 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Volctrans GLAT System: Non-autoregressive Translation Meets WMT21
Sep 24, 2021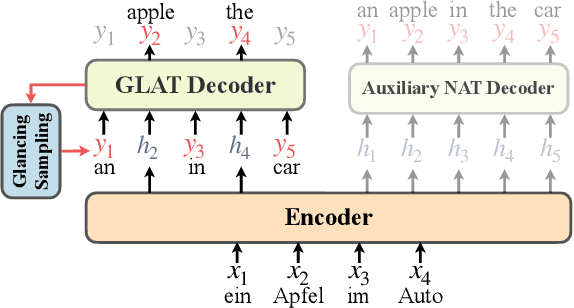
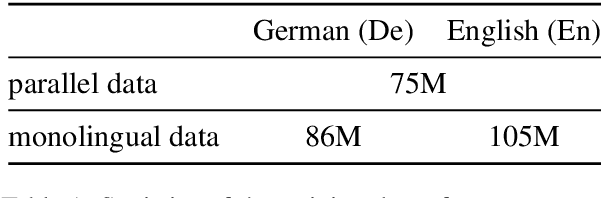
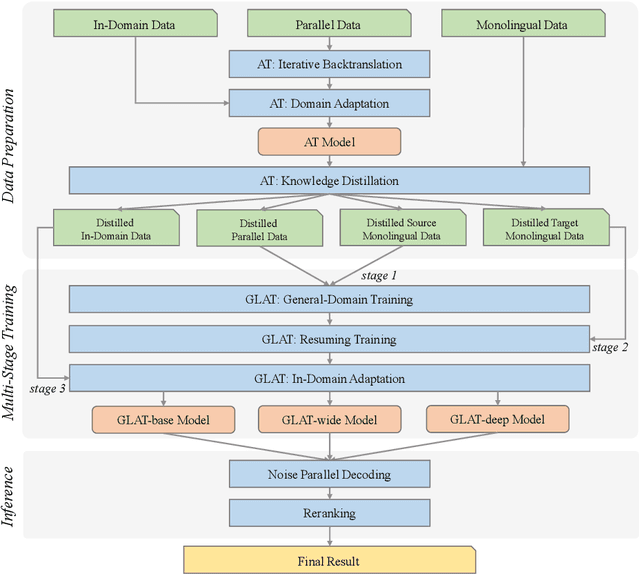
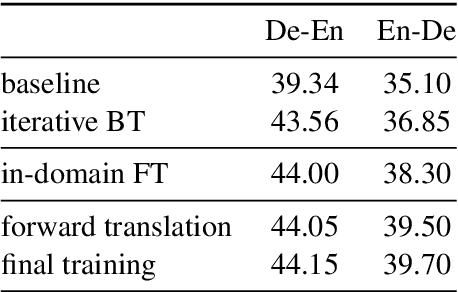
This paper describes the Volctrans' submission to the WMT21 news translation shared task for German->English translation. We build a parallel (i.e., non-autoregressive) translation system using the Glancing Transformer, which enables fast and accurate parallel decoding in contrast to the currently prevailing autoregressive models. To the best of our knowledge, this is the first parallel translation system that can be scaled to such a practical scenario like WMT competition. More importantly, our parallel translation system achieves the best BLEU score (35.0) on German->English translation task, outperforming all strong autoregressive counterparts.
