 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMechanism-Guided Selective Unlearning for RLVR-Induced Reasoning
Jun 17, 2026We propose MAST (Mechanism-Aligned Selective Targeting), a mechanism-guided method for unlearning RLVR-induced reasoning with substantially lower collateral damage than standard full-parameter updates. In matched SFT/RLVR checkpoints on Qwen2.5-Math-1.5B and Qwen3-1.7B-Base, the SFT-to-RLVR increment differs sharply from the SFT update in token-level delta-log-probability, and full-parameter gradient ascent forgets only by damaging retain MATH and GSM8K. MAST ranks attention-projection tensors by off-principal energy, update magnitude, and forget-gradient coupling magnitude, then updates only the top-ranked subset. On the primary model, MAST induces statistically significant target forgetting (MATH forget 45/150 to 37/150; McNemar p=0.0078) while preserving GSM8K (+0.8 pp) and MATH retain (-0.5 pp). The advantage reproduces across seeds, NPO/SimNPO objectives, and Qwen3, where MAST preserves GSM8K while full-parameter unlearning collapses it.
The Vision Encoder as a Privacy Boundary: Visual-Token Side Channels in Encoder-Free Vision-Language Models
Jun 10, 2026A vision encoder compresses image pixels into semantic embeddings, implicitly acting as a privacy boundary by preserving semantic content while attenuating pixel-local detail required for exact text recovery. Encoder-free vision-language models (VLMs) remove this boundary by routing image patches directly into the language-model token stream, thereby exposing an architectural privacy attack surface: intermediate visual tokens become a pre-output side channel. Under a token-access adversary, decoders invert visual-token streams from two encoder-free VLMs, Gemma4 and Fuyu, recovering recognizable image structure and readable held-out access codes, whereas matched encoder-based controls localize target regions but recover no exact strings. Within-model ablations show that the operative factor is spatial sampling fidelity of the visual-token grid, especially character-direction sampling density, rather than token or value count. The leakage is not limited to exported tokens: Gemma4 layer-0 key-value cache tensors are