 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Intrinsic Common Discriminative Features Learning for Face Forgery Detection using Adversarial Learning
Jul 08, 2022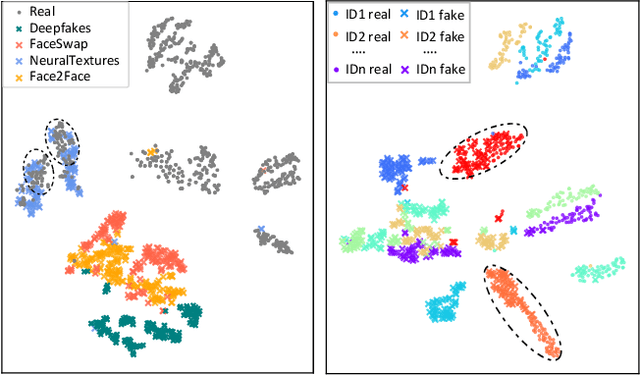
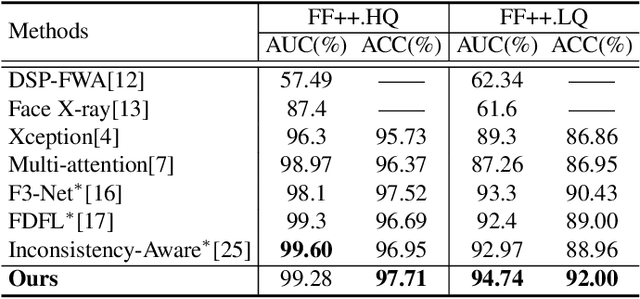
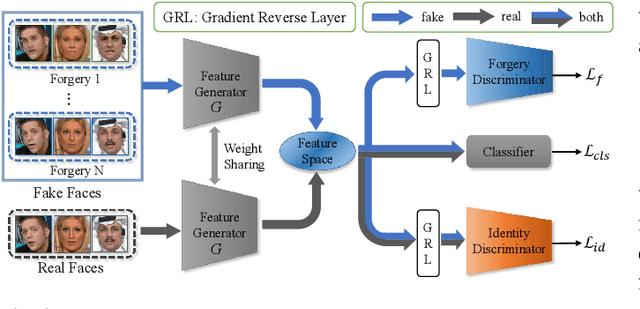
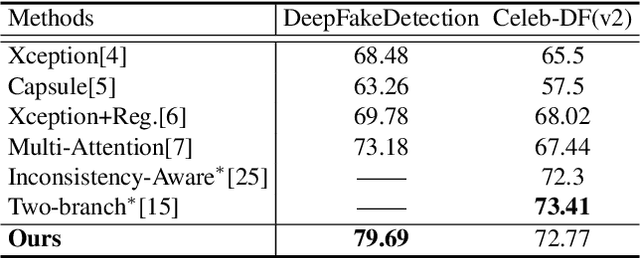
Existing face forgery detection methods usually treat face forgery detection as a binary classification problem and adopt deep convolution neural networks to learn discriminative features. The ideal discriminative features should be only related to the real/fake labels of facial images. However, we observe that the features learned by vanilla classification networks are correlated to unnecessary properties, such as forgery methods and facial identities. Such phenomenon would limit forgery detection performance especially for the generalization ability. Motivated by this, we propose a novel method which utilizes adversarial learning to eliminate the negative effect of different forgery methods and facial identities, which helps classification network to learn intrinsic common discriminative features for face forgery detection. To leverage data lacking ground truth label of facial identities, we design a special identity discriminator based on similarity information derived from off-the-shelf face recognition model. With the help of adversarial learning, our face forgery detection model learns to extract common discriminative features through eliminating the effect of forgery methods and facial identities. Extensive experiments demonstrate the effectiveness of the proposed method under both intra-dataset and cross-dataset evaluation settings.
