 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo You Really Mean That? Content Driven Audio-Visual Deepfake Dataset and Multimodal Method for Temporal Forgery Localization
Apr 13, 2022

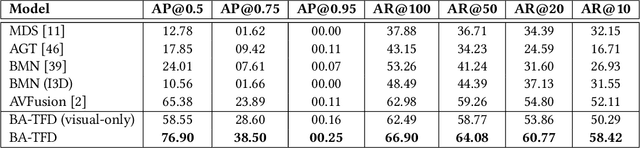
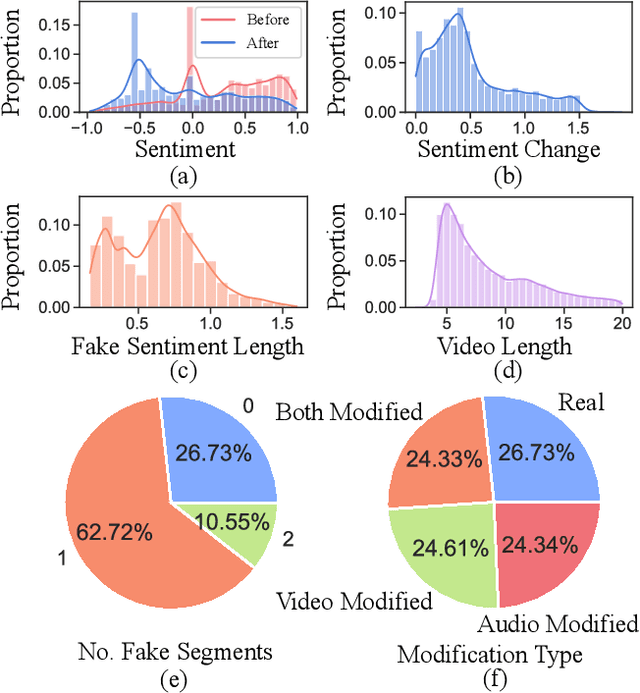
Due to its high societal impact, deepfake detection is getting active attention in the computer vision community. Most deepfake detection methods rely on identity, facial attribute and adversarial perturbation based spatio-temporal modifications at the whole video or random locations, while keeping the meaning of the content intact. However, a sophisticated deepfake may contain only a small segment of video/audio manipulation, through which the meaning of the content can be, for example, completely inverted from sentiment perspective. To address this gap, we introduce a content driven audio-visual deepfake dataset, termed as Localized Audio Visual DeepFake (LAV-DF), explicitly designed for the task of learning temporal forgery localization. Specifically, the content driven audio-visual manipulations are performed at strategic locations in order to change the sentiment polarity of the whole video. Our baseline method for benchmarking the proposed dataset is a 3DCNN model, termed as Boundary Aware Temporal Forgery Detection (BA-TFD), which is guided via contrastive, boundary matching and frame classification loss functions. Our extensive quantitative analysis demonstrates the strong performance of the proposed method for both task of temporal forgery localization and deepfake detection.
Semantic-Aware Domain Generalized Segmentation
Apr 02, 2022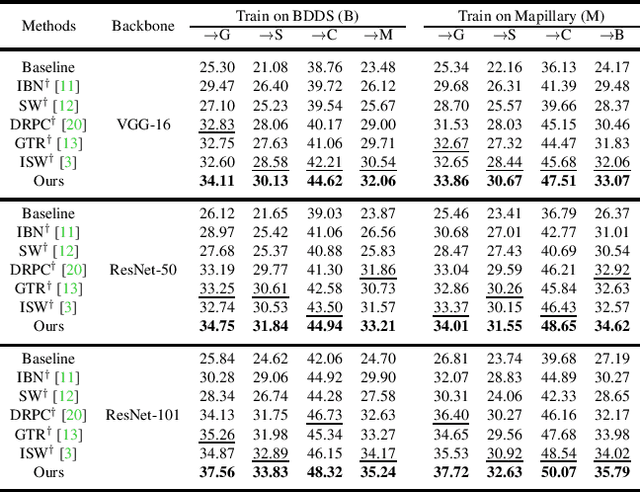
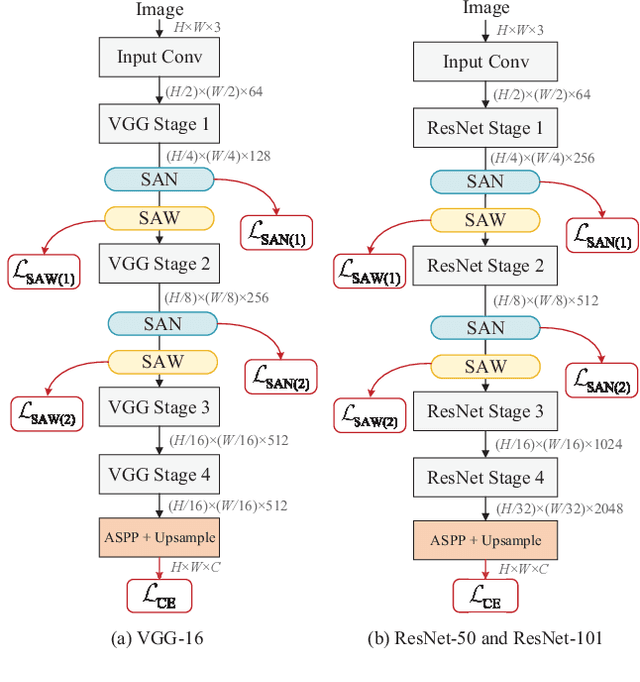
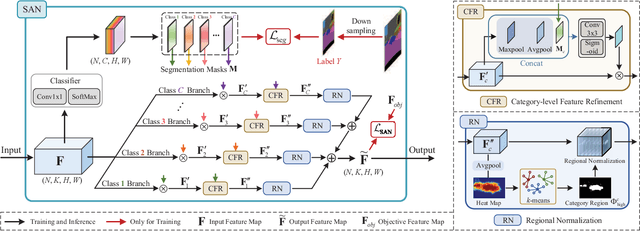

Deep models trained on source domain lack generalization when evaluated on unseen target domains with different data distributions. The problem becomes even more pronounced when we have no access to target domain samples for adaptation. In this paper, we address domain generalized semantic segmentation, where a segmentation model is trained to be domain-invariant without using any target domain data. Existing approaches to tackle this problem standardize data into a unified distribution. We argue