 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-environment Cooperation Enables Zero-shot Multi-agent Coordination
Apr 20, 2025



Zero-shot coordination (ZSC), the ability to adapt to a new partner in a cooperative task, is a critical component of human-compatible AI. While prior work has focused on training agents to cooperate on a single task, these specialized models do not generalize to new tasks, even if they are highly similar. Here, we study how reinforcement learning on a distribution of environments with a single partner enables learning general cooperative skills that support ZSC with many new partners on many new problems. We introduce two Jax-based, procedural generators that create billions of solvable coordination challenges. We develop a new paradigm called Cross-Environment Cooperation (CEC), and show that it outperforms competitive baselines quantitatively and qualitatively when collaborating with real people. Our findings suggest that learning to collaborate across many unique scenarios encourages agents to develop general norms, which prove effective for collaboration with different partners. Together, our results suggest a new route toward designing generalist cooperative agents capable of interacting with humans without requiring human data.
Enhancing Personalized Multi-Turn Dialogue with Curiosity Reward
Apr 04, 2025
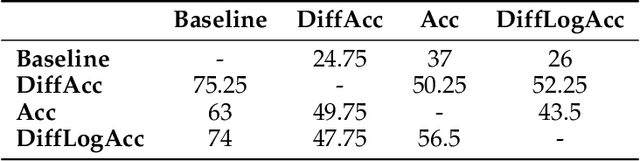
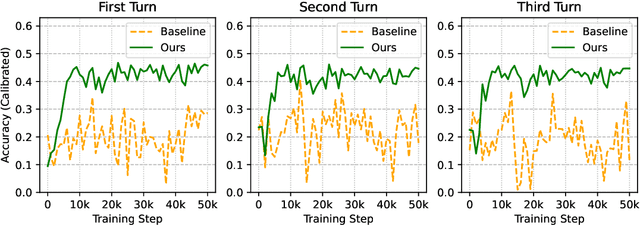

Effective conversational agents must be able to personalize their behavior to suit a user's preferences, personality, and attributes, whether they are assisting with writing tasks or operating in domains like education or healthcare. Current training methods like Reinforcement Learning from Human Feedback (RLHF) prioritize helpfulness and safety but fall short in fostering truly empathetic, adaptive, and personalized interactions. Traditional approaches to personalization often rely on extensive user history, limiting their effectiveness for new or context-limited users. To overcome these limitations, we propose to incorporate an intrinsic motivation to improve the conversational agents's model of the user as an additional reward alongside multi-turn RLHF. This reward mechanism encourages the agent to actively elicit user traits by optimizing conversations to increase the accuracy of its user model. Consequently, the policy agent can deliver more personalized interactions through obtaining more information about the user. We applied our method both education and fitness settings, where LLMs teach concepts or recommend personalized strategies based on users' hidden learning style or lifestyle attributes. Using LLM-simulated users, our approach outperformed a multi-turn RLHF baseline in revealing information about the users' preferences, and adapting to them.
ReaLJam: Real-Time Human-AI Music Jamming with Reinforcement Learning-Tuned Transformers
Feb 28, 2025Recent advances in generative artificial intelligence (AI) have created models capable of high-quality musical content generation. However, little consideration is given to how to use these models for real-time or cooperative jamming musical applications because of crucial required features: low latency, the ability to communicate planned actions, and the ability to adapt to user input in real-time. To support these needs, we introduce ReaLJam, an interface and protocol for live musical jamming sessions between a human and a Transformer-based AI agent trained with reinforcement learning. We enable real-time interactions using the concept of anticipation, where the agent continually predicts how the performance will unfold and visually conveys its plan to the user. We conduct a user study where experienced musicians jam in real-time with the agent through ReaLJam. Our results demonstrate that ReaLJam enables enjoyable and musically interesting sessions, and we uncover important takeaways for future work.
Learning to Cooperate with Humans using Generative Agents
Nov 21, 2024Training agents that can coordinate zero-shot with humans is a key mission in multi-agent reinforcement learning (MARL). Current algorithms focus on training simulated human partner policies which are then used to train a Cooperator agent. The simulated human is produced either through behavior cloning over a dataset of human cooperation behavior, or by using MARL to create a population of simulated agents. However, these approaches often struggle to produce a Cooperator that can coordinate well with real humans, since the simulated humans fail to cover the diverse strategies and styles employed by people in the real world. We show \emph{learning a generative model of human partners} can effectively address this issue. Our model learns a latent variable representation of the human that can be regarded as encoding the human's unique strategy, intention, experience, or style. This generative model can be flexibly trained from any (human or neural policy) agent interaction data. By sampling from the latent space, we can use the generative model to produce different partners to train Cooperator agents. We evaluate our method -- \textbf{G}enerative \textbf{A}gent \textbf{M}odeling for \textbf{M}ulti-agent \textbf{A}daptation (GAMMA) -- on Overcooked, a challenging cooperative cooking game that has become a standard benchmark for zero-shot coordination. We conduct an evaluation with real human teammates, and the results show that GAMMA consistently improves performance, whether the generative model is trained on simulated populations or human datasets. Further, we propose a method for posterior sampling from the generative model that is biased towards the human data, enabling us to efficiently improve performance with only a small amount of expensive human interaction data.
InvestESG: A multi-agent reinforcement learning benchmark for studying climate investment as a social dilemma
Nov 15, 2024