Learning Kernel-Smoothed Machine Translation with Retrieved Examples
Sep 21, 2021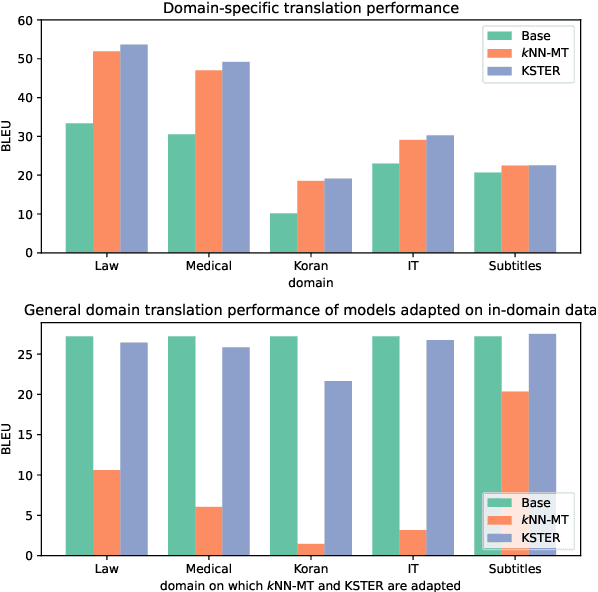
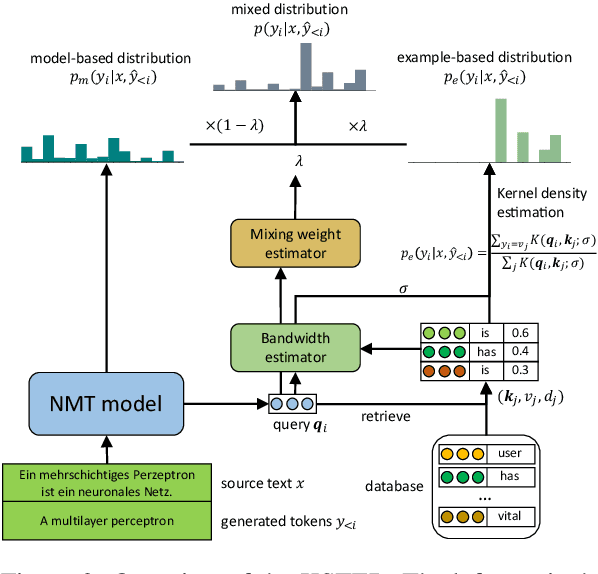

How to effectively adapt neural machine translation (NMT) models according to emerging cases without retraining? Despite the great success of neural machine translation, updating the deployed models online remains a challenge. Existing non-parametric approaches that retrieve similar examples from a database to guide the translation process are promising but are prone to overfit the retrieved examples. However, non-parametric methods are prone to overfit the retrieved examples. In this work, we propose to learn Kernel-Smoothed Translation with Example Retrieval (KSTER), an effective approach to adapt neural machine translation models online. Experiments on domain adaptation and multi-domain machine translation datasets show that even without expensive retraining, KSTER is able to achieve improvement of 1.1 to 1.5 BLEU scores over the best existing online adaptation methods. The code and trained models are released at https://github.com/jiangqn/KSTER.
UniST: Unified End-to-end Model for Streaming and Non-streaming Speech Translation
Sep 15, 2021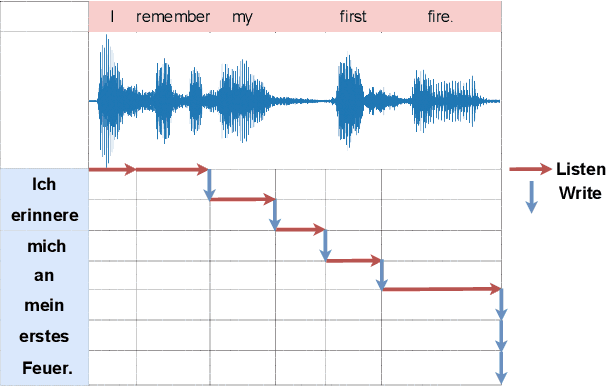

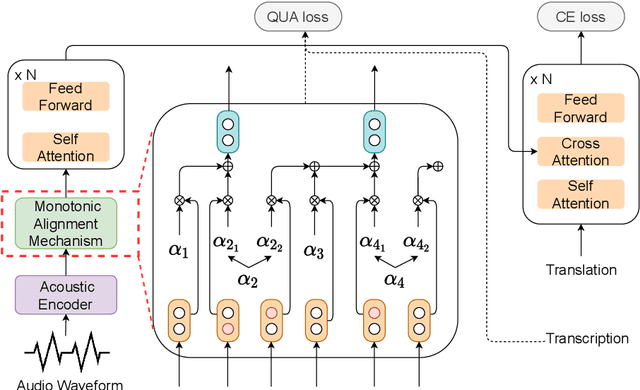

This paper presents a unified end-to-end frame-work for both streaming and non-streamingspeech translation. While the training recipes for non-streaming speech translation have been mature, the recipes for streaming speechtranslation are yet to be built. In this work, wefocus on developing a unified model (UniST) which supports streaming and non-streaming ST from the perspective of fundamental components, including training objective, attention mechanism and decoding policy. Experiments on the most popular speech-to-text translation benchmark dataset, MuST-C, show that UniST achieves significant improvement for non-streaming ST, and a better-learned trade-off for BLEU score and latency metrics for streaming ST, compared with end-to-end baselines and the cascaded models. We will make our codes and evaluation tools publicly available.
