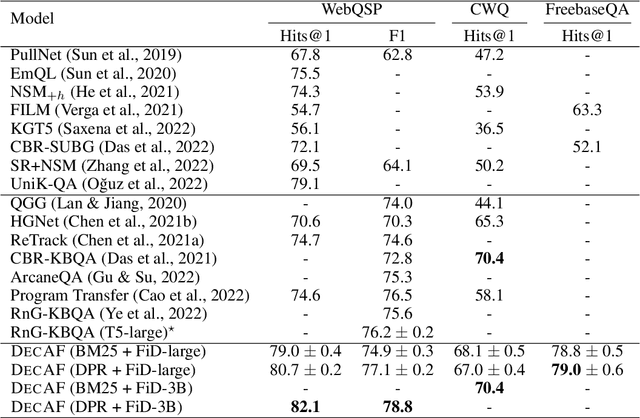
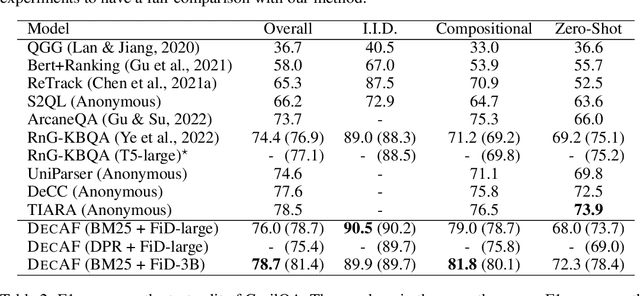
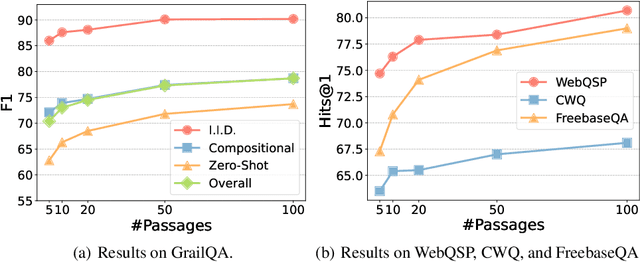
Question answering over knowledge bases (KBs) aims to answer natural language questions with factual information such as entities and relations in KBs. Previous methods either generate logical forms that can be executed over KBs to obtain final answers or predict answers directly. Empirical results show that the former often produces more accurate answers, but it suffers from non-execution issues due to potential syntactic and semantic errors in the generated logical forms. In this work, we propose a novel framework DecAF that jointly generates both logical forms and direct answers, and then combines the merits of them to get the final answers. Moreover, different from most of the previous methods, DecAF is based on simple free-text retrieval without relying on any entity linking tools -- this simplification eases its adaptation to different datasets. DecAF achieves new state-of-the-art accuracy on WebQSP, FreebaseQA, and GrailQA benchmarks, while getting competitive results on the ComplexWebQuestions benchmark.
