 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBYOL-Explore: Exploration by Bootstrapped Prediction
Jun 16, 2022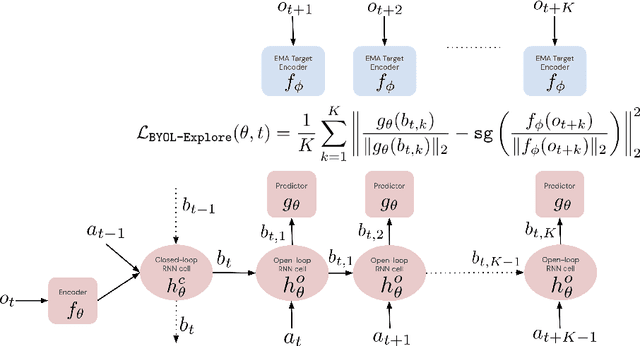
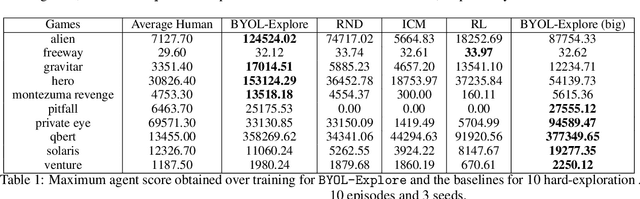

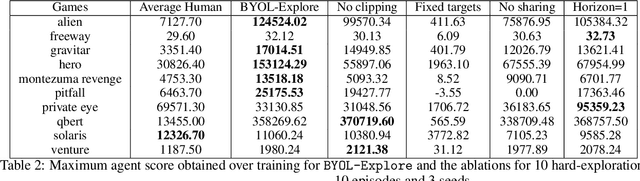
We present BYOL-Explore, a conceptually simple yet general approach for curiosity-driven exploration in visually-complex environments. BYOL-Explore learns a world representation, the world dynamics, and an exploration policy all-together by optimizing a single prediction loss in the latent space with no additional auxiliary objective. We show that BYOL-Explore is effective in DM-HARD-8, a challenging partially-observable continuous-action hard-exploration benchmark with visually-rich 3-D environments. On this benchmark, we solve the majority of the tasks purely through augmenting the extrinsic reward with BYOL-Explore s intrinsic reward, whereas prior work could only get off the ground with human demonstrations. As further evidence of the generality of BYOL-Explore, we show that it achieves superhuman performance on the ten hardest exploration games in Atari while having a much simpler design than other competitive agents.
KL-Entropy-Regularized RL with a Generative Model is Minimax Optimal
May 27, 2022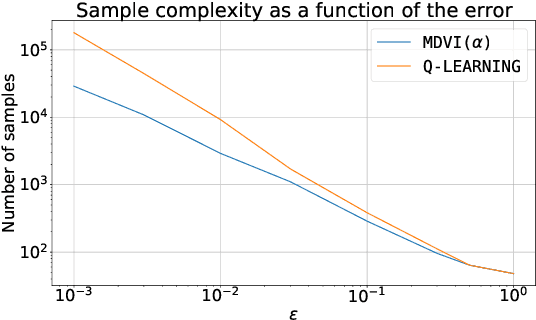

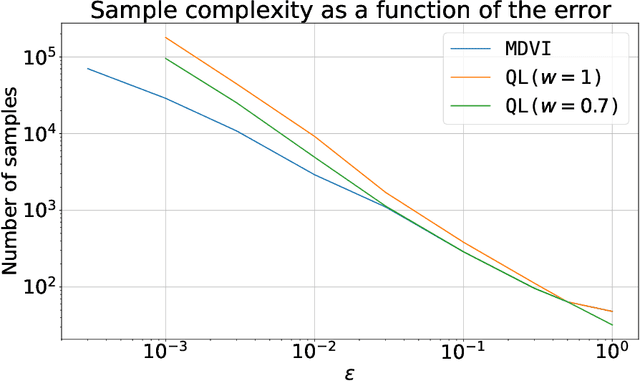
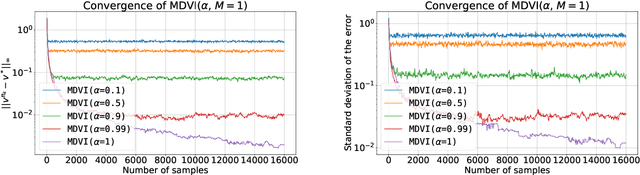
In this work, we consider and analyze the sample complexity of model-free reinforcement learning with a generative model. Particularly, we analyze mirror descent value iteration (MDVI) by Geist et al. (2019) and Vieillard et al. (2020a), which uses the Kullback-Leibler divergence and entropy regularization in its value and policy updates. Our analysis shows that it is nearly minimax-optimal for finding an $\varepsilon$-optimal policy when $\varepsilon$ is sufficiently small. This is the first theoretical result that demonstrates that a simple model-free algorithm without variance-reduction can be nearly minimax-optimal under the considered setting.
