 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNa Zhao
View-Consistent 3D Editing with Gaussian Splatting
Mar 20, 2024

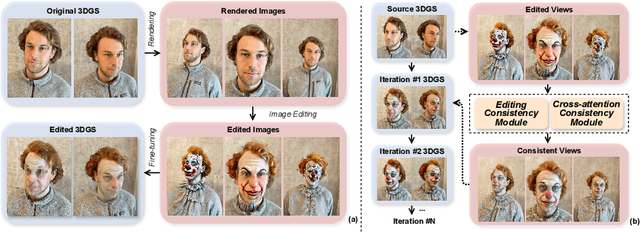
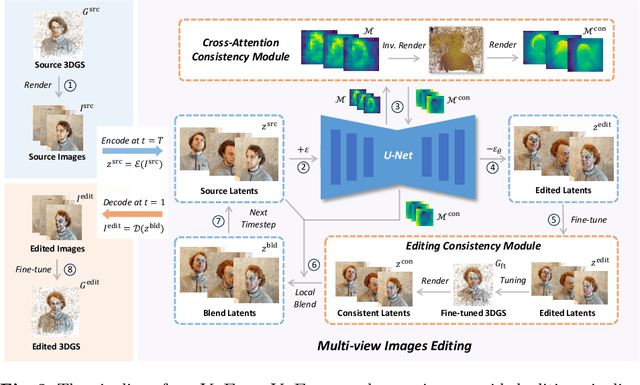

The advent of 3D Gaussian Splatting (3DGS) has revolutionized 3D editing, offering efficient, high-fidelity rendering and enabling precise local manipulations. Currently, diffusion-based 2D editing models are harnessed to modify multi-view rendered images, which then guide the editing of 3DGS models. However, this approach faces a critical issue of multi-view inconsistency, where the guidance images exhibit significant discrepancies across views, leading to mode collapse and visual artifacts of 3DGS. To this end, we introduce View-consistent Editing (VcEdit), a novel framework that seamlessly incorporates 3DGS into image editing processes, ensuring multi-view consistency in edited guidance images and effectively mitigating mode collapse issues. VcEdit employs two innovative consistency modules: the Cross-attention Consistency Module and the Editing Consistency Module, both designed to reduce inconsistencies in edited images. By incorporating these consistency modules into an iterative pattern, VcEdit proficiently resolves the issue of multi-view inconsistency, facilitating high-quality 3DGS editing across a diverse range of scenes.
Dual-Perspective Knowledge Enrichment for Semi-Supervised 3D Object Detection
Jan 10, 2024Semi-supervised 3D object detection is a promising yet under-explored direction to reduce data annotation costs, especially for cluttered indoor scenes. A few prior works, such as SESS and 3DIoUMatch, attempt to solve this task by utilizing a teacher model to generate pseudo-labels for unlabeled samples. However, the availability of unlabeled samples in the 3D domain is relatively limited compared to its 2D counterpart due to the greater effort required to collect 3D data. Moreover, the loose consistency regularization in SESS and restricted pseudo-label selection strategy in 3DIoUMatch lead to either low-quality supervision or a limited amount of pseudo labels. To address these issues, we present a novel Dual-Perspective Knowledge Enrichment approach named DPKE for semi-supervised 3D object detection. Our DPKE enriches the knowledge of limited training data, particularly unlabeled data, from two perspectives: data-perspective and feature-perspective. Specifically, from the data-perspective, we propose a class-probabilistic data augmentation method that augments the input data with additional instances based on the varying distribution of class probabilities. Our DPKE achieves feature-perspective knowledge enrichment by designing a geometry-aware feature matching method that regularizes feature-level similarity between object proposals from the student and teacher models. Extensive experiments on the two benchmark datasets demonstrate that our DPKE achieves superior performance over existing state-of-the-art approaches under various label ratio conditions. The source code will be made available to the public.
