 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowBender: Feedback-Aware Training for Self-Correcting Conditional Flows
Jun 18, 2026Conditional diffusion and flow models routinely fail to satisfy the very constraints that define their task. For instance, a depth-conditioned model often produces images whose re-extracted depth disagrees with the input, even though the forward operator--the depth predictor defining the constraint--is available during both training and inference. Existing approaches generally fall into two categories: supervised models that treat the conditioning signal as a static cue and ignore alignment information at inference, and guidance-based methods that consult it through hand-tuned linear updates, typically trading fidelity to the condition against the plausibility of the generated sample. We argue that the fundamental gap in both paradigms is that the model is never trained to utilize its own alignment error. We introduce FlowBender, a closed-loop framework that treats this error as a first-class input, training the network to learn a correction policy conditioned on inference-time feedback. At each step, an unguided look-ahead pass estimates the clean signal, a task-specific deviation is computed via the forward operator, and a refinement pass consumes this signal to produce a corrected velocity. We propose several variants of FlowBender, including a gradient-based formulation for differentiable operators and a zero-order variant for non-differentiable settings such as JPEG compression. For efficient sampling, we introduce a prior-step shortcut that enables closed-loop correction at a minimal additional computational cost. Across image-to-image translation, restoration, and 3D mesh texturing, FlowBender consistently outperforms standard supervised baselines, alignment-loss-augmented training, and state-of-the-art inference-time guidance, improving fidelity and plausibility simultaneously rather than trading them against each other. Project page: https://flow-bender.github.io/
RealMaster: Lifting Rendered Scenes into Photorealistic Video
Mar 24, 2026State-of-the-art video generation models produce remarkable photorealism, but they lack the precise control required to align generated content with specific scene requirements. Furthermore, without an underlying explicit geometry, these models cannot guarantee 3D consistency. Conversely, 3D engines offer granular control over every scene element and provide native 3D consistency by design, yet their output often remains trapped in the "uncanny valley". Bridging this sim-to-real gap requires both structural precision, where the output must exactly preserve the geometry and dynamics of the input, and global semantic transformation, where materials, lighting, and textures must be holistically transformed to achieve photorealism. We present RealMaster, a method that leverages video diffusion models to lift rendered video into photorealistic video while maintaining full alignment with the output of the 3D engine. To train this model, we generate a paired dataset via an anchor-based propagation strategy, where the first and last frames are enhanced for realism and propagated across the intermediate frames using geometric conditioning cues. We then train an IC-LoRA on these paired videos to distill the high-quality outputs of the pipeline into a model that generalizes beyond the pipeline's constraints, handling objects and characters that appear mid-sequence and enabling inference without requiring anchor frames. Evaluated on complex GTA-V sequences, RealMaster significantly outperforms existing video editing baselines, improving photorealism while preserving the geometry, dynamics, and identity specified by the original 3D control.
Appreciate the View: A Task-Aware Evaluation Framework for Novel View Synthesis
Nov 16, 2025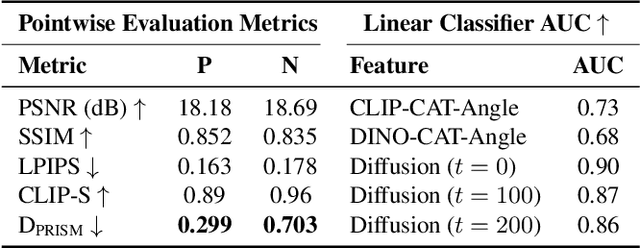
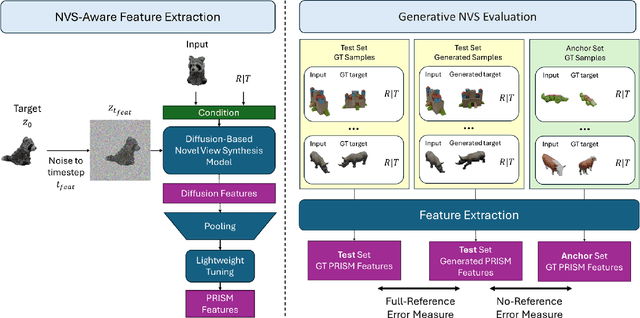
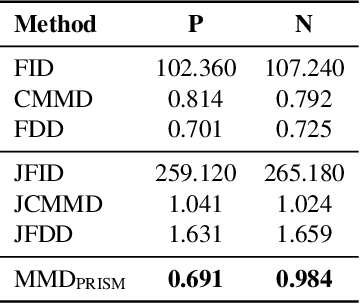
