 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrustratingly Hard Evidence Retrieval for QA Over Books
Jul 20, 2020
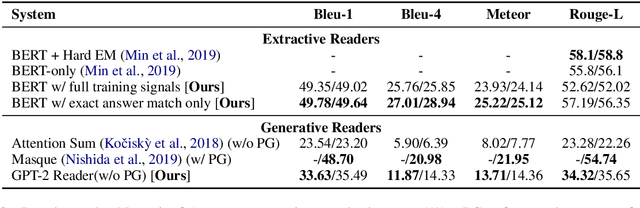
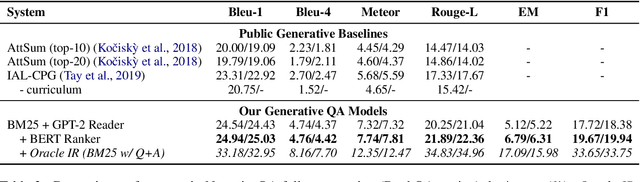
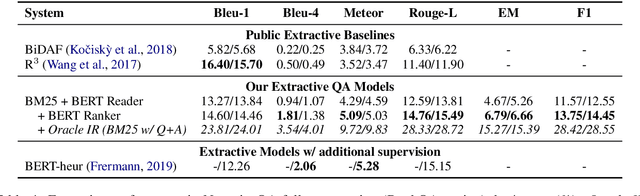
A lot of progress has been made to improve question answering (QA) in recent years, but the special problem of QA over narrative book stories has not been explored in-depth. We formulate BookQA as an open-domain QA task given its similar dependency on evidence retrieval. We further investigate how state-of-the-art open-domain QA approaches can help BookQA. Besides achieving state-of-the-art on the NarrativeQA benchmark, our study also reveals the difficulty of evidence retrieval in books with a wealth of experiments and analysis - which necessitates future effort on novel solutions for evidence retrieval in BookQA.
Differential Treatment for Stuff and Things: A Simple Unsupervised Domain Adaptation Method for Semantic Segmentation
Apr 22, 2020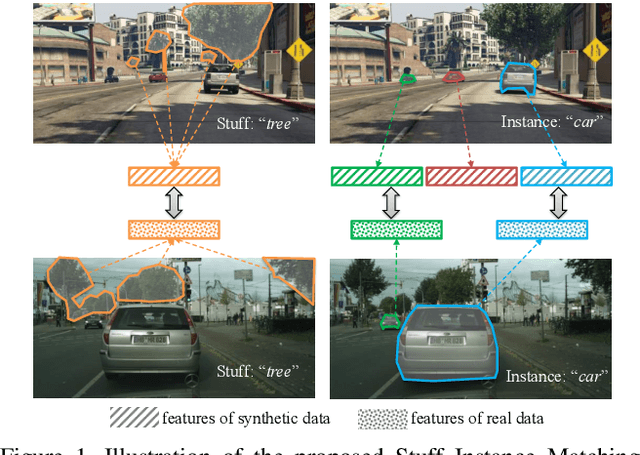
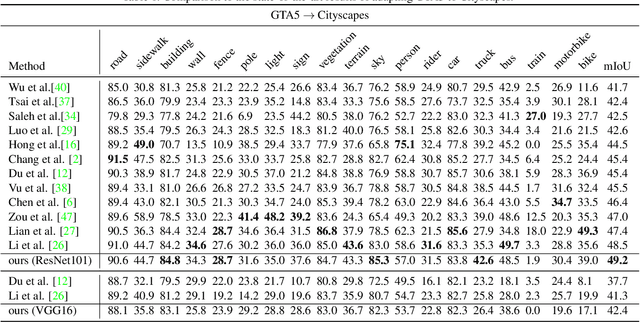
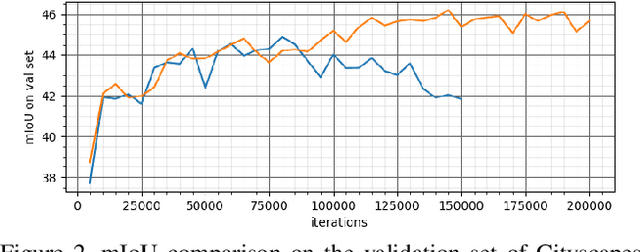
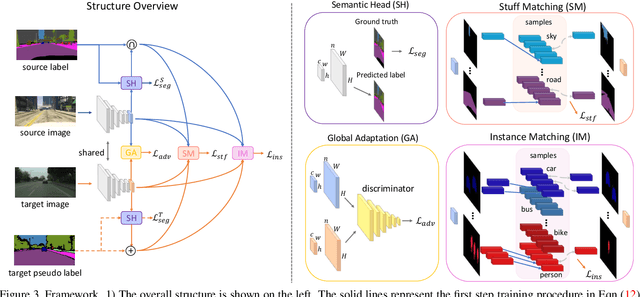
We consider the problem of unsupervised domain adaptation for semantic segmentation by easing the domain shift between the source domain (synthetic data) and the target domain (real data) in this work. State-of-the-art approaches prove that performing semantic-level alignment is helpful in tackling the domain shift issue. Based on the observation that stuff categories usually share similar appearances across images of different domains while things (i.e. object instances) have much larger differences, we propose to improve the semantic-level alignment with different strategies for stuff regions and for things: 1) for the stuff categories, we generate