Reduce Information Loss in Transformers for Pluralistic Image Inpainting
May 15, 2022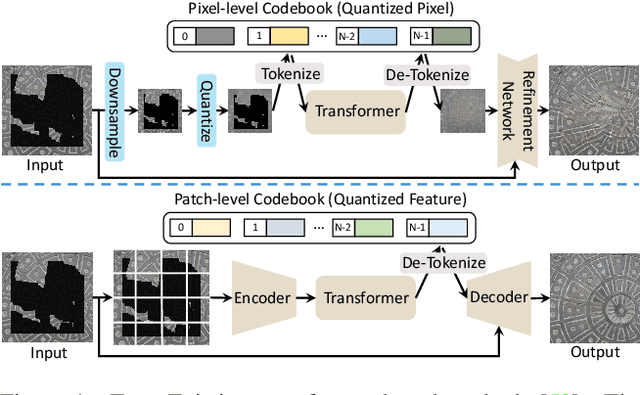
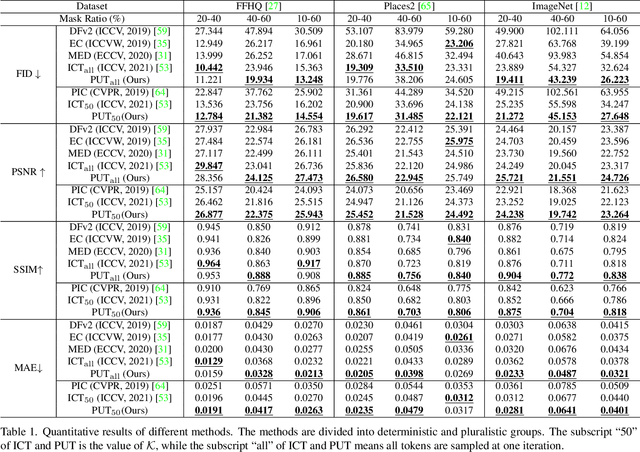
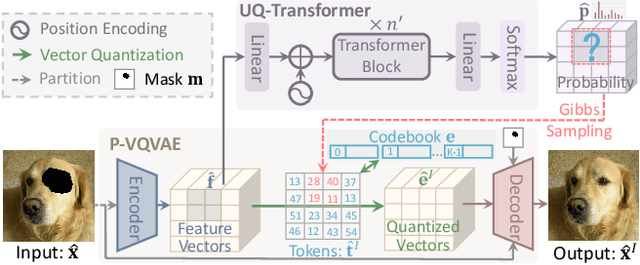

Transformers have achieved great success in pluralistic image inpainting recently. However, we find existing transformer based solutions regard each pixel as a token, thus suffer from information loss issue from two aspects: 1) They downsample the input image into much lower resolutions for efficiency consideration, incurring information loss and extra misalignment for the boundaries of masked regions. 2) They quantize $256^3$ RGB pixels to a small number (such as 512) of quantized pixels. The indices of quantized pixels are used as tokens for the inputs and prediction targets of transformer. Although an extra CNN network is used to upsample and refine the low-resolution results, it is difficult to retrieve the lost information back.To keep input information as much as possible, we propose a new transformer based framework "PUT". Specifically, to avoid input downsampling while maintaining the computation efficiency, we design a patch-based auto-encoder P-VQVAE, where the encoder converts the masked image into non-overlapped patch tokens and the decoder recovers the masked regions from inpainted tokens while keeping the unmasked regions unchanged. To eliminate the information loss caused by quantization, an Un-Quantized Transformer (UQ-Transformer) is applied, which directly takes the features from P-VQVAE encoder as input without quantization and regards the quantized tokens only as prediction targets. Extensive experiments show that PUT greatly outperforms state-of-the-art methods on image fidelity, especially for large masked regions and complex large-scale datasets. Code is available at https://github.com/liuqk3/PUT
Invertible Mask Network for Face Privacy-Preserving
Apr 19, 2022
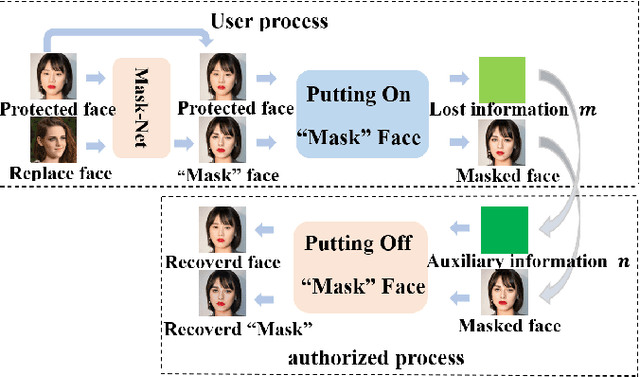
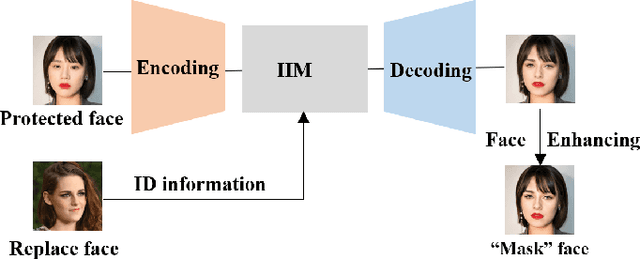
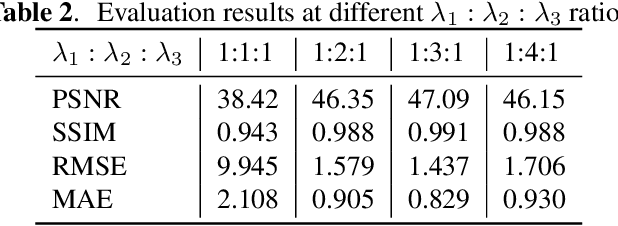
