 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwinWeaver: An LLM-Based Foundation Model Framework for Pan-Cancer Digital Twins
Jan 28, 2026Precision oncology requires forecasting clinical events and trajectories, yet modeling sparse, multi-modal clinical time series remains a critical challenge. We introduce TwinWeaver, an open-source framework that serializes longitudinal patient histories into text, enabling unified event prediction as well as forecasting with large language models, and use it to build Genie Digital Twin (GDT) on 93,054 patients across 20 cancer types. In benchmarks, GDT significantly reduces forecasting error, achieving a median Mean Absolute Scaled Error (MASE) of 0.87 compared to 0.97 for the strongest time-series baseline (p<0.001). Furthermore, GDT improves risk stratification, achieving an average concordance index (C-index) of 0.703 across survival, progression, and therapy switching tasks, surpassing the best baseline of 0.662. GDT also generalizes to out-of-distribution clinical trials, matching trained baselines at zero-shot and surpassing them with fine-tuning, achieving a median MASE of 0.75-0.88 and outperforming the strongest baseline in event prediction with an average C-index of 0.672 versus 0.648. Finally, TwinWeaver enables an interpretable clinical reasoning extension, providing a scalable and transparent foundation for longitudinal clinical modeling.
BioVerge: A Comprehensive Benchmark and Study of Self-Evaluating Agents for Biomedical Hypothesis Generation
Nov 12, 2025Hypothesis generation in biomedical research has traditionally centered on uncovering hidden relationships within vast scientific literature, often using methods like Literature-Based Discovery (LBD). Despite progress, current approaches typically depend on single data types or predefined extraction patterns, which restricts the discovery of novel and complex connections. Recent advances in Large Language Model (LLM) agents show significant potential, with capabilities in information retrieval, reasoning, and generation. However, their application to biomedical hypothesis generation has been limited by the absence of standardized datasets and execution environments. To address this, we introduce BioVerge, a comprehensive benchmark, and BioVerge Agent, an LLM-based agent framework, to create a standardized environment for exploring biomedical hypothesis generation at the frontier of existing scientific knowledge. Our dataset includes structured and textual data derived from historical biomedical hypotheses and PubMed literature, organized to support exploration by LLM agents. BioVerge Agent utilizes a ReAct-based approach with distinct Generation and Evaluation modules that iteratively produce and self-assess hypothesis proposals. Through extensive experimentation, we uncover key insights: 1) different architectures of BioVerge Agent influence exploration diversity and reasoning strategies; 2) structured and textual information sources each provide unique, critical contexts that enhance hypothesis generation; and 3) self-evaluation significantly improves the novelty and relevance of proposed hypotheses.
iSeal: Encrypted Fingerprinting for Reliable LLM Ownership Verification
Nov 12, 2025Given the high cost of large language model (LLM) training from scratch, safeguarding LLM intellectual property (IP) has become increasingly crucial. As the standard paradigm for IP ownership verification, LLM fingerprinting thus plays a vital role in addressing this challenge. Existing LLM fingerprinting methods verify ownership by extracting or injecting model-specific features. However, they overlook potential attacks during the verification process, leaving them ineffective when the model thief fully controls the LLM's inference process. In such settings, attackers may share prompt-response pairs to enable fingerprint unlearning or manipulate outputs to evade exact-match verification. We propose iSeal, the first fingerprinting method designed for reliable verification when the model thief controls the suspected LLM in an end-to-end manner. It injects unique features into both the model and an external module, reinforced by an error-correction mechanism and a similarity-based verification strategy. These components are resistant to verification-time attacks, including collusion-based fingerprint unlearning and response manipulation, backed by both theoretical analysis and empirical results. iSeal achieves 100 percent Fingerprint Success Rate (FSR) on 12 LLMs against more than 10 attacks, while baselines fail under unlearning and response manipulations.
BIASINSPECTOR: Detecting Bias in Structured Data through LLM Agents
Apr 07, 2025Detecting biases in structured data is a complex and time-consuming task. Existing automated techniques are limited in diversity of data types and heavily reliant on human case-by-case handling, resulting in a lack of generalizability. Currently, large language model (LLM)-based agents have made significant progress in data science, but their ability to detect data biases is still insufficiently explored. To address this gap, we introduce the first end-to-end, multi-agent synergy framework, BIASINSPECTOR, designed for automatic bias detection in structured data based on specific user requirements. It first develops a multi-stage plan to analyze user-specified bias detection tasks and then implements it with a diverse and well-suited set of tools. It delivers detailed results that include explanations and visualizations. To address the lack of a standardized framework for evaluating the capability of LLM agents to detect biases in data, we further propose a comprehensive benchmark that includes multiple evaluation metrics and a large set of test cases. Extensive experiments demonstrate that our framework achieves exceptional overall performance in structured data bias detection, setting a new milestone for fairer data applications.
Entropy-Based Adaptive Weighting for Self-Training
Mar 31, 2025
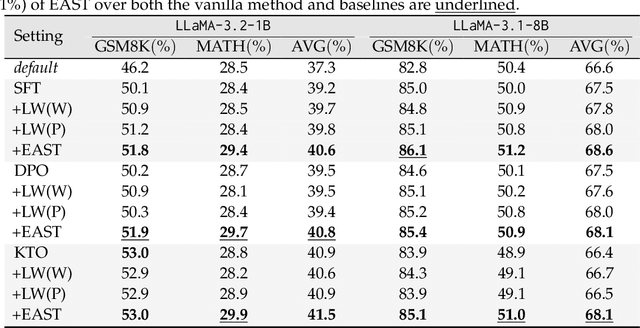
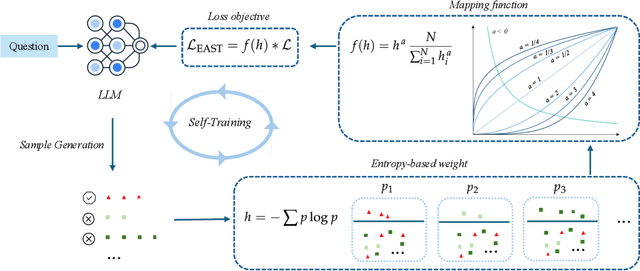