feature representation for each class and conduct the alignment operation from the target domain to the source domain; 2) for the thing categories, we generate feature representation for each individual instance and encourage the instance in the target domain to align with the most similar one in the source domain. In this way, the individual differences within thing categories will also be considered to alleviate over-alignment. In addition to our proposed method, we further reveal the reason why the current adversarial loss is often unstable in minimizing the distribution discrepancy and show that our method can help ease this issue by minimizing the most similar stuff and instance features between the source and the target domains. We conduct extensive experiments in two unsupervised domain adaptation tasks, i.e. GTA5 to Cityscapes and SYNTHIA to Cityscapes, and achieve the new state-of-the-art segmentation accuracy.
Learning to Recover Reasoning Chains for Multi-Hop Question Answering via Cooperative Games
Apr 06, 2020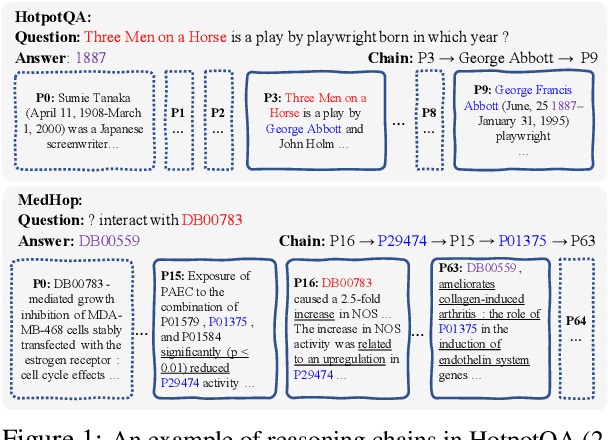
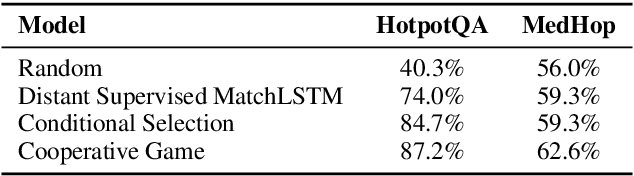
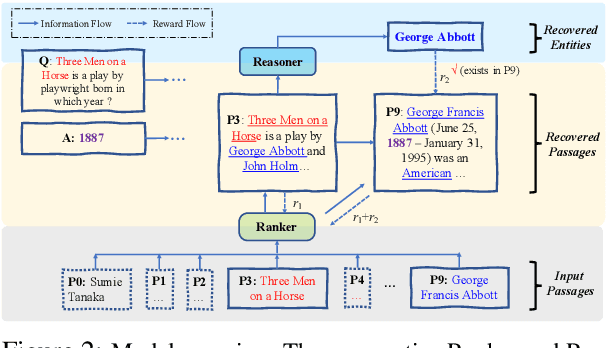

We propose the new problem of learning to recover reasoning chains from weakly supervised signals, i.e., the question-answer pairs. We propose a cooperative game approach to deal with this problem, in which how the evidence passages are selected and how the selected passages are connected are handled by two models that cooperate to select the most confident chains from a large set of candidates (from distant supervision). For evaluation, we created benchmarks based on two multi-hop QA datasets, HotpotQA and MedHop; and hand-labeled reasoning chains for the latter. The experimental results demonstrate the effectiveness of our proposed approach.
