 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowBender: Feedback-Aware Training for Self-Correcting Conditional Flows
Jun 18, 2026Conditional diffusion and flow models routinely fail to satisfy the very constraints that define their task. For instance, a depth-conditioned model often produces images whose re-extracted depth disagrees with the input, even though the forward operator--the depth predictor defining the constraint--is available during both training and inference. Existing approaches generally fall into two categories: supervised models that treat the conditioning signal as a static cue and ignore alignment information at inference, and guidance-based methods that consult it through hand-tuned linear updates, typically trading fidelity to the condition against the plausibility of the generated sample. We argue that the fundamental gap in both paradigms is that the model is never trained to utilize its own alignment error. We introduce FlowBender, a closed-loop framework that treats this error as a first-class input, training the network to learn a correction policy conditioned on inference-time feedback. At each step, an unguided look-ahead pass estimates the clean signal, a task-specific deviation is computed via the forward operator, and a refinement pass consumes this signal to produce a corrected velocity. We propose several variants of FlowBender, including a gradient-based formulation for differentiable operators and a zero-order variant for non-differentiable settings such as JPEG compression. For efficient sampling, we introduce a prior-step shortcut that enables closed-loop correction at a minimal additional computational cost. Across image-to-image translation, restoration, and 3D mesh texturing, FlowBender consistently outperforms standard supervised baselines, alignment-loss-augmented training, and state-of-the-art inference-time guidance, improving fidelity and plausibility simultaneously rather than trading them against each other. Project page: https://flow-bender.github.io/
Déjà View: Looping Transformers for Multi-View 3D Reconstruction
May 28, 2026Recent feed-forward 3D reconstruction transformers have scaled to over a billion parameters, following the broader trend of increasing model capacity in computer vision. Yet emerging evidence suggests that contiguous transformer layers often behave like repeated applications of similar operations, and multi-view reconstruction transformers refine their predictions progressively across decoder depth. We posit that model depth partially buys iteration, paid for inefficiently in unique parameters, and instead make that iteration explicit in architecture. Our model, DéjàView, applies a single looped transformer block recurrently to per-view features for K refinement steps. Trained once, it exposes K as an inference-time compute knob, matching or outperforming substantially larger feed-forward baselines across five reconstruction benchmarks spanning indoor, outdoor, object-centric, and driving scenes, while using a fraction of their parameters and comparable or lower compute. Importantly, the same looped block formulation outperforms an otherwise identical variant with independent per-step parameters under matched training data and compute, suggesting that explicit iteration is not merely a compute-efficient substitute for capacity but a stronger inductive bias for multi-view 3D reconstruction.
VGG-T$^3$: Offline Feed-Forward 3D Reconstruction at Scale
Feb 26, 2026We present a scalable 3D reconstruction model that addresses a critical limitation in offline feed-forward methods: their computational and memory requirements grow quadratically w.r.t. the number of input images. Our approach is built on the key insight that this bottleneck stems from the varying-length Key-Value (KV) space representation of scene geometry, which we distill into a fixed-size Multi-Layer Perceptron (MLP) via test-time training. VGG-T$^3$ (Visual Geometry Grounded Test Time Training) scales linearly w.r.t. the number of input views, similar to online models, and reconstructs a $1k$ image collection in just $54$ seconds, achieving a $11.6\times$ speed-up over baselines that rely on softmax attention. Since our method retains global scene aggregation capability, our point map reconstruction error outperforming other linear-time methods by large margins. Finally, we demonstrate visual localization capabilities of our model by querying the scene representation with unseen images.
Test-Time Training with KV Binding Is Secretly Linear Attention
Feb 24, 2026Test-time training (TTT) with KV binding as sequence modeling layer is commonly interpreted as a form of online meta-learning that memorizes a key-value mapping at test time. However, our analysis reveals multiple phenomena that contradict this memorization-based interpretation. Motivated by these findings, we revisit the formulation of TTT and show that a broad class of TTT architectures can be expressed as a form of learned linear attention operator. Beyond explaining previously puzzling model behaviors, this perspective yields multiple practical benefits: it enables principled architectural simplifications, admits fully parallel formulations that preserve performance while improving efficiency, and provides a systematic reduction of diverse TTT variants to a standard linear attention form. Overall, our results reframe TTT not as test-time memorization, but as learned linear attention with enhanced representational capacity.
