 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Backpropagation: A Memory Efficient Strategy for Training Video Models
Mar 31, 2022
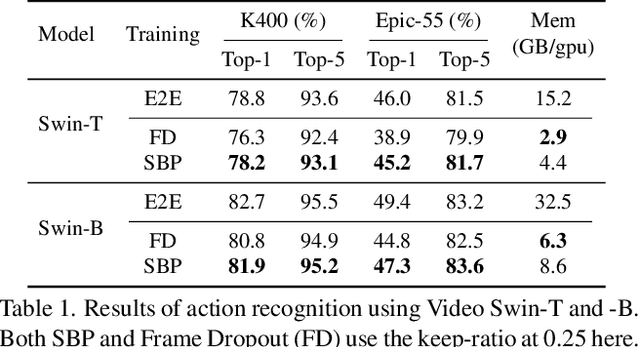
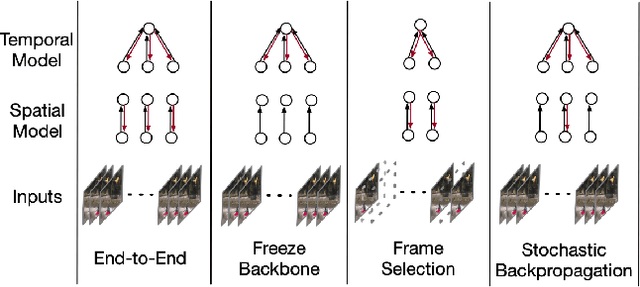
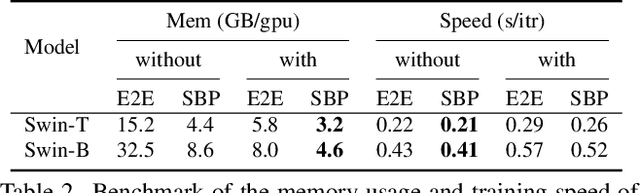
We propose a memory efficient method, named Stochastic Backpropagation (SBP), for training deep neural networks on videos. It is based on the finding that gradients from incomplete execution for backpropagation can still effectively train the models with minimal accuracy loss, which attributes to the high redundancy of video. SBP keeps all forward paths but randomly and independently removes the backward paths for each network layer in each training step. It reduces the GPU memory cost by eliminating the need to cache activation values corresponding to the dropped backward paths, whose amount can be controlled by an adjustable keep-ratio. Experiments show that SBP can be applied to a wide range of models for video tasks, leading to up to 80.0% GPU memory saving and 10% training speedup with less than 1% accuracy drop on action recognition and temporal action detection.
Long Short-Term Transformer for Online Action Detection
Jul 07, 2021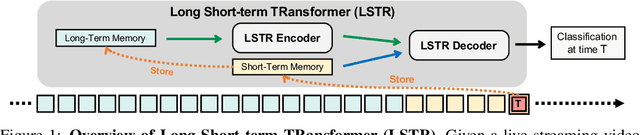
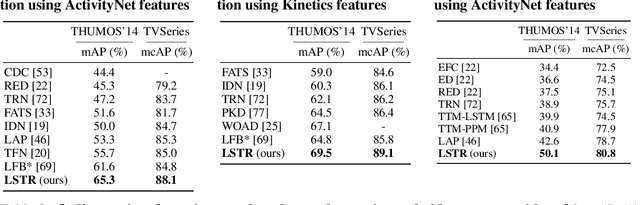
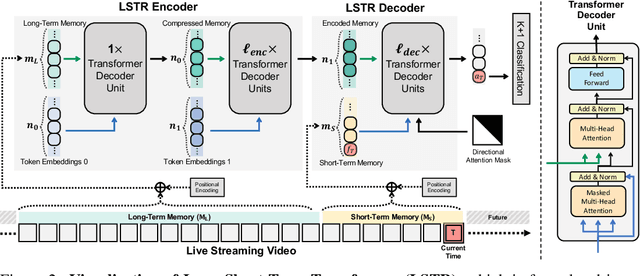
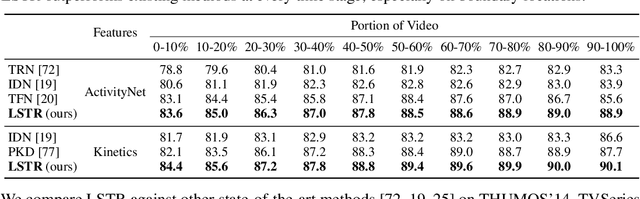
In this paper, we present Long Short-term TRansformer (LSTR), a new temporal modeling algorithm for online action detection, by employing a long- and short-term memories mechanism that is able to model prolonged sequence data. It consists of an LSTR encoder that is capable of dynamically exploiting coarse-scale historical information from an extensively long time window (e.g., 2048 long-range frames of up to 8 minutes), together with an LSTR decoder that focuses on a short time window (e.g., 32 short-range frames of 8 seconds) to model the fine-scale characterization of the ongoing event. Compared to prior work, LSTR provides an effective and efficient method to model long videos with less heuristic algorithm design. LSTR achieves significantly improved results on standard online action detection benchmarks, THUMOS'14, TVSeries, and HACS Segment, over the existing state-of-the-art approaches. Extensive empirical analysis validates the setup of the long- and short-term memories and the design choices of LSTR.