that while such a standardization promotes global normalization, the resulting features are not discriminative enough to get clear segmentation boundaries. To enhance separation between categories while simultaneously promoting domain invariance, we propose a framework including two novel modules: Semantic-Aware Normalization (SAN) and Semantic-Aware Whitening (SAW). Specifically, SAN focuses on category-level center alignment between features from different image styles, while SAW enforces distributed alignment for the already center-aligned features. With the help of SAN and SAW, we encourage both intra-category compactness and inter-category separability. We validate our approach through extensive experiments on widely-used datasets (i.e. GTAV, SYNTHIA, Cityscapes, Mapillary and BDDS). Our approach shows significant improvements over existing state-of-the-art on various backbone networks. Code is available at https://github.com/leolyj/SAN-SAW
Deformation and Correspondence Aware Unsupervised Synthetic-to-Real Scene Flow Estimation for Point Clouds
Mar 31, 2022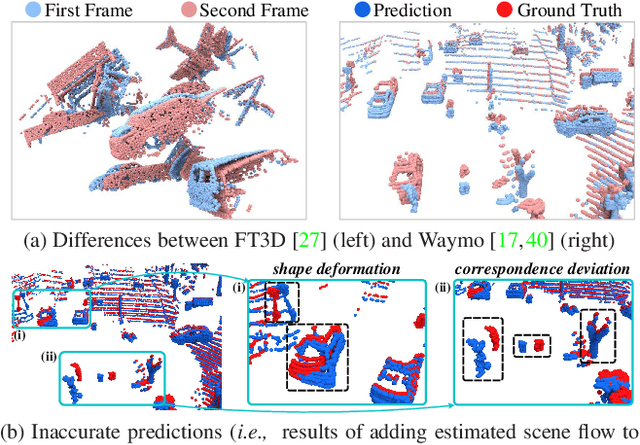
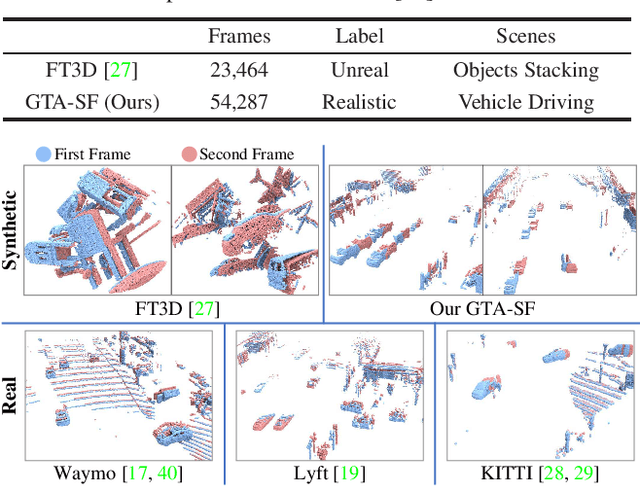
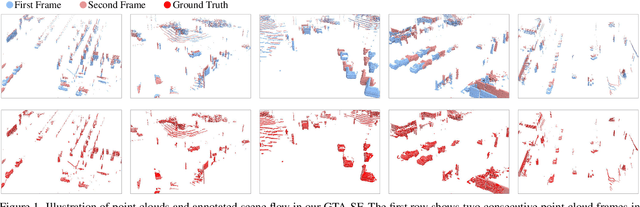
Point cloud scene flow estimation is of practical importance for dynamic scene navigation in autonomous driving. Since scene flow labels are hard to obtain, current methods train their models on synthetic data and transfer them to real scenes. However, large disparities between existing synthetic datasets and real scenes lead to poor model transfer. We make two major contributions to address that. First, we develop a point cloud collector and scene flow annotator for GTA-V engine to automatically obtain diverse realistic training samples without human intervention. With that, we develop a large-scale synthetic scene flow dataset GTA-SF. Second, we propose a mean-teacher-based domain adaptation framework that leverages self-generated pseudo-labels of the target domain. It also explicitly incorporates shape deformation regularization and surface correspondence refinement to address distortions and misalignments in domain transfer. Through extensive experiments, we show that our GTA-SF dataset leads to a consistent boost in model generalization to three real datasets (i.e., Waymo, Lyft and KITTI) as compared to the most widely used FT3D dataset. Moreover, our framework achieves superior adaptation performance on six source-target dataset pairs, remarkably closing the average domain gap by 60%. Data and codes are available at https://github.com/leolyj/DCA-SRSFE