Face privacy-preserving is one of the hotspots that arises dramatic interests of research. However, the existing face privacy-preserving methods aim at causing the missing of semantic information of face and cannot preserve the reusability of original facial information. To achieve the naturalness of the processed face and the recoverability of the original protected face, this paper proposes face privacy-preserving method based on Invertible "Mask" Network (IMN). In IMN, we introduce a Mask-net to generate "Mask" face firstly. Then, put the "Mask" face onto the protected face and generate the masked face, in which the masked face is indistinguishable from "Mask" face. Finally, "Mask" face can be put off from the masked face and obtain the recovered face to the authorized users, in which the recovered face is visually indistinguishable from the protected face. The experimental results show that the proposed method can not only effectively protect the privacy of the protected face, but also almost perfectly recover the protected face from the masked face.
Real-time Online Multi-Object Tracking in Compressed Domain
Apr 05, 2022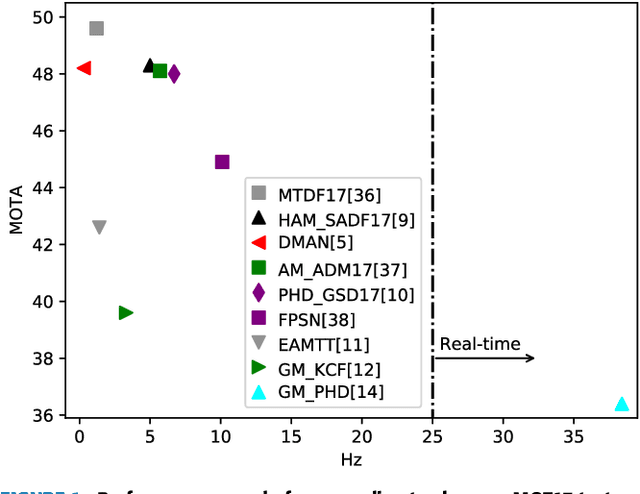

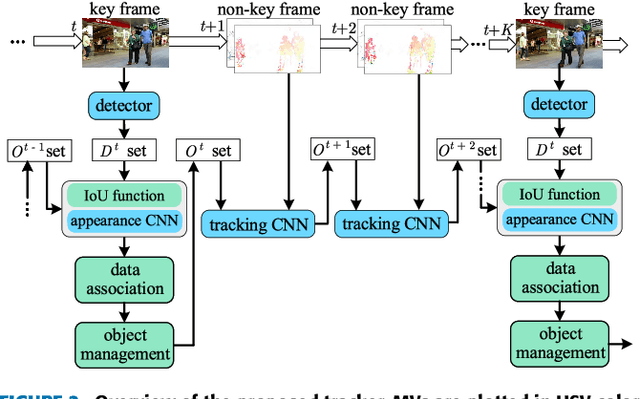
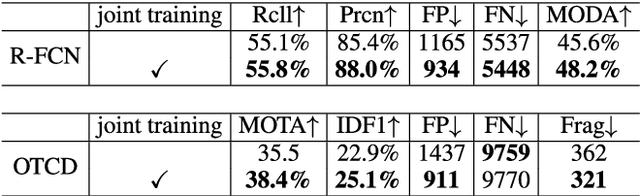
Recent online Multi-Object Tracking (MOT) methods have achieved desirable tracking performance. However, the tracking speed of most existing methods is rather slow. Inspired from the fact that the adjacent frames are highly relevant and redundant, we divide the frames into key and non-key frames respectively and track objects in the compressed domain. For the key frames, the RGB images are restored for detection and data association. To make data association more reliable, an appearance Convolutional Neural Network (CNN) which can be jointly trained with the detector is proposed. For the non-key frames, the objects are directly propagated by a tracking CNN based on the motion information provided in the compressed domain. Compared with the state-of-the-art online MOT methods,our tracker is about 6x faster while maintaining a comparable tracking performance.