Multilingual Translation via Grafting Pre-trained Language Models
Sep 11, 2021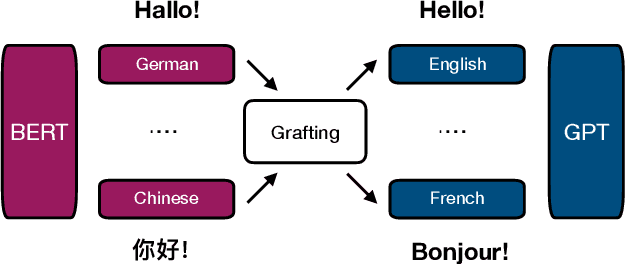
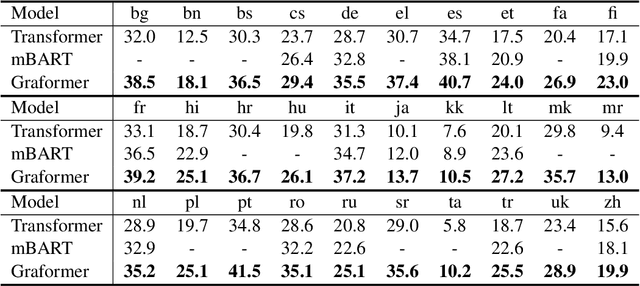
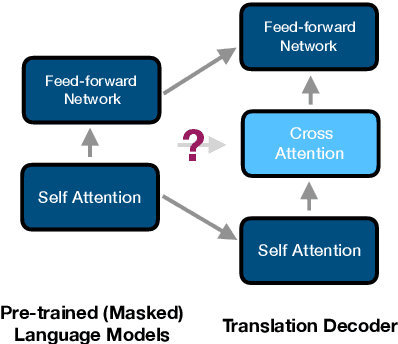
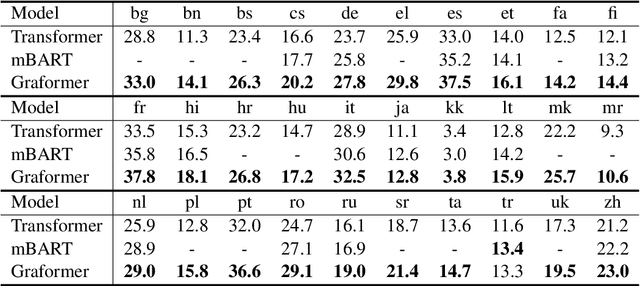
Can pre-trained BERT for one language and GPT for another be glued together to translate texts? Self-supervised training using only monolingual data has led to the success of pre-trained (masked) language models in many NLP tasks. However, directly connecting BERT as an encoder and GPT as a decoder can be challenging in machine translation, for GPT-like models lack a cross-attention component that is needed in seq2seq decoders. In this paper, we propose Graformer to graft separately pre-trained (masked) language models for machine translation. With monolingual data for pre-training and parallel data for grafting training, we maximally take advantage of the usage of both types of data. Experiments on 60 directions show that our method achieves average improvements of 5.8 BLEU in x2en and 2.9 BLEU in en2x directions comparing with the multilingual Transformer of the same size.