Transformers in Medical Imaging: A Survey
Jan 24, 2022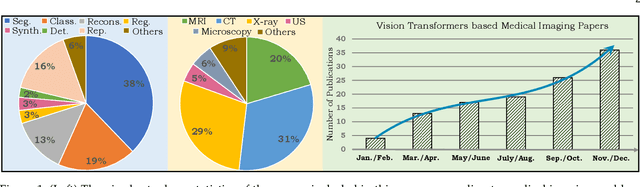
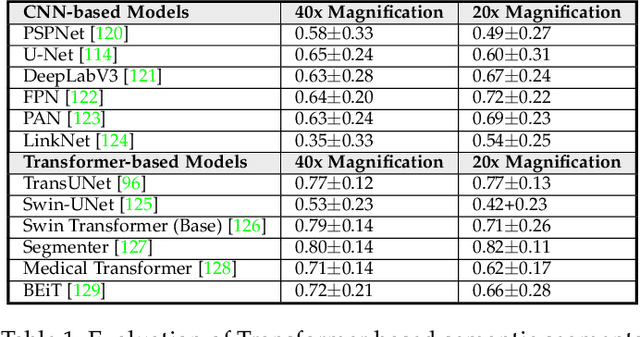
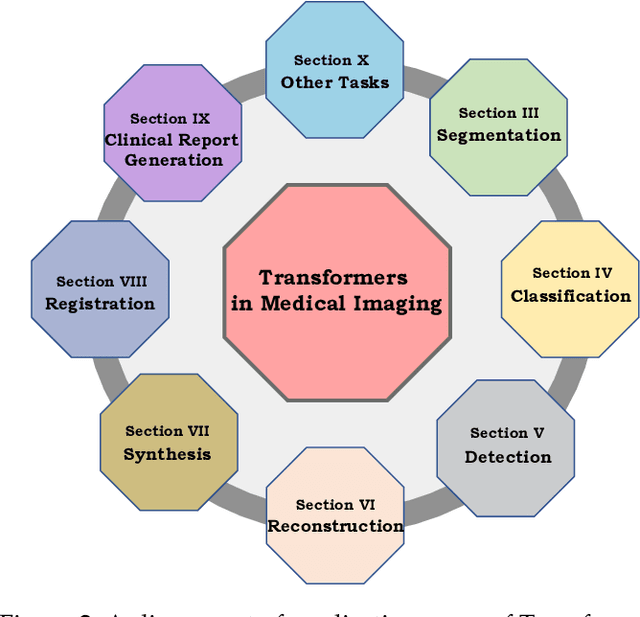
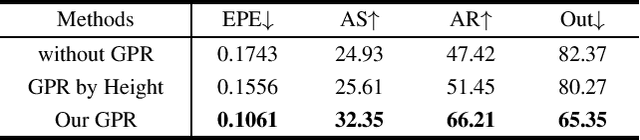
Following unprecedented success on the natural language tasks, Transformers have been successfully applied to several computer vision problems, achieving state-of-the-art results and prompting researchers to reconsider the supremacy of convolutional neural networks (CNNs) as {de facto} operators. Capitalizing on these advances in computer vision, the medical imaging field has also witnessed growing interest for Transformers that can capture global context compared to CNNs with local receptive fields. Inspired from this transition, in this survey, we attempt to provide a comprehensive review of the applications of Transformers in medical imaging covering various aspects, ranging from recently proposed architectural designs to unsolved issues. Specifically, we survey the use of Transformers in medical image segmentation, detection, classification, reconstruction, synthesis, registration, clinical report generation, and other tasks. In particular, for each of these applications, we develop taxonomy, identify application-specific challenges as well as provide insights to solve them, and highlight recent trends. Further, we provide a critical discussion of the field's current state as a whole, including the identification of key challenges, open problems, and outlining promising future directions. We hope this survey will ignite further interest in the community and provide researchers with an up-to-date reference regarding applications of Transformer models in medical imaging. Finally, to cope with the rapid development in this field, we intend to regularly update the relevant latest papers and their open-source implementations at \url{https://github.com/fahadshamshad/awesome-transformers-in-medical-imaging}.
