 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOSIC: A New One-Stage Image Captioner Coined
Nov 04, 2022Mainstream image caption models are usually two-stage captioners, i.e., calculating object features by pre-trained detector, and feeding them into a language model to generate text descriptions. However, such an operation will cause a task-based information gap to decrease the performance, since the object features in detection task are suboptimal representation and cannot provide all necessary information for subsequent text generation. Besides, object features are usually represented by the last layer features that lose the local details of input images. In this paper, we propose a novel One-Stage Image Captioner (OSIC) with dynamic multi-sight learning, which directly transforms input image into descriptive sentences in one stage. As a result, the task-based information gap can be greatly reduced. To obtain rich features, we use the Swin Transformer to calculate multi-level features, and then feed them into a novel dynamic multi-sight embedding module to exploit both global structure and local texture of input images. To enhance the global modeling of encoder for caption, we propose a new dual-dimensional refining module to non-locally model the interaction of the embedded features. Finally, OSIC can obtain rich and useful information to improve the image caption task. Extensive comparisons on benchmark MS-COCO dataset verified the superior performance of our method.
Seeing Through The Noisy Dark: Toward Real-world Low-Light Image Enhancement and Denoising
Oct 07, 2022
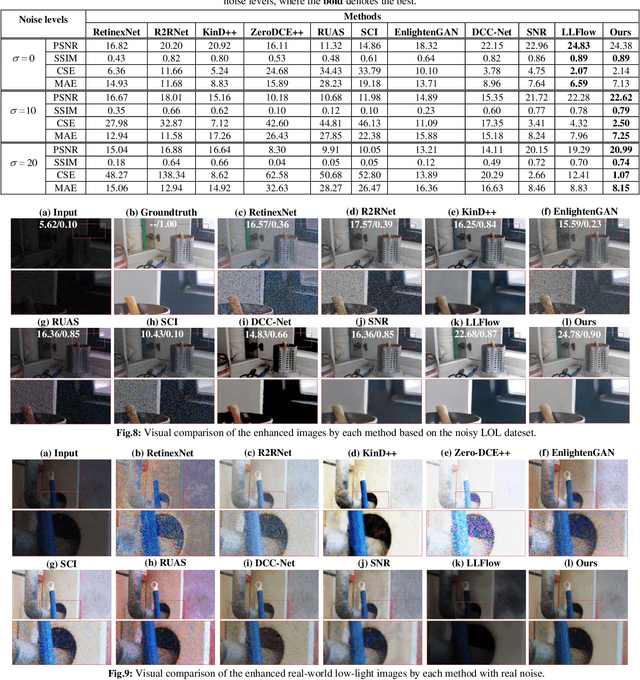
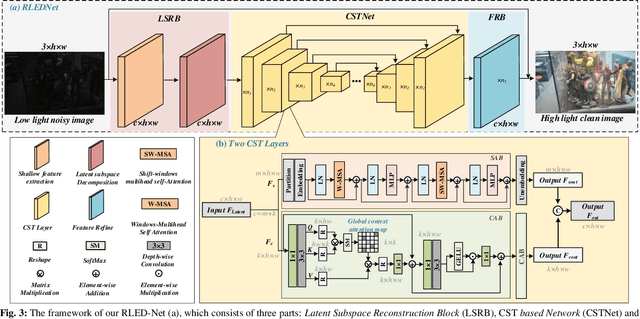
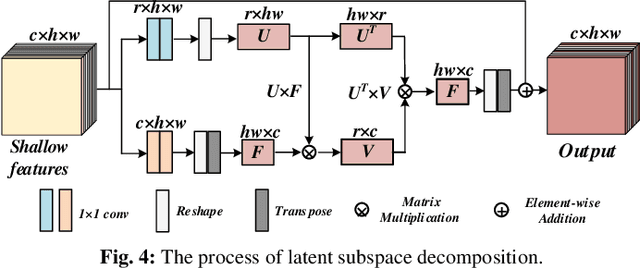
Images collected in real-world low-light environment usually suffer from lower visibility and heavier noise, due to the insufficient light or hardware limitation. While existing low-light image enhancement (LLIE) methods basically ignored the noise interference and mainly focus on refining the illumination of the low-light images based on benchmarked noise-negligible datasets. Such operations will make them inept for the real-world LLIE (RLLIE) with heavy noise, and result in speckle noise and blur in the enhanced images. Although several LLIE methods considered the noise in low-light image, they are trained on the raw data and hence cannot be used for sRGB images, since the domains of data are different and lack of expertise or unknown protocols. In this paper, we clearly consider the task of seeing through the noisy dark in sRGB color space, and propose a novel end-to-end method termed Real-world Low-light Enhancement & Denoising Network (RLED-Net). Since natural images can usually be characterized by low-rank subspaces in which the redundant information and noise can be removed, we design a Latent Subspace Reconstruction Block (LSRB) for feature extraction and denoising. To reduce the loss of global feature (e.g., color/shape information) and extract more accurate local features (e.g., edge/texture information), we also present a basic layer with two branches, called Cross-channel & Shift-window Transformer (CST). Based on the CST, we further present a new backbone to design a U-structure Network (CSTNet) for deep feature recovery, and also design a Feature Refine Block (FRB) to refine the final features. Extensive experiments on real noisy images and public databases verified the effectiveness of our RLED-Net for both RLLIE and denoising.