LongPerceptualThoughts: Distilling System-2 Reasoning for System-1 Perception
Apr 21, 2025Recent reasoning models through test-time scaling have demonstrated that long chain-of-thoughts can unlock substantial performance boosts in hard reasoning tasks such as math and code. However, the benefit of such long thoughts for system-2 reasoning is relatively less explored in other domains such as perceptual tasks where shallower, system-1 reasoning seems sufficient. In this paper, we introduce LongPerceptualThoughts, a new synthetic dataset with 30K long-thought traces for perceptual tasks. The key challenges in synthesizing elaborate reasoning thoughts for perceptual tasks are that off-the-shelf models are not yet equipped with such thinking behavior and that it is not straightforward to build a reliable process verifier for perceptual tasks. Thus, we propose a novel three-stage data synthesis framework that first synthesizes verifiable multiple-choice questions from dense image descriptions, then extracts simple CoTs from VLMs for those verifiable problems, and finally expands those simple thoughts to elaborate long thoughts via frontier reasoning models. In controlled experiments with a strong instruction-tuned 7B model, we demonstrate notable improvements over existing visual reasoning data-generation methods. Our model, trained on the generated dataset, achieves an average +3.4 points improvement over 5 vision-centric benchmarks, including +11.8 points on V$^*$ Bench. Notably, despite being tuned for vision tasks, it also improves performance on the text reasoning benchmark, MMLU-Pro, by +2 points.
MATCHA:Towards Matching Anything
Jan 24, 2025



Establishing correspondences across images is a fundamental challenge in computer vision, underpinning tasks like Structure-from-Motion, image editing, and point tracking. Traditional methods are often specialized for specific correspondence types, geometric, semantic, or temporal, whereas humans naturally identify alignments across these domains. Inspired by this flexibility, we propose MATCHA, a unified feature model designed to ``rule them all'', establishing robust correspondences across diverse matching tasks. Building on insights that diffusion model features can encode multiple correspondence types, MATCHA augments this capacity by dynamically fusing high-level semantic and low-level geometric features through an attention-based module, creating expressive, versatile, and robust features. Additionally, MATCHA integrates object-level features from DINOv2 to further boost generalization, enabling a single feature capable of matching anything. Extensive experiments validate that MATCHA consistently surpasses state-of-the-art methods across geometric, semantic, and temporal matching tasks, setting a new foundation for a unified approach for the fundamental correspondence problem in computer vision. To the best of our knowledge, MATCHA is the first approach that is able to effectively tackle diverse matching tasks with a single unified feature.
Light3R-SfM: Towards Feed-forward Structure-from-Motion
Jan 24, 2025



We present Light3R-SfM, a feed-forward, end-to-end learnable framework for efficient large-scale Structure-from-Motion (SfM) from unconstrained image collections. Unlike existing SfM solutions that rely on costly matching and global optimization to achieve accurate 3D reconstructions, Light3R-SfM addresses this limitation through a novel latent global alignment module. This module replaces traditional global optimization with a learnable attention mechanism, effectively capturing multi-view constraints across images for robust and precise camera pose estimation. Light3R-SfM constructs a sparse scene graph via retrieval-score-guided shortest path tree to dramatically reduce memory usage and computational overhead compared to the naive approach. Extensive experiments demonstrate that Light3R-SfM achieves competitive accuracy while significantly reducing runtime, making it ideal for 3D reconstruction tasks in real-world applications with a runtime constraint. This work pioneers a data-driven, feed-forward SfM approach, paving the way toward scalable, accurate, and efficient 3D reconstruction in the wild.