ProposalCLIP: Unsupervised Open-Category Object Proposal Generation via Exploiting CLIP Cues
Jan 18, 2022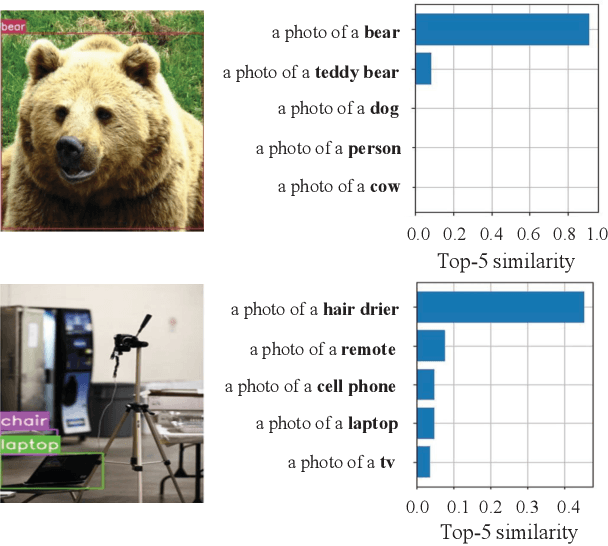
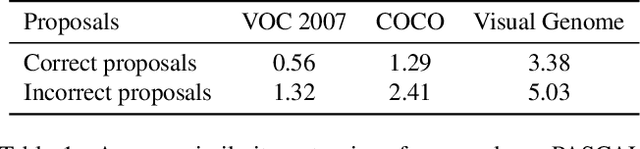

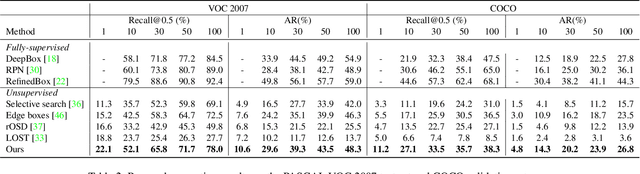
Object proposal generation is an important and fundamental task in computer vision. In this paper, we propose ProposalCLIP, a method towards unsupervised open-category object proposal generation. Unlike previous works which require a large number of bounding box annotations and/or can only generate proposals for limited object categories, our ProposalCLIP is able to predict proposals for a large variety of object categories without annotations, by exploiting CLIP (contrastive language-image pre-training) cues. Firstly, we analyze CLIP for unsupervised open-category proposal generation and design an objectness score based on our empirical analysis on proposal selection. Secondly, a graph-based merging module is proposed to solve the limitations of CLIP cues and merge fragmented proposals. Finally, we present a proposal regression module that extracts pseudo labels based on CLIP cues and trains a lightweight network to further refine proposals. Extensive experiments on PASCAL VOC, COCO and Visual Genome datasets show that our ProposalCLIP can better generate proposals than previous state-of-the-art methods. Our ProposalCLIP also shows benefits for downstream tasks, such as unsupervised object detection.
Unpaired Referring Expression Grounding via Bidirectional Cross-Modal Matching
Jan 18, 2022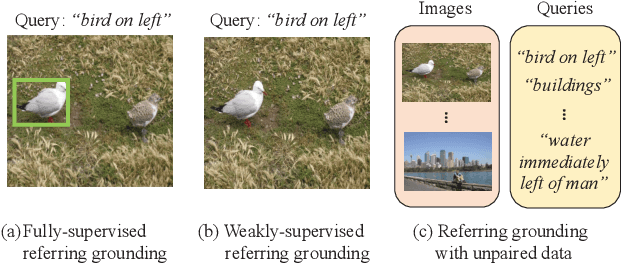
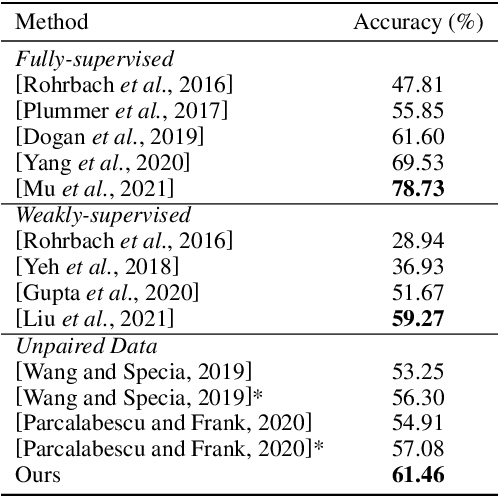
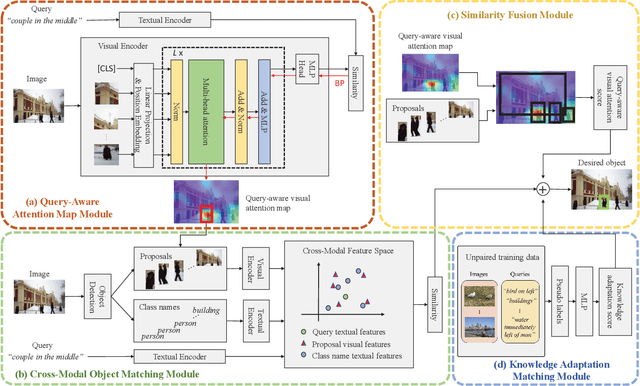
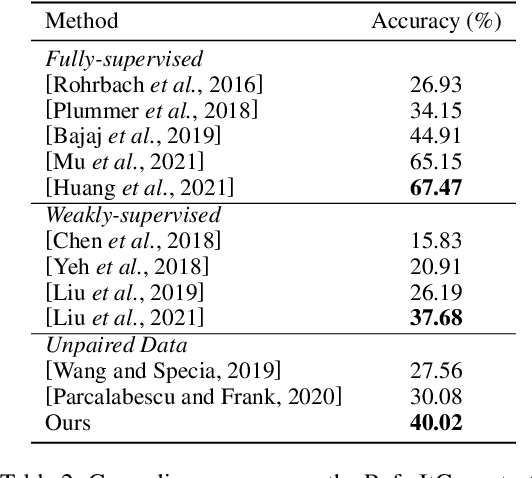