Invariant Rationalization
Mar 22, 2020

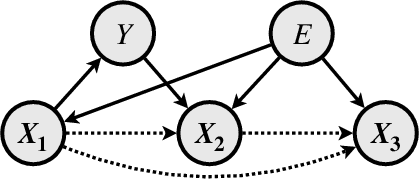
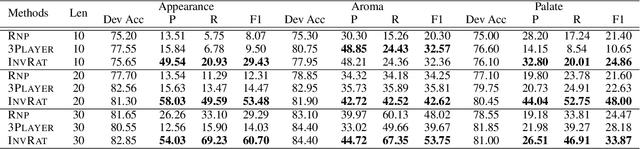
Selective rationalization improves neural network interpretability by identifying a small subset of input features -- the rationale -- that best explains or supports the prediction. A typical rationalization criterion, i.e. maximum mutual information (MMI), finds the rationale that maximizes the prediction performance based only on the rationale. However, MMI can be problematic because it picks up spurious correlations between the input features and the output. Instead, we introduce a game-theoretic invariant rationalization criterion where the rationales are constrained to enable the same predictor to be optimal across different environments. We show both theoretically and empirically that the proposed rationales can rule out spurious correlations, generalize better to different test scenarios, and align better with human judgments. Our data and code are available.
Leveraging Dependency Forest for Neural Medical Relation Extraction
Dec 16, 2019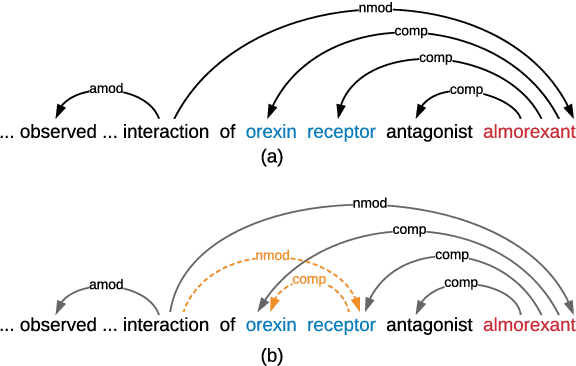
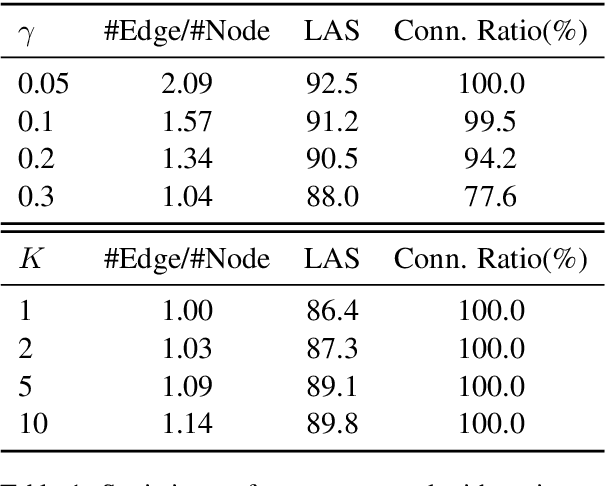
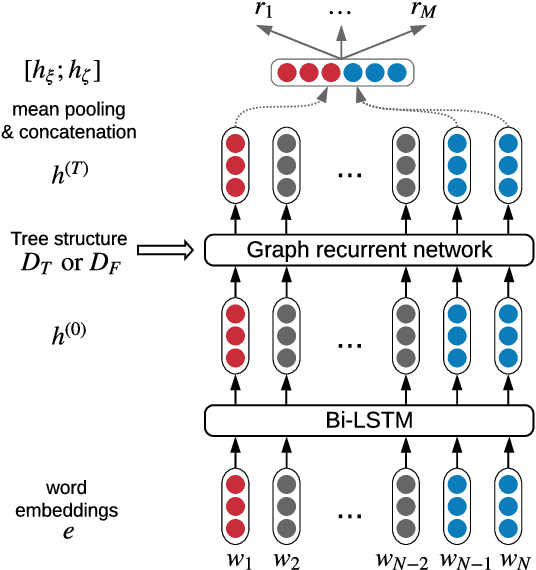
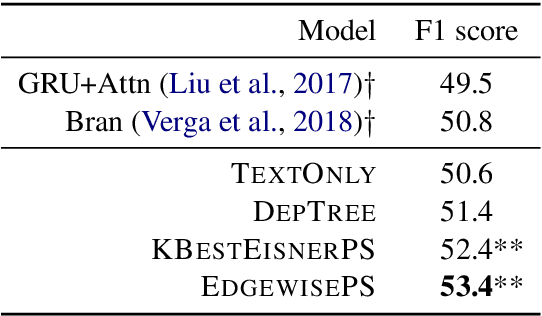
Medical relation extraction discovers relations between entity mentions in text, such as research articles. For this task, dependency syntax has been recognized as a crucial source of features. Yet in the medical domain, 1-best parse trees suffer from relatively low accuracies, diminishing their usefulness. We investigate a method to alleviate this problem by utilizing dependency forests. Forests contain many possible decisions and therefore have higher recall but more noise compared with 1-best outputs. A graph neural network is used to represent the forests, automatically distinguishing the useful syntactic information from parsing noise. Results on two biomedical benchmarks show that our method outperforms the standard tree-based methods, giving the state-of-the-art results in the literature.