MG-GAN: A Multi-Generator Model Preventing Out-of-Distribution Samples in Pedestrian Trajectory Prediction
Aug 20, 2021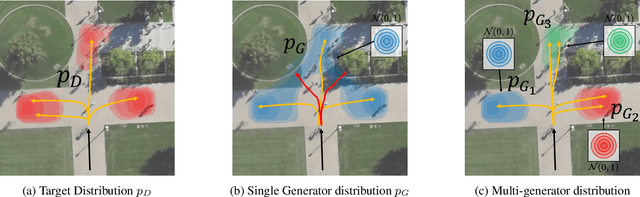
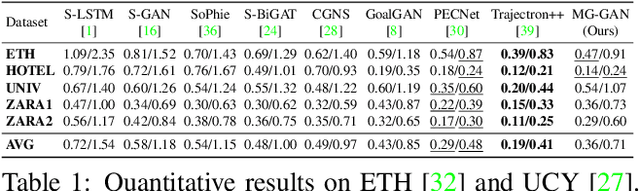
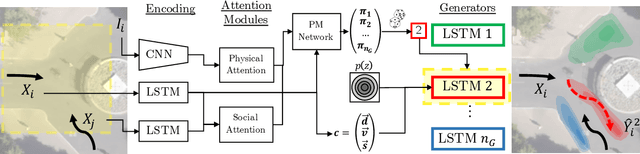
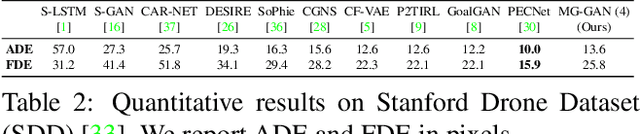
Pedestrian trajectory prediction is challenging due to its uncertain and multimodal nature. While generative adversarial networks can learn a distribution over future trajectories, they tend to predict out-of-distribution samples when the distribution of future trajectories is a mixture of multiple, possibly disconnected modes. To address this issue, we propose a multi-generator model for pedestrian trajectory prediction. Each generator specializes in learning a distribution over trajectories routing towards one of the primary modes in the scene, while a second network learns a categorical distribution over these generators, conditioned on the dynamics and scene input. This architecture allows us to effectively sample from specialized generators and to significantly reduce the out-of-distribution samples compared to single generator methods.
On Out-of-distribution Detection with Energy-based Models
Jul 03, 2021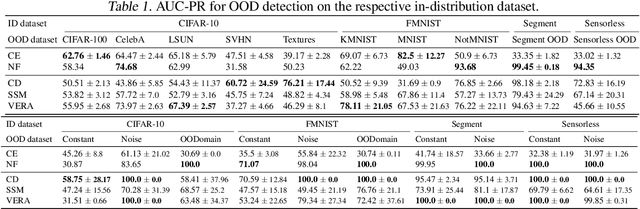
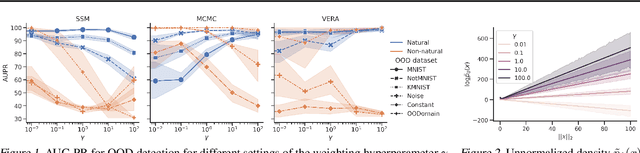
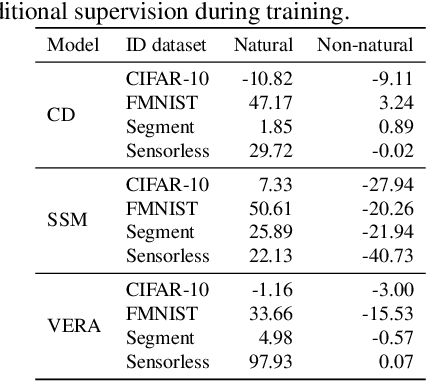
Several density estimation methods have shown to fail to detect out-of-distribution (OOD) samples by assigning higher likelihoods to anomalous data. Energy-based models (EBMs) are flexible, unnormalized density models which seem to be able to improve upon this failure mode. In this work, we provide an extensive study investigating OOD detection with EBMs trained with different approaches on tabular and image data and find that EBMs do not provide consistent advantages. We hypothesize that EBMs do not learn semantic features despite their discriminative structure similar to Normalizing Flows. To verify this hypotheses, we show that supervision and architectural restrictions improve the OOD detection of EBMs independent of the training approach.