Referring expression grounding is an important and challenging task in computer vision. To avoid the laborious annotation in conventional referring grounding, unpaired referring grounding is introduced, where the training data only contains a number of images and queries without correspondences. The few existing solutions to unpaired referring grounding are still preliminary, due to the challenges of learning image-text matching and lack of the top-down guidance with unpaired data. In this paper, we propose a novel bidirectional cross-modal matching (BiCM) framework to address these challenges. Particularly, we design a query-aware attention map (QAM) module that introduces top-down perspective via generating query-specific visual attention maps. A cross-modal object matching (COM) module is further introduced, which exploits the recently emerged image-text matching pretrained model, CLIP, to predict the target objects from a bottom-up perspective. The top-down and bottom-up predictions are then integrated via a similarity funsion (SF) module. We also propose a knowledge adaptation matching (KAM) module that leverages unpaired training data to adapt pretrained knowledge to the target dataset and task. Experiments show that our framework outperforms previous works by 6.55% and 9.94% on two popular grounding datasets.
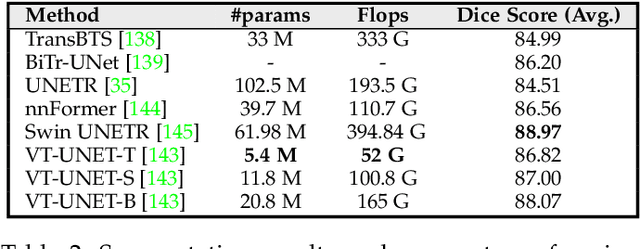
A Volumetric Transformer for Accurate 3D Tumor Segmentation
Nov 26, 2021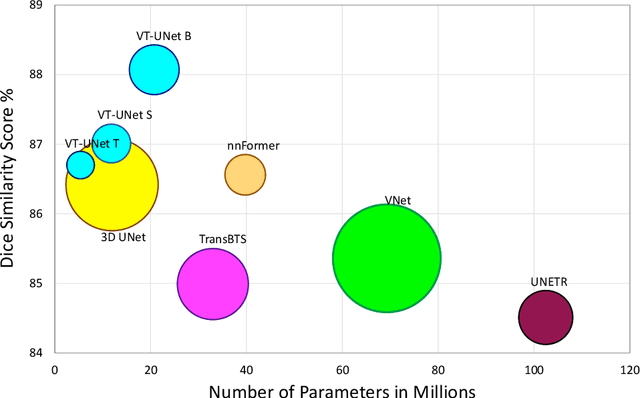
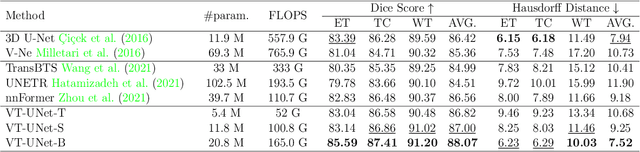
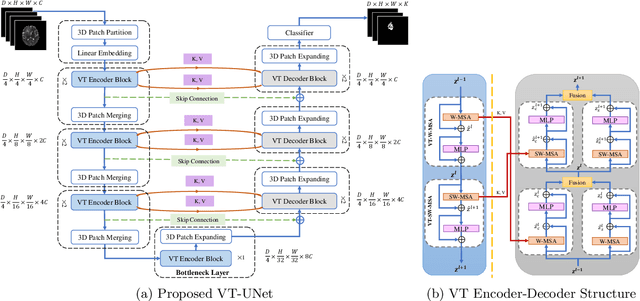
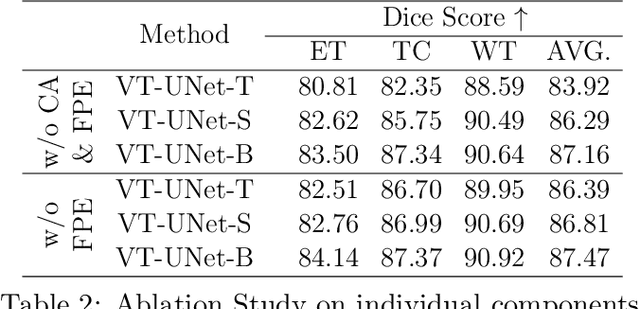
This paper presents a Transformer architecture for volumetric medical image segmentation. Designing a computationally efficient Transformer architecture for volumetric segmentation is a challenging task. It requires keeping a complex balance in encoding local and global spatial cues, and preserving information along all axes of the volumetric data. The proposed volumetric Transformer has a U-shaped encoder-decoder design that processes the input voxels