 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask diversity produces systematic transfer but inhibits continual reinforcement learning
May 30, 2026Continual reinforcement learning aims to produce agents that learn not only to improve at their current tasks but also to adapt as task distributions change. Training an agent on many diverse tasks can induce zero-shot generalization, but previous work generally evaluates this generalization after training -- with frozen weights. Whether task diversity also improves an agent's ability to continue learning across distribution shifts remains unclear. We introduce Banyan, a GPU-accelerated continual RL domain in which task diversity factors into three independently controllable axes: the map layouts an agent must navigate, the objects it must interact with, and the hierarchical structures of sub-goal dependencies. Across individual distribution shifts, increasing diversity along each axis causes agents to begin training on the new tasks near the performance attained on the previous one, even when the shift changes the structure of the optimal policy. However, as the number of shifts increases, this local transfer does not by itself yield sustained continual learning: longer-horizon tasks plateau, and earlier task distributions are forgotten after later training. Banyan is a benchmark for studying when controlled task diversity produces transferable learning, when that transfer persists, and where it falls short of proper continual learning.
Cross-environment Cooperation Enables Zero-shot Multi-agent Coordination
Apr 20, 2025



Zero-shot coordination (ZSC), the ability to adapt to a new partner in a cooperative task, is a critical component of human-compatible AI. While prior work has focused on training agents to cooperate on a single task, these specialized models do not generalize to new tasks, even if they are highly similar. Here, we study how reinforcement learning on a distribution of environments with a single partner enables learning general cooperative skills that support ZSC with many new partners on many new problems. We introduce two Jax-based, procedural generators that create billions of solvable coordination challenges. We develop a new paradigm called Cross-Environment Cooperation (CEC), and show that it outperforms competitive baselines quantitatively and qualitatively when collaborating with real people. Our findings suggest that learning to collaborate across many unique scenarios encourages agents to develop general norms, which prove effective for collaboration with different partners. Together, our results suggest a new route toward designing generalist cooperative agents capable of interacting with humans without requiring human data.
GOMA: Proactive Embodied Cooperative Communication via Goal-Oriented Mental Alignment
Mar 17, 2024



Verbal communication plays a crucial role in human cooperation, particularly when the partners only have incomplete information about the task, environment, and each other's mental state. In this paper, we propose a novel cooperative communication framework, Goal-Oriented Mental Alignment (GOMA). GOMA formulates verbal communication as a planning problem that minimizes the misalignment between the parts of agents' mental states that are relevant to the goals. This approach enables an embodied assistant to reason about when and how to proactively initialize communication with humans verbally using natural language to help achieve better cooperation. We evaluate our approach against strong baselines in two challenging environments, Overcooked (a multiplayer game) and VirtualHome (a household simulator). Our experimental results demonstrate that large language models struggle with generating meaningful communication that is grounded in the social and physical context. In contrast, our approach can successfully generate concise verbal communication for the embodied assistant to effectively boost the performance of the cooperation as well as human users' perception of the assistant.
Neural Amortized Inference for Nested Multi-agent Reasoning
Aug 21, 2023



Multi-agent interactions, such as communication, teaching, and bluffing, often rely on higher-order social inference, i.e., understanding how others infer oneself. Such intricate reasoning can be effectively modeled through nested multi-agent reasoning. Nonetheless, the computational complexity escalates exponentially with each level of reasoning, posing a significant challenge. However, humans effortlessly perform complex social inferences as part of their daily lives. To bridge the gap between human-like inference capabilities and computational limitations, we propose a novel approach: leveraging neural networks to amortize high-order social inference, thereby expediting nested multi-agent reasoning. We evaluate our method in two challenging multi-agent interaction domains. The experimental results demonstrate that our method is computationally efficient while exhibiting minimal degradation in accuracy.
SimDoc: Topic Sequence Alignment based Document Similarity Framework
Nov 11, 2017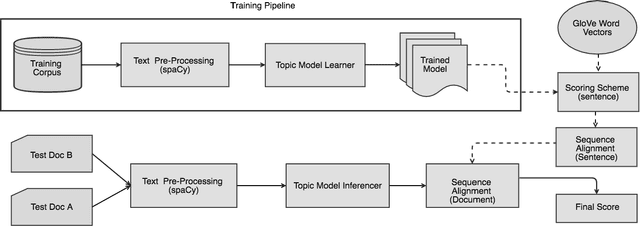

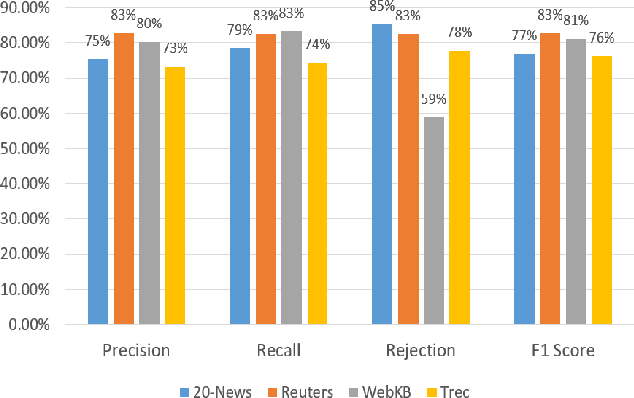

Document similarity is the problem of estimating the degree to which a given pair of documents has similar semantic content. An accurate document similarity measure can improve several enterprise relevant tasks such as document clustering, text mining, and question-answering. In this paper, we show that a document's thematic flow, which is often disregarded by bag-of-word techniques, is pivotal in estimating their similarity. To this end, we propose a novel semantic document similarity framework, called SimDoc. We model documents as topic-sequences, where topics represent latent generative clusters of related words. Then, we use a sequence alignment algorithm to estimate their semantic similarity. We further conceptualize a novel mechanism to compute topic-topic similarity to fine tune our system. In our experiments, we show that SimDoc outperforms many contemporary bag-of-words techniques in accurately computing document similarity, and on practical applications such as document clustering.