Focal and Global Spatial-Temporal Transformer for Skeleton-based Action Recognition
Oct 06, 2022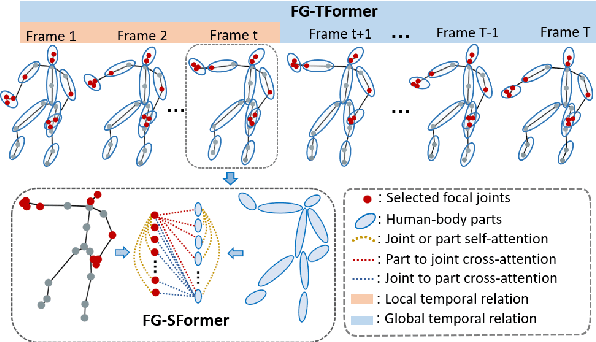
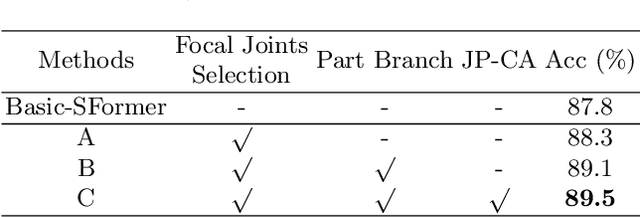
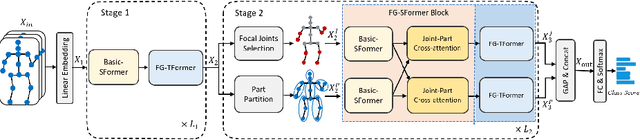

Despite great progress achieved by transformer in various vision tasks, it is still underexplored for skeleton-based action recognition with only a few attempts. Besides, these methods directly calculate the pair-wise global self-attention equally for all the joints in both the spatial and temporal dimensions, undervaluing the effect of discriminative local joints and the short-range temporal dynamics. In this work, we propose a novel Focal and Global Spatial-Temporal Transformer network (FG-STFormer), that is equipped with two key components: (1) FG-SFormer: focal joints and global parts coupling spatial transformer. It forces the network to focus on modelling correlations for both the learned discriminative spatial joints and human body parts respectively. The selective focal joints eliminate the negative effect of non-informative ones during accumulating the correlations. Meanwhile, the interactions between the focal joints and body parts are incorporated to enhance the spatial dependencies via mutual cross-attention. (2) FG-TFormer: focal and global temporal transformer. Dilated temporal convolution is integrated into the global self-attention mechanism to explicitly capture the local temporal motion patterns of joints or body parts, which is found to be vital important to make temporal transformer work. Extensive experimental results on three benchmarks, namely NTU-60, NTU-120 and NW-UCLA, show our FG-STFormer surpasses all existing transformer-based methods, and compares favourably with state-of-the art GCN-based methods.
