 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectralSplats: Robust Differentiable Tracking via Spectral Moment Supervision
Mar 25, 20263D Gaussian Splatting (3DGS) enables real-time, photorealistic novel view synthesis, making it a highly attractive representation for model-based video tracking. However, leveraging the differentiability of the 3DGS renderer "in the wild" remains notoriously fragile. A fundamental bottleneck lies in the compact, local support of the Gaussian primitives. Standard photometric objectives implicitly rely on spatial overlap; if severe camera misalignment places the rendered object outside the target's local footprint, gradients strictly vanish, leaving the optimizer stranded. We introduce SpectralSplats, a robust tracking framework that resolves this "vanishing gradient" problem by shifting the optimization objective from the spatial to the frequency domain. By supervising the rendered image via a set of global complex sinusoidal features (Spectral Moments), we construct a global basin of attraction, ensuring that a valid, directional gradient toward the target exists across the entire image domain, even when pixel overlap is completely nonexistent. To harness this global basin without introducing periodic local minima associated with high frequencies, we derive a principled Frequency Annealing schedule from first principles, gracefully transitioning the optimizer from global convexity to precise spatial alignment. We demonstrate that SpectralSplats acts as a seamless, drop-in replacement for spatial losses across diverse deformation parameterizations (from MLPs to sparse control points), successfully recovering complex deformations even from severely misaligned initializations where standard appearance-based tracking catastrophically fails.
Time-to-Move: Training-Free Motion Controlled Video Generation via Dual-Clock Denoising
Nov 09, 2025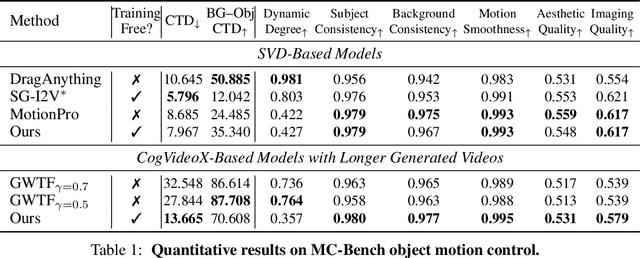
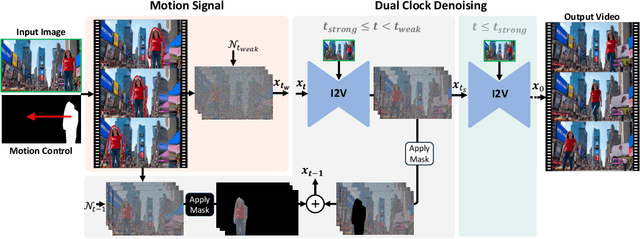
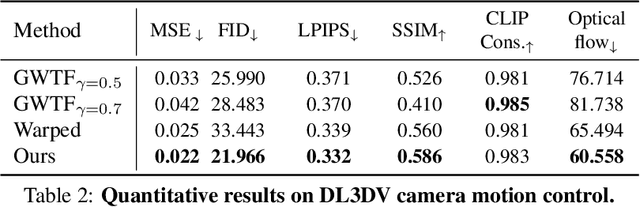
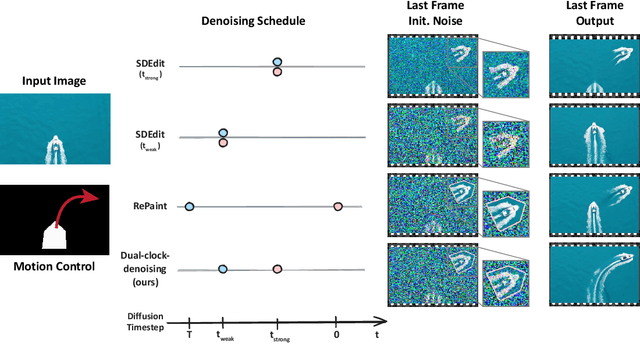
Diffusion-based video generation can create realistic videos, yet existing image- and text-based conditioning fails to offer precise motion control. Prior methods for motion-conditioned synthesis typically require model-specific fine-tuning, which is computationally expensive and restrictive. We introduce Time-to-Move (TTM), a training-free, plug-and-play framework for motion- and appearance-controlled video generation with image-to-video (I2V) diffusion models. Our key insight is to use crude reference animations obtained through user-friendly manipulations such as cut-and-drag or depth-based reprojection. Motivated by SDEdit's use of coarse layout cues for image editing, we treat the crude animations as coarse motion cues and adapt the mechanism to the video domain. We preserve appearance with image conditioning and introduce dual-clock denoising, a region-dependent strategy that enforces strong alignment in motion-specified regions while allowing flexibility elsewhere, balancing fidelity to user intent with natural dynamics. This lightweight modification of the sampling process incurs no additional training or runtime cost and is compatible with any backbone. Extensive experiments on object and camera motion benchmarks show that TTM matches or exceeds existing training-based baselines in realism and motion control. Beyond this, TTM introduces a unique capability: precise appearance control through pixel-level conditioning, exceeding the limits of text-only prompting. Visit our project page for video examples and code: https://time-to-move.github.io/.