 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose Adaptive Dual Mixup for Few-Shot Single-View 3D Reconstruction
Dec 23, 2021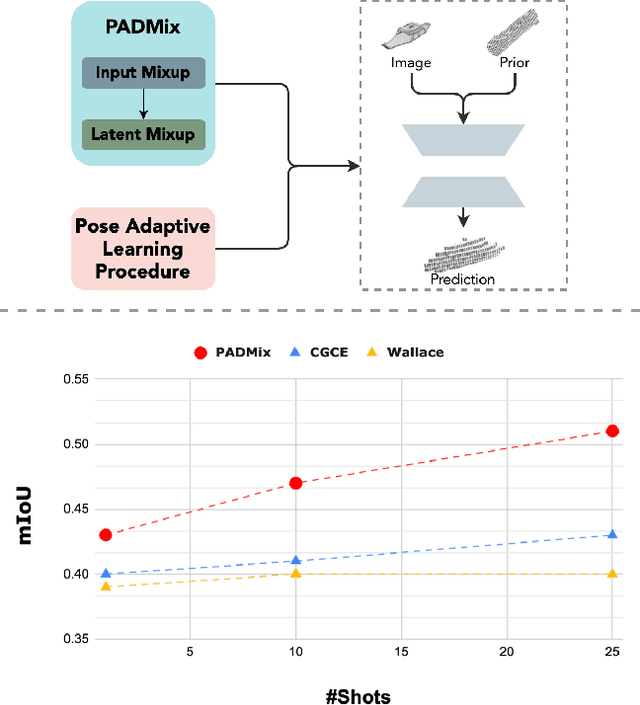
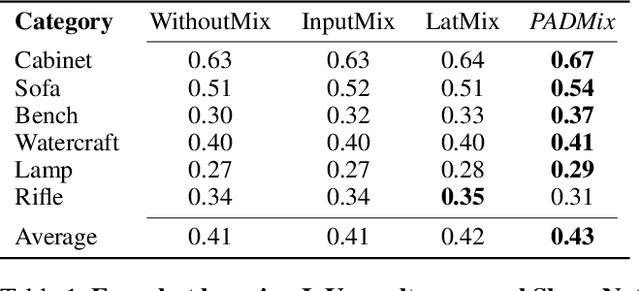
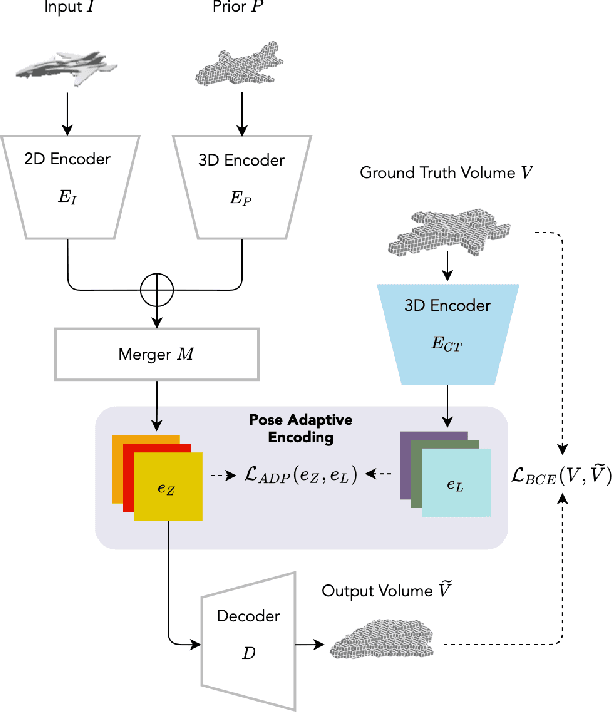
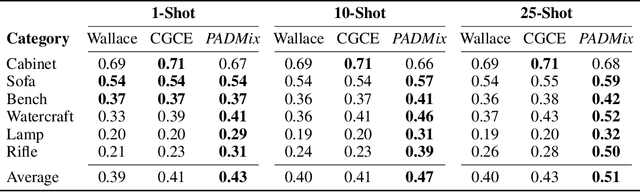
We present a pose adaptive few-shot learning procedure and a two-stage data interpolation regularization, termed Pose Adaptive Dual Mixup (PADMix), for single-image 3D reconstruction. While augmentations via interpolating feature-label pairs are effective in classification tasks, they fall short in shape predictions potentially due to inconsistencies between interpolated products of two images and volumes when rendering viewpoints are unknown. PADMix targets this issue with two sets of mixup procedures performed sequentially. We first perform an input mixup which, combined with a pose adaptive learning procedure, is helpful in learning 2D feature extraction and pose adaptive latent encoding. The stagewise training allows us to build upon the pose invariant representations to perform a follow-up latent mixup under one-to-one correspondences between features and ground-truth volumes. PADMix significantly outperforms previous literature on few-shot settings over the ShapeNet dataset and sets new benchmarks on the more challenging real-world Pix3D dataset.