Generalizable Resource Allocation in Stream Processing via Deep Reinforcement Learning
Nov 19, 2019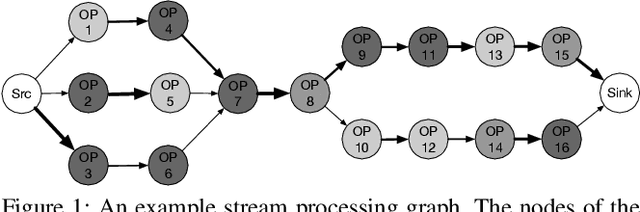
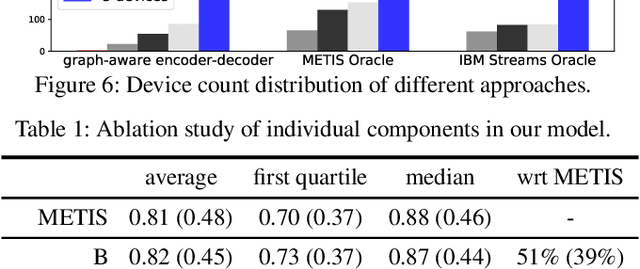
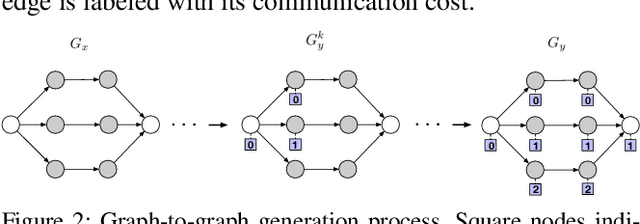

This paper considers the problem of resource allocation in stream processing, where continuous data flows must be processed in real time in a large distributed system. To maximize system throughput, the resource allocation strategy that partitions the computation tasks of a stream processing graph onto computing devices must simultaneously balance workload distribution and minimize communication. Since this problem of graph partitioning is known to be NP-complete yet crucial to practical streaming systems, many heuristic-based algorithms have been developed to find reasonably good solutions. In this paper, we present a graph-aware encoder-decoder framework to learn a generalizable resource allocation strategy that can properly distribute computation tasks of stream processing graphs unobserved from training data. We, for the first time, propose to leverage graph embedding to learn the structural information of the stream processing graphs. Jointly trained with the graph-aware decoder using deep reinforcement learning, our approach can effectively find optimized solutions for unseen graphs. Our experiments show that the proposed model outperforms both METIS, a state-of-the-art graph partitioning algorithm, and an LSTM-based encoder-decoder model, in about 70% of the test cases.