Secoco: Self-Correcting Encoding for Neural Machine Translation
Aug 27, 2021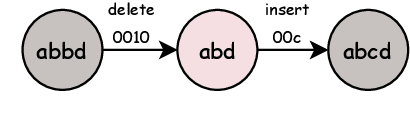
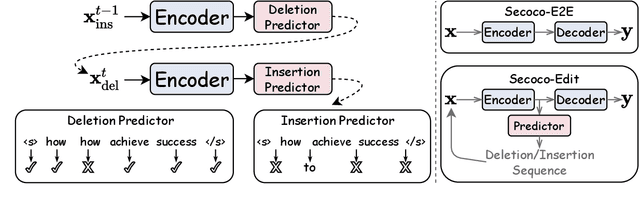
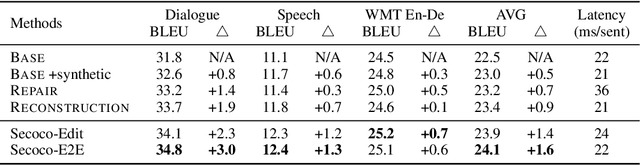
This paper presents Self-correcting Encoding (Secoco), a framework that effectively deals with input noise for robust neural machine translation by introducing self-correcting predictors. Different from previous robust approaches, Secoco enables NMT to explicitly correct noisy inputs and delete specific errors simultaneously with the translation decoding process. Secoco is able to achieve significant improvements over strong baselines on two real-world test sets and a benchmark WMT dataset with good interpretability. We will make our code and dataset publicly available soon.
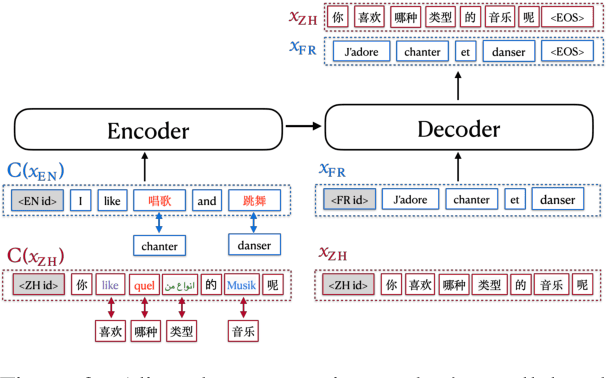
Language Tags Matter for Zero-Shot Neural Machine Translation
Jun 15, 2021
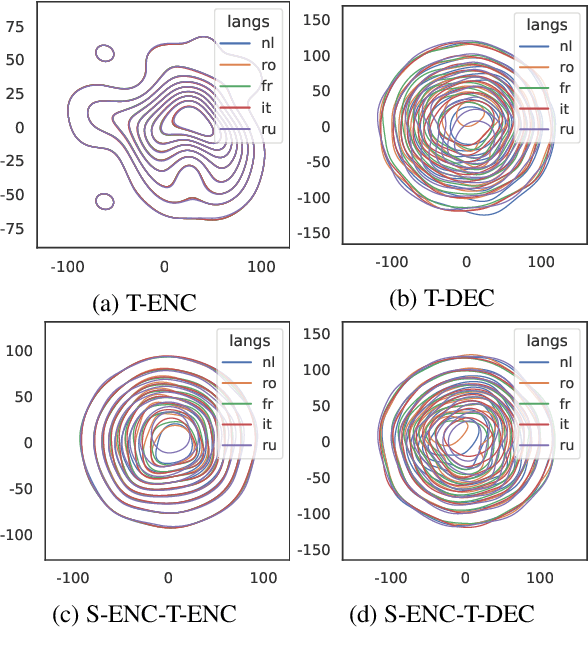
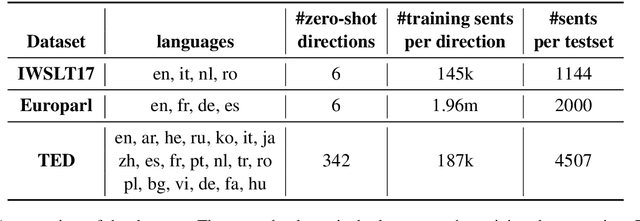
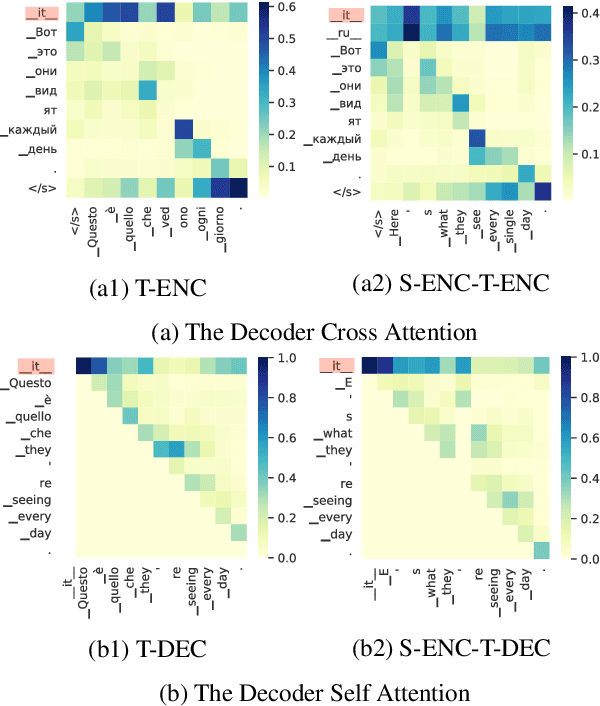
Multilingual Neural Machine Translation (MNMT) has aroused widespread interest due to its efficiency. An exciting advantage of MNMT models is that they could also translate between unsupervised (zero-shot) language directions. Language tag (LT) strategies are often adopted to indicate the translation directions in MNMT. In this paper, we demonstrate that the LTs are not only indicators for translation directions but also crucial to zero-shot translation qualities. Unfortunately, previous work tends to ignore the importance of LT strategies. We demonstrate that a proper LT strategy could enhance the consistency of semantic representations and alleviate the off-target