FT-HID: A Large Scale RGB-D Dataset for First and Third Person Human Interaction Analysis
Sep 21, 2022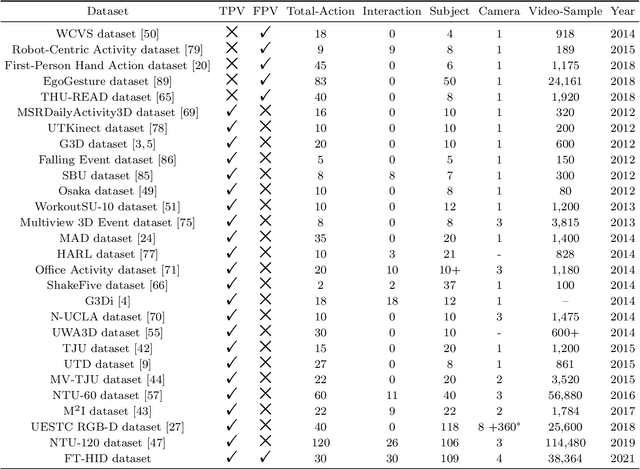
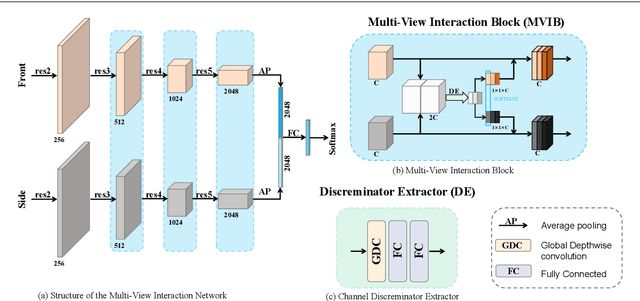
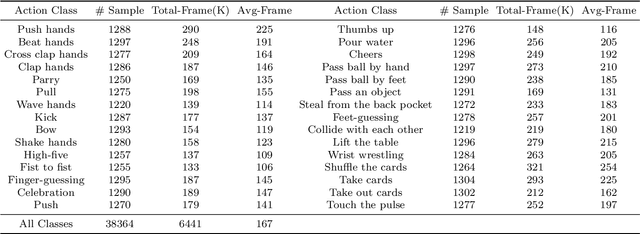
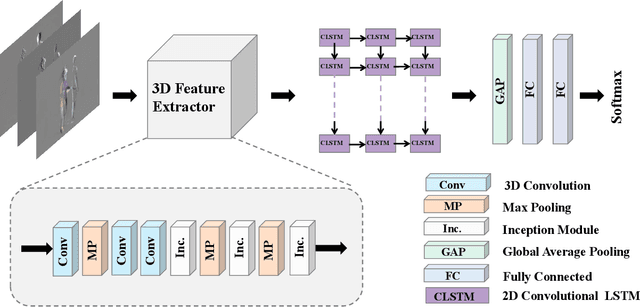
Analysis of human interaction is one important research topic of human motion analysis. It has been studied either using first person vision (FPV) or third person vision (TPV). However, the joint learning of both types of vision has so far attracted little attention. One of the reasons is the lack of suitable datasets that cover both FPV and TPV. In addition, existing benchmark datasets of either FPV or TPV have several limitations, including the limited number of samples, participant subjects, interaction categories, and modalities. In this work, we contribute a large-scale human interaction dataset, namely, FT-HID dataset. FT-HID contains pair-aligned samples of first person and third person visions. The dataset was collected from 109 distinct subjects and has more than 90K samples for three modalities. The dataset has been validated by using several existing action recognition methods. In addition, we introduce a novel multi-view interaction mechanism for skeleton sequences, and a joint learning multi-stream framework for first person and third person visions. Both methods yield promising results on the FT-HID dataset. It is expected that the introduction of this vision-aligned large-scale dataset will promote the development of both FPV and TPV, and their joint learning techniques for human action analysis. The dataset and code are available at \href{https://github.com/ENDLICHERE/FT-HID}{here}.