in their entirety. Our encoder has two consecutive self-attention layers to simultaneously encode local and global cues, and our decoder has novel parallel shifted window based self and cross attention blocks to capture fine details for boundary refinement by subsuming Fourier position encoding. Our proposed design choices result in a computationally efficient architecture, which demonstrates promising results on Brain Tumor Segmentation (BraTS) 2021, and Medical Segmentation Decathlon (Pancreas and Liver) datasets for tumor segmentation. We further show that the representations learned by our model transfer better across-datasets and are robust against data corruptions. \href{https://github.com/himashi92/VT-UNet}{Our code implementation is publicly available}.
Restormer: Efficient Transformer for High-Resolution Image Restoration
Nov 18, 2021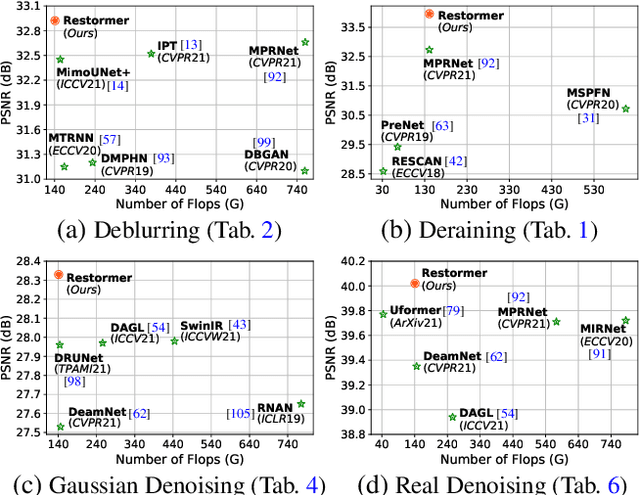
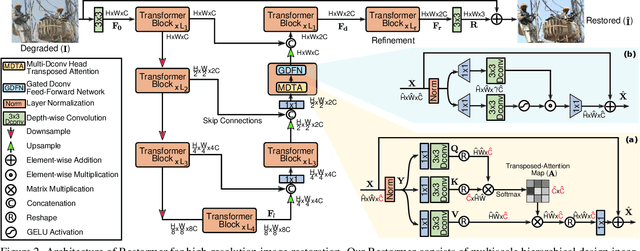
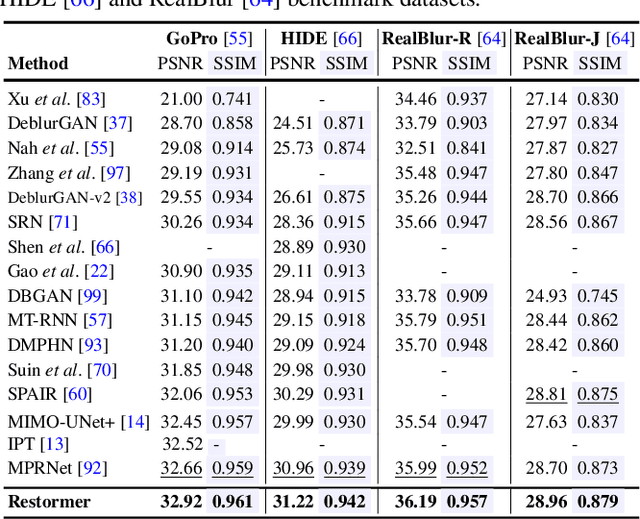
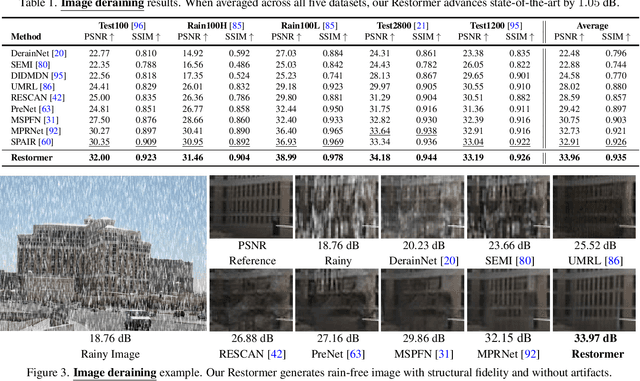
Since convolutional neural networks (CNNs) perform well at learning generalizable image priors from large-scale data, these models have been extensively applied to image restoration and related tasks. Recently, another class of neural architectures, Transformers, have shown significant performance gains on natural language and high-level vision tasks. While the Transformer model mitigates the shortcomings of CNNs (i.e., limited receptive field and inadaptability to input content), its computational complexity grows quadratically with the spatial resolution, therefore making it infeasible to apply to most image restoration tasks involving high-resolution images. In this work, we propose an efficient Transformer model by making several key designs in the building blocks (multi-head attention and feed-forward network) such that it can capture long-range pixel