The mathematical problem-solving capabilities of large language models have become a focal point of research, with growing interests in leveraging self-generated reasoning paths as a promising way to refine and enhance these models. These paths capture step-by-step logical processes while requiring only the correct answer for supervision. The self-training method has been shown to be effective in reasoning tasks while eliminating the need for external models and manual annotations. However, optimizing the use of self-generated data for model training remains an open challenge. In this work, we propose Entropy-Based Adaptive Weighting for Self-Training (EAST), an adaptive weighting strategy designed to prioritize uncertain data during self-training. Specifically, EAST employs a mapping function with a tunable parameter that controls the sharpness of the weighting, assigning higher weights to data where the model exhibits greater uncertainty. This approach guides the model to focus on more informative and challenging examples, thereby enhancing its reasoning ability. We evaluate our approach on GSM8K and MATH benchmarks. Empirical results show that, while the vanilla method yields virtually no improvement (0%) on MATH, EAST achieves around a 1% gain over backbone model. On GSM8K, EAST attains a further 1-2% performance boost compared to the vanilla method.
Memorize and Rank: Elevating Large Language Models for Clinical Diagnosis Prediction
Jan 28, 2025Clinical diagnosis prediction models, when provided with a patient's medical history, aim to detect potential diseases early, facilitating timely intervention and improving prognostic outcomes. However, the inherent scarcity of patient data and large disease candidate space often pose challenges in developing satisfactory models for this intricate task. The exploration of leveraging Large Language Models (LLMs) for encapsulating clinical decision processes has been limited. We introduce MERA, a clinical diagnosis prediction model that bridges pertaining natural language knowledge with medical practice. We apply hierarchical contrastive learning on a disease candidate ranking list to alleviate the large decision space issue. With concept memorization through fine-tuning, we bridge the natural language clinical knowledge with medical codes. Experimental results on MIMIC-III and IV datasets show that MERA achieves the state-of-the-art diagnosis prediction performance and dramatically elevates the diagnosis prediction capabilities of generative LMs.
Inferring from Logits: Exploring Best Practices for Decoding-Free Generative Candidate Selection
Jan 28, 2025