directly invertible, placing the side channel within KV caches commonly persisted by production serving stacks for decoding efficiency. The attack survives clutter, realistic document degradation, and zero-shot transfer to public document images, and it resists value-level defenses such as additive noise and quantization. Effective mitigation must therefore reduce spatial sampling, making removal of the vision encoder a first-class privacy decision in VLM deployment.
Multi-Agent Broad Reinforcement Learning for Intelligent Traffic Light Control
Mar 08, 2022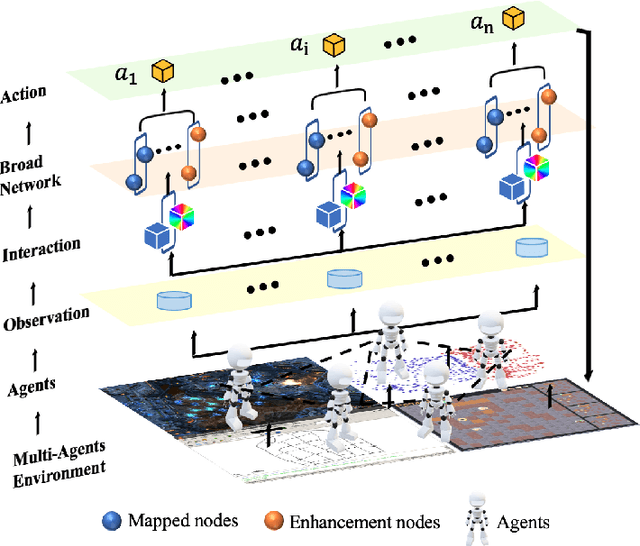
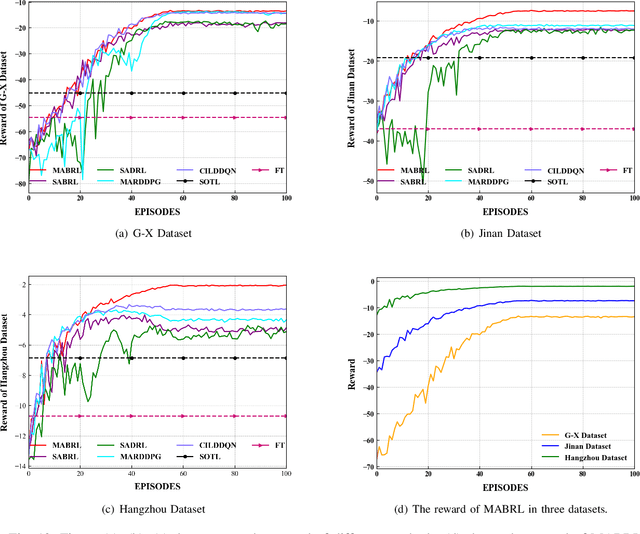
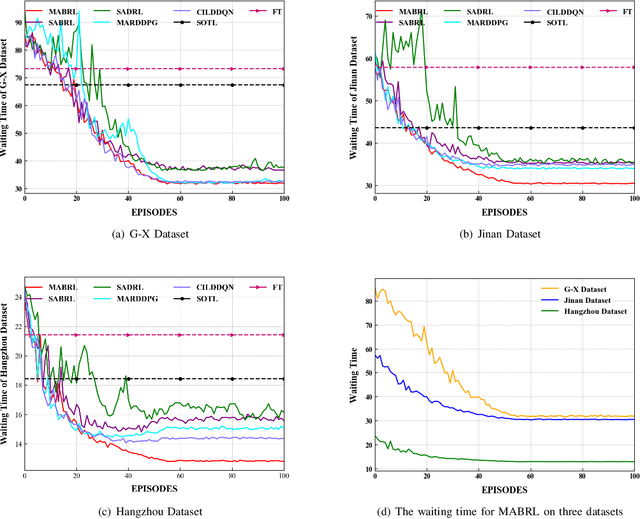
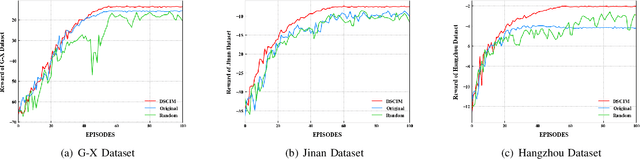
Intelligent Traffic Light Control System (ITLCS) is a typical Multi-Agent System (MAS), which comprises multiple roads and traffic lights.Constructing a model of MAS for ITLCS is the basis to alleviate traffic congestion. Existing approaches of MAS are largely based on Multi-Agent Deep Reinforcement Learning (MADRL). Although the Deep Neural Network (DNN) of MABRL is effective, the training time is long, and the parameters are difficult to trace. Recently, Broad Learning Systems (BLS) provided a selective way for learning in the deep neural networks by a flat network. Moreover, Broad Reinforcement Learning (BRL) extends BLS in Single Agent Deep Reinforcement Learning (SADRL) problem with promising results. However, BRL does not focus on the intricate structures and interaction of agents. Motivated by the feature of MADRL and the issue of BRL, we propose a Multi-Agent Broad Reinforcement Learning (MABRL) framework to explore the function of BLS in MAS. Firstly, unlike most existing MADRL approaches, which use a series of deep neural networks structures, we model each agent with broad networks. Then, we introduce a dynamic self-cycling interaction mechanism to confirm the "3W" information: When to interact, Which agents need to consider, What information to transmit. Finally, we do the experiments based on the intelligent traffic light control scenario. We compare the MABRL approach with six different approaches, and experimental results on three datasets verify the effectiveness of MABRL.
