 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Useful is Causal Invariance for Domain Adaptation in Finite-Sample Settings?
Jun 10, 2026Machine learning models often degrade when they are deployed on a target distribution that differs from the source distributions they were trained on. Recent work in causality-based domain generalization has shown how shared causal structure between domains can induce invariant predictors, e.g., models on a subset of features which have stable risk across structured domain shifts. However, the extent to which such population-level causal invariances can lead to gains in finite-sample settings remains underexplored. In particular, in practice we often have access to a few labeled target samples, a setting called supervised domain adaptation (sDA). In this paper, we explore when (full or partial) causal knowledge can provably improve supervised domain adaptation. As a first step, we study linear regression, where full or partial causal knowledge specifies a collection of invariant or possibly invariant feature subsets, each yielding a source-trained candidate predictor. We derive matching upper and lower bounds showing that finite-sample gains are governed by the target-risk margins separating the candidates, together with the finite-source estimation error. When these margins are sufficiently large relative to $n_Q$, an adaptive aggregation procedure can match the best candidate predictor while avoiding negative transfer relative to target-only learning. On the other hand, when the margins are too small, no algorithm can reliably exploit the candidate collection to obtain faster finite-sample rates. We further connect these margins to structural shift magnitude in linear SCMs and validate the theory on real-world causal benchmarks.
Confounder Detection via Treatment Intent: A New Observational Study Design
May 26, 2026Understanding the effects of interventions is central to scientific progress, with randomized controlled trials (RCTs) regarded as the gold standard for causal inference in many applied fields. However, RCTs are costly, time-consuming, and often constrained by ethical or practical limitations, motivating the need for causal methods able to draw conclusions from observational data. While such data is collected at ever larger scale, making its use for causal inference is often hindered by the fact that not all variables affecting treatment allocation and the outcome are observed: an issue known as unobserved confounding. In this paper, we introduce a new study design called confounder detection via treatment intent. The idea is to query a human expert who makes treatment decisions, and ask them to compare pairs of units proposed by a principled matching strategy, with the goal of eliciting unobserved variables that explain why treatment decisions differ. We provide a theoretical basis for such a procedure, ascertaining conditions under which such a study design may elicit unobserved confounders. Building on this newly established foundations, we study treatment effects of interventions in the intensive care unit (ICU). First, we show empirical evidence strongly indicating that electronic health records (EHRs) collected in ICUs are subject to unobserved confounding. By using clinical text notes as a proxy for physicians' knowledge and leveraging natural language processing, we provide a proof of concept for our methodology in a semi-synthetic environment with a known ground truth.
Confounding Robust Continuous Control via Automatic Reward Shaping
Feb 10, 2026Reward shaping has been applied widely to accelerate Reinforcement Learning (RL) agents' training. However, a principled way of designing effective reward shaping functions, especially for complex continuous control problems, remains largely under-explained. In this work, we propose to automatically learn a reward shaping function for continuous control problems from offline datasets, potentially contaminated by unobserved confounding variables. Specifically, our method builds upon the recently proposed causal Bellman equation to learn a tight upper bound on the optimal state values, which is then used as the potentials in the Potential-Based Reward Shaping (PBRS) framework. Our proposed reward shaping algorithm is tested with Soft-Actor-Critic (SAC) on multiple commonly used continuous control benchmarks and exhibits strong performance guarantees under unobserved confounders. More broadly, our work marks a solid first step towards confounding robust continuous control from a causal perspective. Code for training our reward shaping functions can be found at https://github.com/mateojuliani/confounding_robust_cont_control.
Causal Flow Q-Learning for Robust Offline Reinforcement Learning
Feb 02, 2026Expressive policies based on flow-matching have been successfully applied in reinforcement learning (RL) more recently due to their ability to model complex action distributions from offline data. These algorithms build on standard policy gradients, which assume that there is no unmeasured confounding in the data. However, this condition does not necessarily hold for pixel-based demonstrations when a mismatch exists between the demonstrator's and the learner's sensory capabilities, leading to implicit confounding biases in offline data. We address the challenge by investigating the problem of confounded observations in offline RL from a causal perspective. We develop a novel causal offline RL objective that optimizes policies' worst-case performance that may arise due to confounding biases. Based on this new objective, we introduce a practical implementation that learns expressive flow-matching policies from confounded demonstrations, employing a deep discriminator to assess the discrepancy between the target policy and the nominal behavioral policy. Experiments across 25 pixel-based tasks demonstrate that our proposed confounding-robust augmentation procedure achieves a success rate 120\% that of confounding-unaware, state-of-the-art offline RL methods.
Adapting, Fast and Slow: Transportable Circuits for Few-Shot Learning
Dec 28, 2025Generalization across the domains is not possible without asserting a structure that constrains the unseen target domain w.r.t. the source domain. Building on causal transportability theory, we design an algorithm for zero-shot compositional generalization which relies on access to qualitative domain knowledge in form of a causal graph for intra-domain structure and discrepancies oracle for inter-domain mechanism sharing. \textit{Circuit-TR} learns a collection of modules (i.e., local predictors) from the source data, and transport/compose them to obtain a circuit for prediction in the target domain if the causal structure licenses. Furthermore, circuit transportability enables us to design a supervised domain adaptation scheme that operates without access to an explicit causal structure, and instead uses limited target data. Our theoretical results characterize classes of few-shot learnable tasks in terms of graphical circuit transportability criteria, and connects few-shot generalizability with the established notion of circuit size complexity; controlled simulations corroborate our theoretical results.
Automatic Reward Shaping from Confounded Offline Data
May 16, 2025A key task in Artificial Intelligence is learning effective policies for controlling agents in unknown environments to optimize performance measures. Off-policy learning methods, like Q-learning, allow learners to make optimal decisions based on past experiences. This paper studies off-policy learning from biased data in complex and high-dimensional domains where \emph{unobserved confounding} cannot be ruled out a priori. Building on the well-celebrated Deep Q-Network (DQN), we propose a novel deep reinforcement learning algorithm robust to confounding biases in observed data. Specifically, our algorithm attempts to find a safe policy for the worst-case environment compatible with the observations. We apply our method to twelve confounded Atari games, and find that it consistently dominates the standard DQN in all games where the observed input to the behavioral and target policies mismatch and unobserved confounders exist.
Partial Transportability for Domain Generalization
Mar 30, 2025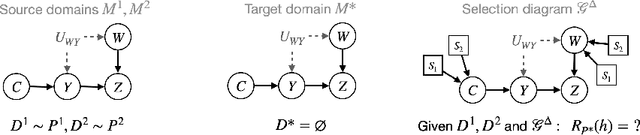