Improving Text-to-SQL Semantic Parsing with Fine-grained Query Understanding
Sep 28, 2022

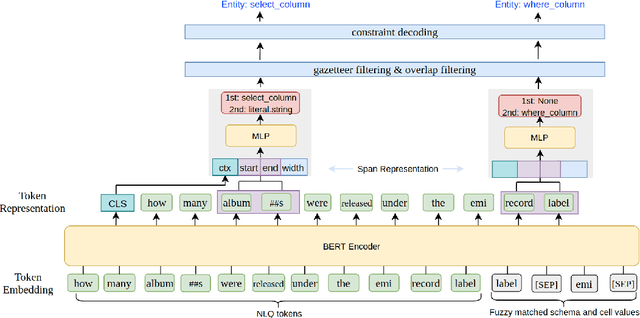
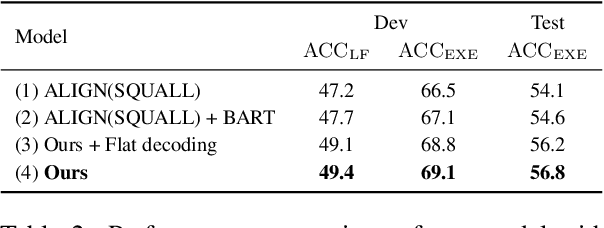
Most recent research on Text-to-SQL semantic parsing relies on either parser itself or simple heuristic based approach to understand natural language query (NLQ). When synthesizing a SQL query, there is no explicit semantic information of NLQ available to the parser which leads to undesirable generalization performance. In addition, without lexical-level fine-grained query understanding, linking between query and database can only rely on fuzzy string match which leads to suboptimal performance in real applications. In view of this, in this paper we present a general-purpose, modular neural semantic parsing framework that is based on token-level fine-grained query understanding. Our framework consists of three modules: named entity recognizer (NER), neural entity linker (NEL) and neural semantic parser (NSP). By jointly modeling query and database, NER model analyzes user intents and identifies entities in the query. NEL model links typed entities to schema and cell values in database. Parser model leverages available semantic information and linking results and synthesizes tree-structured SQL queries based on dynamically generated grammar. Experiments on SQUALL, a newly released semantic parsing dataset, show that we can achieve 56.8% execution accuracy on WikiTableQuestions (WTQ) test set, which outperforms the state-of-the-art model by 2.7%.
REKnow: Enhanced Knowledge for Joint Entity and Relation Extraction
Jun 20, 2022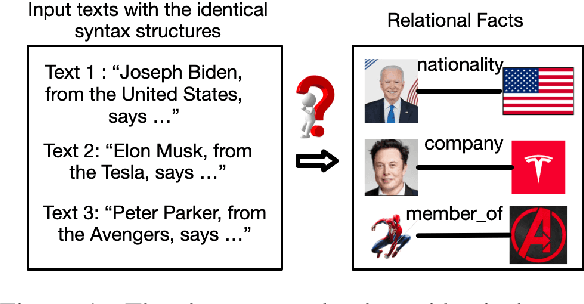
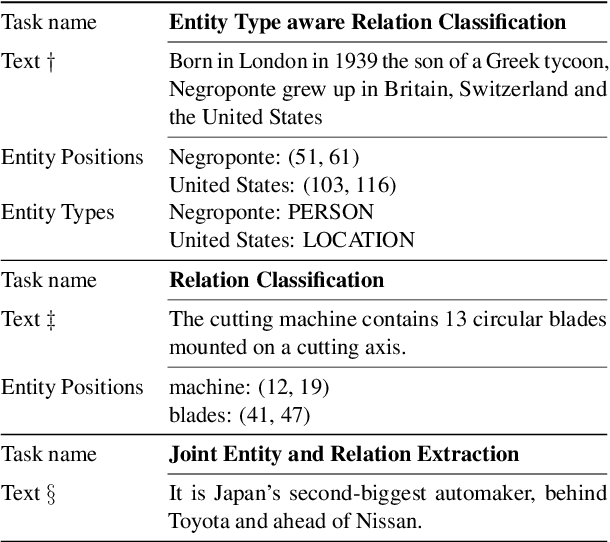
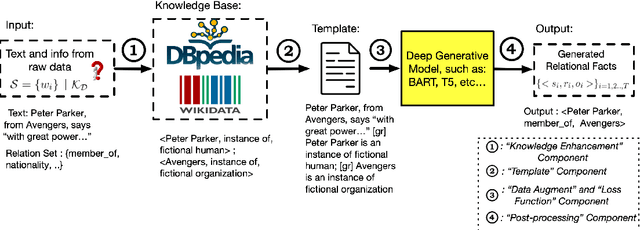
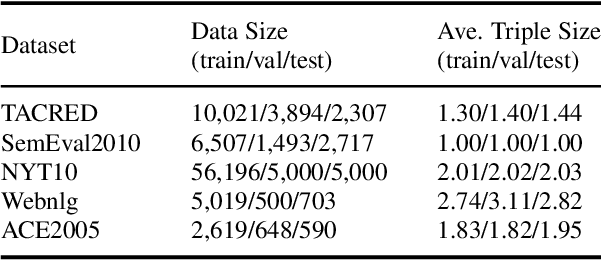
Relation extraction is an important but challenging task that aims to extract all hidden relational facts from the text. With the development of deep language models, relation extraction methods have achieved good performance on various benchmarks. However, we observe two shortcomings of previous methods: first, there is no unified framework that works well under various relation extraction settings; second, effectively utilizing external knowledge as background information is absent. In this work, we propose a knowledge-enhanced generative model to mitigate these two issues. Our generative model is a unified framework to sequentially generate relational triplets under various relation extraction settings and explicitly utilizes relevant knowledge from Knowledge Graph (KG) to resolve ambiguities. Our model achieves superior performance on multiple benchmarks and settings, including WebNLG, NYT10, and TACRED.