interactions, while still remaining applicable to large images. Our model, named Restoration Transformer (Restormer), achieves state-of-the-art results on several image restoration tasks, including image deraining, single-image motion deblurring, defocus deblurring (single-image and dual-pixel data), and image denoising (Gaussian grayscale/color denoising, and real image denoising). The source code and pre-trained models are available at https://github.com/swz30/Restormer.
MTGLS: Multi-Task Gaze Estimation with Limited Supervision
Oct 23, 2021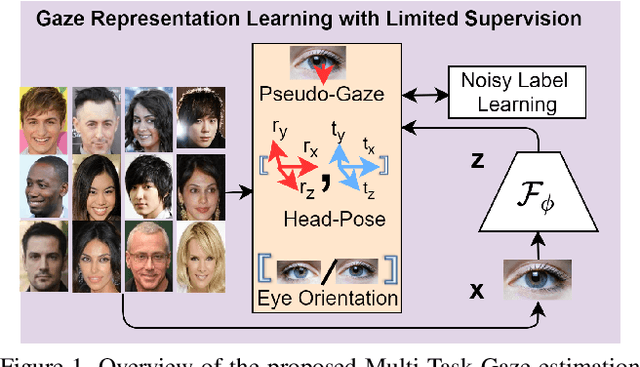
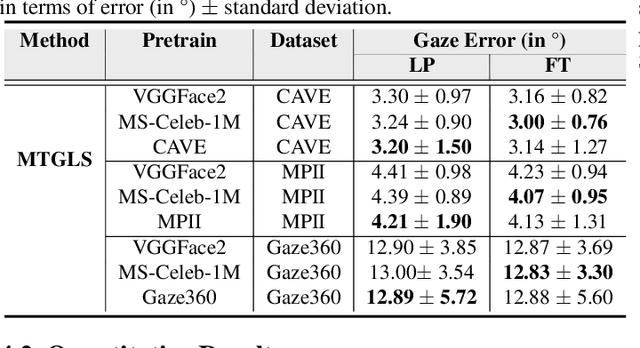
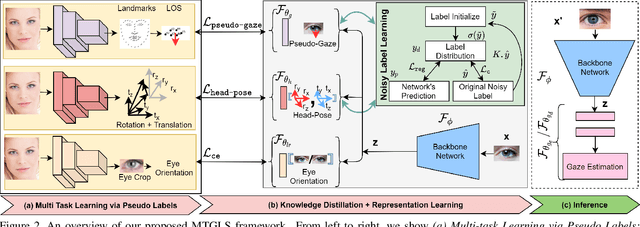
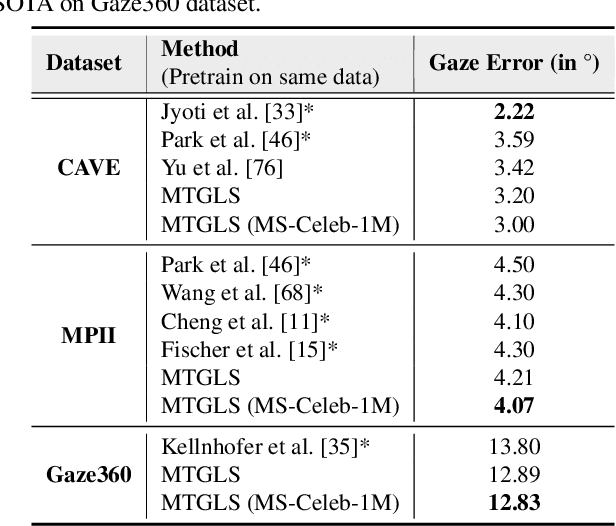
Robust gaze estimation is a challenging task, even for deep CNNs, due to the non-availability of large-scale labeled data. Moreover, gaze annotation is a time-consuming process and requires specialized hardware setups. We propose MTGLS: a Multi-Task Gaze estimation framework with Limited Supervision, which leverages abundantly available non-annotated facial image data. MTGLS distills knowledge from off-the-shelf facial image analysis models, and learns strong feature representations of human eyes, guided by three complementary auxiliary signals: (a) the line of sight of the pupil (i.e. pseudo-gaze) defined by the localized facial landmarks, (b) the head-pose given by Euler angles, and (c) the orientation of the eye patch (left/right eye). To overcome inherent noise in the supervisory signals, MTGLS further incorporates a noise distribution modelling approach. Our experimental results show that MTGLS learns highly generalized representations which consistently perform well on a range of datasets. Our proposed framework outperforms the unsupervised state-of-the-art on CAVE (by 6.43%) and even supervised state-of-the-art methods on Gaze360 (by 6.59%) datasets.