D2-TPred: Discontinuous Dependency for Trajectory Prediction under Traffic Lights
Jul 21, 2022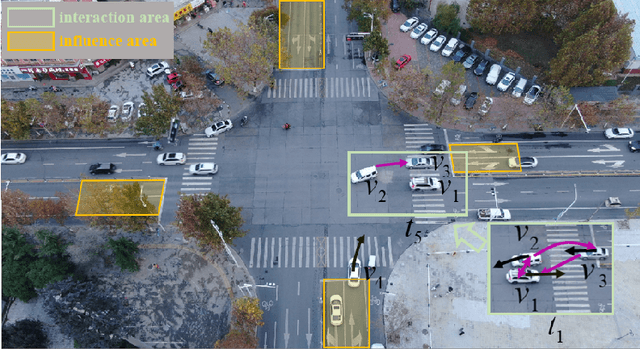
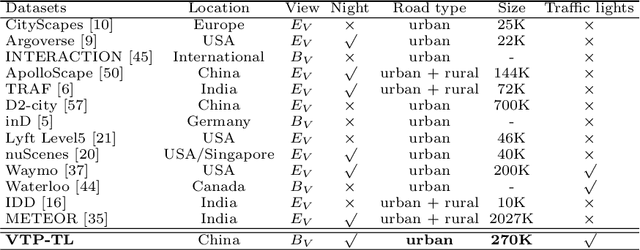
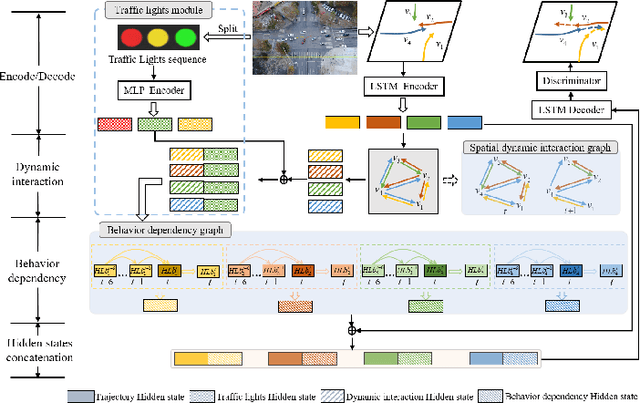
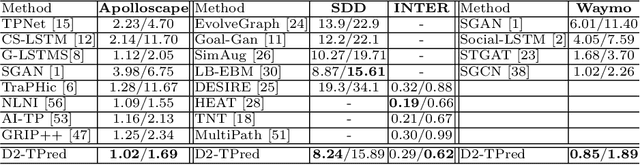
A profound understanding of inter-agent relationships and motion behaviors is important to achieve high-quality planning when navigating in complex scenarios, especially at urban traffic intersections. We present a trajectory prediction approach with respect to traffic lights, D2-TPred, which uses a spatial dynamic interaction graph (SDG) and a behavior dependency graph (BDG) to handle the problem of discontinuous dependency in the spatial-temporal space. Specifically, the SDG is used to capture spatial interactions by reconstructing sub-graphs for different agents with dynamic and changeable characteristics during each frame. The BDG is used to infer motion tendency by modeling the implicit dependency of the current state on priors behaviors, especially the discontinuous motions corresponding to acceleration, deceleration, or turning direction. Moreover, we present a new dataset for vehicle trajectory prediction under traffic lights called VTP-TL. Our experimental results show that our model achieves more than {20.45% and 20.78% }improvement in terms of ADE and FDE, respectively, on VTP-TL as compared to other trajectory prediction algorithms. The dataset and code are available at: https://github.com/VTP-TL/D2-TPred.