Semi-TCL: Semi-Supervised Track Contrastive Representation Learning
Jul 06, 2021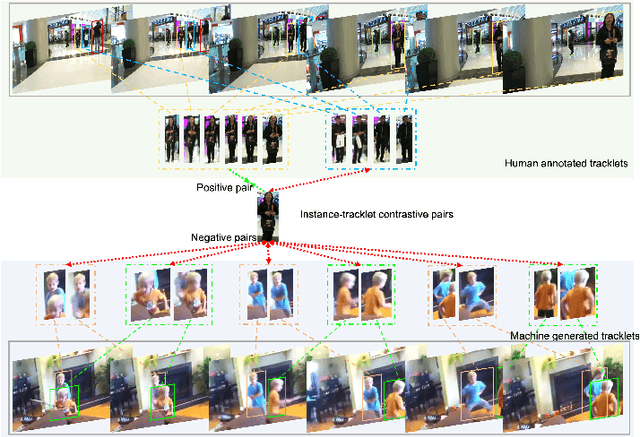

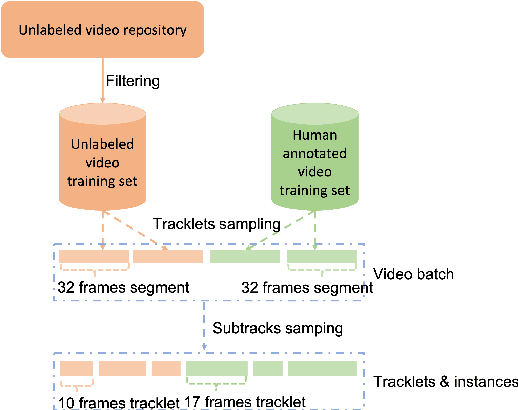

Online tracking of multiple objects in videos requires strong capacity of modeling and matching object appearances. Previous methods for learning appearance embedding mostly rely on instance-level matching without considering the temporal continuity provided by videos. We design a new instance-to-track matching objective to learn appearance embedding that compares a candidate detection to the embedding of the tracks persisted in the tracker. It enables us to learn not only from videos labeled with complete tracks, but also unlabeled or partially labeled videos. We implement this learning objective in a unified form following the spirit of constrastive loss. Experiments on multiple object tracking datasets demonstrate that our method can effectively learning discriminative appearance embeddings in a semi-supervised fashion and outperform state of the art methods on representative benchmarks.