Drop, Swap, and Generate: A Self-Supervised Approach for Generating Neural Activity
Nov 03, 2021Meaningful and simplified representations of neural activity can yield insights into how and what information is being processed within a neural circuit. However, without labels, finding representations that reveal the link between the brain and behavior can be challenging. Here, we introduce a novel unsupervised approach for learning disentangled representations of neural activity called Swap-VAE. Our approach combines a generative modeling framework with an instance-specific alignment loss that tries to maximize the representational similarity between transformed views of the input (brain state). These transformed (or augmented) views are created by dropping out neurons and jittering samples in time, which intuitively should lead the network to a representation that maintains both temporal consistency and invariance to the specific neurons used to represent the neural state. Through evaluations on both synthetic data and neural recordings from hundreds of neurons in different primate brains, we show that it is possible to build representations that disentangle neural datasets along relevant latent dimensions linked to behavior.
Mine Your Own vieW: Self-Supervised Learning Through Across-Sample Prediction
Feb 19, 2021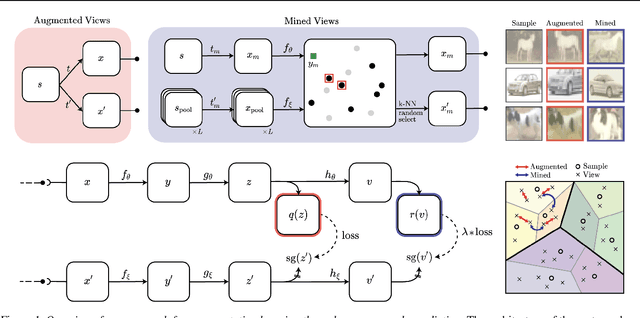
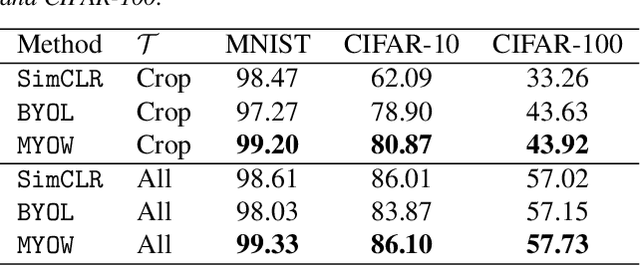
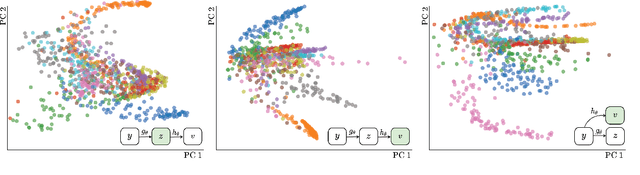
State-of-the-art methods for self-supervised learning (SSL) build representations by maximizing the similarity between different augmented "views" of a sample. Because these approaches try to match views of the same sample, they can be too myopic and fail to produce meaningful results when augmentations are not sufficiently rich. This motivates the use of the dataset itself to find similar, yet distinct, samples to serve as views for one another. In this paper, we introduce Mine Your Own vieW (MYOW), a new approach for building across-sample prediction into SSL. The idea behind our approach is to actively mine views, finding samples that are close in the representation space of the network, and then predict, from one sample's latent representation, the representation of a nearby sample. In addition to showing the promise of MYOW on standard datasets used in computer vision, we highlight the power of this idea in a novel application in neuroscience where rich augmentations are not already established. When applied to neural datasets, MYOW outperforms other self-supervised approaches in all examples (in some cases by more than 10%), and surpasses the supervised baseline for most datasets. By learning to predict the latent representation of similar samples, we show that it is possible to learn good representations in new domains where augmentations are still limited.