Towards Robust Few-shot Point Cloud Semantic Segmentation
Sep 20, 2023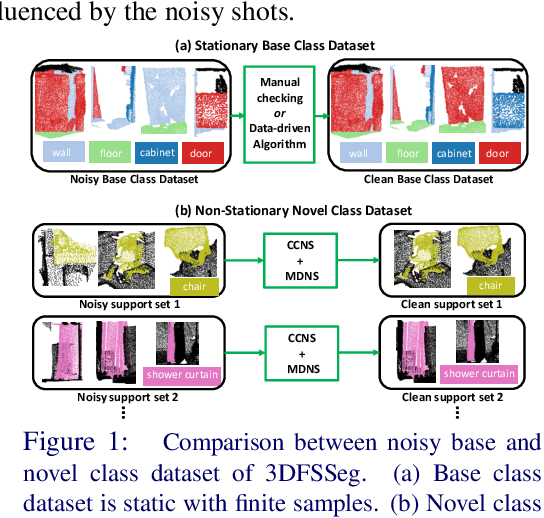
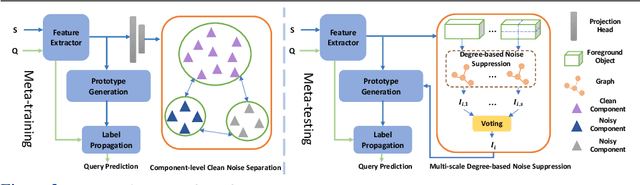
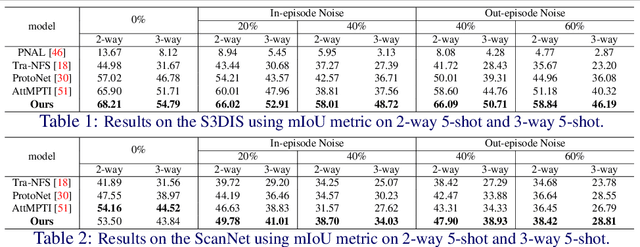
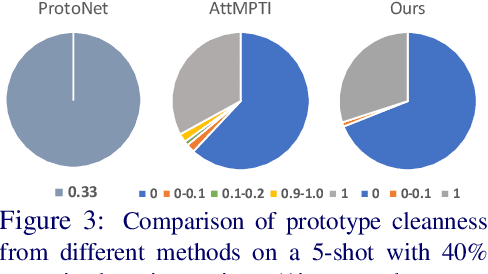
Few-shot point cloud semantic segmentation aims to train a model to quickly adapt to new unseen classes with only a handful of support set samples. However, the noise-free assumption in the support set can be easily violated in many practical real-world settings. In this paper, we focus on improving the robustness of few-shot point cloud segmentation under the detrimental influence of noisy support sets during testing time. To this end, we first propose a Component-level Clean Noise Separation (CCNS) representation learning to learn discriminative feature representations that separates the clean samples of the target classes from the noisy samples. Leveraging the well separated clean and noisy support samples from our CCNS, we further propose a Multi-scale Degree-based Noise Suppression (MDNS) scheme to remove the noisy shots from the support set. We conduct extensive experiments on various noise settings on two benchmark datasets. Our results show that the combination of CCNS and MDNS significantly improves the performance. Our code is available at https://github.com/Pixie8888/R3DFSSeg.
Generalized Few-Shot Point Cloud Segmentation Via Geometric Words
Sep 20, 2023

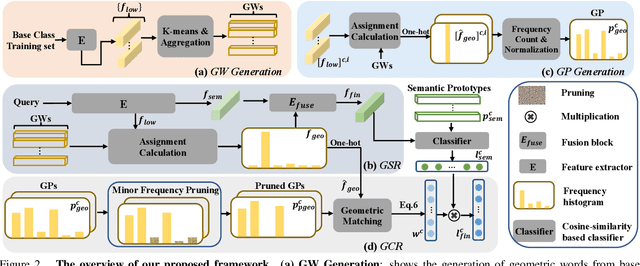
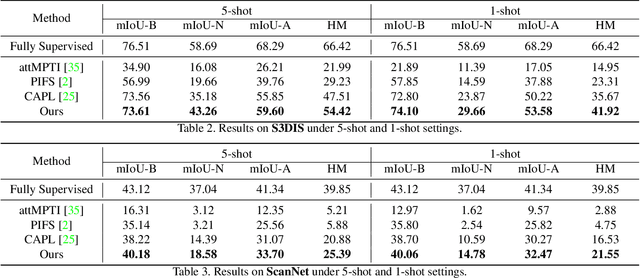
Existing fully-supervised point cloud segmentation methods suffer in the dynamic testing environment with emerging new classes. Few-shot point cloud segmentation algorithms address this problem by learning to adapt to new classes at the sacrifice of segmentation accuracy for the base classes, which severely impedes its practicality. This largely motivates us to present the first attempt at a more practical paradigm of generalized few-shot point cloud segmentation, which requires the model to generalize to new categories with only a few support point clouds and simultaneously retain the capability to segment base classes. We propose the geometric words to represent geometric components shared between the base and novel classes, and incorporate them into a novel geometric-aware semantic representation to facilitate better generalization to the new classes without forgetting the old ones. Moreover, we introduce geometric prototypes to guide the segmentation with geometric prior knowledge. Extensive experiments on S3DIS and ScanNet consistently illustrate the superior performance of our method over baseline methods. Our code is available at: https://github.com/Pixie8888/GFS-3DSeg_GWs.