Dual Reader-Parser on Hybrid Textual and Tabular Evidence for Open Domain Question Answering
Aug 05, 2021
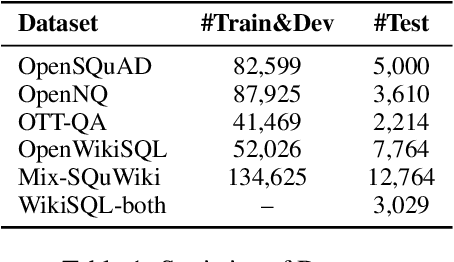
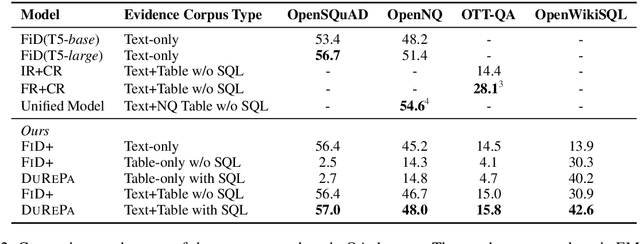
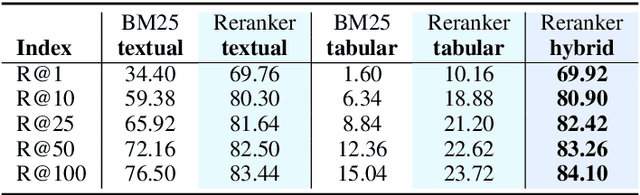
The current state-of-the-art generative models for open-domain question answering (ODQA) have focused on generating direct answers from unstructured textual information. However, a large amount of world's knowledge is stored in structured databases, and need to be accessed using query languages such as SQL. Furthermore, query languages can answer questions that require complex reasoning, as well as offering full explainability. In this paper, we propose a hybrid framework that takes both textual and tabular evidence as input and generates either direct answers or SQL queries depending on which form could better answer the question. The generated SQL queries can then be executed on the associated databases to obtain the final answers. To the best of our knowledge, this is the first paper that applies Text2SQL to ODQA tasks. Empirically, we demonstrate that on several ODQA datasets, the hybrid methods consistently outperforms the baseline models that only take homogeneous input by a large margin. Specifically we achieve state-of-the-art performance on OpenSQuAD dataset using a T5-base model. In a detailed analysis, we demonstrate that the being able to generate structural SQL queries can always bring gains, especially for those questions that requires complex reasoning.