issue in zero-shot directions. Experimental results show that by ignoring the source language tag (SLT) and adding the target language tag (TLT) to the encoder, the zero-shot translations could achieve a +8 BLEU score difference over other LT strategies in IWSLT17, Europarl, TED talks translation tasks.
Contrastive Learning for Many-to-many Multilingual Neural Machine Translation
Jun 09, 2021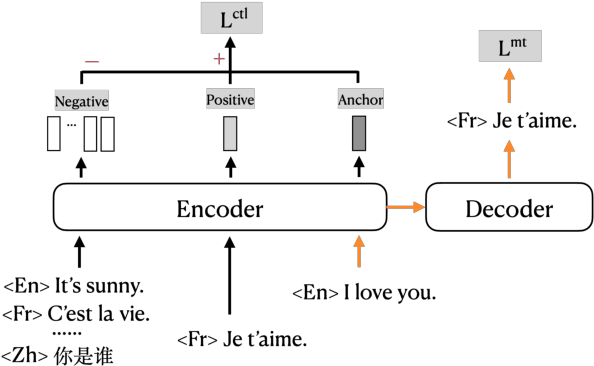
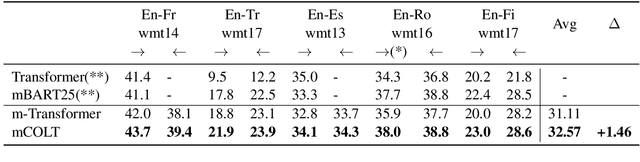

Existing multilingual machine translation approaches mainly focus on English-centric directions, while the non-English directions still lag behind. In this work, we aim to build a many-to-many translation system with an emphasis on the quality of non-English language directions. Our intuition is based on the hypothesis that a universal cross-language representation leads to better multilingual translation performance. To this end, we propose mRASP2, a training method to obtain a single unified multilingual translation model. mRASP2 is empowered by two techniques: a) a contrastive learning scheme to close the gap among representations of different languages, and b) data augmentation on both multiple parallel and monolingual data to further align token representations. For English-centric directions, mRASP2 outperforms existing best unified model and achieves competitive or even better performance than the pre-trained and fine-tuned model mBART on tens of WMT's translation directions. For non-English directions, mRASP2 achieves an improvement of average 10+ BLEU compared with the multilingual Transformer baseline. Code, data and trained models are available at https://github.com/PANXiao1994/mRASP2.