Refining 6-DoF Grasps with Context-Specific Classifiers
Aug 14, 2023
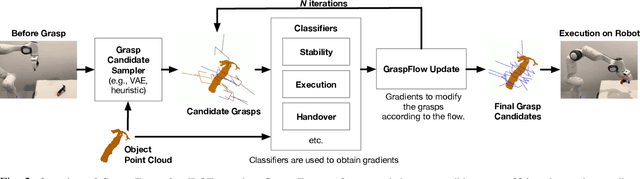
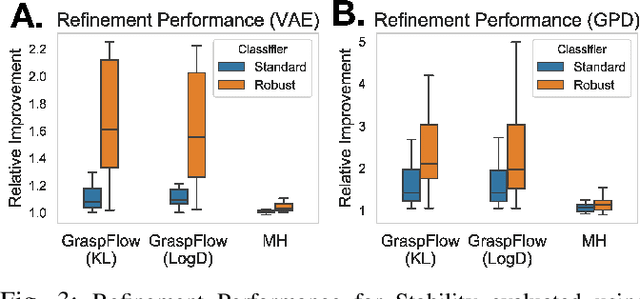
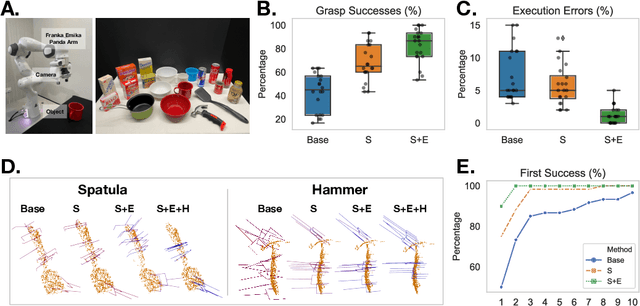
In this work, we present GraspFlow, a refinement approach for generating context-specific grasps. We formulate the problem of grasp synthesis as a sampling problem: we seek to sample from a context-conditioned probability distribution of successful grasps. However, this target distribution is unknown. As a solution, we devise a discriminator gradient-flow method to evolve grasps obtained from a simpler distribution in a manner that mimics sampling from the desired target distribution. Unlike existing approaches, GraspFlow is modular, allowing grasps that satisfy multiple criteria to be obtained simply by incorporating the relevant discriminators. It is also simple to implement, requiring minimal code given existing auto-differentiation libraries and suitable discriminators. Experiments show that GraspFlow generates stable and executable grasps on a real-world Panda robot for a diverse range of objects. In particular, in 60 trials on 20 different household objects, the first attempted grasp was successful 94% of the time, and 100% grasp success was achieved by the second grasp. Moreover, incorporating a functional discriminator for robot-human handover improved the functional aspect of the grasp by up to 33%.