Automatic Gaze Analysis: A Survey of Deep Learning based Approaches
Aug 30, 2021
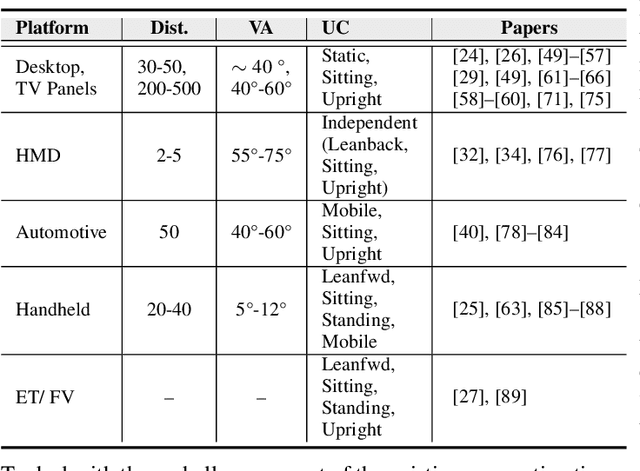
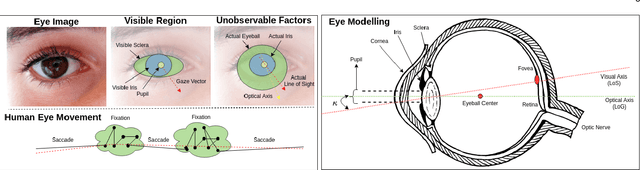
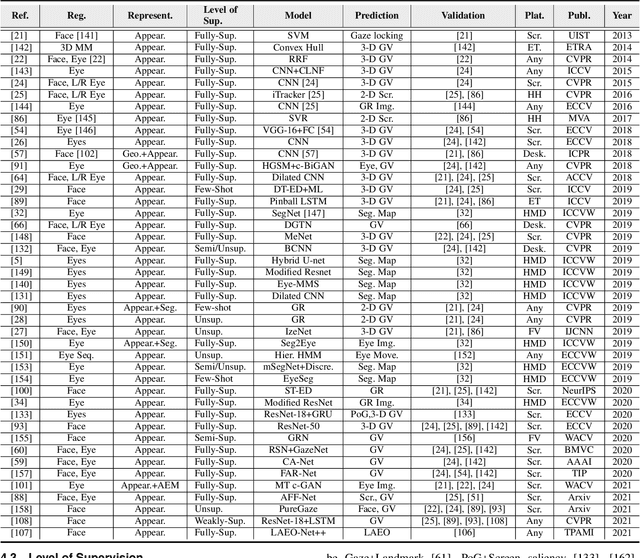
Eye gaze analysis is an important research problem in the field of Computer Vision and Human-Computer Interaction. Even with notable progress in the last 10 years, automatic gaze analysis still remains challenging due to the uniqueness of eye appearance, eye-head interplay, occlusion, image quality, and illumination conditions. There are several open questions including what are the important cues to interpret gaze direction in an unconstrained environment without prior knowledge and how to encode them in real-time. We review the progress across a range of gaze analysis tasks and applications to elucidate these fundamental questions; identify effective methods in gaze analysis and provide possible future directions. We analyze recent gaze estimation and segmentation methods, especially in the unsupervised and weakly supervised domain, based on their advantages and reported evaluation metrics. Our analysis shows that the development of a robust and generic gaze analysis method still needs to address real-world challenges such as unconstrained setup and learning with less supervision. We conclude by discussing future research directions for designing a real-world gaze analysis system that can propagate to other domains including Computer Vision, Augmented Reality (AR), Virtual Reality (VR), and Human Computer Interaction (HCI). Project Page: https://github.com/i-am-shreya/EyeGazeSurvey}{https://github.com/i-am-shreya/EyeGazeSurvey