Do Multi-hop Readers Dream of Reasoning Chains?
Oct 31, 2019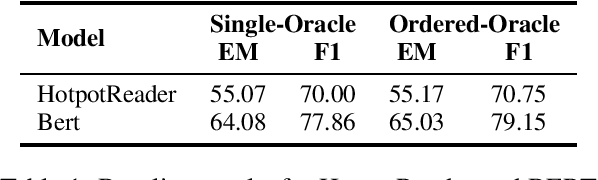
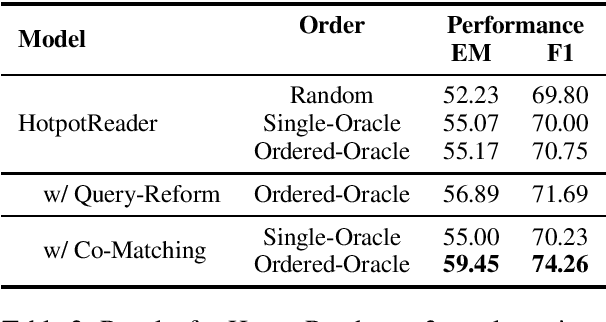

General Question Answering (QA) systems over texts require the multi-hop reasoning capability, i.e. the ability to reason with information collected from multiple passages to derive the answer. In this paper we conduct a systematic analysis to assess such an ability of various existing models proposed for multi-hop QA tasks. Specifically, our analysis investigates that whether providing the full reasoning chain of multiple passages, instead of just one final passage where the answer appears, could improve the performance of the existing QA models. Surprisingly, when using the additional evidence passages, the improvements of all the existing multi-hop reading approaches are rather limited, with the highest error reduction of 5.8% on F1 (corresponding to 1.3% absolute improvement) from the BERT model. To better understand whether the reasoning chains could indeed help find correct answers, we further develop a co-matching-based method that leads to 13.1% error reduction with passage chains when applied to two of our base readers (including BERT). Our results demonstrate the existence of the potential improvement using explicit multi-hop reasoning and the necessity to develop models with better reasoning abilities.
Rethinking Cooperative Rationalization: Introspective Extraction and Complement Control
Oct 29, 2019
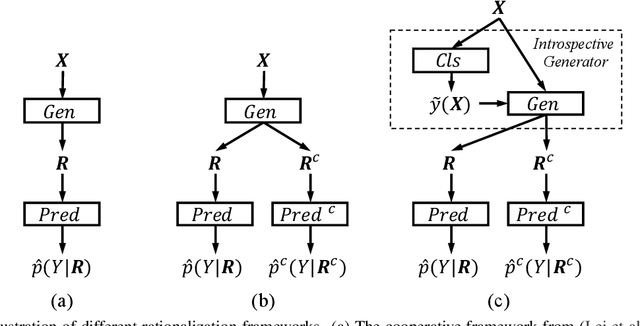
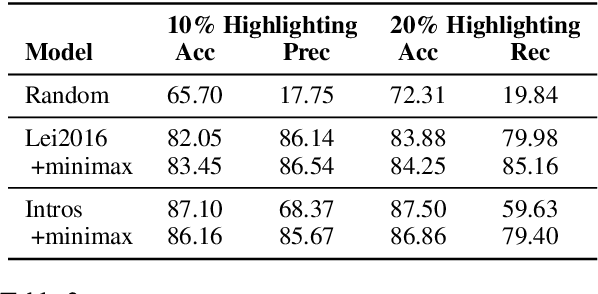
Selective rationalization has become a common mechanism to ensure that predictive models reveal how they use any available features. The selection may be soft or hard, and identifies a subset of input features relevant for prediction. The setup can be viewed as a co-operate game between the selector (aka rationale generator) and the predictor making use of only the selected features. The co-operative setting may, however, be compromised for two reasons. First, the generator typically has no direct access to the outcome it aims to justify, resulting in poor performance. Second, there's typically no control exerted on the information left outside the selection. We revise the overall co-operative framework to address these challenges. We introduce an introspective model which explicitly predicts and incorporates the outcome into the selection process. Moreover, we explicitly control the rationale complement via an adversary so as not to leave any useful information out of the selection. We show that the two complementary mechanisms maintain both high predictive accuracy and lead to comprehensive rationales.