Learning Shared Semantic Space for Speech-to-Text Translation
Jun 03, 2021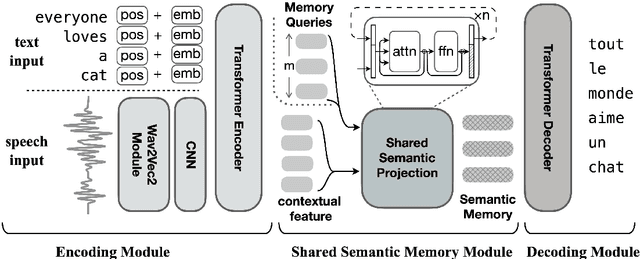
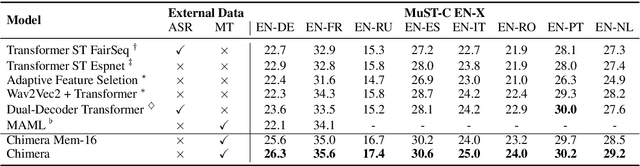
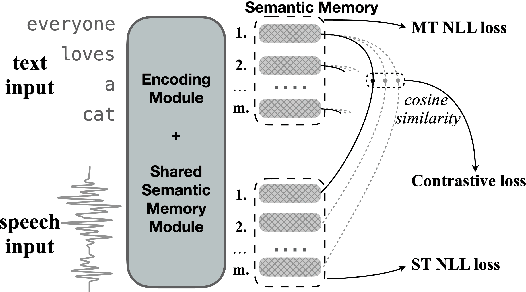
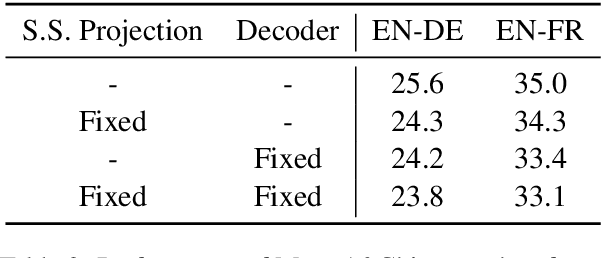
Having numerous potential applications and great impact, end-to-end speech translation (ST) has long been treated as an independent task, failing to fully draw strength from the rapid advances of its sibling - text machine translation (MT). With text and audio inputs represented differently, the modality gap has rendered MT data and its end-to-end models incompatible with their ST counterparts. In observation of this obstacle, we propose to bridge this representation gap with Chimera. By projecting audio and text features to a common semantic representation, Chimera unifies MT and ST tasks and boosts the performance on ST benchmarks, MuST-C and Augmented Librispeech, to a new state-of-the-art. Specifically, Chimera obtains 27.1 BLEU on MuST-C EN-DE, improving the SOTA by a +1.9 BLEU margin. Further experimental analyses demonstrate that the shared semantic space indeed conveys common knowledge between these two tasks and thus paves a new way for augmenting training resources across modalities. Code, data, and resources are available at https://github.com/Glaciohound/Chimera-ST.
Learning Language Specific Sub-network for Multilingual Machine Translation
May 19, 2021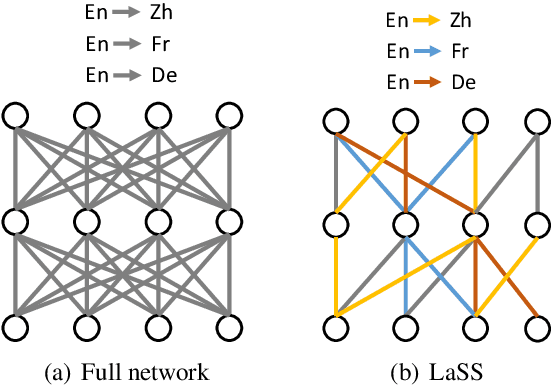
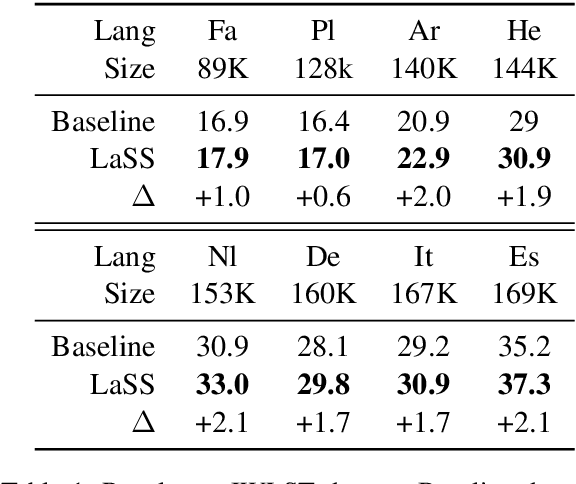
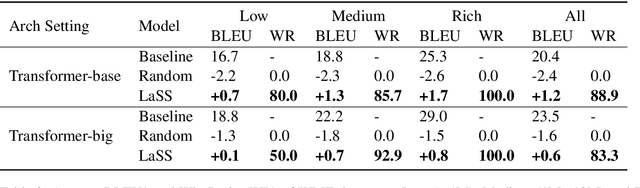
Multilingual neural machine translation aims at learning a single translation model for multiple languages. These jointly trained models often suffer from performance degradation on rich-resource language pairs. We attribute this degeneration to parameter interference. In this paper, we propose LaSS to jointly train a single unified multilingual MT model. LaSS learns Language Specific Sub-network (LaSS) for each language pair to counter parameter interference. Comprehensive experiments on IWSLT and WMT datasets with various Transformer architectures show that LaSS obtains gains on 36 language pairs by up to 1.2 BLEU. Besides, LaSS shows its strong generalization performance at easy extension to new language pairs and zero-shot translation.LaSS boosts zero-shot translation with an average of 8.3 BLEU on 30 language pairs. Codes and trained models are available at https://github.com/NLP-Playground/LaSS.