End-to-End Cross-Domain Text-to-SQL Semantic Parsing with Auxiliary Task
Jun 17, 2021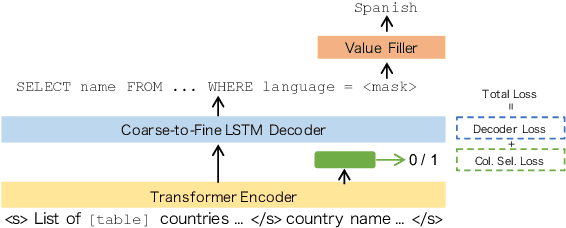

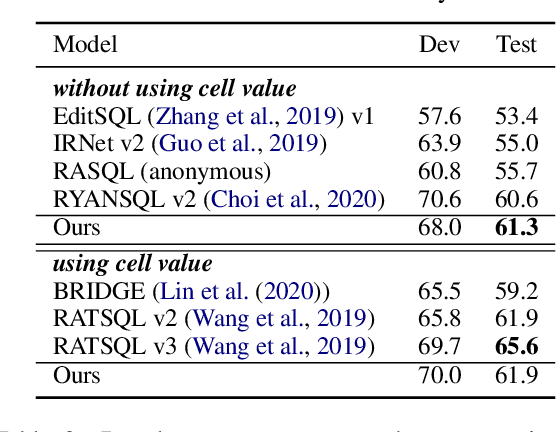
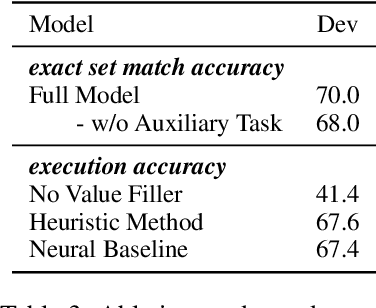
In this work, we focus on two crucial components in the cross-domain text-to-SQL semantic parsing task: schema linking and value filling. To encourage the model to learn better encoding ability, we propose a column selection auxiliary task to empower the encoder with the relevance matching capability by using explicit learning targets. Furthermore, we propose two value filling methods to build the bridge from the existing zero-shot semantic parsers to real-world applications, considering most of the existing parsers ignore the values filling in the synthesized SQL. With experiments on Spider, our proposed framework improves over the baselines on the execution accuracy and exact set match accuracy when database contents are unavailable, and detailed analysis sheds light on future work.
Improving Factual Consistency of Abstractive Summarization via Question Answering
May 10, 2021
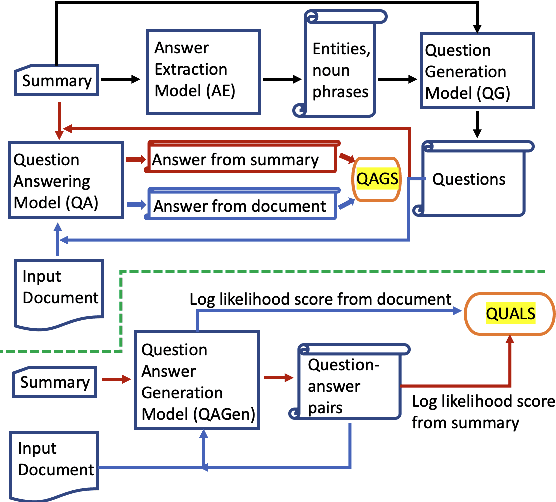
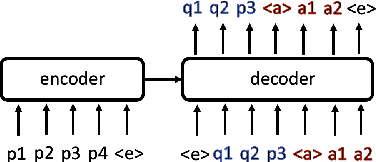
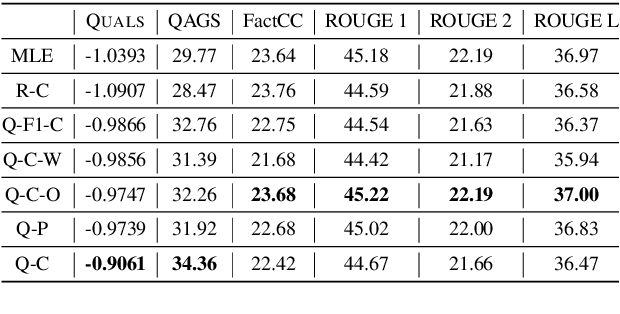
A commonly observed problem with the state-of-the art abstractive summarization models is that the generated summaries can be factually inconsistent with the input documents. The fact that automatic summarization may produce plausible-sounding yet inaccurate summaries is a major concern that limits its wide application. In this paper we present an approach to address factual consistency in summarization. We first propose an efficient automatic evaluation metric to measure factual consistency; next, we propose a novel learning algorithm that maximizes the proposed metric during model training. Through extensive experiments, we confirm that our method is effective in improving factual consistency and even overall quality of the summaries, as judged by both automatic metrics and human evaluation.