InvestESG is a novel multi-agent reinforcement learning (MARL) benchmark designed to study the impact of Environmental, Social, and Governance (ESG) disclosure mandates on corporate climate investments. Supported by both PyTorch and GPU-accelerated JAX framework, the benchmark models an intertemporal social dilemma where companies balance short-term profit losses from climate mitigation efforts and long-term benefits from reducing climate risk, while ESG-conscious investors attempt to influence corporate behavior through their investment decisions. Companies allocate capital across mitigation, greenwashing, and resilience, with varying strategies influencing climate outcomes and investor preferences. Our experiments show that without ESG-conscious investors with sufficient capital, corporate mitigation efforts remain limited under the disclosure mandate. However, when a critical mass of investors prioritizes ESG, corporate cooperation increases, which in turn reduces climate risks and enhances long-term financial stability. Additionally, providing more information about global climate risks encourages companies to invest more in mitigation, even without investor involvement. Our findings align with empirical research using real-world data, highlighting MARL's potential to inform policy by providing insights into large-scale socio-economic challenges through efficient testing of alternative policy and market designs.
Infer Human's Intentions Before Following Natural Language Instructions
Sep 26, 2024



For AI agents to be helpful to humans, they should be able to follow natural language instructions to complete everyday cooperative tasks in human environments. However, real human instructions inherently possess ambiguity, because the human speakers assume sufficient prior knowledge about their hidden goals and intentions. Standard language grounding and planning methods fail to address such ambiguities because they do not model human internal goals as additional partially observable factors in the environment. We propose a new framework, Follow Instructions with Social and Embodied Reasoning (FISER), aiming for better natural language instruction following in collaborative embodied tasks. Our framework makes explicit inferences about human goals and intentions as intermediate reasoning steps. We implement a set of Transformer-based models and evaluate them over a challenging benchmark, HandMeThat. We empirically demonstrate that using social reasoning to explicitly infer human intentions before making action plans surpasses purely end-to-end approaches. We also compare our implementation with strong baselines, including Chain of Thought prompting on the largest available pre-trained language models, and find that FISER provides better performance on the embodied social reasoning tasks under investigation, reaching the state-of-the-art on HandMeThat.
Personalizing Reinforcement Learning from Human Feedback with Variational Preference Learning
Aug 19, 2024Reinforcement Learning from Human Feedback (RLHF) is a powerful paradigm for aligning foundation models to human values and preferences. However, current RLHF techniques cannot account for the naturally occurring differences in individual human preferences across a diverse population. When these differences arise, traditional RLHF frameworks simply average over them, leading to inaccurate rewards and poor performance for individual subgroups. To address the need for pluralistic alignment, we develop a class of multimodal RLHF methods. Our proposed techniques are based on a latent variable formulation - inferring a novel user-specific latent and learning reward models and policies conditioned on this latent without additional user-specific data. While conceptually simple, we show that in practice, this reward modeling requires careful algorithmic considerations around model architecture and reward scaling. To empirically validate our proposed technique, we first show that it can provide a way to combat underspecification in simulated control problems, inferring and optimizing user-specific reward functions. Next, we conduct experiments on pluralistic language datasets representing diverse user preferences and demonstrate improved reward function accuracy. We additionally show the benefits of this probabilistic framework in terms of measuring uncertainty, and actively learning user preferences. This work enables learning from diverse populations of users with divergent preferences, an important challenge that naturally occurs in problems from robot learning to foundation model alignment.
Achieving Human Level Competitive Robot Table Tennis
Aug 07, 2024