Deep Odometry Systems on Edge with EKF-LoRa Backend for Real-Time Positioning in Adverse Environment
Dec 10, 2021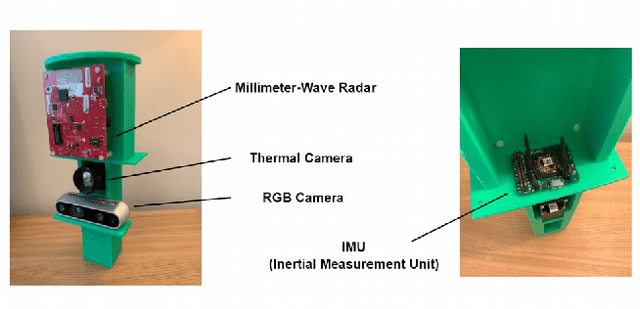
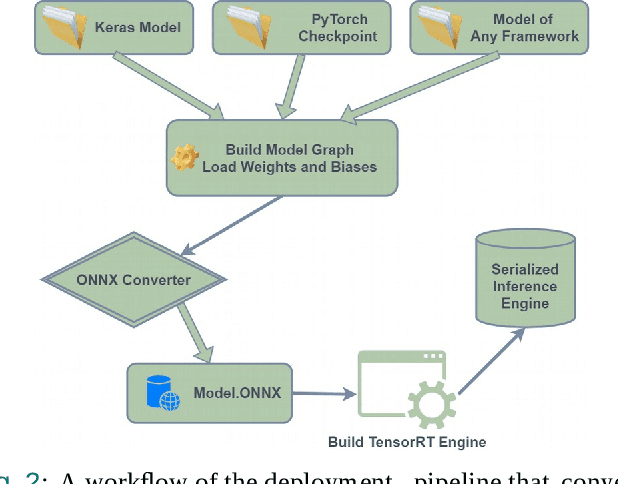
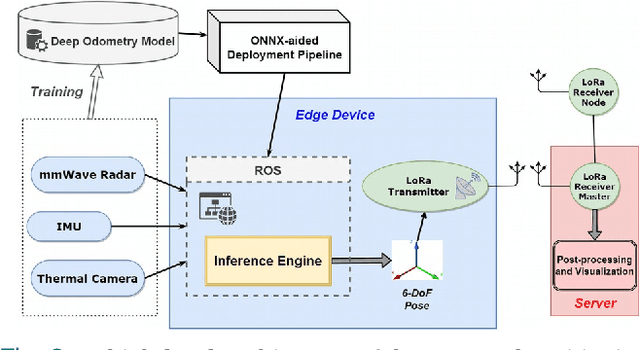
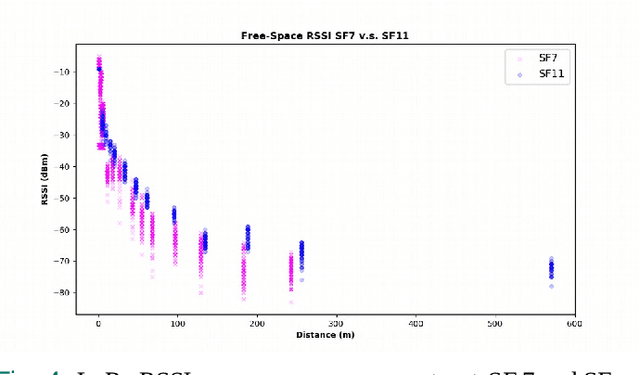
Ubiquitous positioning for pedestrian in adverse environment has served a long standing challenge. Despite dramatic progress made by Deep Learning, multi-sensor deep odometry systems yet pose a high computational cost and suffer from cumulative drifting errors over time. Thanks to the increasing computational power of edge devices, we propose a novel ubiquitous positioning solution by integrating state-of-the-art deep odometry models on edge with an EKF (Extended Kalman Filter)-LoRa backend. We carefully compare and select three sensor modalities, i.e., an Inertial Measurement Unit (IMU), a millimetre-wave (mmWave) radar, and a thermal infrared camera, and realise their deep odometry inference engines which runs in real-time. A pipeline of deploying deep odometry considering accuracy, complexity, and edge platform is proposed. We design a LoRa link for positional data backhaul and projecting aggregated positions of deep odometry into the global frame. We find that a simple EKF based fusion module is sufficient for generic positioning calibration with over 34% accuracy gains against any standalone deep odometry system. Extensive tests in different environments validate the efficiency and efficacy of our proposed positioning system.