Protecting Celebrities from DeepFake with Identity Consistency Transformer
Apr 05, 2022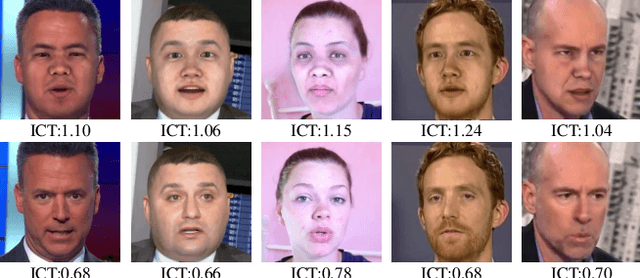
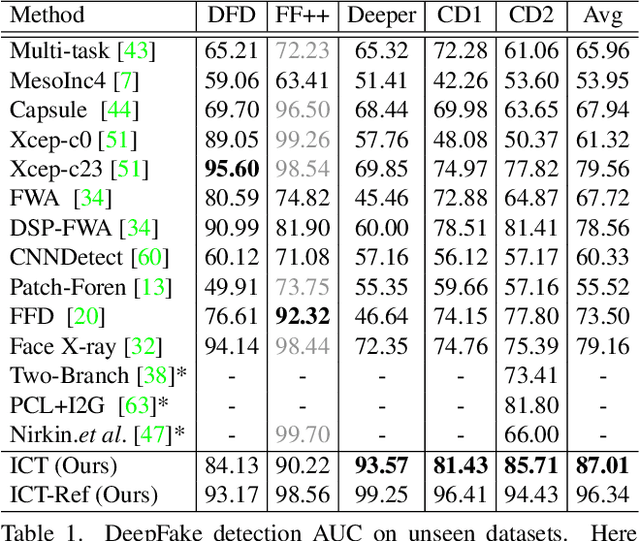

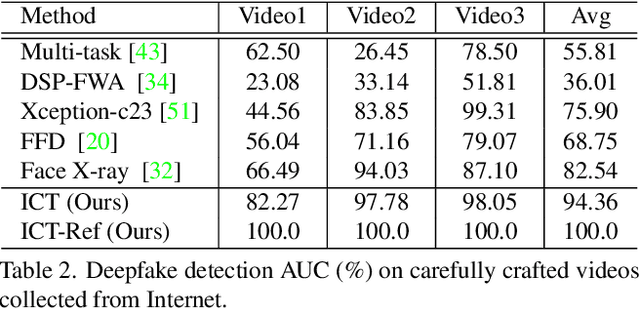
In this work we propose Identity Consistency Transformer, a novel face forgery detection method that focuses on high-level semantics, specifically identity information, and detecting a suspect face by finding identity inconsistency in inner and outer face regions. The Identity Consistency Transformer incorporates a consistency loss for identity consistency determination. We show that Identity Consistency Transformer exhibits superior generalization ability not only across different datasets but also across various types of image degradation forms found in real-world applications including deepfake videos. The Identity Consistency Transformer can be easily enhanced with additional identity information when such information is available, and for this reason it is especially well-suited for detecting face forgeries involving celebrities. Code will be released at \url{https://github.com/LightDXY/ICT_DeepFake}
Shape-invariant 3D Adversarial Point Clouds
Mar 22, 2022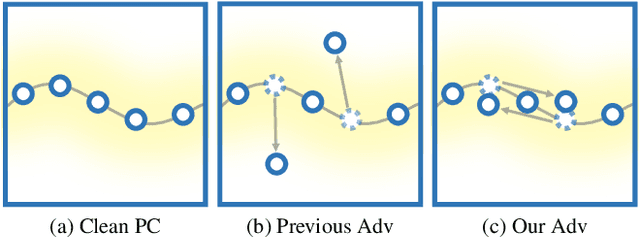
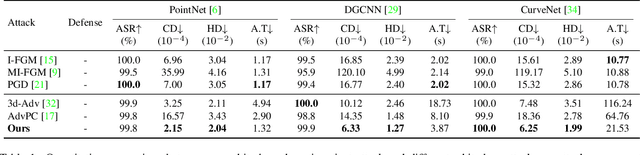
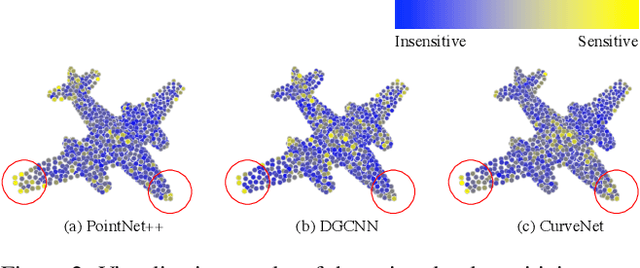
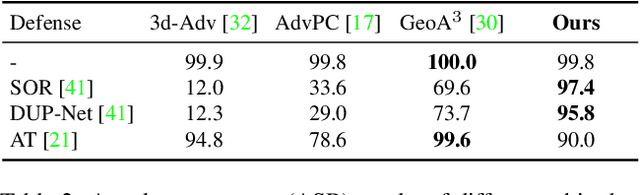
Adversary and invisibility are two fundamental but conflict characters of adversarial perturbations. Previous adversarial attacks on 3D point cloud recognition have often been criticized for their noticeable point outliers, since they just involve an "implicit constrain" like global distance loss in the time-consuming optimization to limit the generated noise. While point cloud is a highly structured data format, it is hard to constrain its perturbation with a simple loss or metric properly. In this paper, we propose a novel Point-Cloud Sensitivity Map to boost both the efficiency and imperceptibility of point perturbations. This map reveals the vulnerability of point cloud recognition models when encountering shape-invariant adversarial noises. These noises are designed along the shape surface with an "explicit constrain" instead of extra distance loss. Specifically, we first apply a reversible coordinate transformation on each point of the point cloud input, to reduce one degree of point freedom and limit its movement on the tangent plane. Then we calculate the best attacking direction with the gradients of the transformed point cloud obtained on the white-box model. Finally we assign each point with a non-negative score to construct the sensitivity map, which benefits both white-box adversarial invisibility and black-box query-efficiency extended in our work. Extensive evaluations prove that our method can achieve the superior performance on various point cloud recognition models, with its satisfying adversarial imperceptibility and strong resistance to different point cloud defense settings. Our code is available at: https://github.com/shikiw/SI-Adv.