On the Performance Tradeoff of an ISAC System with Finite Blocklength
Aug 01, 2023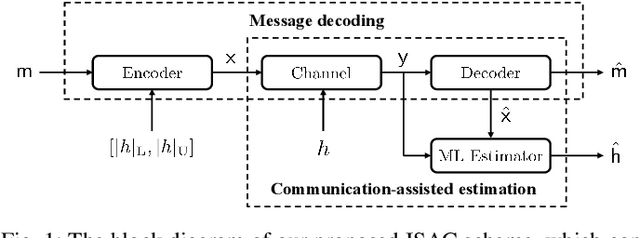
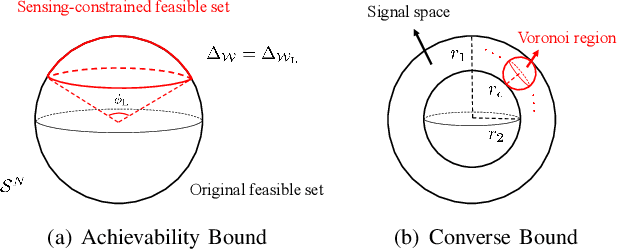
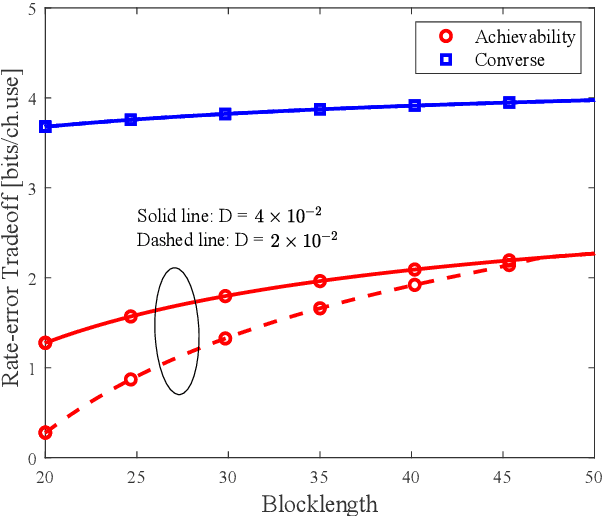
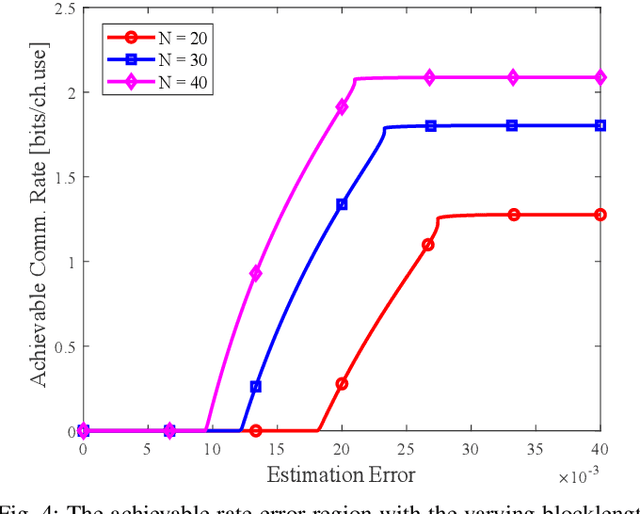
Integrated sensing and communication (ISAC) has been proposed as a promising paradigm in the future wireless networks, where the spectral and hardware resources are shared to provide a considerable performance gain. It is essential to understand how sensing and communication (S\&C) influences each other to guide the practical algorithm and system design in ISAC. In this paper, we investigate the performance tradeoff between S\&C in a single-input single-output (SISO) ISAC system with finite blocklength. In particular, we present the system model and the ISAC scheme, after which the rate-error tradeoff is introduced as the performance metric. Then we derive the achievability and converse bounds for the rate-error tradeoff, determining the boundary of the joint S\&C performance. Furthermore, we develop the asymptotic analysis at large blocklength regime, where the performance tradeoff between S\&C is proved to vanish as the blocklength tends to infinity. Finally, our theoretical analysis is consolidated by simulation results.