Bootstrapped Representation Learning on Graphs
Feb 12, 2021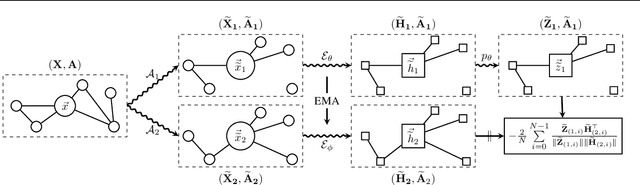
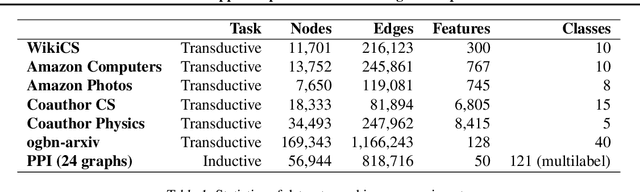
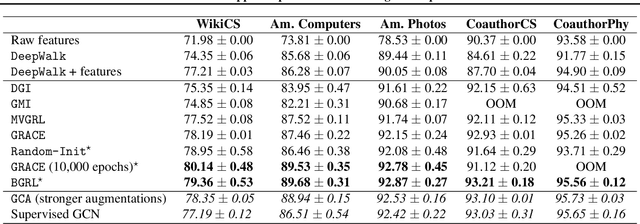
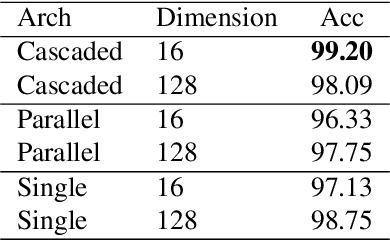
Current state-of-the-art self-supervised learning methods for graph neural networks (GNNs) are based on contrastive learning. As such, they heavily depend on the construction of augmentations and negative examples. For example, on the standard PPI benchmark, increasing the number of negative pairs improves performance, thereby requiring computation and memory cost quadratic in the number of nodes to achieve peak performance. Inspired by BYOL, a recently introduced method for self-supervised learning that does not require negative pairs, we present Bootstrapped Graph Latents, BGRL, a self-supervised graph representation method that gets rid of this potentially quadratic bottleneck. BGRL outperforms or matches the previous unsupervised state-of-the-art results on several established benchmark datasets. Moreover, it enables the effective usage of graph attentional (GAT) encoders, allowing us to further improve the state of the art. In particular on the PPI dataset, using GAT as an encoder we achieve state-of-the-art 70.49% Micro-F1, using the linear evaluation protocol. On all other datasets under consideration, our model is competitive with the equivalent supervised GNN results, often exceeding them.
Geometric Entropic Exploration
Jan 07, 2021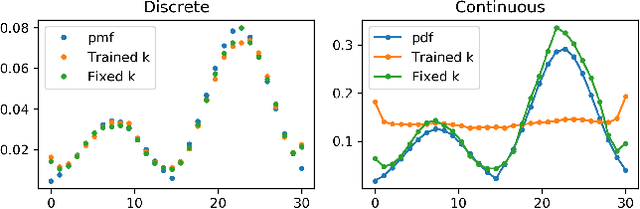
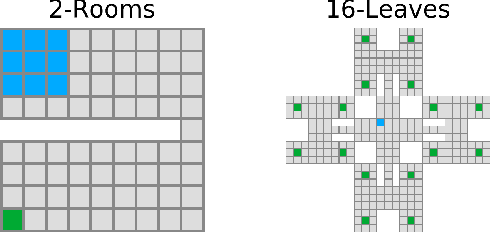
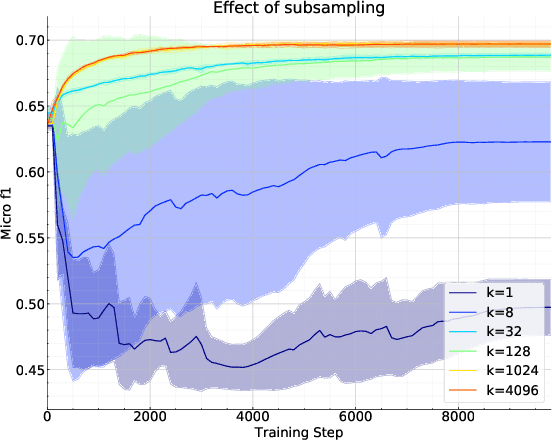
Exploration is essential for solving complex Reinforcement Learning (RL) tasks. Maximum State-Visitation Entropy (MSVE) formulates the exploration problem as a well-defined policy optimization problem whose solution aims at visiting all states as uniformly as possible. This is in contrast to standard uncertainty-based approaches where exploration is transient and eventually vanishes. However, existing approaches to MSVE are theoretically justified only for discrete state-spaces as they are oblivious to the geometry of continuous domains. We address this challenge by introducing Geometric Entropy Maximisation (GEM), a new algorithm that maximises the geometry-aware Shannon entropy of state-visits in both discrete and continuous domains. Our key theoretical contribution is casting geometry-aware MSVE exploration as a tractable problem of optimising a simple and novel noise-contrastive objective function. In our experiments, we show the efficiency of GEM in solving several RL problems with sparse rewards, compared against other deep RL exploration approaches.