Self-supervised Transformer for Deepfake Detection
Mar 02, 2022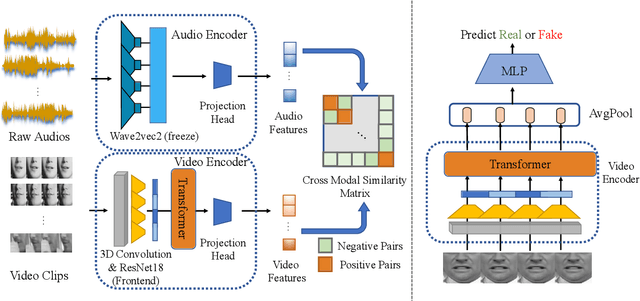
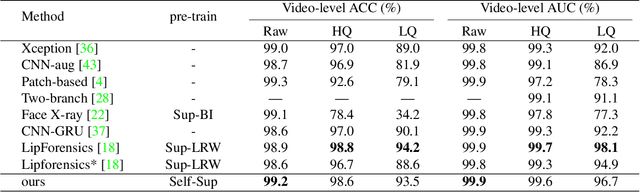
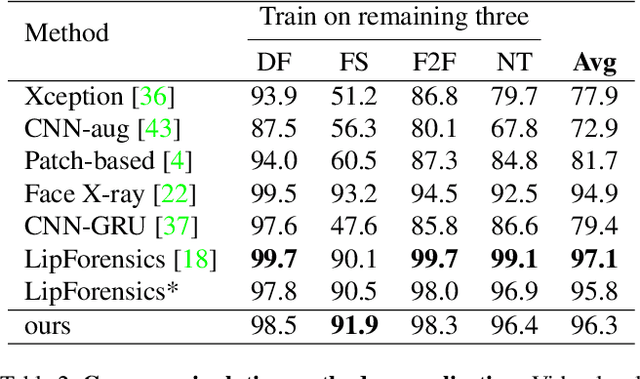
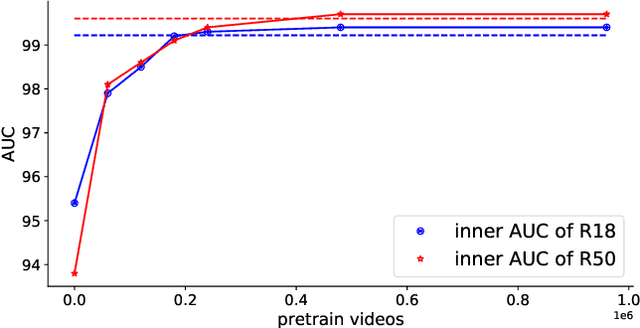
The fast evolution and widespread of deepfake techniques in real-world scenarios require stronger generalization abilities of face forgery detectors. Some works capture the features that are unrelated to method-specific artifacts, such as clues of blending boundary, accumulated up-sampling, to strengthen the generalization ability. However, the effectiveness of these methods can be easily corrupted by post-processing operations such as compression. Inspired by transfer learning, neural networks pre-trained on other large-scale face-related tasks may provide useful features for deepfake detection. For example, lip movement has been proved to be a kind of robust and good-transferring highlevel semantic feature, which can be learned from the lipreading task. However, the existing method pre-trains the lip feature extraction model in a supervised manner, which requires plenty of human resources in data annotation and increases the difficulty of obtaining training data. In this paper, we propose a self-supervised transformer based audio-visual contrastive learning method. The proposed method learns mouth motion representations by encouraging the paired video and audio representations to be close while unpaired ones to be diverse. After pre-training with our method, the model will then be partially fine-tuned for deepfake detection task. Extensive experiments show that our self-supervised method performs comparably or even better than the supervised pre-training counterpart.
Online Multi-Object Tracking with Unsupervised Re-Identification Learning and Occlusion Estimation
Jan 04, 2022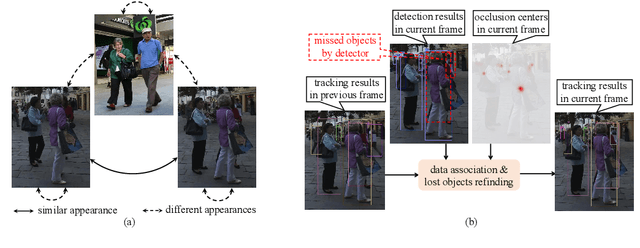

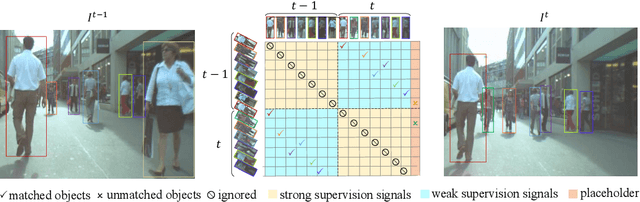

Occlusion between different objects is a typical challenge in Multi-Object Tracking (MOT), which often leads to inferior tracking results due to the missing detected objects. The common practice in multi-object tracking is re-identifying the missed objects after their reappearance. Though tracking performance can be boosted by the re-identification, the annotation of identity is required to train the model. In addition, such practice of re-identification still can not track those highly occluded objects when they are missed by the detector. In this paper, we focus on online multi-object tracking and design two novel modules, the unsupervised re-identification learning module and the occlusion estimation module, to handle these problems. Specifically, the proposed unsupervised re-identification learning module does not require any (pseudo) identity information nor suffer from the scalability issue. The proposed occlusion estimation module tries to predict the locations where occlusions happen, which are used to estimate the positions of missed objects by the detector. Our study shows that, when applied to state-of-the-art MOT methods, the proposed unsupervised re-identification learning is comparable to supervised re-identification learning, and the tracking performance is further improved by the proposed occlusion estimation module.