Stepwise Goal-Driven Networks for Trajectory Prediction
Mar 25, 2021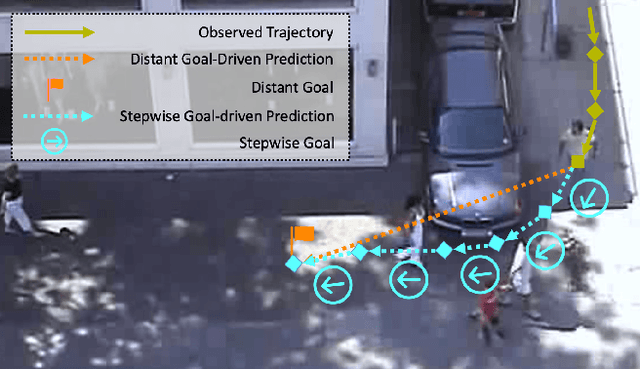
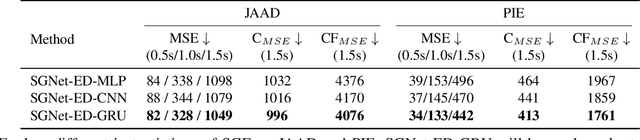
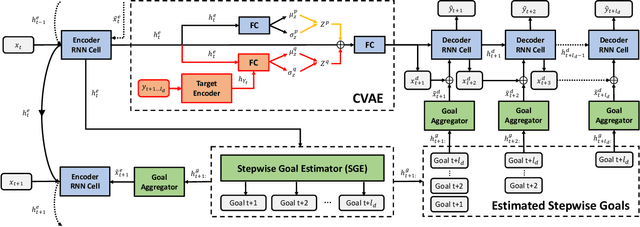
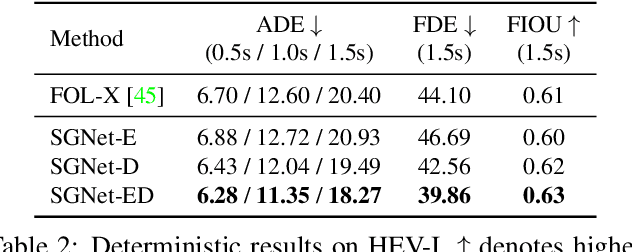
We propose to predict the future trajectories of observed agents (e.g., pedestrians or vehicles) by estimating and using their goals at multiple time scales. We argue that the goal of a moving agent may change over time, and modeling goals continuously provides more accurate and detailed information for future trajectory estimation. In this paper, we present a novel recurrent network for trajectory prediction, called Stepwise Goal-Driven Network (SGNet). Unlike prior work that models only a single, long-term goal, SGNet estimates and uses goals at multiple temporal scales. In particular, the framework incorporates an encoder module that captures historical information, a stepwise goal estimator that predicts successive goals into the future, and a decoder module that predicts future trajectory. We evaluate our model on three first-person traffic datasets (HEV-I, JAAD, and PIE) as well as on two bird's eye view datasets (ETH and UCY), and show that our model outperforms the state-of-the-art methods in terms of both average and final displacement errors on all datasets. Code has been made available at: https://github.com/ChuhuaW/SGNet.pytorch.
Learning to Recognize Patch-Wise Consistency for Deepfake Detection
Dec 16, 2020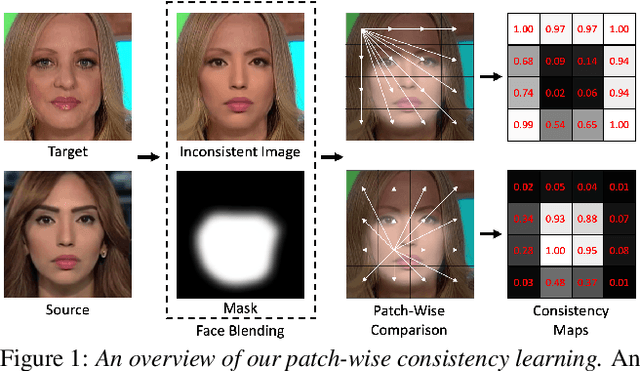

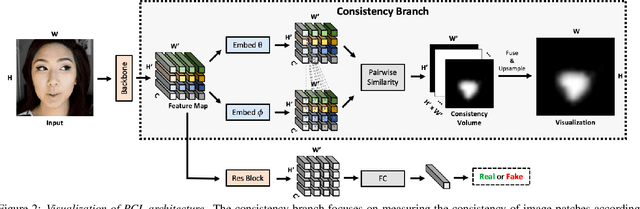
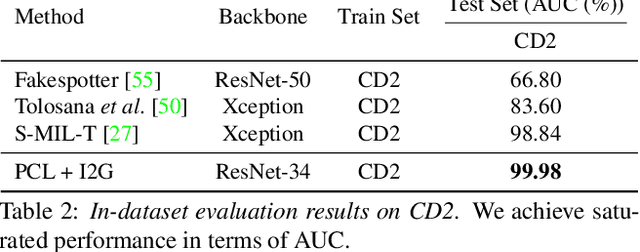
We propose to detect Deepfake generated by face manipulation based on one of their fundamental features: images are blended by patches from multiple sources, carrying distinct and persistent source features. In particular, we propose a novel representation learning approach for this task, called patch-wise consistency learning (PCL). It learns by measuring the consistency of image source features, resulting to representation with good interpretability and robustness to multiple forgery methods. We develop an inconsistency image generator (I2G) to generate training data for PCL and boost its robustness. We evaluate our approach on seven popular Deepfake detection datasets. Our model achieves superior detection accuracy and generalizes well to unseen generation methods. On average, our model outperforms the state-of-the-art in terms of AUC by 2% and 8% in the in- and cross-dataset evaluation, respectively.