DeepAoANet: Learning Angle of Arrival from Software Defined Radios with Deep Neural Networks
Dec 09, 2021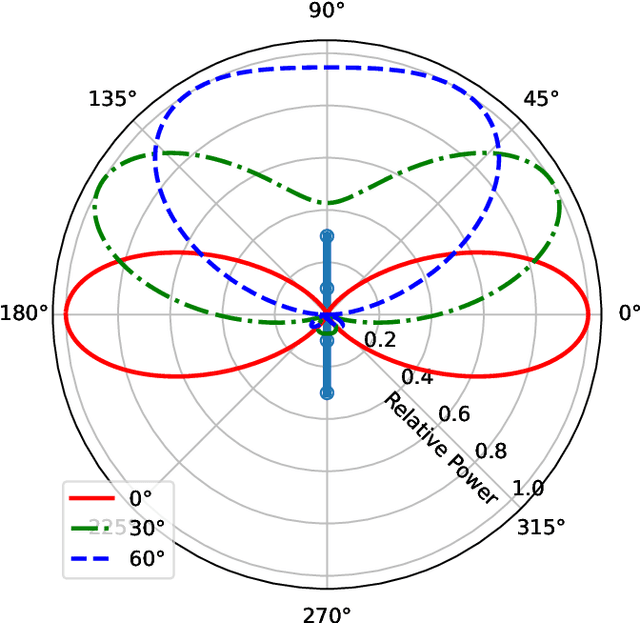
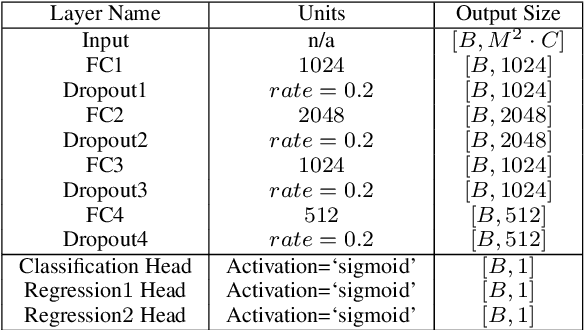
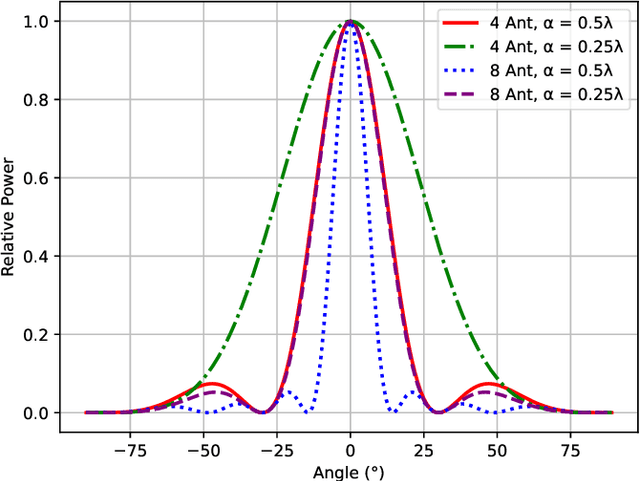
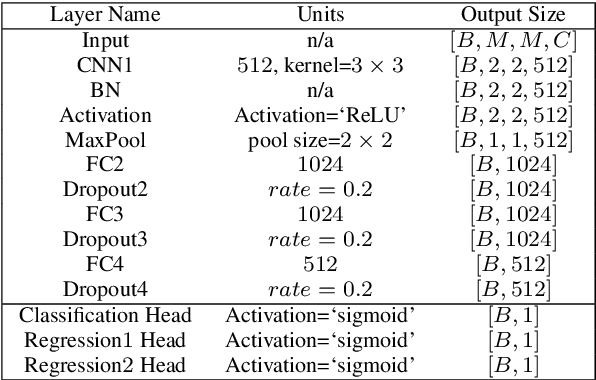
Direction finding and positioning systems based on RF signals are significantly impacted by multipath propagation, particularly in indoor environments. Existing algorithms (e.g MUSIC) perform poorly in resolving Angle of Arrival (AoA) in the presence of multipath or when operating in a weak signal regime. We note that digitally sampled RF frontends allow for the easy analysis of signals, and their delayed components. Low-cost Software-Defined Radio (SDR) modules enable Channel State Information (CSI) extraction across a wide spectrum, motivating the design of an enhanced Angle-of-Arrival (AoA) solution. We propose a Deep Learning approach to deriving AoA from a single snapshot of the SDR multichannel data. We compare and contrast deep-learning based angle classification and regression models, to estimate up to two AoAs accurately. We have implemented the inference engines on different platforms to extract AoAs in real-time, demonstrating the computational tractability of our approach. To demonstrate the utility of our approach we have collected IQ (In-phase and Quadrature components) samples from a four-element Universal Linear Array (ULA) in various Light-of-Sight (LOS) and Non-Line-of-Sight (NLOS) environments, and published the dataset. Our proposed method demonstrates excellent reliability in determining number of impinging signals and realized mean absolute AoA errors less than $2^{\circ}$.
