 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric Entropic Exploration
Paper and Code
Jan 07, 2021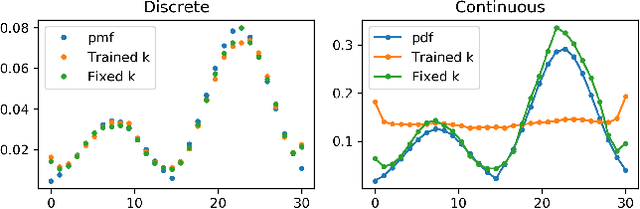
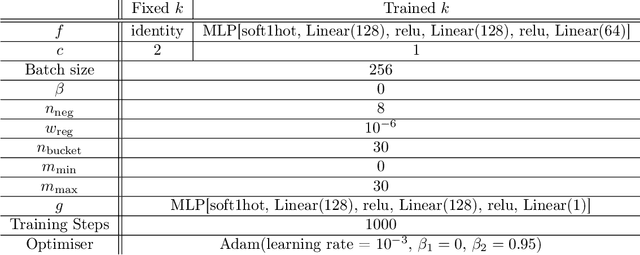
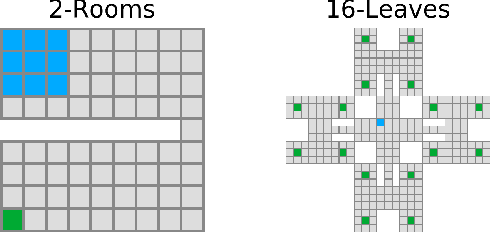
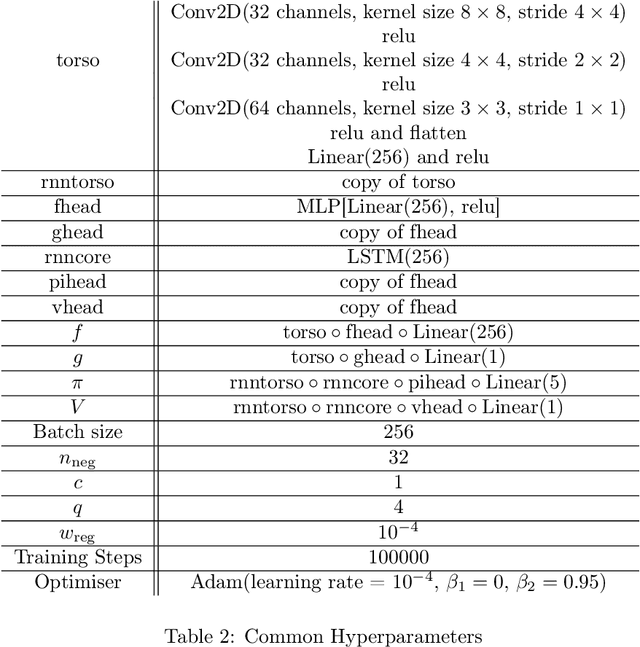
Exploration is essential for solving complex Reinforcement Learning (RL) tasks. Maximum State-Visitation Entropy (MSVE) formulates the exploration problem as a well-defined policy optimization problem whose solution aims at visiting all states as uniformly as possible. This is in contrast to standard uncertainty-based approaches where exploration is transient and eventually vanishes. However, existing approaches to MSVE are theoretically justified only for discrete state-spaces as they are oblivious to the geometry of continuous domains. We address this challenge by introducing Geometric Entropy Maximisation (GEM), a new algorithm that maximises the geometry-aware Shannon entropy of state-visits in both discrete and continuous domains. Our key theoretical contribution is casting geometry-aware MSVE exploration as a tractable problem of optimising a simple and novel noise-contrastive objective function. In our experiments, we show the efficiency of GEM in solving several RL problems with sparse rewards, compared against other deep RL exploration approaches.