Achieving human-level speed and performance on real world tasks is a north star for the robotics research community. This work takes a step towards that goal and presents the first learned robot agent that reaches amateur human-level performance in competitive table tennis. Table tennis is a physically demanding sport which requires human players to undergo years of training to achieve an advanced level of proficiency. In this paper, we contribute (1) a hierarchical and modular policy architecture consisting of (i) low level controllers with their detailed skill descriptors which model the agent's capabilities and help to bridge the sim-to-real gap and (ii) a high level controller that chooses the low level skills, (2) techniques for enabling zero-shot sim-to-real including an iterative approach to defining the task distribution that is grounded in the real-world and defines an automatic curriculum, and (3) real time adaptation to unseen opponents. Policy performance was assessed through 29 robot vs. human matches of which the robot won 45% (13/29). All humans were unseen players and their skill level varied from beginner to tournament level. Whilst the robot lost all matches vs. the most advanced players it won 100% matches vs. beginners and 55% matches vs. intermediate players, demonstrating solidly amateur human-level performance. Videos of the matches can be viewed at https://sites.google.com/view/competitive-robot-table-tennis
Moral Foundations of Large Language Models
Oct 23, 2023



Moral foundations theory (MFT) is a psychological assessment tool that decomposes human moral reasoning into five factors, including care/harm, liberty/oppression, and sanctity/degradation (Graham et al., 2009). People vary in the weight they place on these dimensions when making moral decisions, in part due to their cultural upbringing and political ideology. As large language models (LLMs) are trained on datasets collected from the internet, they may reflect the biases that are present in such corpora. This paper uses MFT as a lens to analyze whether popular LLMs have acquired a bias towards a particular set of moral values. We analyze known LLMs and find they exhibit particular moral foundations, and show how these relate to human moral foundations and political affiliations. We also measure the consistency of these biases, or whether they vary strongly depending on the context of how the model is prompted. Finally, we show that we can adversarially select prompts that encourage the moral to exhibit a particular set of moral foundations, and that this can affect the model's behavior on downstream tasks. These findings help illustrate the potential risks and unintended consequences of LLMs assuming a particular moral stance.
Impossibility Theorems for Feature Attribution
Dec 22, 2022



Despite a sea of interpretability methods that can produce plausible explanations, the field has also empirically seen many failure cases of such methods. In light of these results, it remains unclear for practitioners how to use these methods and choose between them in a principled way. In this paper, we show that for even moderately rich model classes (easily satisfied by neural networks), any feature attribution method that is complete and linear--for example, Integrated Gradients and SHAP--can provably fail to improve on random guessing for inferring model behaviour. Our results apply to common end-tasks such as identifying local model behaviour, spurious feature identification, and algorithmic recourse. One takeaway from our work is the importance of concretely defining end-tasks. In particular, we show that once such an end-task is defined, a simple and direct approach of repeated model evaluations can outperform many other complex feature attribution methods.