CubeLearn: End-to-end Learning for Human Motion Recognition from Raw mmWave Radar Signals
Nov 07, 2021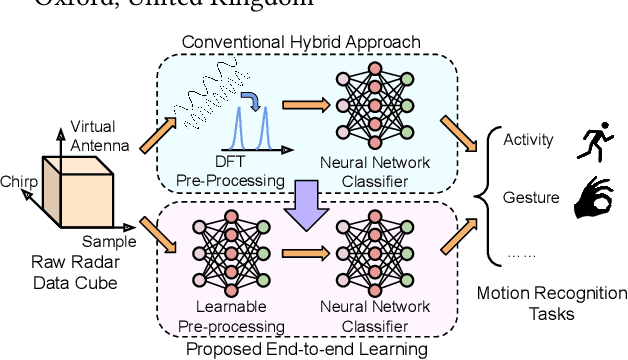

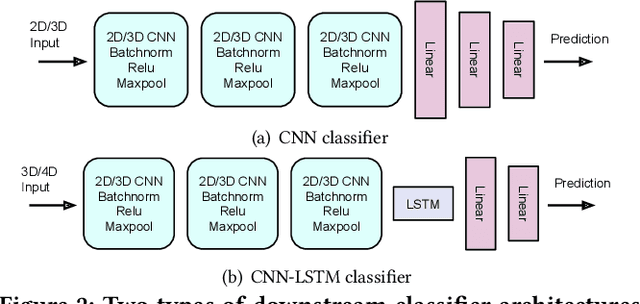

mmWave FMCW radar has attracted huge amount of research interest for human-centered applications in recent years, such as human gesture/activity recognition. Most existing pipelines are built upon conventional Discrete Fourier Transform (DFT) pre-processing and deep neural network classifier hybrid methods, with a majority of previous works focusing on designing the downstream classifier to improve overall accuracy. In this work, we take a step back and look at the pre-processing module. To avoid the drawbacks of conventional DFT pre-processing, we propose a learnable pre-processing module, named CubeLearn, to directly extract features from raw radar signal and build an end-to-end deep neural network for mmWave FMCW radar motion recognition applications. Extensive experiments show that our CubeLearn module consistently improves the classification accuracies of different pipelines, especially benefiting those previously weaker models. We provide ablation studies on initialization methods and structure of the proposed module, as well as an evaluation of the running time on PC and edge devices. This work also serves as a comparison of different approaches towards data cube slicing. Through our task agnostic design, we propose a first step towards a generic end-to-end solution for radar recognition problems.
Learning Semantic Segmentation of Large-Scale Point Clouds with Random Sampling
Jul 06, 2021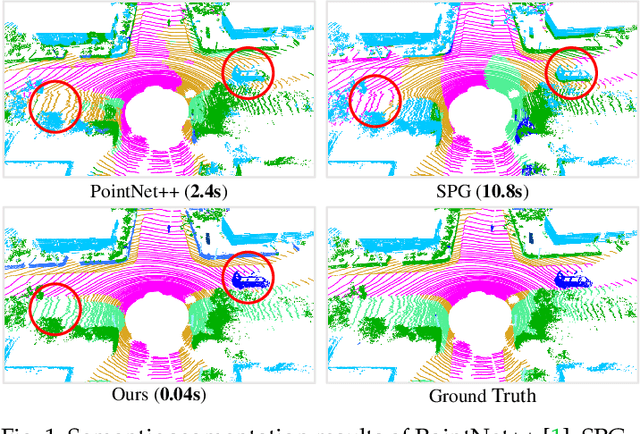
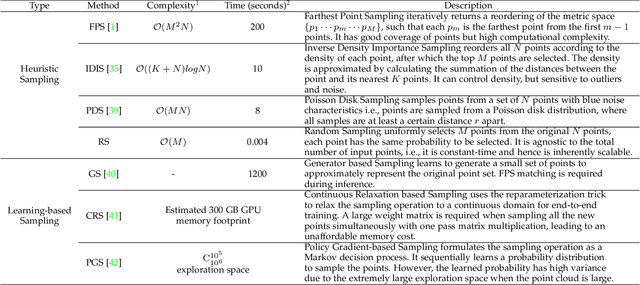
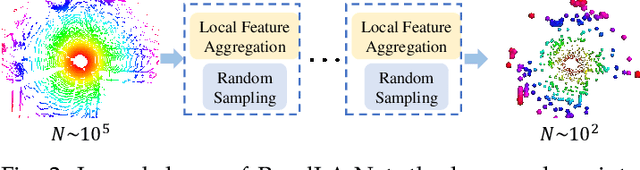
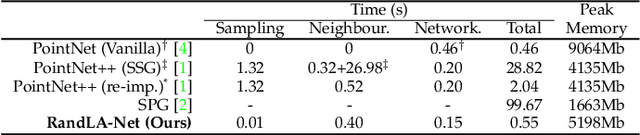
We study the problem of efficient semantic segmentation of large-scale 3D point clouds. By relying on expensive sampling techniques or computationally heavy pre/post-processing steps, most existing approaches are only able to be trained and operate over small-scale point clouds. In this paper, we introduce RandLA-Net, an efficient and lightweight neural architecture to directly infer per-point semantics for large-scale point clouds. The key to our approach is to use random point sampling instead of more complex point selection approaches. Although remarkably computation and memory efficient, random sampling can discard key features by chance. To overcome this, we introduce a novel local feature aggregation module to progressively increase the receptive field for each 3D point, thereby effectively preserving geometric details. Comparative experiments show that our RandLA-Net can process 1 million points in a single pass up to 200x faster than existing approaches. Moreover, extensive experiments on five large-scale point cloud datasets, including Semantic3D, SemanticKITTI, Toronto3D, NPM3D and S3DIS, demonstrate the state-of-the-art semantic segmentation performance of our RandLA-Net.