A fundamental task in AI is providing performance guarantees for predictions made in unseen domains. In practice, there can be substantial uncertainty about the distribution of new data, and corresponding variability in the performance of existing predictors. Building on the theory of partial identification and transportability, this paper introduces new results for bounding the value of a functional of the target distribution, such as the generalization error of a classifier, given data from source domains and assumptions about the data generating mechanisms, encoded in causal diagrams. Our contribution is to provide the first general estimation technique for transportability problems, adapting existing parameterization schemes such Neural Causal Models to encode the structural constraints necessary for cross-population inference. We demonstrate the expressiveness and consistency of this procedure and further propose a gradient-based optimization scheme for making scalable inferences in practice. Our results are corroborated with experiments.
* causalai.net/r88.pdf
Causally Aligned Curriculum Learning
Mar 21, 2025A pervasive challenge in Reinforcement Learning (RL) is the "curse of dimensionality" which is the exponential growth in the state-action space when optimizing a high-dimensional target task. The framework of curriculum learning trains the agent in a curriculum composed of a sequence of related and more manageable source tasks. The expectation is that when some optimal decision rules are shared across source tasks and the target task, the agent could more quickly pick up the necessary skills to behave optimally in the environment, thus accelerating the learning process. However, this critical assumption of invariant optimal decision rules does not necessarily hold in many practical applications, specifically when the underlying environment contains unobserved confounders. This paper studies the problem of curriculum RL through causal lenses. We derive a sufficient graphical condition characterizing causally aligned source tasks, i.e., the invariance of optimal decision rules holds. We further develop an efficient algorithm to generate a causally aligned curriculum, provided with qualitative causal knowledge of the target task. Finally, we validate our proposed methodology through experiments in discrete and continuous confounded tasks with pixel observations.
Counterfactual Realizability
Mar 14, 2025



It is commonly believed that, in a real-world environment, samples can only be drawn from observational and interventional distributions, corresponding to Layers 1 and 2 of the Pearl Causal Hierarchy. Layer 3, representing counterfactual distributions, is believed to be inaccessible by definition. However, Bareinboim, Forney, and Pearl (2015) introduced a procedure that allows an agent to sample directly from a counterfactual distribution, leaving open the question of what other counterfactual quantities can be estimated directly via physical experimentation. We resolve this by introducing a formal definition of realizability, the ability to draw samples from a distribution, and then developing a complete algorithm to determine whether an arbitrary counterfactual distribution is realizable given fundamental physical constraints, such as the inability to go back in time and subject the same unit to a different experimental condition. We illustrate the implications of this new framework for counterfactual data collection using motivating examples from causal fairness and causal reinforcement learning. While the baseline approach in these motivating settings typically follows an interventional or observational strategy, we show that a counterfactual strategy provably dominates both.
An Algorithmic Approach for Causal Health Equity: A Look at Race Differentials in Intensive Care Unit (ICU) Outcomes
Jan 09, 2025



The new era of large-scale data collection and analysis presents an opportunity for diagnosing and understanding the causes of health inequities. In this study, we describe a framework for systematically analyzing health disparities using causal inference. The framework is illustrated by investigating racial and ethnic disparities in intensive care unit (ICU) outcome between majority and minority groups in Australia (Indigenous vs. Non-Indigenous) and the United States (African-American vs. White). We demonstrate that commonly used statistical measures for quantifying inequity are insufficient, and focus on attributing the observed disparity to the causal mechanisms that generate it. We find that minority patients are younger at admission, have worse chronic health, are more likely to be admitted for urgent and non-elective reasons, and have higher illness severity. At the same time, however, we find a protective direct effect of belonging to a minority group, with minority patients showing improved survival compared to their majority counterparts, with all other variables kept equal. We demonstrate that this protective effect is related to the increased probability of being admitted to ICU, with minority patients having an increased risk of ICU admission. We also find that minority patients, while showing improved survival, are more likely to be readmitted to ICU. Thus, due to worse access to primary health care, minority patients are more likely to end up in ICU for preventable conditions, causing a reduction in the mortality rates and creating an effect that appears to be protective. Since the baseline risk of ICU admission may serve as proxy for lack of access to primary care, we developed the Indigenous Intensive Care Equity (IICE) Radar, a monitoring system for tracking the over-utilization of ICU resources by the Indigenous population of Australia across geographical areas.