Generative Language Models rely on autoregressive decoding to produce the output sequence token by token. Many tasks such as preference optimization, require the model to produce task-level output consisting of multiple tokens directly by selecting candidates from a pool as predictions. Determining a task-level prediction from candidates using the ordinary token-level decoding mechanism is constrained by time-consuming decoding and interrupted gradients by discrete token selection. Existing works have been using decoding-free candidate selection methods to obtain candidate probability from initial output logits over vocabulary. Though these estimation methods are widely used, they are not systematically evaluated, especially on end tasks. We introduce an evaluation of a comprehensive collection of decoding-free candidate selection approaches on a comprehensive set of tasks, including five multiple-choice QA tasks with a small candidate pool and four clinical decision tasks with a massive amount of candidates, some with 10k+ options. We evaluate the estimation methods paired with a wide spectrum of foundation LMs covering different architectures, sizes and training paradigms. The results and insights from our analysis inform the future model design.
MetaScientist: A Human-AI Synergistic Framework for Automated Mechanical Metamaterial Design
Dec 20, 2024



The discovery of novel mechanical metamaterials, whose properties are dominated by their engineered structures rather than chemical composition, is a knowledge-intensive and resource-demanding process. To accelerate the design of novel metamaterials, we present MetaScientist, a human-in-the-loop system that integrates advanced AI capabilities with expert oversight with two primary phases: (1) hypothesis generation, where the system performs complex reasoning to generate novel and scientifically sound hypotheses, supported with domain-specific foundation models and inductive biases retrieved from existing literature; (2) 3D structure synthesis, where a 3D structure is synthesized with a novel 3D diffusion model based on the textual hypothesis and refined it with a LLM-based refinement model to achieve better structure properties. At each phase, domain experts iteratively validate the system outputs, and provide feedback and supplementary materials to ensure the alignment of the outputs with scientific principles and human preferences. Through extensive evaluation from human scientists, MetaScientist is able to deliver novel and valid mechanical metamaterial designs that have the potential to be highly impactful in the metamaterial field.
Are Large-Language Models Graph Algorithmic Reasoners?
Oct 29, 2024



We seek to address a core challenge facing current Large Language Models (LLMs). LLMs have demonstrated superior performance in many tasks, yet continue to struggle with reasoning problems on explicit graphs that require multiple steps. To address this gap, we introduce a novel benchmark designed to evaluate LLM performance on classical algorithmic reasoning tasks on explicit graphs. Our benchmark encompasses five fundamental algorithms: Breadth-First Search (BFS) and Depth-First Search (DFS) for connectivity, Dijkstra's algorithm and Floyd-Warshall algorithm for all nodes shortest path, and Prim's Minimum Spanning Tree (MST-Prim's) algorithm. Through extensive experimentation, we assess the capabilities of state-of-the-art LLMs in executing these algorithms step-by-step and systematically evaluate their performance at each stage. Our findings highlight the persistent challenges LLMs face in this domain and underscore the necessity for advanced prompting techniques and algorithmic instruction to enhance their graph reasoning abilities. This work presents MAGMA, the first comprehensive benchmark focused on LLMs completing classical graph algorithms, and provides a critical step toward understanding and improving their structured problem-solving skills.
GIVE: Structured Reasoning with Knowledge Graph Inspired Veracity Extrapolation
Oct 11, 2024



Existing retrieval-based reasoning approaches for large language models (LLMs) heavily rely on the density and quality of the non-parametric knowledge source to provide domain knowledge and explicit reasoning chain. However, inclusive knowledge sources are expensive and sometimes infeasible to build for scientific or corner domains. To tackle the challenges, we introduce Graph Inspired Veracity Extrapolation (GIVE), a novel reasoning framework that integrates the parametric and non-parametric memories to enhance both knowledge retrieval and faithful reasoning processes on very sparse knowledge graphs. By leveraging the external structured knowledge to inspire LLM to model the interconnections among relevant concepts, our method facilitates a more logical and step-wise reasoning approach akin to experts' problem-solving, rather than gold answer retrieval. Specifically, the framework prompts LLMs to decompose the query into crucial concepts and attributes, construct entity groups with relevant entities, and build an augmented reasoning chain by probing potential relationships among node pairs across these entity groups. Our method incorporates both factual and extrapolated linkages to enable comprehensive understanding and response generation. Extensive experiments on reasoning-intense benchmarks on biomedical and commonsense QA demonstrate the effectiveness of our proposed method. Specifically, GIVE enables GPT3.5-turbo to outperform advanced models like GPT4 without any additional training cost, thereby underscoring the efficacy of integrating structured information and internal reasoning ability of LLMs for tackling specialized tasks with limited external resources.