SoundDet: Polyphonic Sound Event Detection and Localization from Raw Waveform
Jun 13, 2021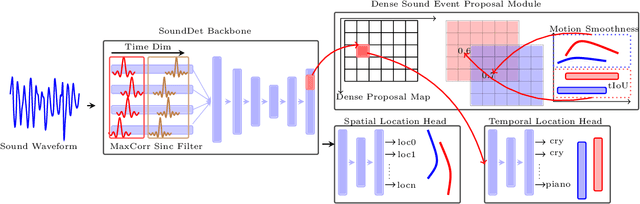
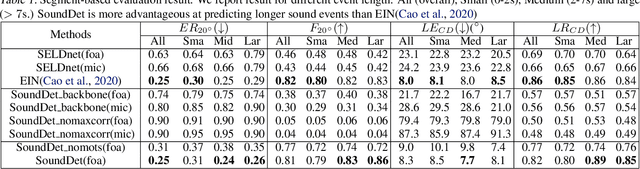
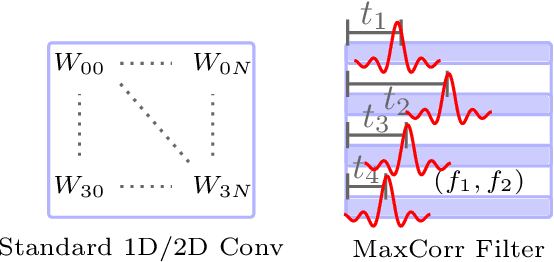
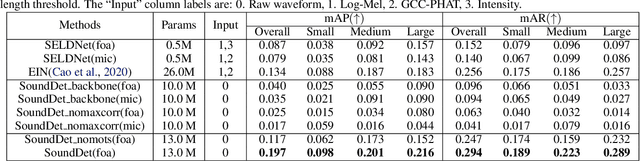
We present a new framework SoundDet, which is an end-to-end trainable and light-weight framework, for polyphonic moving sound event detection and localization. Prior methods typically approach this problem by preprocessing raw waveform into time-frequency representations, which is more amenable to process with well-established image processing pipelines. Prior methods also detect in segment-wise manner, leading to incomplete and partial detections. SoundDet takes a novel approach and directly consumes the raw, multichannel waveform and treats the spatio-temporal sound event as a complete ``sound-object" to be detected. Specifically, SoundDet consists of a backbone neural network and two parallel heads for temporal detection and spatial localization, respectively. Given the large sampling rate of raw waveform, the backbone network first learns a set of phase-sensitive and frequency-selective bank of filters to explicitly retain direction-of-arrival information, whilst being highly computationally and parametrically efficient than standard 1D/2D convolution. A dense sound event proposal map is then constructed to handle the challenges of predicting events with large varying temporal duration. Accompanying the dense proposal map are a temporal overlapness map and a motion smoothness map that measure a proposal's confidence to be an event from temporal detection accuracy and movement consistency perspective. Involving the two maps guarantees SoundDet to be trained in a spatio-temporally unified manner. Experimental results on the public DCASE dataset show the advantage of SoundDet on both segment-based and our newly proposed event-based evaluation system.
Graph-based Thermal-Inertial SLAM with Probabilistic Neural Networks
Apr 18, 2021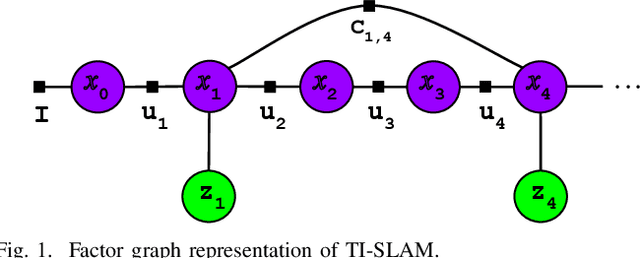
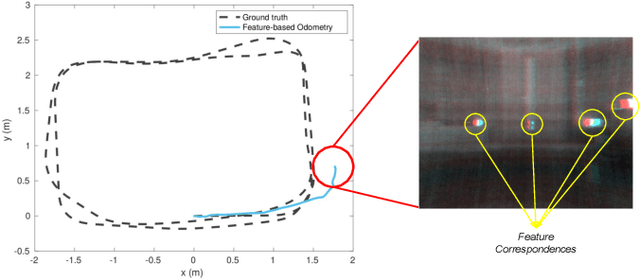
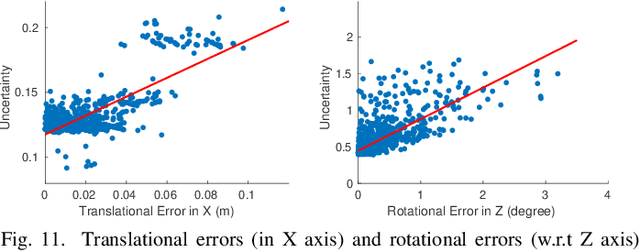