FCL-GAN: A Lightweight and Real-Time Baseline for Unsupervised Blind Image Deblurring
Apr 16, 2022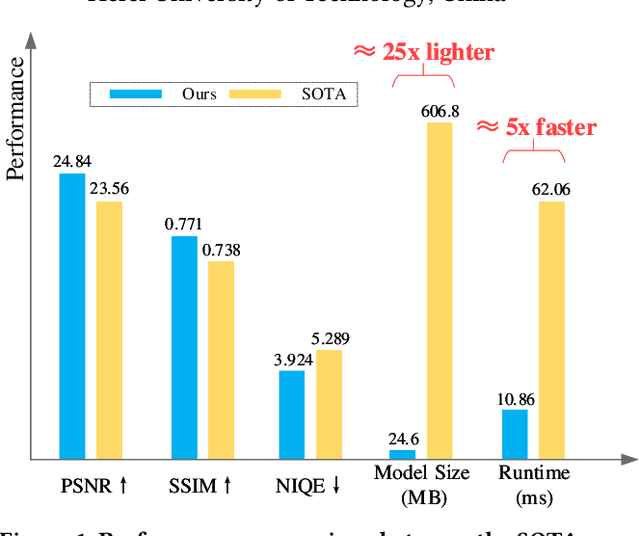
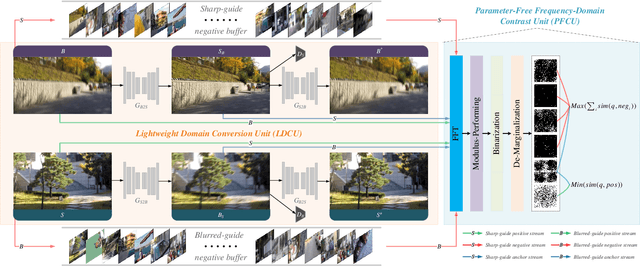
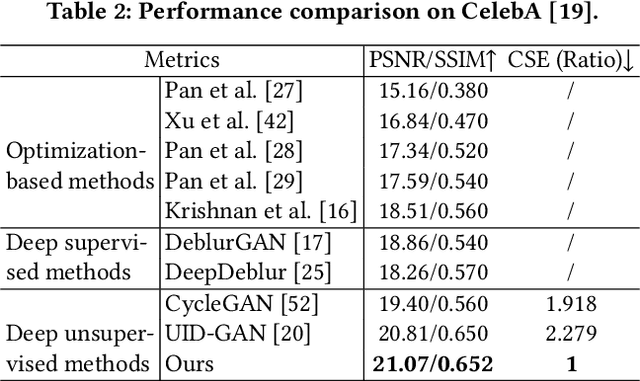

Blind image deblurring (BID) remains a challenging and significant task. Benefiting from the strong fitting ability of deep learning, paired data-driven supervised BID method has obtained great progress. However, paired data are usually synthesized by hand, and the realistic blurs are more complex than synthetic ones, which makes the supervised methods inept at modeling realistic blurs and hinders their real-world applications. As such, unsupervised deep BID method without paired data offers certain advantages, but current methods still suffer from some drawbacks, e.g., bulky model size, long inference time, and strict image resolution and domain requirements. In this paper, we propose a lightweight and real-time unsupervised BID baseline, termed Frequency-domain Contrastive Loss Constrained Lightweight CycleGAN (shortly, FCL-GAN), with attractive properties, i.e., no image domain limitation, no image resolution limitation, 25x lighter than SOTA, and 5x faster than SOTA. To guarantee the lightweight property and performance superiority, two new collaboration units called lightweight domain conversion unit(LDCU) and parameter-free frequency-domain contrastive unit(PFCU) are designed. LDCU mainly implements inter-domain conversion in lightweight manner. PFCU further explores the similarity measure, external difference and internal connection between the blurred domain and sharp domain images in frequency domain, without involving extra parameters. Extensive experiments on several image datasets demonstrate the effectiveness of our FCL-GAN in terms of performance, model size and reference time.
Towards Efficient and Elastic Visual Question Answering with Doubly Slimmable Transformer
Mar 24, 2022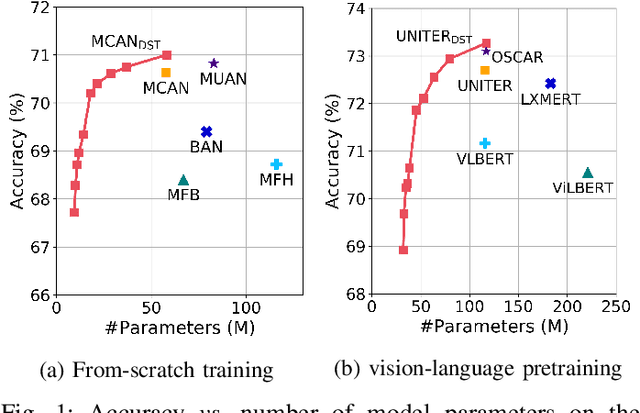
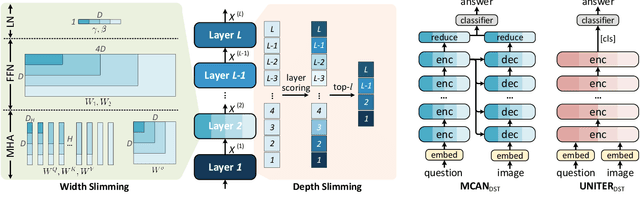
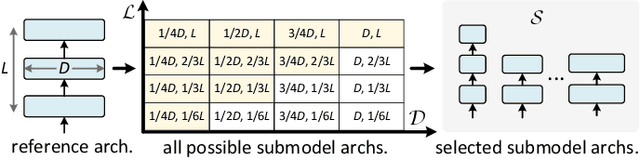
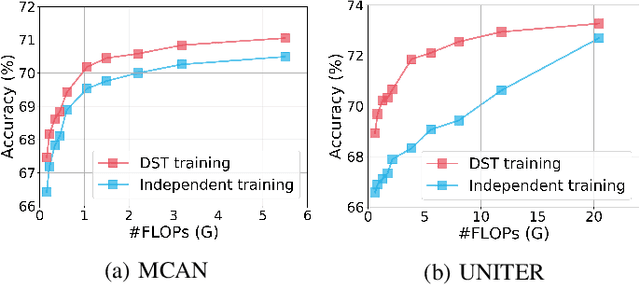