Initiative Defense against Facial Manipulation
Dec 19, 2021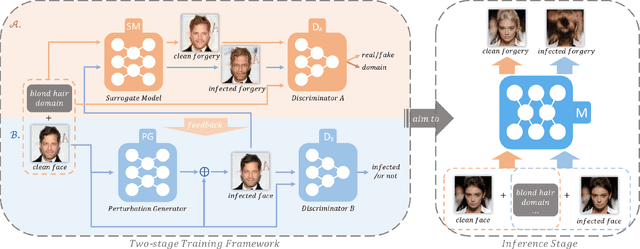
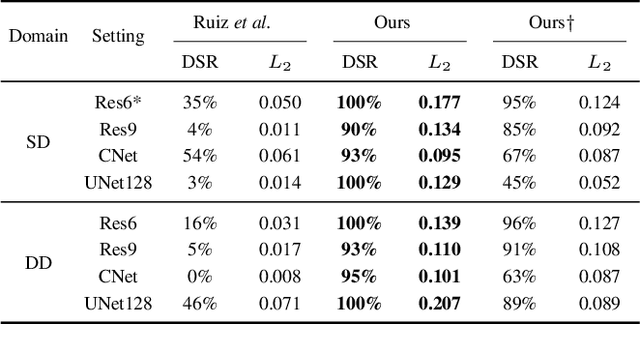
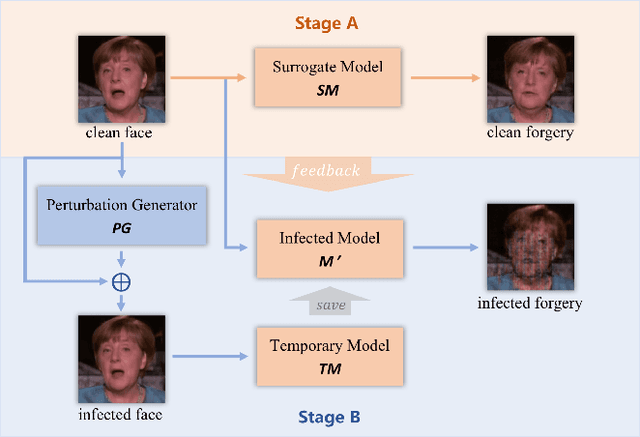
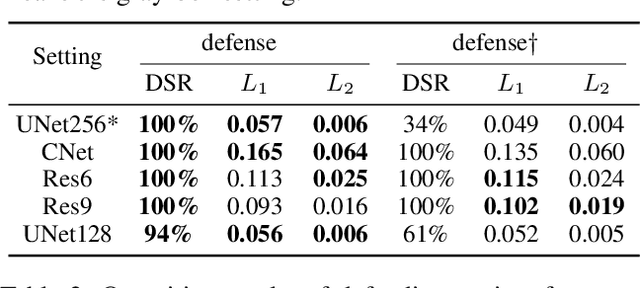
Benefiting from the development of generative adversarial networks (GAN), facial manipulation has achieved significant progress in both academia and industry recently. It inspires an increasing number of entertainment applications but also incurs severe threats to individual privacy and even political security meanwhile. To mitigate such risks, many countermeasures have been proposed. However, the great majority methods are designed in a passive manner, which is to detect whether the facial images or videos are tampered after their wide propagation. These detection-based methods have a fatal limitation, that is, they only work for ex-post forensics but can not prevent the engendering of malicious behavior. To address the limitation, in this paper, we propose a novel framework of initiative defense to degrade the performance of facial manipulation models controlled by malicious users. The basic idea is to actively inject imperceptible venom into target facial data before manipulation. To this end, we first imitate the target manipulation model with a surrogate model, and then devise a poison perturbation generator to obtain the desired venom. An alternating training strategy are further leveraged to train both the surrogate model and the perturbation generator. Two typical facial manipulation tasks: face attribute editing and face reenactment, are considered in our initiative defense framework. Extensive experiments demonstrate the effectiveness and robustness of our framework in different settings. Finally, we hope this work can shed some light on initiative countermeasures against more adversarial scenarios.