Deep Tiered Image Segmentation forDetecting Internal Ice Layers in Radar Imagery
Oct 08, 2020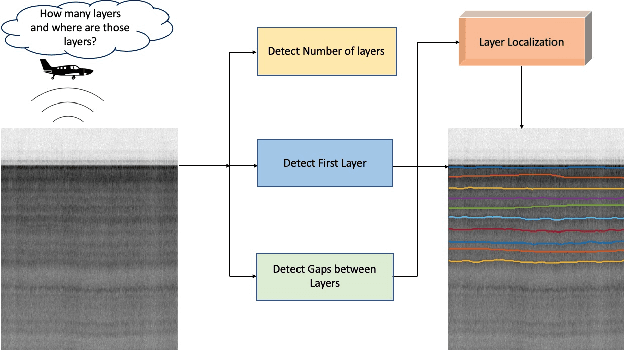

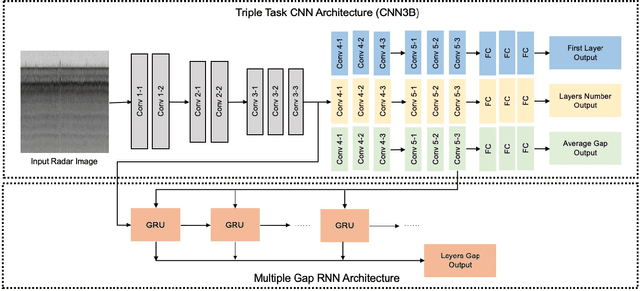
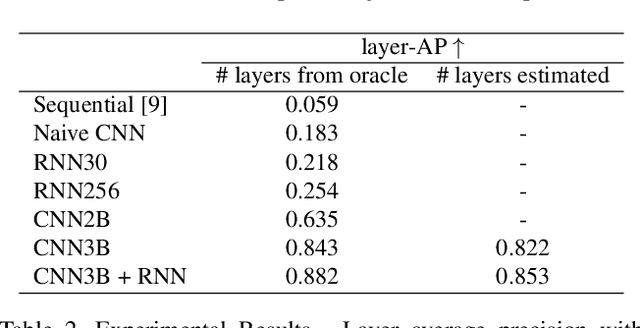
Understanding the structure of the ice at the Earth's poles is important for modeling how global warming will impact polar ice and, in turn, the Earth's climate. Ground-penetrating radar is able to collect observations of the internal structure of snow and ice, but the process of manually labeling these observations with layer boundaries is slow and laborious. Recent work has developed automatic techniques for finding ice-bed boundaries, but finding internal boundaries is much more challenging because the number of layers is unknown and the layers can disappear, reappear, merge, and split. In this paper, we propose a novel deep neural network-based model for solving a general class of tiered segmentation problems. We then apply it to detecting internal layers in polar ice, and evaluate on a large-scale dataset of polar ice radar data with human-labeled annotations as ground truth.