Transformer-based approaches have shown great success in visual question answering (VQA). However, they usually require deep and wide models to guarantee good performance, making it difficult to deploy on capacity-restricted platforms. It is a challenging yet valuable task to design an elastic VQA model that supports adaptive pruning at runtime to meet the efficiency constraints of diverse platforms. In this paper, we present the Doubly Slimmable Transformer (DST), a general framework that can be seamlessly integrated into arbitrary Transformer-based VQA models to train one single model once and obtain various slimmed submodels of different widths and depths. Taking two typical Transformer-based VQA approaches, i.e., MCAN and UNITER, as the reference models, the obtained slimmable MCAN_DST and UNITER_DST models outperform the state-of-the-art methods trained independently on two benchmark datasets. In particular, one slimmed MCAN_DST submodel achieves a comparable accuracy on VQA-v2, while being 0.38x smaller in model size and having 0.27x fewer FLOPs than the reference MCAN model. The smallest MCAN_DST submodel has 9M parameters and 0.16G FLOPs in the inference stage, making it possible to be deployed on edge devices.
Decision-making of Emergent Incident based on P-MADDPG
Mar 19, 2022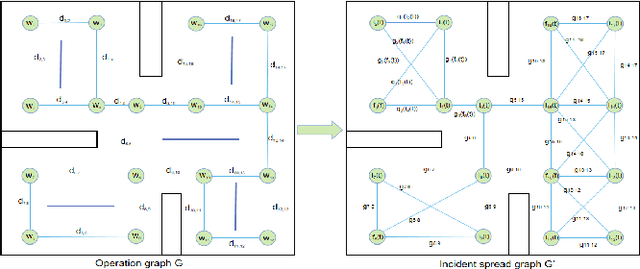
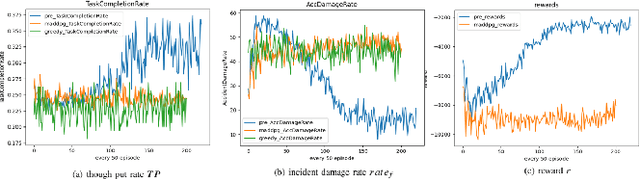
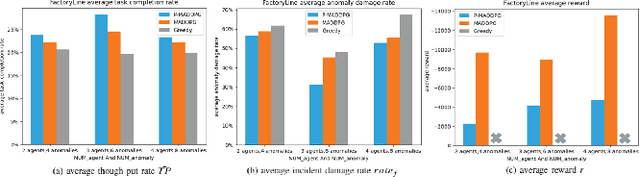

In recent years, human casualties and damage to resources caused by emergent incidents have become a serious problem worldwide. In this paper, we model the emergency decision-making problem and use Multi-agent System (MAS) to solve the problem that the decision speed cannot keep up with the spreading speed. MAS can play an important role in the automated execution of these tasks to reduce mission completion time. In this paper, we propose a P-MADDPG algorithm to solve the emergency decision-making problem of emergent incidents, which predicts the nodes where an incident may occur in the next time by GRU model and makes decisions before the incident occurs, thus solving the problem that the decision speed cannot keep up with the spreading speed. A simulation environment was established for realistic scenarios, and three scenarios were selected to test the performance of P-MADDPG in emergency decision-making problems for emergent incidents: unmanned storage, factory assembly line, and civil airport baggage transportation. Simulation results using the P-MADDPG algorithm are compared with the greedy algorithm and the MADDPG algorithm, and the final experimental results show that the P-MADDPG algorithm converges faster and better than the other algorithms in scenarios of different sizes. This shows that the P-MADDP algorithm is effective for emergency decision-making in emergent incident.