The goal of Novel View Synthesis (NVS) is to generate realistic images of a given content from unseen viewpoints. But how can we trust that a generated image truly reflects the intended transformation? Evaluating its reliability remains a major challenge. While recent generative models, particularly diffusion-based approaches, have significantly improved NVS quality, existing evaluation metrics struggle to assess whether a generated image is both realistic and faithful to the source view and intended viewpoint transformation. Standard metrics, such as pixel-wise similarity and distribution-based measures, often mis-rank incorrect results as they fail to capture the nuanced relationship between the source image, viewpoint change, and generated output. We propose a task-aware evaluation framework that leverages features from a strong NVS foundation model, Zero123, combined with a lightweight tuning step to enhance discrimination. Using these features, we introduce two complementary evaluation metrics: a reference-based score, $D_{\text{PRISM}}$, and a reference-free score, $\text{MMD}_{\text{PRISM}}$. Both reliably identify incorrect generations and rank models in agreement with human preference studies, addressing a fundamental gap in NVS evaluation. Our framework provides a principled and practical approach to assessing synthesis quality, paving the way for more reliable progress in novel view synthesis. To further support this goal, we apply our reference-free metric to six NVS methods across three benchmarks: Toys4K, Google Scanned Objects (GSO), and OmniObject3D, where $\text{MMD}_{\text{PRISM}}$ produces a clear and stable ranking, with lower scores consistently indicating stronger models.
A Lesson in Splats: Teacher-Guided Diffusion for 3D Gaussian Splats Generation with 2D Supervision
Dec 01, 2024



We introduce a diffusion model for Gaussian Splats, SplatDiffusion, to enable generation of three-dimensional structures from single images, addressing the ill-posed nature of lifting 2D inputs to 3D. Existing methods rely on deterministic, feed-forward predictions, which limit their ability to handle the inherent ambiguity of 3D inference from 2D data. Diffusion models have recently shown promise as powerful generative models for 3D data, including Gaussian splats; however, standard diffusion frameworks typically require the target signal and denoised signal to be in the same modality, which is challenging given the scarcity of 3D data. To overcome this, we propose a novel training strategy that decouples the denoised modality from the supervision modality. By using a deterministic model as a noisy teacher to create the noised signal and transitioning from single-step to multi-step denoising supervised by an image rendering loss, our approach significantly enhances performance compared to the deterministic teacher. Additionally, our method is flexible, as it can learn from various 3D Gaussian Splat (3DGS) teachers with minimal adaptation; we demonstrate this by surpassing the performance of two different deterministic models as teachers, highlighting the potential generalizability of our framework. Our approach further incorporates a guidance mechanism to aggregate information from multiple views, enhancing reconstruction quality when more than one view is available. Experimental results on object-level and scene-level datasets demonstrate the effectiveness of our framework.
Zero-to-Hero: Enhancing Zero-Shot Novel View Synthesis via Attention Map Filtering
May 29, 2024Generating realistic images from arbitrary views based on a single source image remains a significant challenge in computer vision, with broad applications ranging from e-commerce to immersive virtual experiences. Recent advancements in diffusion models, particularly the Zero-1-to-3 model, have been widely adopted for generating plausible views, videos, and 3D models. However, these models still struggle with inconsistencies and implausibility in new views generation, especially for challenging changes in viewpoint. In this work, we propose Zero-to-Hero, a novel test-time approach that enhances view synthesis by manipulating attention maps during the denoising process of Zero-1-to-3. By drawing an analogy between the denoising process and stochastic gradient descent (SGD), we implement a filtering mechanism that aggregates attention maps, enhancing generation reliability and authenticity. This process improves geometric consistency without requiring retraining or significant computational resources. Additionally, we modify the self-attention mechanism to integrate information from the source view, reducing shape distortions. These processes are further supported by a specialized sampling schedule. Experimental results demonstrate substantial improvements in fidelity and consistency, validated on a diverse set of out-of-distribution objects.