When, Where, and What? A New Dataset for Anomaly Detection in Driving Videos
Apr 06, 2020

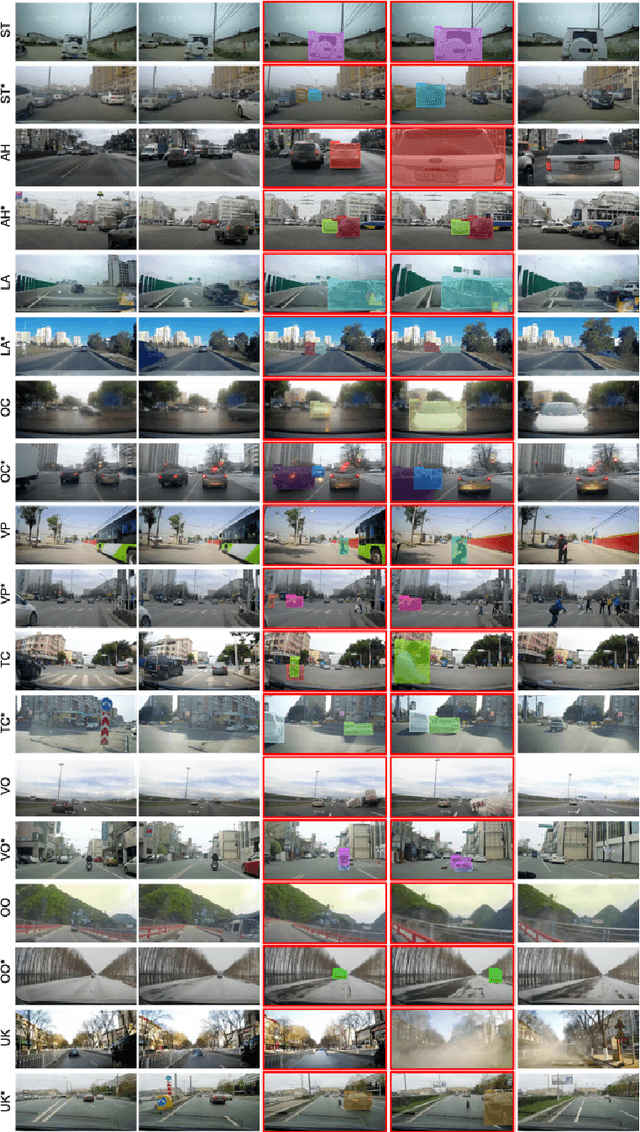
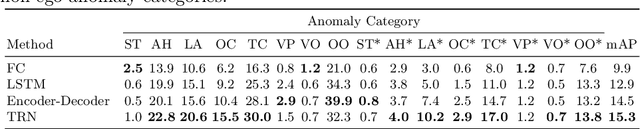
Video anomaly detection (VAD) has been extensively studied. However, research on egocentric traffic videos with dynamic scenes lacks large-scale benchmark datasets as well as effective evaluation metrics. This paper proposes traffic anomaly detection with a \textit{when-where-what} pipeline to detect, localize, and recognize anomalous events from egocentric videos. We introduce a new dataset called Detection of Traffic Anomaly (DoTA) containing 4,677 videos with temporal, spatial, and categorical annotations. A new spatial-temporal area under curve (STAUC) evaluation metric is proposed and used with DoTA. State-of-the-art methods are benchmarked for two VAD-related tasks.Experimental results show STAUC is an effective VAD metric. To our knowledge, DoTA is the largest traffic anomaly dataset to-date and is the first supporting traffic anomaly studies across when-where-what perspectives. Our code and dataset can be found in: https://github.com/MoonBlvd/Detection-of-Traffic-Anomaly
Embodied Visual Recognition
Apr 09, 2019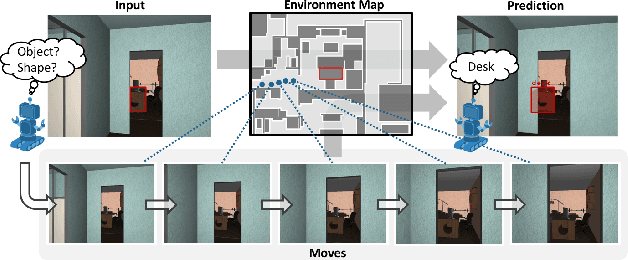
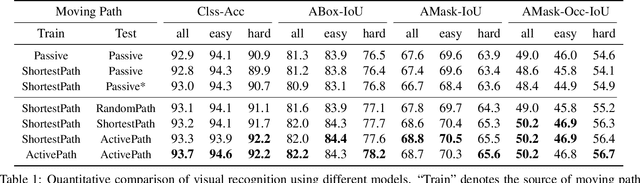
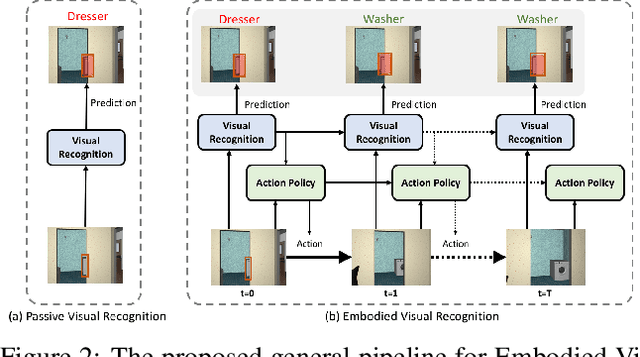
Passive visual systems typically fail to recognize objects in the amodal setting where they are heavily occluded. In contrast, humans and other embodied agents have the ability to move in the environment, and actively control the viewing angle to better understand object shapes and semantics. In this work, we introduce the task of Embodied Visual Recognition (EVR): An agent is instantiated in a 3D environment close to an occluded target object, and is free to move in the environment to perform object classification, amodal object localization, and amodal object segmentation. To