The Advantage Regret-Matching Actor-Critic
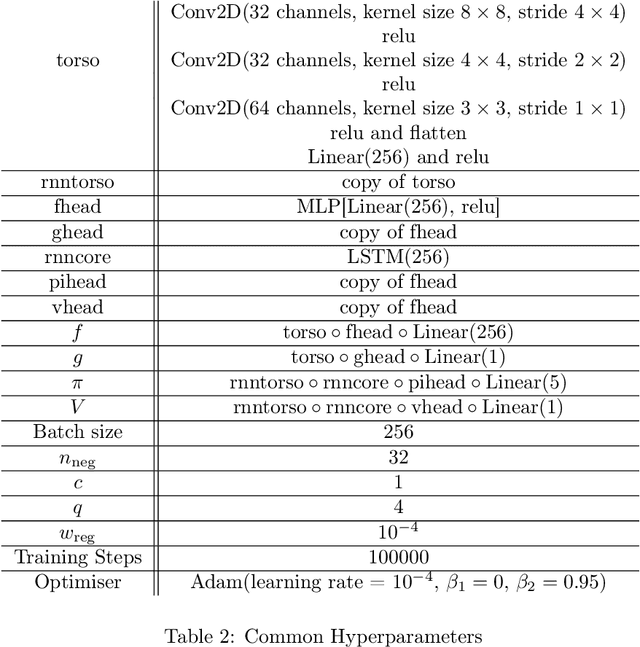
Aug 27, 2020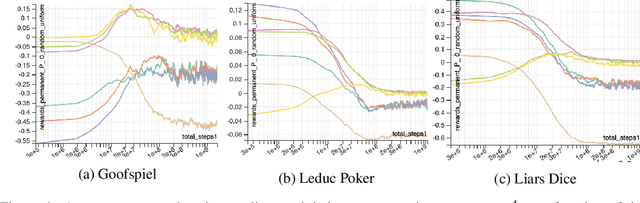
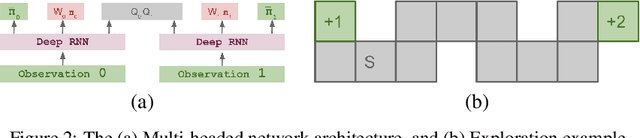
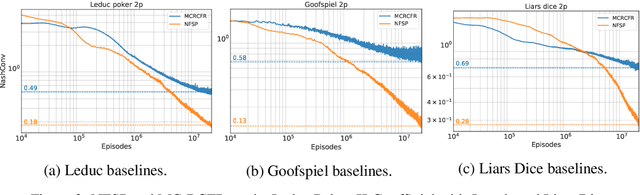
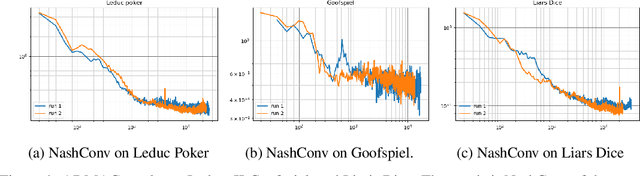
Regret minimization has played a key role in online learning, equilibrium computation in games, and reinforcement learning (RL). In this paper, we describe a general model-free RL method for no-regret learning based on repeated reconsideration of past behavior. We propose a model-free RL algorithm, the AdvantageRegret-Matching Actor-Critic (ARMAC): rather than saving past state-action data, ARMAC saves a buffer of past policies, replaying through them to reconstruct hindsight assessments of past behavior. These retrospective value estimates are used to predict conditional advantages which, combined with regret matching, produces a new policy. In particular, ARMAC learns from sampled trajectories in a centralized training setting, without requiring the application of importance sampling commonly used in Monte Carlo counterfactual regret (CFR) minimization; hence, it does not suffer from excessive variance in large environments. In the single-agent setting, ARMAC shows an interesting form of exploration by keeping past policies intact. In the multiagent setting, ARMAC in self-play approaches Nash equilibria on some partially-observable zero-sum benchmarks. We provide exploitability estimates in the significantly larger game of betting-abstracted no-limit Texas Hold'em.
Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning
Jun 13, 2020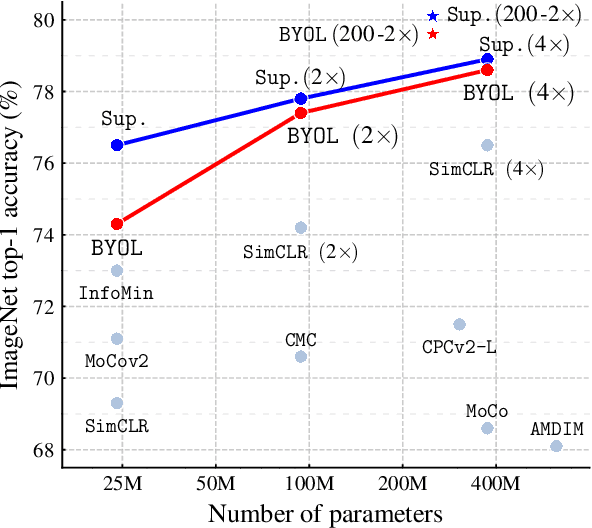

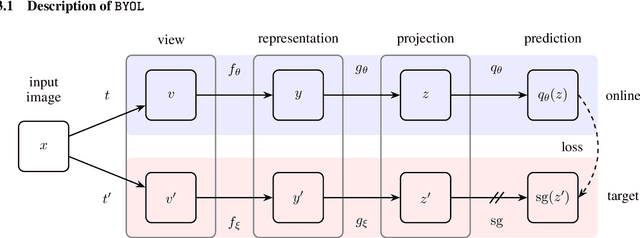
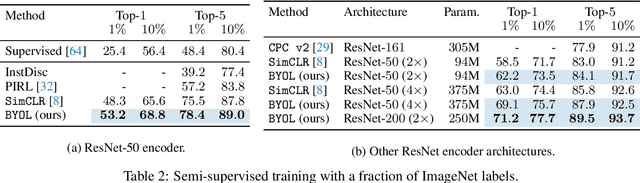
We introduce Bootstrap Your Own Latent (BYOL), a new approach to self-supervised image representation learning. BYOL relies on two neural networks, referred to as online and target networks, that interact and learn from each other. From an augmented view of an image, we train the online network to predict the target network representation of the same image under a different augmented view. At the same time, we update the target network with a slow-moving average of the online network. While state-of-the art methods intrinsically rely on negative pairs, BYOL achieves a new state of the art without them. BYOL reaches $74.3\%$ top-1 classification accuracy on ImageNet using the standard linear evaluation protocol with a ResNet-50 architecture and $79.6\%$ with a larger ResNet. We show that BYOL performs on par or better than the current state of the art on both transfer and semi-supervised benchmarks.