* Accepted at AAAI 2021
Tracing Text Provenance via Context-Aware Lexical Substitution
Dec 15, 2021
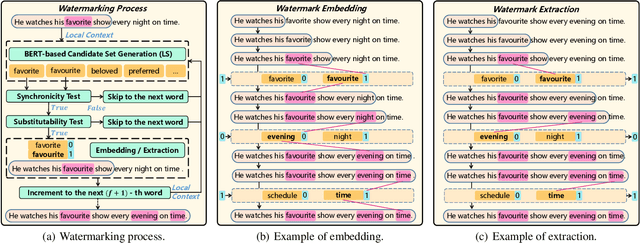
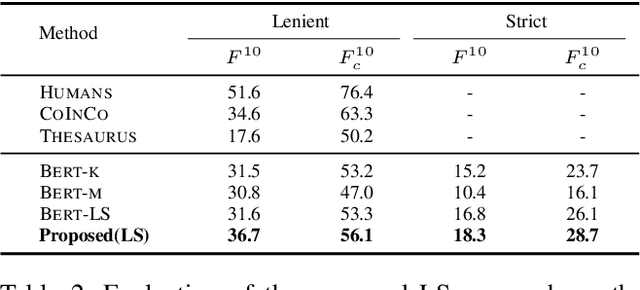
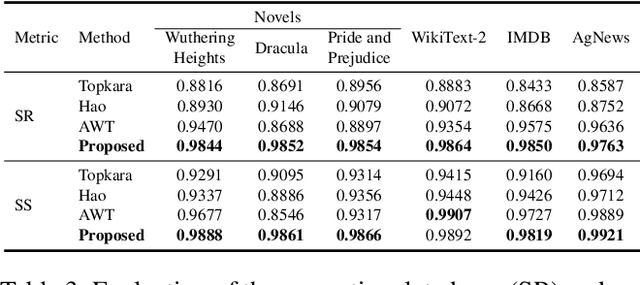
Text content created by humans or language models is often stolen or misused by adversaries. Tracing text provenance can help claim the ownership of text content or identify the malicious users who distribute misleading content like machine-generated fake news. There have been some attempts to achieve this, mainly based on watermarking techniques. Specifically, traditional text watermarking methods embed watermarks by slightly altering text format like line spacing and font, which, however, are fragile to cross-media transmissions like OCR. Considering this, natural language watermarking methods represent watermarks by replacing words in original sentences with synonyms from handcrafted lexical resources (e.g., WordNet), but they do not consider the substitution's impact on the overall sentence's meaning. Recently, a transformer-based network was proposed to embed watermarks by modifying the unobtrusive words (e.g., function words), which also impair the sentence's logical and semantic coherence. Besides, one well-trained network fails on other different types of text content. To address the limitations mentioned above, we propose a natural language watermarking scheme based on context-aware lexical substitution (LS). Specifically, we employ BERT to suggest LS candidates by inferring the semantic relatedness between the candidates and the original sentence. Based on this, a selection strategy in terms of synchronicity and substitutability is further designed to test whether a word is exactly suitable for carrying the watermark signal. Extensive experiments demonstrate that, under both objective and subjective metrics, our watermarking scheme can well preserve the semantic integrity of original sentences and has a better transferability than existing methods. Besides, the proposed LS approach outperforms the state-of-the-art approach on the Stanford Word Substitution Benchmark.