 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmbiBench: Benchmarking Mobile GUI Agents Beyond One-Shot Instructions in the Wild
Feb 12, 2026Benchmarks are paramount for gauging progress in the domain of Mobile GUI Agents. In practical scenarios, users frequently fail to articulate precise directives containing full task details at the onset, and their expressions are typically ambiguous. Consequently, agents are required to converge on the user's true intent via active clarification and interaction during execution. However, existing benchmarks predominantly operate under the idealized assumption that user-issued instructions are complete and unequivocal. This paradigm focuses exclusively on assessing single-turn execution while overlooking the alignment capability of the agent. To address this limitation, we introduce AmbiBench, the first benchmark incorporating a taxonomy of instruction clarity to shift evaluation from unidirectional instruction following to bidirectional intent alignment. Grounded in Cognitive Gap theory, we propose a taxonomy of four clarity levels: Detailed, Standard, Incomplete, and Ambiguous. We construct a rigorous dataset of 240 ecologically valid tasks across 25 applications, subject to strict review protocols. Furthermore, targeting evaluation in dynamic environments, we develop MUSE (Mobile User Satisfaction Evaluator), an automated framework utilizing an MLLM-as-a-judge multi-agent architecture. MUSE performs fine-grained auditing across three dimensions: Outcome Effectiveness, Execution Quality, and Interaction Quality. Empirical results on AmbiBench reveal the performance boundaries of SoTA agents across different clarity levels, quantify the gains derived from active interaction, and validate the strong correlation between MUSE and human judgment. This work redefines evaluation standards, laying the foundation for next-generation agents capable of truly understanding user intent.
CI4A: Semantic Component Interfaces for Agents Empowering Web Automation
Jan 21, 2026While Large Language Models demonstrate remarkable proficiency in high-level semantic planning, they remain limited in handling fine-grained, low-level web component manipulations. To address this limitation, extensive research has focused on enhancing model grounding capabilities through techniques such as Reinforcement Learning. However, rather than compelling agents to adapt to human-centric interfaces, we propose constructing interaction interfaces specifically optimized for agents. This paper introduces Component Interface for Agent (CI4A), a semantic encapsulation mechanism that abstracts the complex interaction logic of UI components into a set of unified tool primitives accessible to agents. We implemented CI4A within Ant Design, an industrial-grade front-end framework, covering 23 categories of commonly used UI components. Furthermore, we developed a hybrid agent featuring an action space that dynamically updates according to the page state, enabling flexible invocation of available CI4A tools. Leveraging the CI4A-integrated Ant Design, we refactored and upgraded the WebArena benchmark to evaluate existing SoTA methods. Experimental results demonstrate that the CI4A-based agent significantly outperforms existing approaches, achieving a new SoTA task success rate of 86.3%, alongside substantial improvements in execution efficiency.
Pilot-Aided Joint Time Synchronization and Channel Estimation for OTFS
Aug 08, 2024



In this letter, we propose a joint time synchronization and channel estimation (JTSCE) algorithm with embedded pilot for orthogonal time frequency space (OTFS) systems. It completes both synchronization and channel estimation using the same pilot signal. Unlike existing synchronization and channel estimation algorithms based on embedded pilots, JTSCE employs a maximum length sequence (MLS) rather than an isolated signal as the pilot. Specifically, JTSCE first explores the autocorrelation properties of MLS to estimate timing offset (TO) and channel delay taps. After obtaining these types of delay taps, the closed-form estimation expressions of the Doppler and channel gain of each propagation path are derived. Extensive simulation results indicate that compared to its counterparts, JTSCE achieves better bit error rate (BER) performance, close to that with perfect time synchronization and channel state information.
Data-Augmented Contact Model for Rigid Body Simulation
Sep 23, 2018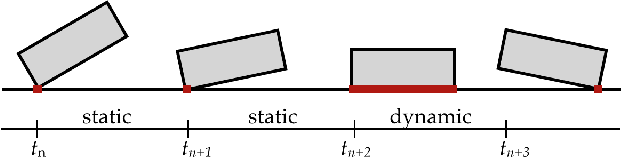
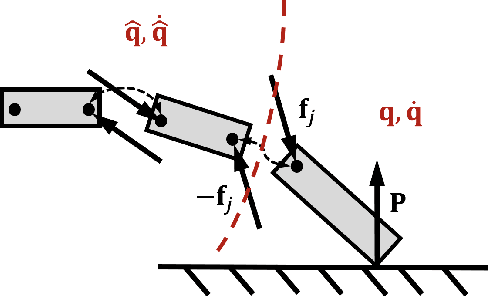
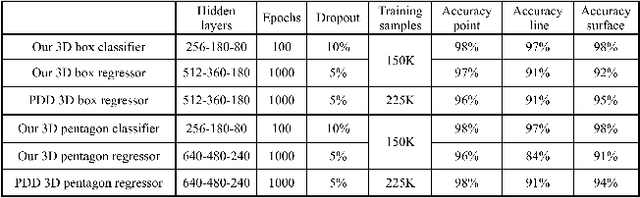
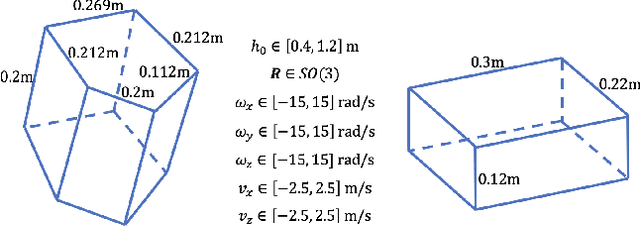
Accurately modeling contact behaviors for real-world, near-rigid materials remains a grand challenge for existing rigid-body physics simulators. This paper introduces a data-augmented contact model that incorporates analytical solutions with observed data to predict the 3D contact impulse which could result in rigid bodies bouncing, sliding or spinning in all directions. Our method enhances the expressiveness of the standard Coulomb contact model by learning the contact behaviors from the observed data, while preserving the fundamental contact constraints whenever possible. For example, a classifier is trained to approximate the transitions between static and dynamic frictions, while non-penetration constraint during collision is enforced analytically. Our method computes the aggregated effect of contact for the entire rigid body, instead of predicting the contact force for each contact point individually, removing the exponential decline in accuracy as the number of contact points increases.