Bootstrap Latent-Predictive Representations for Multitask Reinforcement Learning
Apr 30, 2020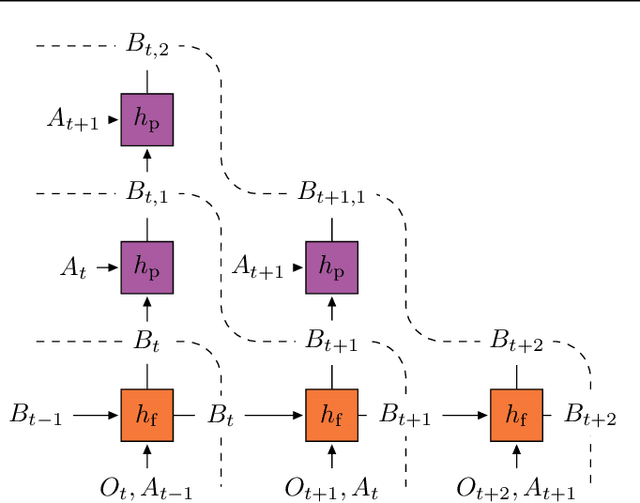
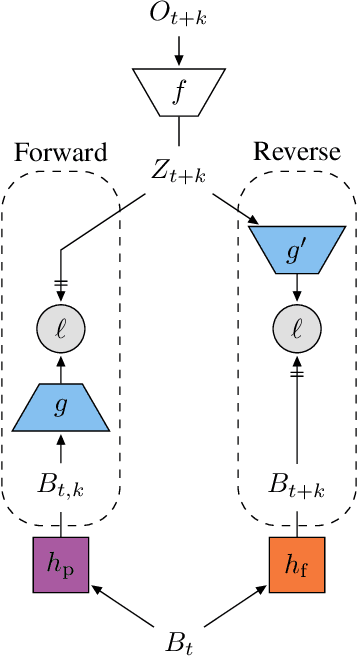

Learning a good representation is an essential component for deep reinforcement learning (RL). Representation learning is especially important in multitask and partially observable settings where building a representation of the unknown environment is crucial to solve the tasks. Here we introduce Prediction of Bootstrap Latents (PBL), a simple and flexible self-supervised representation learning algorithm for multitask deep RL. PBL builds on multistep predictive representations of future observations, and focuses on capturing structured information about environment dynamics. Specifically, PBL trains its representation by predicting latent embeddings of future observations. These latent embeddings are themselves trained to be predictive of the aforementioned representations. These predictions form a bootstrapping effect, allowing the agent to learn more about the key aspects of the environment dynamics. In addition, by defining prediction tasks completely in latent space, PBL provides the flexibility of using multimodal observations involving pixel images, language instructions, rewards and more. We show in our experiments that PBL delivers across-the-board improved performance over state of the art deep RL agents in the DMLab-30 and Atari-57 multitask setting.
World Discovery Models
Mar 01, 2019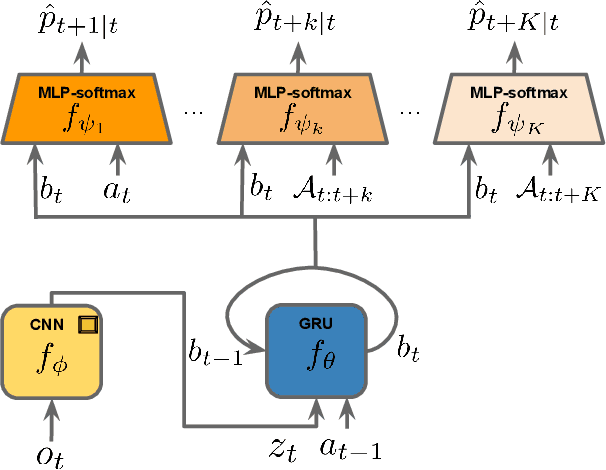
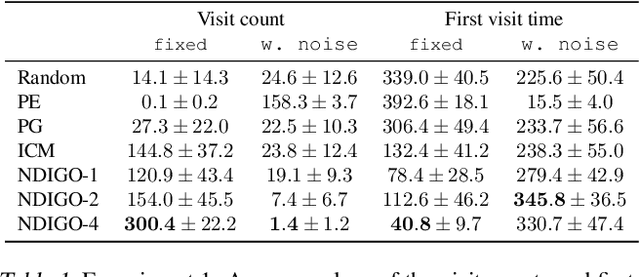

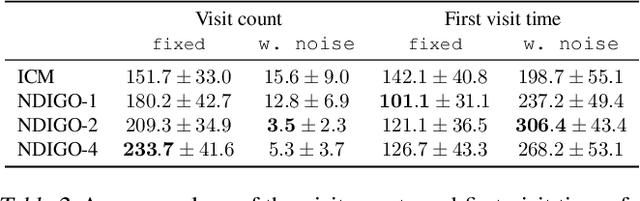
As humans we are driven by a strong desire for seeking novelty in our world. Also upon observing a novel pattern we are capable of refining our understanding of the world based on the new information---humans can discover their world. The outstanding ability of the human mind for discovery has led to many breakthroughs in science, art and technology. Here we investigate the possibility of building an agent capable of discovering its world using the modern AI technology. In particular we introduce NDIGO, Neural Differential Information Gain Optimisation, a self-supervised discovery model that aims at seeking new information to construct a global view of its world from partial and noisy observations. Our experiments on some controlled 2-D navigation tasks show that NDIGO outperforms state-of-the-art information-seeking methods in terms of the quality of the learned representation. The improvement in performance is particularly significant in the presence of white or structured noise where other information-seeking methods follow the noise instead of discovering their world.