address this, we develop a new model called Embodied Mask R-CNN, for agents to learn to move strategically to improve their visual recognition abilities. We conduct experiments using the House3D environment. Experimental results show that: 1) agents with embodiment (movement) achieve better visual recognition performance than passive ones; 2) in order to improve visual recognition abilities, agents can learn strategical moving paths that are different from shortest paths.
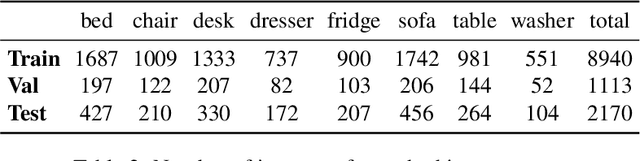
StartNet: Online Detection of Action Start in Untrimmed Videos
Mar 23, 2019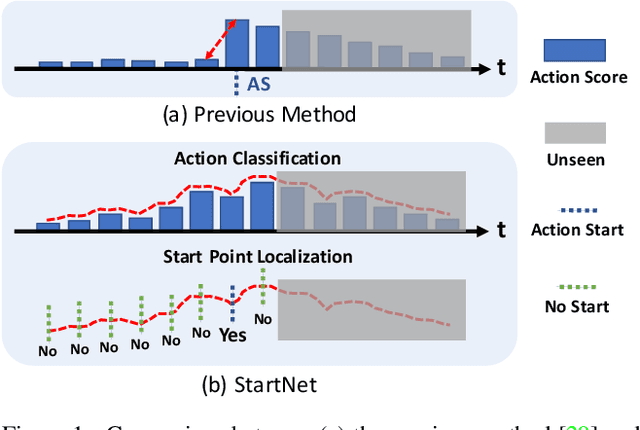
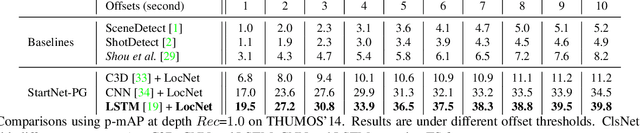
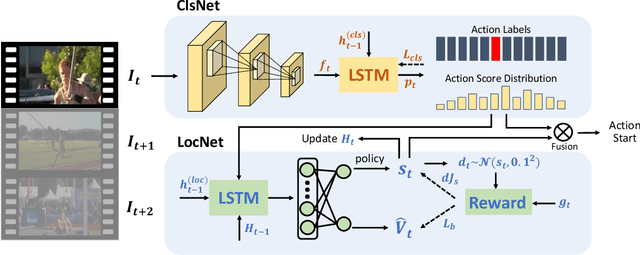

We propose StartNet to address Online Detection of Action Start (ODAS) where action starts and their associated categories are detected in untrimmed, streaming videos. Previous methods aim to localize action starts by learning feature representations that can directly separate the start point from its preceding background. It is challenging due to the subtle appearance difference near the action starts and the lack of training data. Instead, StartNet decomposes ODAS into two stages: action classification (using ClsNet) and start point localization (using LocNet). ClsNet focuses on per-frame labeling and predicts action score distributions online. Based on the predicted action scores of the past and current frames, LocNet conducts class-agnostic start detection by optimizing long-term localization rewards using policy gradient methods. The proposed framework is validated on two large-scale datasets, THUMOS'14 and ActivityNet. The experimental results show that StartNet significantly outperforms the state-of-the-art by 15%-30% p-mAP under the offset tolerance of 1-10 seconds on THUMOS'14, and achieves comparable performance on ActivityNet with 10 times smaller time offset.