The Volctrans Neural Speech Translation System for IWSLT 2021
May 16, 2021
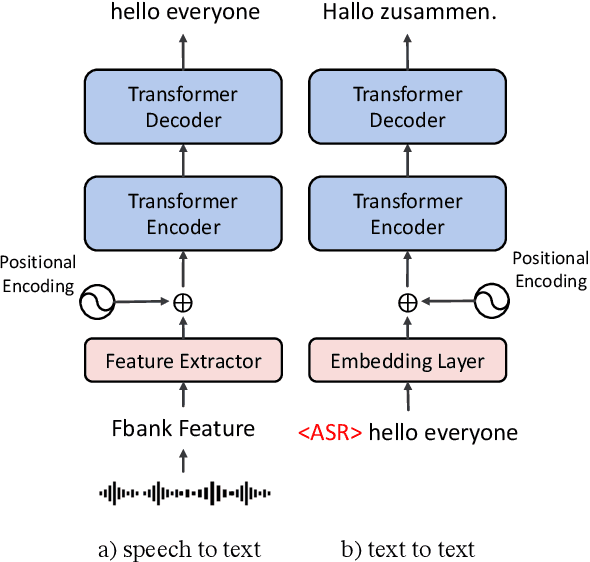
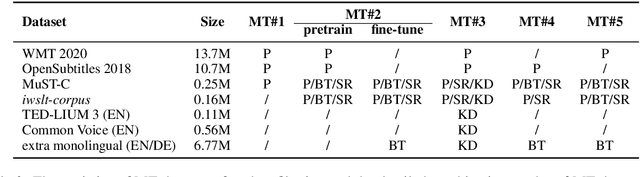
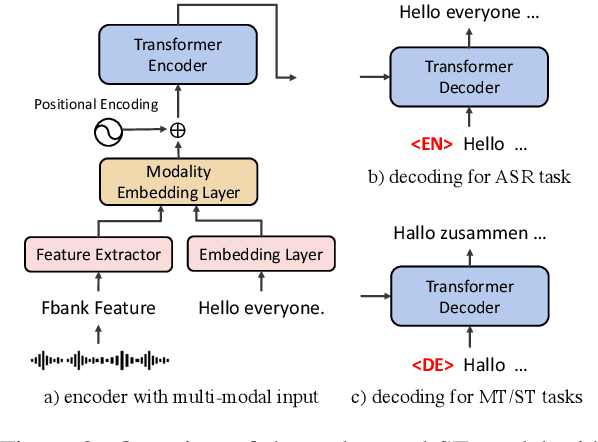
This paper describes the systems submitted to IWSLT 2021 by the Volctrans team. We participate in the offline speech translation and text-to-text simultaneous translation tracks. For offline speech translation, our best end-to-end model achieves 8.1 BLEU improvements over the benchmark on the MuST-C test set and is even approaching the results of a strong cascade solution. For text-to-text simultaneous translation, we explore the best practice to optimize the wait-k model. As a result, our final submitted systems exceed the benchmark at around 7 BLEU on the same latency regime. We will publish our code and model to facilitate both future research works and industrial applications.