A Game Theoretic Approach to Class-wise Selective Rationalization
Oct 28, 2019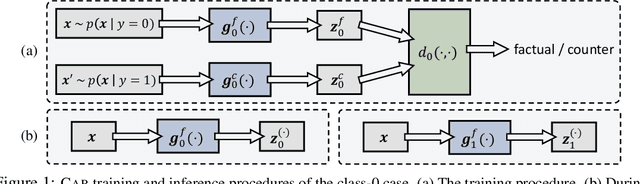

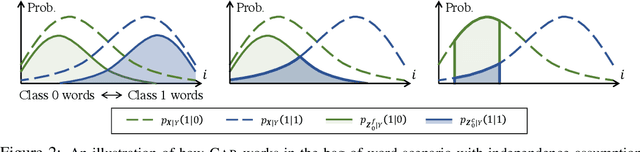
Selection of input features such as relevant pieces of text has become a common technique of highlighting how complex neural predictors operate. The selection can be optimized post-hoc for trained models or incorporated directly into the method itself (self-explaining). However, an overall selection does not properly capture the multi-faceted nature of useful rationales such as pros and cons for decisions. To this end, we propose a new game theoretic approach to class-dependent rationalization, where the method is specifically trained to highlight evidence supporting alternative conclusions. Each class involves three players set up competitively to find evidence for factual and counterfactual scenarios. We show theoretically in a simplified scenario how the game drives the solution towards meaningful class-dependent rationales. We evaluate the method in single- and multi-aspect sentiment classification tasks and demonstrate that the proposed method is able to identify both factual (justifying the ground truth label) and counterfactual (countering the ground truth label) rationales consistent with human rationalization. The code for our method is publicly available.
An Efficient and Margin-Approaching Zero-Confidence Adversarial Attack
Oct 01, 2019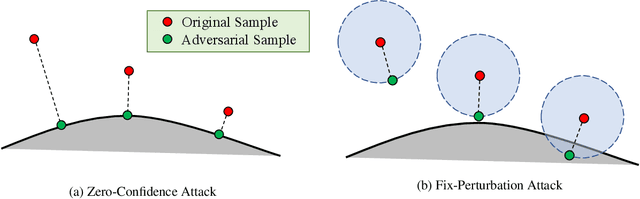
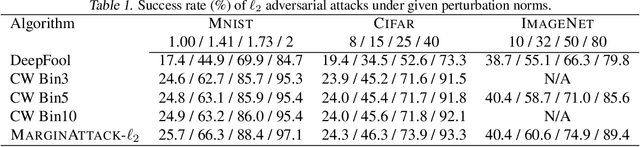
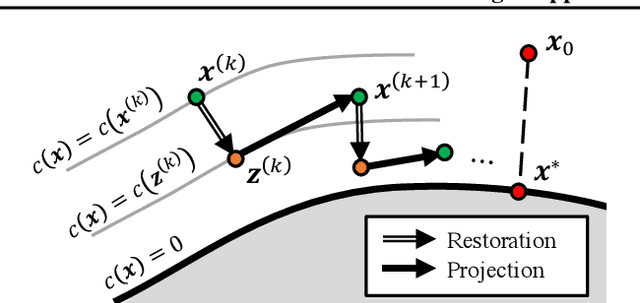

There are two major paradigms of white-box adversarial attacks that attempt to impose input perturbations. The first paradigm, called the fix-perturbation attack, crafts adversarial samples within a given perturbation level. The second paradigm, called the zero-confidence attack, finds the smallest perturbation needed to cause mis-classification, also known as the margin of an input feature. While the former paradigm is well-resolved, the latter is not. Existing zero-confidence attacks either introduce significant ap-proximation errors, or are too time-consuming. We therefore propose MARGINATTACK, a zero-confidence attack framework that is able to compute the margin with improved accuracy and efficiency. Our experiments show that MARGINATTACK is able to compute a smaller margin than the state-of-the-art zero-confidence attacks, and matches the state-of-the-art fix-perturbation at-tacks. In addition, it runs significantly faster than the Carlini-Wagner attack, currently the most ac-curate zero-confidence attack algorithm.