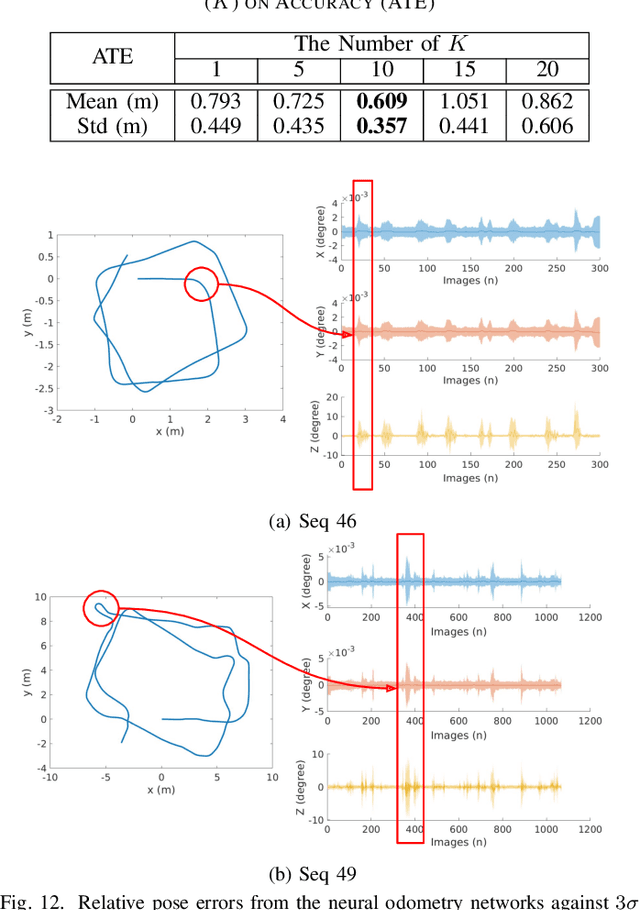
Simultaneous Localization and Mapping (SLAM) system typically employ vision-based sensors to observe the surrounding environment. However, the performance of such systems highly depends on the ambient illumination conditions. In scenarios with adverse visibility or in the presence of airborne particulates (e.g. smoke, dust, etc.), alternative modalities such as those based on thermal imaging and inertial sensors are more promising. In this paper, we propose the first complete thermal-inertial SLAM system which combines neural abstraction in the SLAM front end with robust pose graph optimization in the SLAM back end. We model the sensor abstraction in the front end by employing probabilistic deep learning parameterized by Mixture Density Networks (MDN). Our key strategies to successfully model this encoding from thermal imagery are the usage of normalized 14-bit radiometric data, the incorporation of hallucinated visual (RGB) features, and the inclusion of feature selection to estimate the MDN parameters. To enable a full SLAM system, we also design an efficient global image descriptor which is able to detect loop closures from thermal embedding vectors. We performed extensive experiments and analysis using three datasets, namely self-collected ground robot and handheld data taken in indoor environment, and one public dataset (SubT-tunnel) collected in underground tunnel. Finally, we demonstrate that an accurate thermal-inertial SLAM system can be realized in conditions of both benign and adverse visibility.
SQN: Weakly-Supervised Semantic Segmentation of Large-Scale 3D Point Clouds with 1000x Fewer Labels
Apr 11, 2021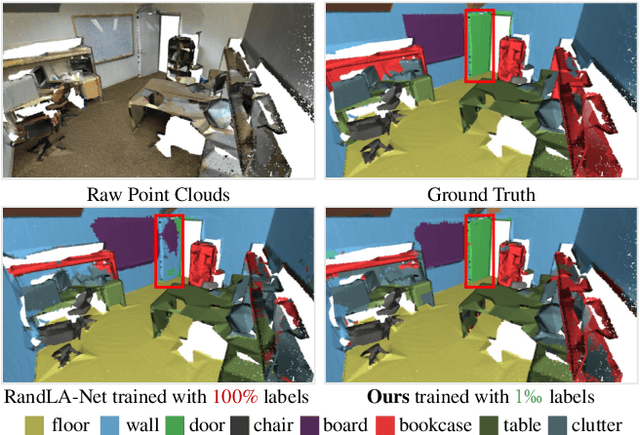
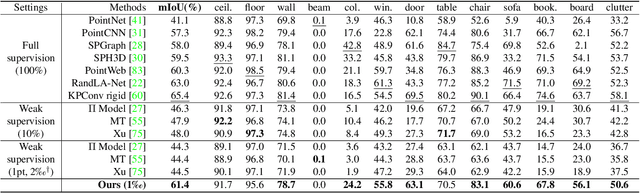
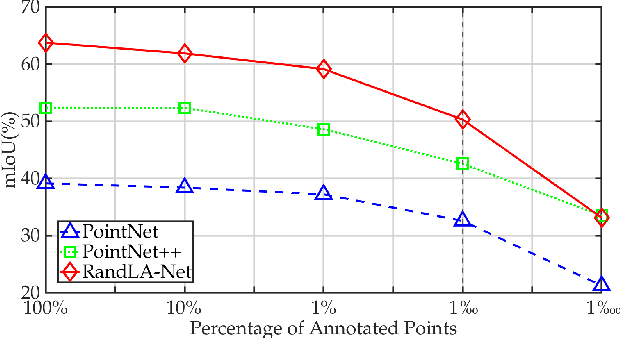
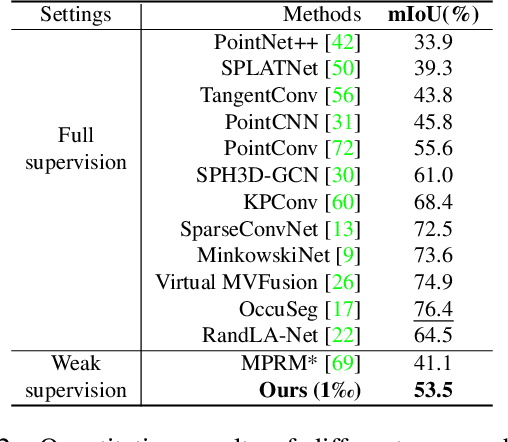