Style-Hallucinated Dual Consistency Learning: A Unified Framework for Visual Domain Generalization
Dec 18, 2022
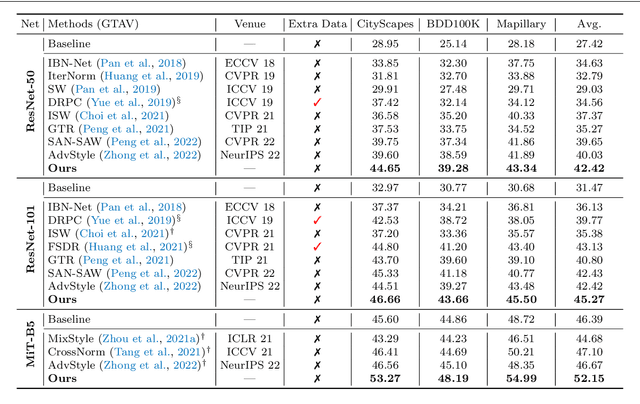
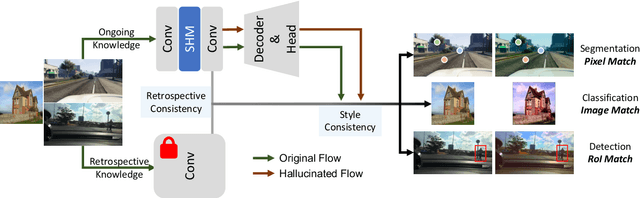
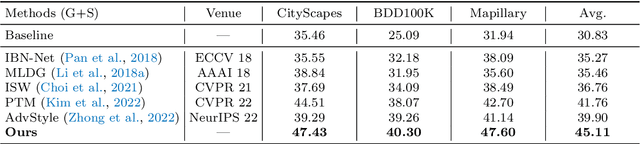
Domain shift widely exists in the visual world, while modern deep neural networks commonly suffer from severe performance degradation under domain shift due to the poor generalization ability, which limits the real-world applications. The domain shift mainly lies in the limited source environmental variations and the large distribution gap between source and unseen target data. To this end, we propose a unified framework, Style-HAllucinated Dual consistEncy learning (SHADE), to handle such domain shift in various visual tasks. Specifically, SHADE is constructed based on two consistency constraints, Style Consistency (SC) and Retrospection Consistency (RC). SC enriches the source situations and encourages the model to learn consistent representation across style-diversified samples. RC leverages general visual knowledge to prevent the model from overfitting to source data and thus largely keeps the representation consistent between the source and general visual models. Furthermore, we present a novel style hallucination module (SHM) to generate style-diversified samples that are essential to consistency learning. SHM selects basis styles from the source distribution, enabling the model to dynamically generate diverse and realistic samples during training. Extensive experiments demonstrate that our versatile SHADE can significantly enhance the generalization in various visual recognition tasks, including image classification, semantic segmentation and object detection, with different models, i.e., ConvNets and Transformer.
Synthetic-to-Real Domain Generalized Semantic Segmentation for 3D Indoor Point Clouds
Dec 09, 2022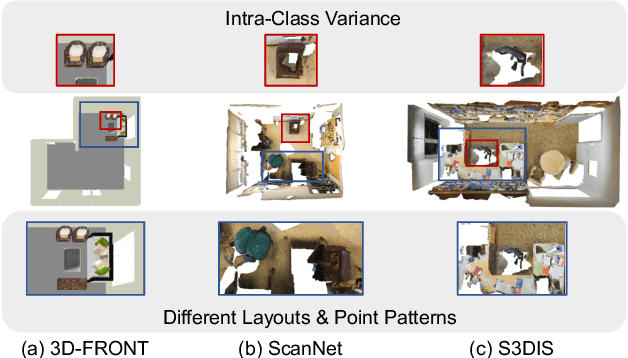

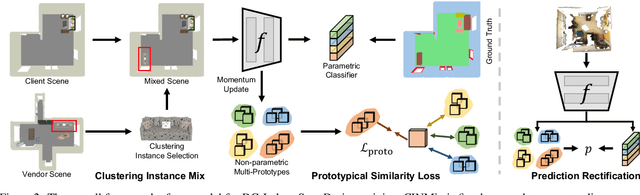
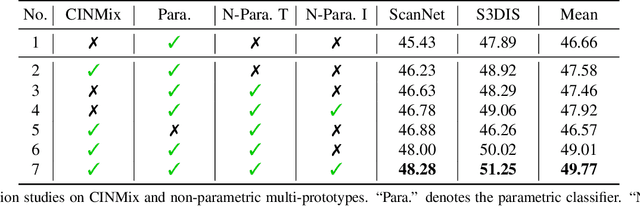
Semantic segmentation in 3D indoor scenes has achieved remarkable performance under the supervision of large-scale annotated data. However, previous works rely on the assumption that the training and testing data are of the same distribution, which may suffer from performance degradation when evaluated on the out-of-distribution scenes. To alleviate the annotation cost and the performance degradation, this paper introduces the synthetic-to-real domain generalization setting to this task. Specifically, the domain gap between synthetic and real-world point cloud data mainly lies in the different layouts and point patterns. To address these problems, we first propose a clustering instance mix (CINMix) augmentation technique to diversify the layouts of the source data. In addition, we augment the point patterns of the source data and introduce non-parametric multi-prototypes to ameliorate the intra-class variance enlarged by the augmented point patterns. The multi-prototypes can model the intra-class variance and rectify the global classifier in both training and inference stages. Experiments on the synthetic-to-real benchmark demonstrate that both CINMix and multi-prototypes can narrow the distribution gap and thus improve the generalization ability on real-world datasets.