Egocentric Vision-based Future Vehicle Localization for Intelligent Driving Assistance Systems
Mar 03, 2019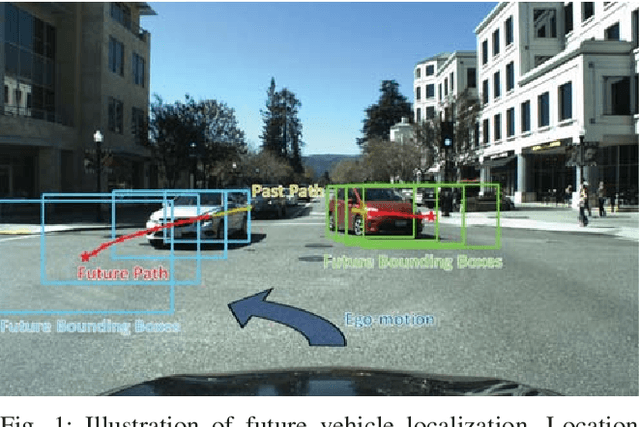
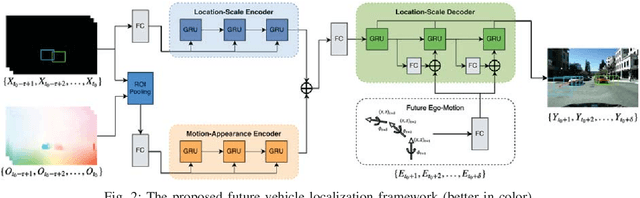
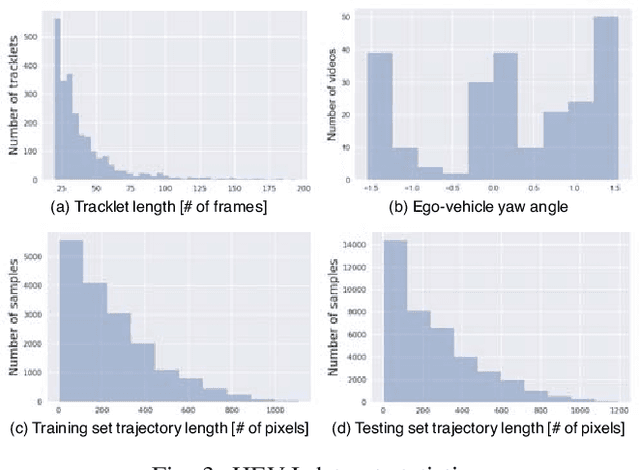

Predicting the future location of vehicles is essential for safety-critical applications such as advanced driver assistance systems (ADAS) and autonomous driving. This paper introduces a novel approach to simultaneously predict both the location and scale of target vehicles in the first-person (egocentric) view of an ego-vehicle. We present a multi-stream recurrent neural network (RNN) encoder-decoder model that separately captures both object location and scale and pixel-level observations for future vehicle localization. We show that incorporating dense optical flow improves prediction results significantly since it captures information about motion as well as appearance change. We also find that explicitly modeling future motion of the ego-vehicle improves the prediction accuracy, which could be especially beneficial in intelligent and automated vehicles that have motion planning capability. To evaluate the performance of our approach, we present a new dataset of first-person videos collected from a variety of scenarios at road intersections, which are particularly challenging moments for prediction because vehicle trajectories are diverse and dynamic.