We study the problem of labelling effort for semantic segmentation of large-scale 3D point clouds. Existing works usually rely on densely annotated point-level semantic labels to provide supervision for network training. However, in real-world scenarios that contain billions of points, it is impractical and extremely costly to manually annotate every single point. In this paper, we first investigate whether dense 3D labels are truly required for learning meaningful semantic representations. Interestingly, we find that the segmentation performance of existing works only drops slightly given as few as 1% of the annotations. However, beyond this point (e.g. 1 per thousand and below) existing techniques fail catastrophically. To this end, we propose a new weak supervision method to implicitly augment the total amount of available supervision signals, by leveraging the semantic similarity between neighboring points. Extensive experiments demonstrate that the proposed Semantic Query Network (SQN) achieves state-of-the-art performance on six large-scale open datasets under weak supervision schemes, while requiring only 1000x fewer labeled points for training. The code is available at https://github.com/QingyongHu/SQN.
RadarLoc: Learning to Relocalize in FMCW Radar
Mar 22, 2021
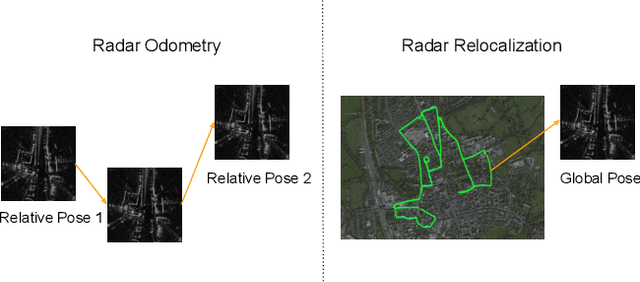
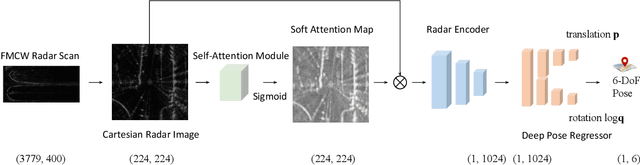
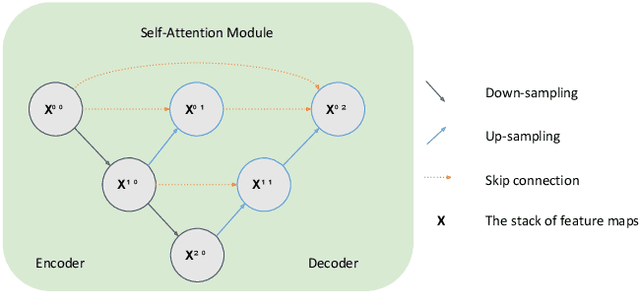
Relocalization is a fundamental task in the field of robotics and computer vision. There is considerable work in the field of deep camera relocalization, which directly estimates poses from raw images. However, learning-based methods have not yet been applied to the radar sensory data. In this work, we investigate how to exploit deep learning to predict global poses from Emerging Frequency-Modulated Continuous Wave (FMCW) radar scans. Specifically, we propose a novel end-to-end neural network with self-attention, termed RadarLoc, which is able to estimate 6-DoF global poses directly. We also propose to improve the localization performance by utilizing geometric constraints between radar scans. We validate our approach on the recently released challenging outdoor dataset Oxford Radar RobotCar. Comprehensive experiments demonstrate that the proposed method outperforms radar-based localization and deep camera relocalization methods by a significant margin.