Myopia prediction for adolescents via time-aware deep learning
Sep 26, 2022
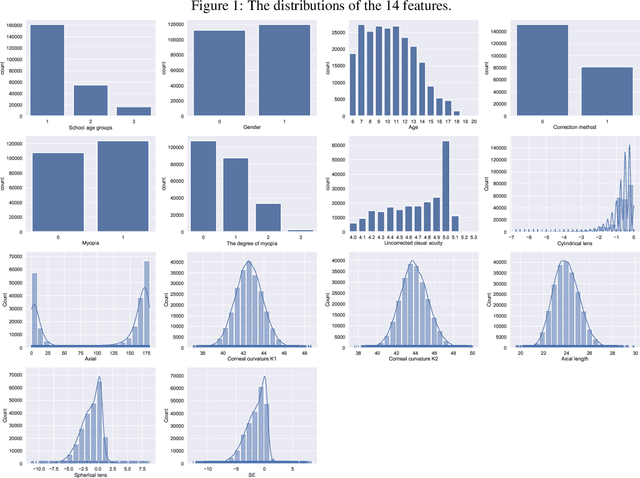

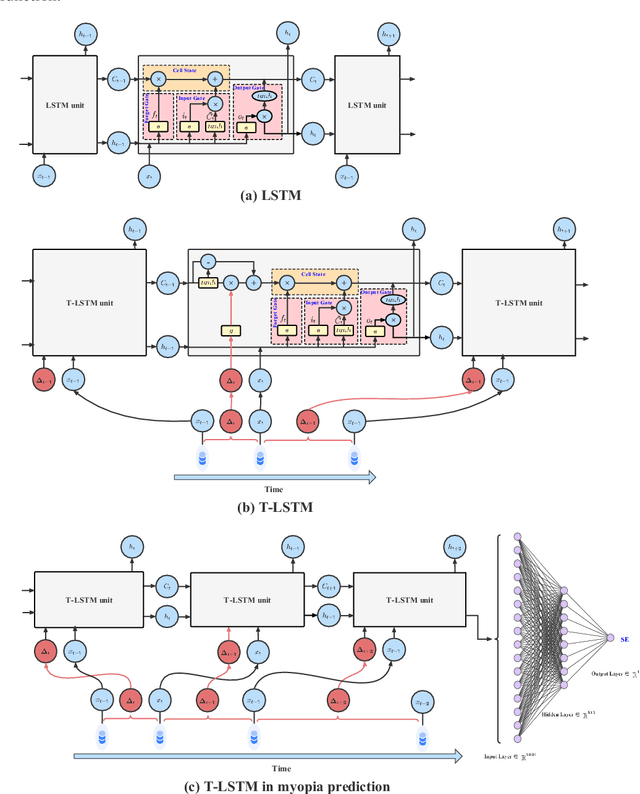
Background: Quantitative prediction of the adolescents' spherical equivalent based on their variable-length historical vision records. Methods: From October 2019 to March 2022, we examined binocular uncorrected visual acuity, axial length, corneal curvature, and axial of 75,172 eyes from 37,586 adolescents aged 6-20 years in Chengdu, China. 80\% samples consist of the training set and the remaining 20\% form the testing set. Time-Aware Long Short-Term Memory was used to quantitatively predict the adolescents' spherical equivalent within two and a half years. Result: The mean absolute prediction error on the testing set was 0.273-0.257 for spherical equivalent, ranging from 0.189-0.160 to 0.596-0.473 if we consider different lengths of historical records and different prediction durations. Conclusions: Time-Aware Long Short-Term Memory was applied to captured the temporal features in irregularly sampled time series, which is more in line with the characteristics of real data and thus has higher applicability, and helps to identify the progression of myopia earlier. The overall error 0.273 is much smaller than the criterion for clinically acceptable prediction, say 0.75.