Multi-Agent Broad Reinforcement Learning for Intelligent Traffic Light Control
Mar 08, 2022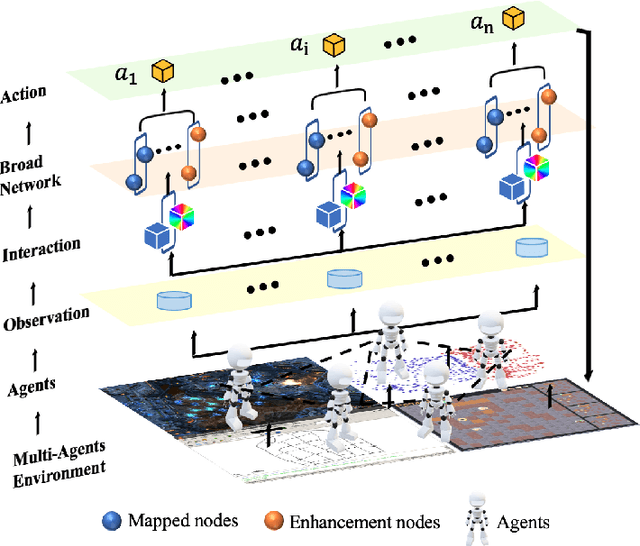
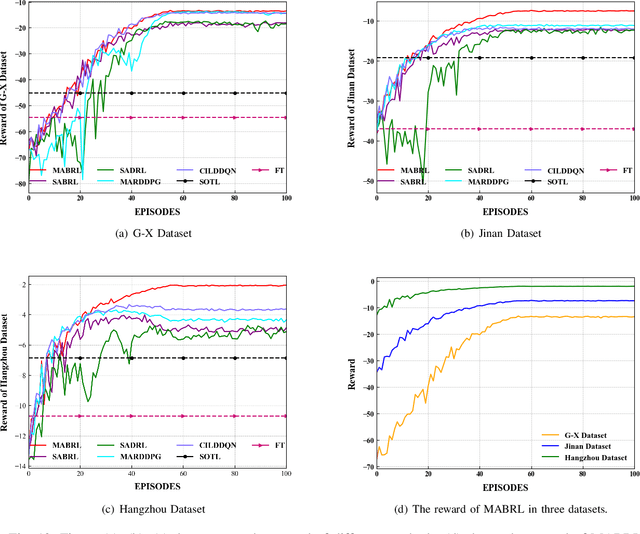
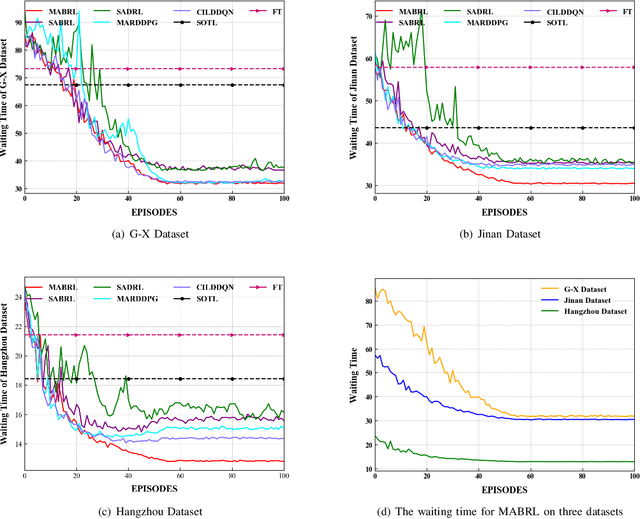
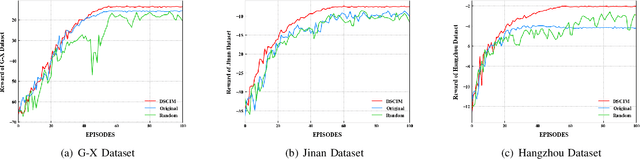
Intelligent Traffic Light Control System (ITLCS) is a typical Multi-Agent System (MAS), which comprises multiple roads and traffic lights.Constructing a model of MAS for ITLCS is the basis to alleviate traffic congestion. Existing approaches of MAS are largely based on Multi-Agent Deep Reinforcement Learning (MADRL). Although the Deep Neural Network (DNN) of MABRL is effective, the training time is long, and the parameters are difficult to trace. Recently, Broad Learning Systems (BLS) provided a selective way for learning in the deep neural networks by a flat network. Moreover, Broad Reinforcement Learning (BRL) extends BLS in Single Agent Deep Reinforcement Learning (SADRL) problem with promising results. However, BRL does not focus on the intricate structures and interaction of agents. Motivated by the feature of MADRL and the issue of BRL, we propose a Multi-Agent Broad Reinforcement Learning (MABRL) framework to explore the function of BLS in MAS. Firstly, unlike most existing MADRL approaches, which use a series of deep neural networks structures, we model each agent with broad networks. Then, we introduce a dynamic self-cycling interaction mechanism to confirm the "3W" information: When to interact, Which agents need to consider, What information to transmit. Finally, we do the experiments based on the intelligent traffic light control scenario. We compare the MABRL approach with six different approaches, and experimental results on three datasets verify the effectiveness of MABRL.