A Deep Belief Network Based Machine Learning System for Risky Host Detection
Dec 29, 2017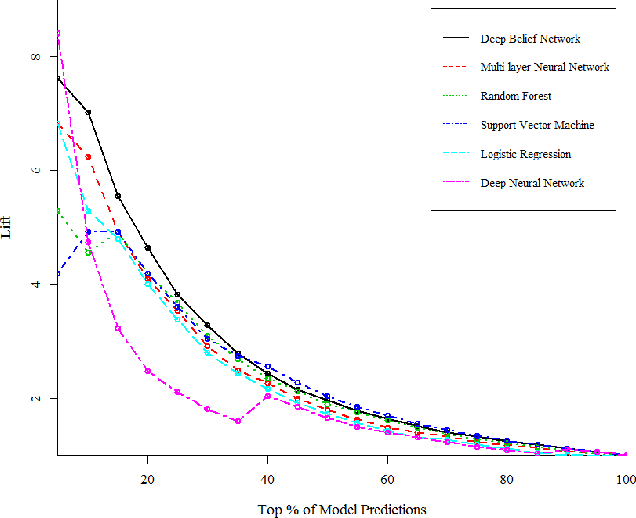
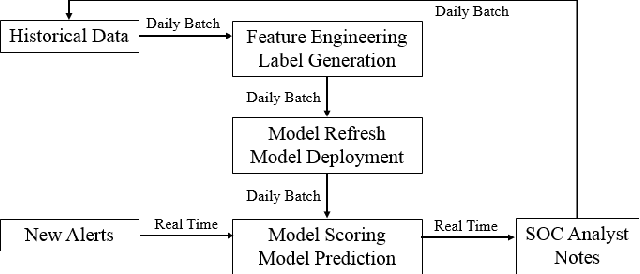
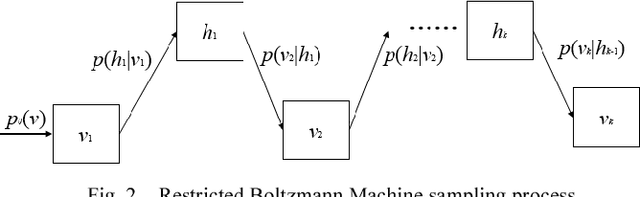
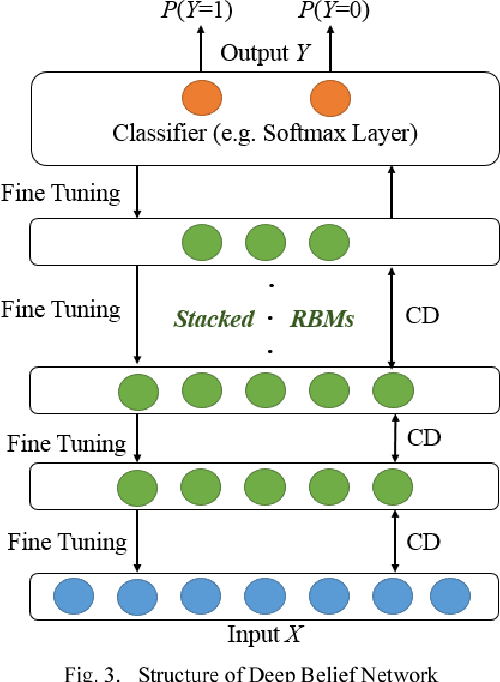
To assure cyber security of an enterprise, typically SIEM (Security Information and Event Management) system is in place to normalize security event from different preventive technologies and flag alerts. Analysts in the security operation center (SOC) investigate the alerts to decide if it is truly malicious or not. However, generally the number of alerts is overwhelming with majority of them being false positive and exceeding the SOC's capacity to handle all alerts. There is a great need to reduce the false positive rate as much as possible. While most previous research focused on network intrusion detection, we focus on risk detection and propose an intelligent Deep Belief Network machine learning system. The system leverages alert information, various security logs and analysts' investigation results in a real enterprise environment to flag hosts that have high likelihood of being compromised. Text mining and graph based method are used to generate targets and create features for machine learning. In the experiment, Deep Belief Network is compared with other machine learning algorithms, including multi-layer neural network, random forest, support vector machine and logistic regression. Results on real enterprise data indicate that the deep belief network machine learning system performs better than other algorithms for our problem and is six times more effective than current rule-based system. We also implement the whole system from data collection, label creation, feature engineering to host score generation in a real enterprise production environment.