Rethinking IoU-based Optimization for Single-stage 3D Object Detection
Jul 20, 2022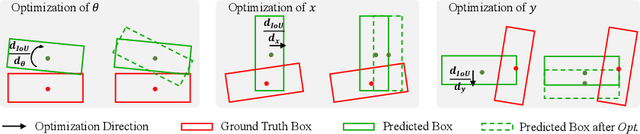
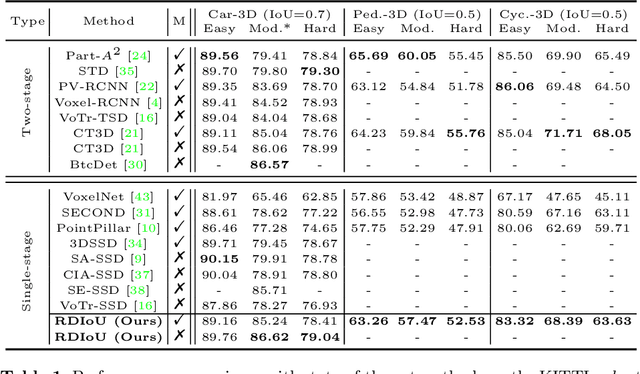
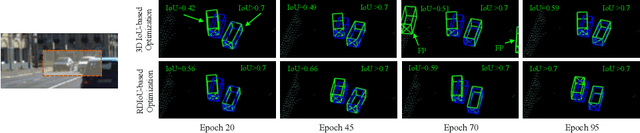
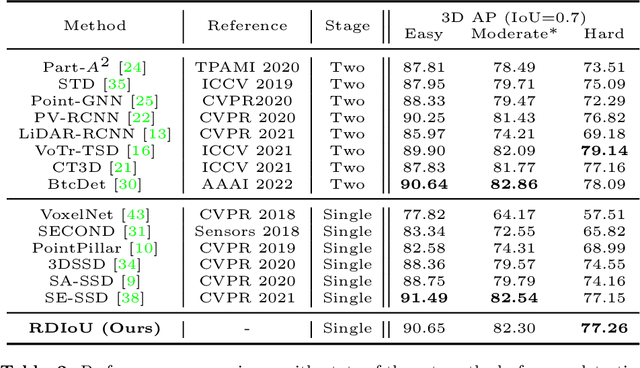
Since Intersection-over-Union (IoU) based optimization maintains the consistency of the final IoU prediction metric and losses, it has been widely used in both regression and classification branches of single-stage 2D object detectors. Recently, several 3D object detection methods adopt IoU-based optimization and directly replace the 2D IoU with 3D IoU. However, such a direct computation in 3D is very costly due to the complex implementation and inefficient backward operations. Moreover, 3D IoU-based optimization is sub-optimal as it is sensitive to rotation and thus can cause training instability and detection performance deterioration. In this paper, we propose a novel Rotation-Decoupled IoU (RDIoU) method that can mitigate the rotation-sensitivity issue, and produce more efficient optimization objectives compared with 3D IoU during the training stage. Specifically, our RDIoU simplifies the complex interactions of regression parameters by decoupling the rotation variable as an independent term, yet preserving the geometry of 3D IoU. By incorporating RDIoU into both the regression and classification branches, the network is encouraged to learn more precise bounding boxes and concurrently overcome the misalignment issue between classification and regression. Extensive experiments on the benchmark KITTI and Waymo Open Dataset validate that our RDIoU method can bring substantial improvement for the single-stage 3D object detection.