Dynamic Hypergraph Convolutional Networks for Skeleton-Based Action Recognition
Dec 20, 2021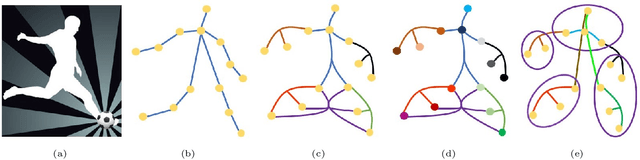
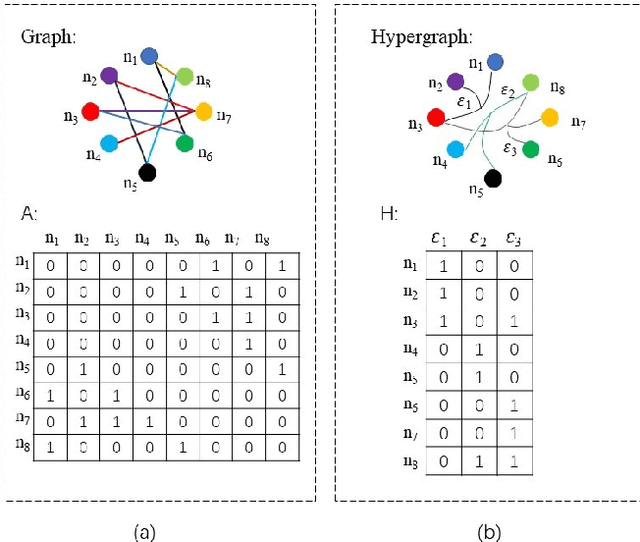

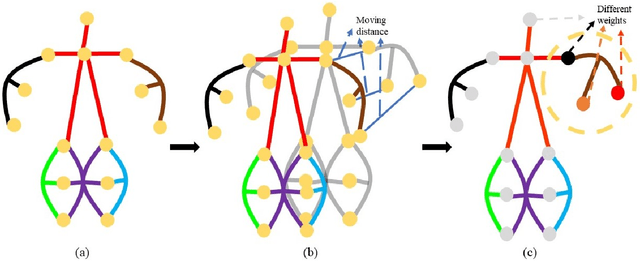
Graph convolutional networks (GCNs) based methods have achieved advanced performance on skeleton-based action recognition task. However, the skeleton graph cannot fully represent the motion information contained in skeleton data. In addition, the topology of the skeleton graph in the GCN-based methods is manually set according to natural connections, and it is fixed for all samples, which cannot well adapt to different situations. In this work, we propose a novel dynamic hypergraph convolutional networks (DHGCN) for skeleton-based action recognition. DHGCN uses hypergraph to represent the skeleton structure to effectively exploit the motion information contained in human joints. Each joint in the skeleton hypergraph is dynamically assigned the corresponding weight according to its moving, and the hypergraph topology in our model can be dynamically adjusted to different samples according to the relationship between the joints. Experimental results demonstrate that the performance of our model achieves competitive performance on three datasets: Kinetics-Skeleton 400, NTU RGB+D 60, and NTU RGB+D 120.