P2-Net: Joint Description and Detection of Local Features for Pixel and Point Matching
Mar 01, 2021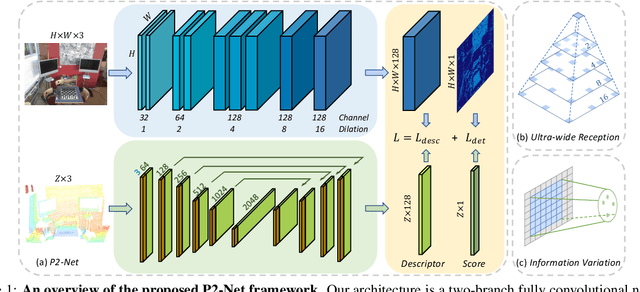
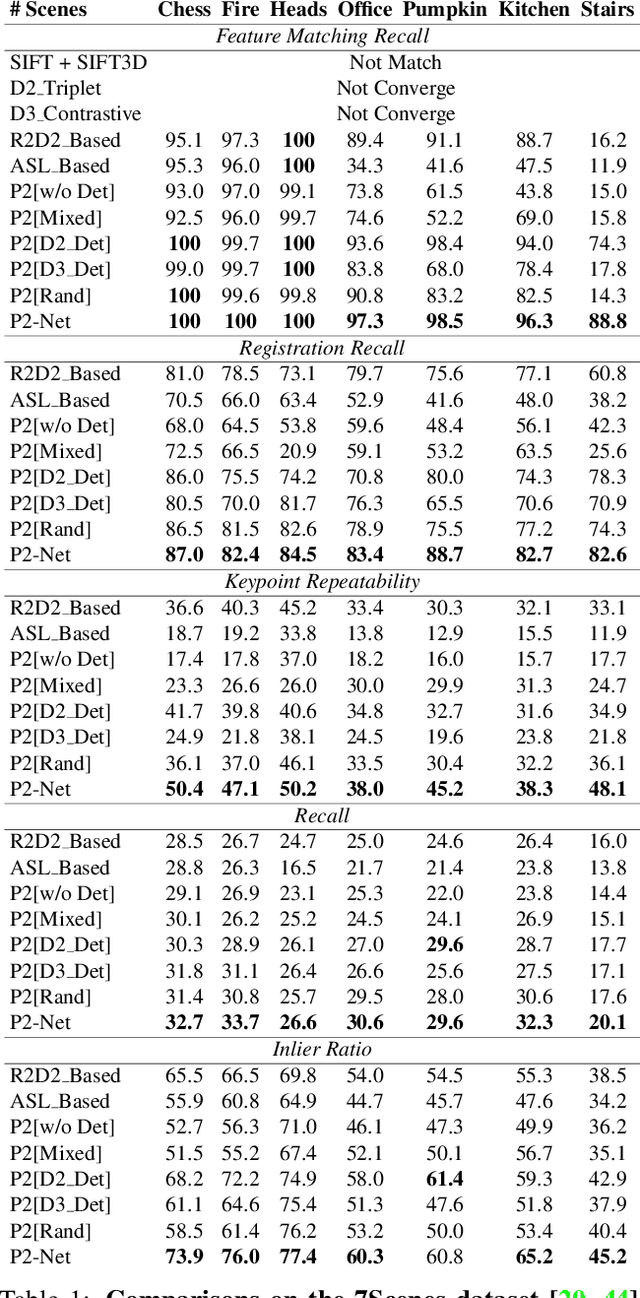
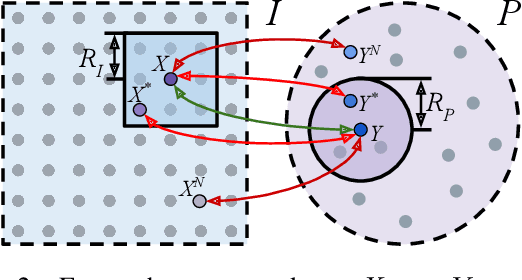
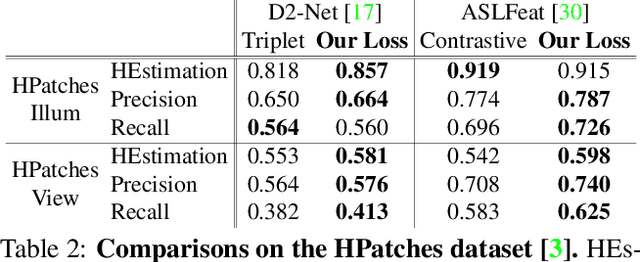
Accurately describing and detecting 2D and 3D keypoints is crucial to establishing correspondences across images and point clouds. Despite a plethora of learning-based 2D or 3D local feature descriptors and detectors having been proposed, the derivation of a shared descriptor and joint keypoint detector that directly matches pixels and points remains under-explored by the community. This work takes the initiative to establish fine-grained correspondences between 2D images and 3D point clouds. In order to directly match pixels and points, a dual fully convolutional framework is presented that maps 2D and 3D inputs into a shared latent representation space to simultaneously describe and detect keypoints. Furthermore, an ultra-wide reception mechanism in combination with a novel loss function are designed to mitigate the intrinsic information variations between pixel and point local regions. Extensive experimental results demonstrate that our framework shows competitive performance in fine-grained matching between images and point clouds and achieves state-of-the-art results for the task of indoor visual localization. Our source code will be available at [no-name-for-blind-review].